3주차 배운 것 Keywords
✅ 크롤링 (웹스크래핑)
✅ Python
✅ pymongo 라이브러리로 mongoDB 제어
[실습 1] 영화 기록 페이지에서 OpenAPI 정보 가져와(Ajax), 영화 포스터 이미지/코멘트/제목/소개글/별점 HTML/CSS에 넣기
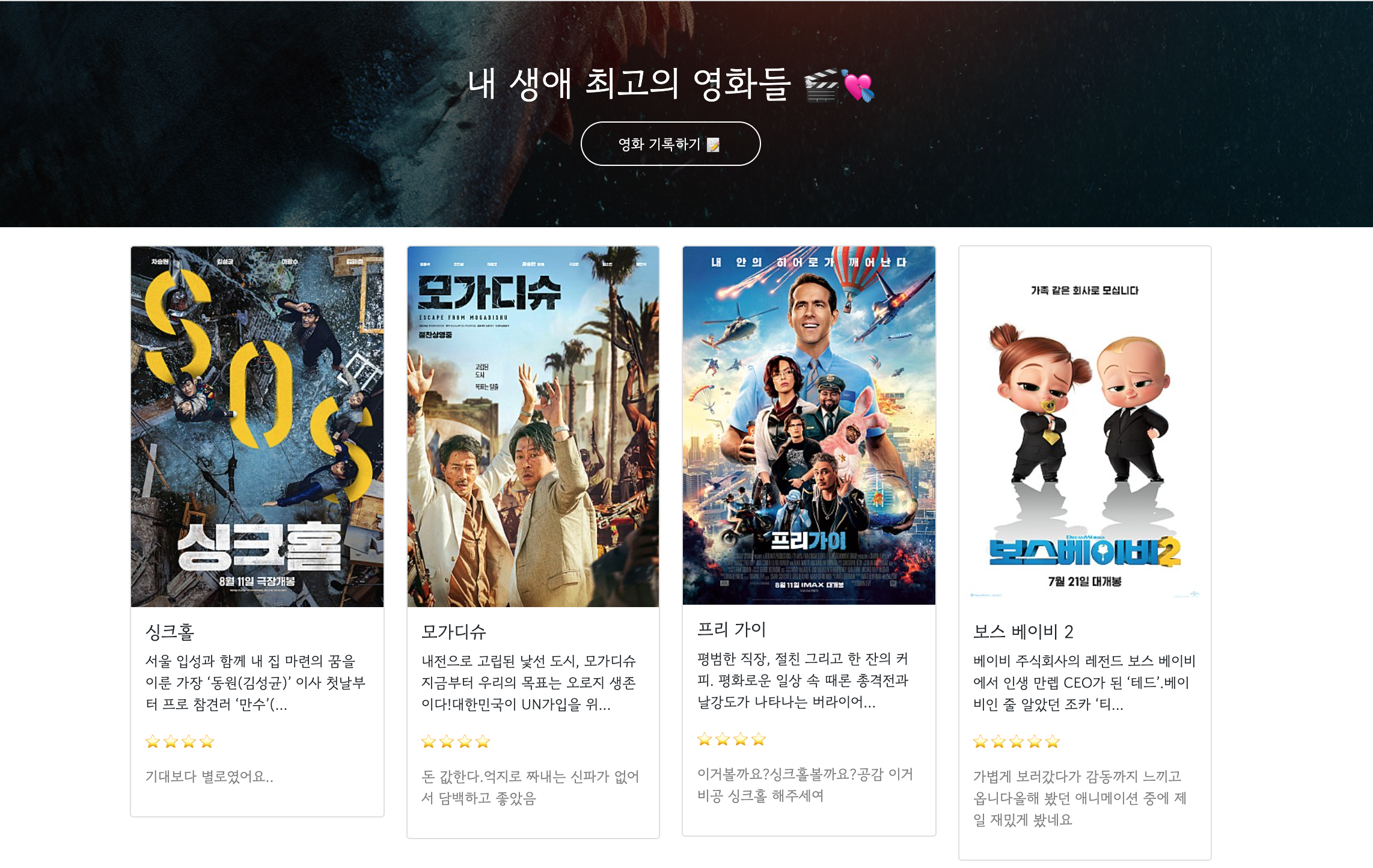
[실습 2] 네이버 영화 사이트에서 원하는 정보 크롤링하기 (BeautifulSoup 라이브러리 사용)
/Users/hyun/Desktop/sparta/frontend/pythontrack/venv/bin/python /Users/hyun/Desktop/sparta/frontend/pythontrack/venv/hello.py
<a href="/movie/bi/mi/basic.naver?code=186114" title="밥정">밥정</a>
/movie/bi/mi/basic.naver?code=186114
