Storage의 분류
-volatile storage: 휘발성 storage Ex) RAM
-non-volatile storage: 비휘발성 storage Ex) SSD, HDD
storage를 선택하는데 영향을 주는 요소
data access speed - performance적인 측면
cost per unit of data / reliability - mainternance적인 측면
Storage Hierarchy

위로 갈수록 빠르고, 비싸다
primary storage: 가장 빠르고, 휘발성인 storage (cache, main memory)
secondary storage: 메모리 계층에서 primary 다음 level의 storage, 비휘발성, 어느정도 빠름 (flash memory, magnetic disk)
tertiary storage: 계층의 가장 아래의 storage, 비휘발성, 느림, 주로 백업에 사용 off-line storage나 archival storage라고도 함 (magnetic tape, optical storage)
Storage Interfaces
Disk interface
SATA(Serial ATA)
SAS(Serial Attached SCSI)
NVMe(Non-Volatile Memory Express)
주로 SATA와 NVMe가 많이 사용됨
SAN(Storage Area Networks) disk들을 network로 연결
NAS(Network Attached Storage) network file system protocol을 사용해 file system interface 제공
Flash Storage
NAND flash
-보통 많이 사용됨, NOR flash보다 저렴
-page read에 20~100ms
-sequential read와 random read의 시간 차이가 HDD에 비해 적음 (여전히 Squential이 빠르긴 함)
-page는 한번만 write될 수 있음 / rewrite하려면 erase해야함
erase는 erase block단위로 발생함
erase를 기다리는것을 피하기 위해 logical address to physical address mapping을 remapping함
File Organization
DB는 file의 모음으로 store됨
각 file은 record의 sequence
각 record는 field의 sequence
이후 설명들은 다음을 가정하고 설명함
- record size는 고정
- 각 file은 특정 한 type의 record만 가짐
- 다른 file은 다른 relation에 사용됨
- record는 disk block보다 작음
Fixed-length Records
i 번째 record store -> n * (i-1) 에서부터 store됨 (n: record size)
record가 block에 걸쳐져서 저장 될 수 있음
예) record size가 1000, block size가 4096인 경우 5번째 record는 해당 block을 넘어가게 됨
=> 복잡해지기 때문에 보통 record가 block을 넘어가는것을 허락하지 않음
i 번째 record를 삭제하면
- i 이하 record를 전부 한칸씩 당겨오던가
- 맨 마지막 record를 i에 넣던가
- record를 실제로 움직이지 않고 빈 record를 표시하는 free list(linked list)를 사용하던가
Variable-length Records
Variable-length records
- multiple record types in a file
- 가변 길이의 (varchar) column type
- 같은 field의 반복을 허용함
Slotted Page Structure

Slotted page header
- record entry의 수
- block의 end of free space ptr
- 각 record의 위치, 크기
record는 연속적으로 저장되어야 함
외부에서 각 record에 접근할 때, 바로 record ptr로 접근하지 말고 header의 entry로 접근
slotted page에 record를 넣을 때, 실제 record의 정렬을 유지하며 input하는게 아니라 header의 record offset array의 정렬을 유지
Sorting Large Objects
E.g blob/clob type
record는 page보다 작아야 함
대안
- file system에 file로 저장
- database에 file로 저장
- 쪼개서 저장
Organization of Records in Files
- Heap: record는 file의 남는공간 아무데나 들어갈 수 있음
- Sequential: search key에 따라 sequential하게 저장
- B+ tree file organization: 뒤에서 자세히 설명
- Hashing: hash function으로 search key를 계산
Heap File Organization
Record는 file의 빈공간 어디에든 들어갈 수 있음
record는 한번 할당되면 이동하지 않음
Free-space map

array의 각 entry는 n bit로 각 블럭의 빈 공간의 비율을 나타냄. 예시는 3bit이고 첫번째 entry를 보면 블럭이 4/8 즉 절반 비어있음을 알 수 있음.
second-level free-space map을 가질 수도 있음
예) 위 예시의 entry를 4개씩 묶어 가장 빈공간이 큰 block의 빈 공간을 표시 (4 7 2 6)
free space map은 주기적으로 기록됨 -> 오래된 값을 가질 수 있지만 크게 문제되지는 않음
Sequential File Organization
file 전체에 sequential한 processing을 요구하는 application에 적절
Record들은 search key를 기준으로 정렬됨
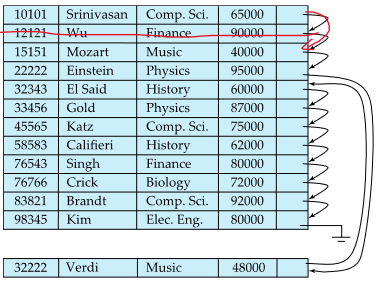
삭제 - 삭제한 record 앞, 뒤 record들을 포인터로 연결 (실제 삭제는 rewrite할 때 수행됨)
삽입 - 정렬 맞춰서 삽입
삽입해야하는 곳에 빈 공간이 있으면? -> 그냥 삽입
없으면? -> overflow block에 삽입
삽입하고 포인터 연결하여 접근할 수 있도록 함
삽입, 삭제 일어난 경우 파일의 물리적/논리적 순서를 일치시키기 위해 파일 재구성 필요
Multitable Clustering File Organization
복수의 relation을 한 file에 저장

동일한 조건으로 Join이 많이 발생될 때, 효율적임
Column-Oriented Storage
= columnar representation
relation의 각 attribute를 따로 저장
Data Dictionary
= system catalog
metadata(data에 관한 data)를 저장
- info about relation (relation name, attribute name/type 등등)
- user and accounting info
- statistical and desctiptive data (각 relation의 tuple의 수 등)
- physical file organization info (relation 저장 방식(sequential/hash/...), relation의 physical location 등)
- index 관련 정보