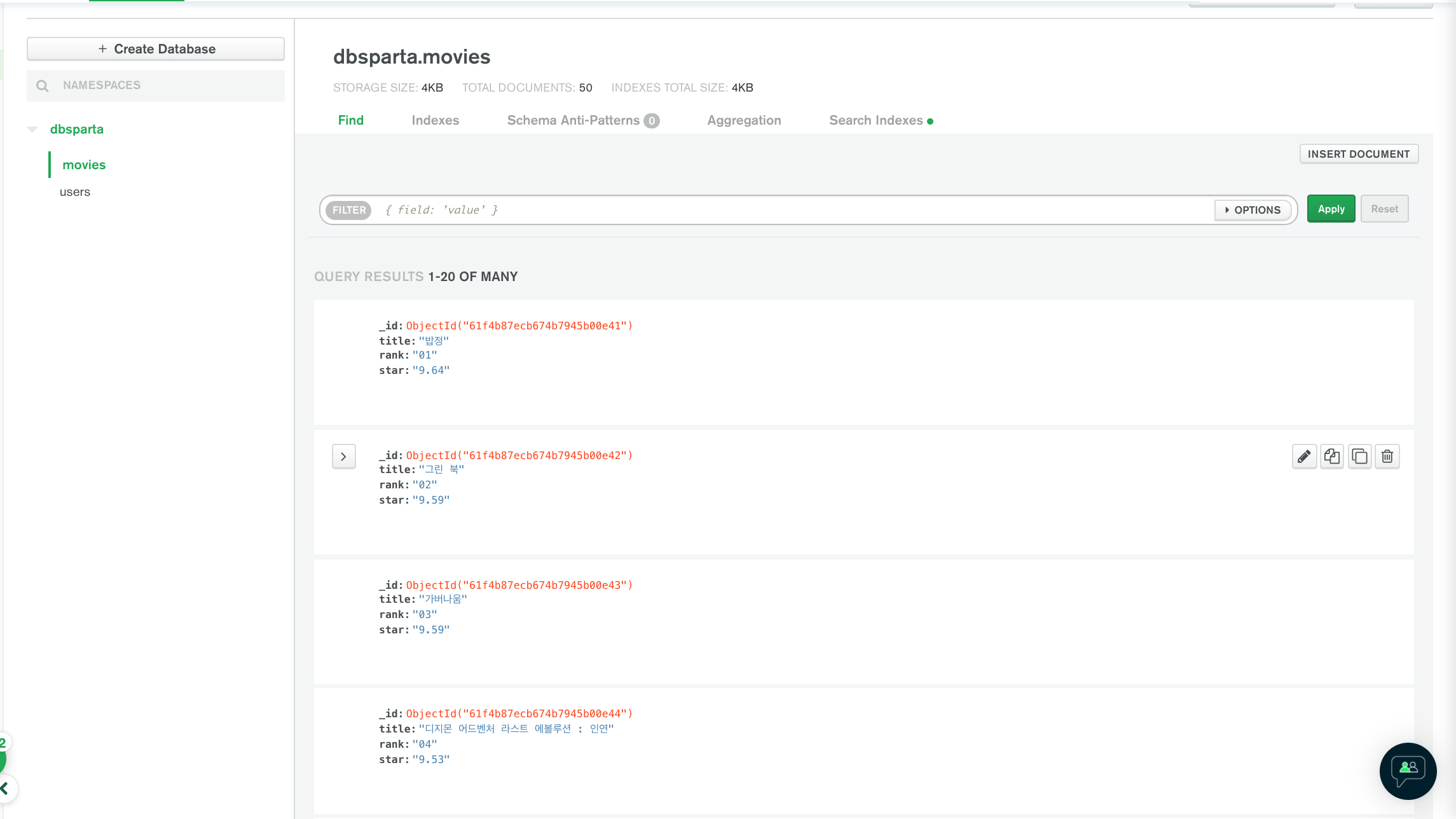
01 밥정 9.64
02 그린 북 9.59
03 가버나움 9.59
04 디지몬 어드벤처 라스트 에볼루션 : 인연 9.53
05 원더 9.52
06 베일리 어게인 9.52
07 먼 훗날 우리 9.52
08 아일라 9.51
09 당갈 9.49
010 극장판 바이올렛 에버가든 9.48
11 포드 V 페라리 9.48
12 주전장 9.47
13 쇼생크 탈출 9.45
14 터미네이터 2:오리지널 9.44
15 덕구 9.43
16 나 홀로 집에 9.43
17 라이언 일병 구하기 9.43
18 클래식 9.42
19 잭 스나이더의 저스티스 리그 9.42
20 그대, 고맙소 : 김호중 생애 첫 팬미팅 무비 9.42
21 월-E 9.42
22 보헤미안 랩소디 9.42
23 사운드 오브 뮤직 9.41
24 포레스트 검프 9.41
25 빽 투 더 퓨쳐 9.41
26 위대한 쇼맨 9.41
27 글래디에이터 9.41
28 헬프 9.41
29 인생은 아름다워 9.40
30 타이타닉 9.40
31 매트릭스 9.40
32 살인의 추억 9.40
33 센과 치히로의 행방불명 9.39
34 토이 스토리 3 9.39
35 가나의 혼인잔치: 언약 9.39
36 헌터 킬러 9.39
37 캐스트 어웨이 9.38
38 집으로... 9.38
39 아이즈 온 미 : 더 무비 9.38
40 반지의 제왕: 왕의 귀환 9.38
41 죽은 시인의 사회 9.38
42 히든 피겨스 9.38[실습 3] mongoDB에 사람 정보 넣고 제어해보기 (클라우드 기반 mongoDB Atlas 사이트 사용)
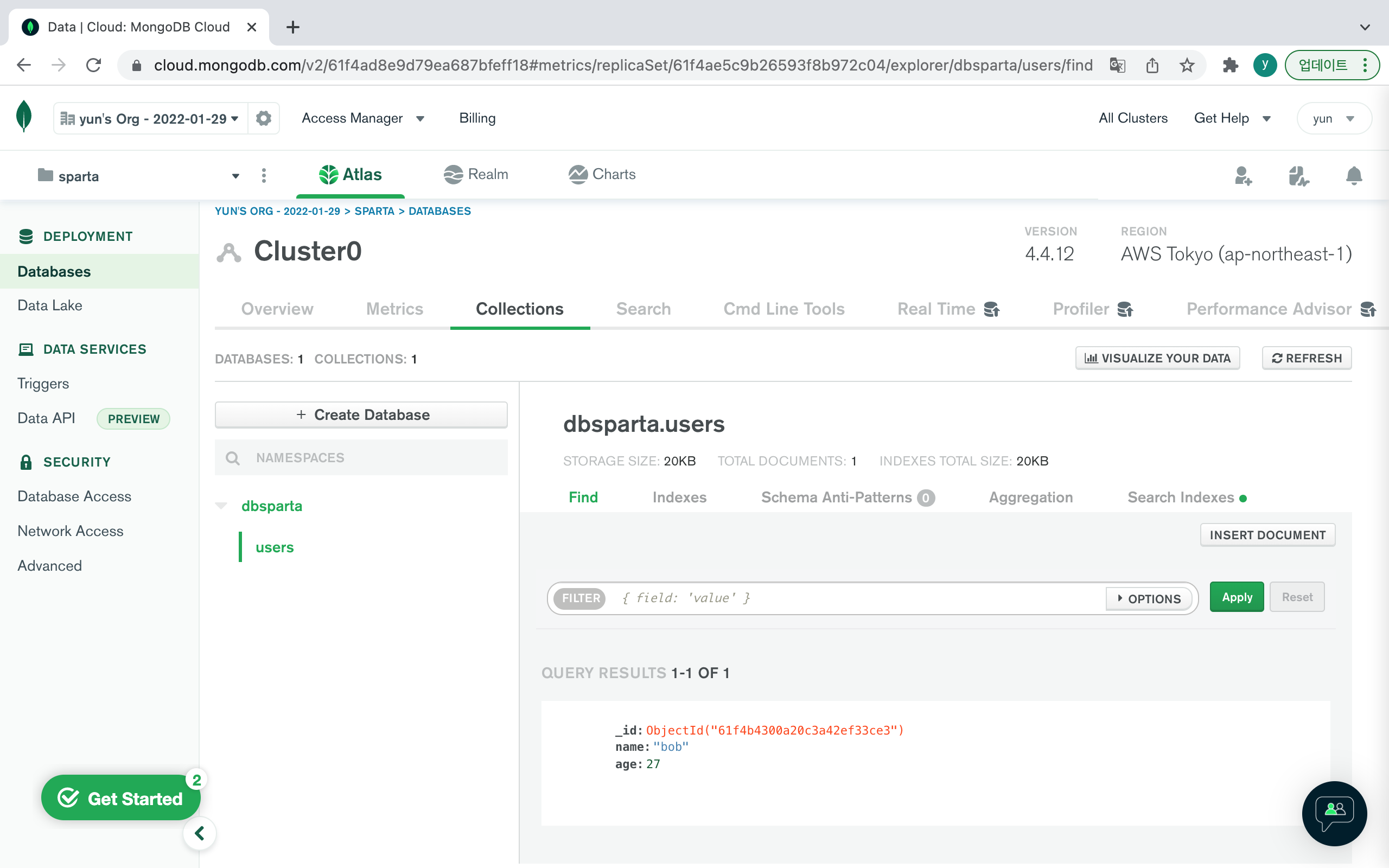
- pymongo 라이브러리 - 기본 CRUD 함수
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})[실습 4] mongoDB에 영화 정보 넣고 제어해보기 (클라우드 기반 mongoDB Atlas 사이트 사용)
💻 [3주차 과제] 지니뮤직 크롤링
- 과제 개요
- 지니뮤직 사이트에서 웹 스크래핑해서 순위 / 곡제목 / 가수 정보만 가져오기
BeautifulSoup사용해서 적절히 파싱 !
- 수행 과정
- 해당 url에
request.get해서 얻은 html 텍스트 데이터로부터soup = BeautifulSoup(data.text, 'html.parser')할당해 웹스크래핑한 정보를 활용했다. - 이후, 웹사이트 > 검사 > 해당 Elements에서 Copy > Copy selector 한 내용 살펴보며,
soup.select('selector')&soup.select_one('selector')활용해 파싱했다. - 출력을 찍어보며 strip(), split(), 인덱싱 등 추가 활용했다.
- (❌) 문제 및 해결 과정
-
저스틴비버의 'Peaches' 곡의 경우 빈 줄이 함께 출력되는 문제를 발견했다.

-
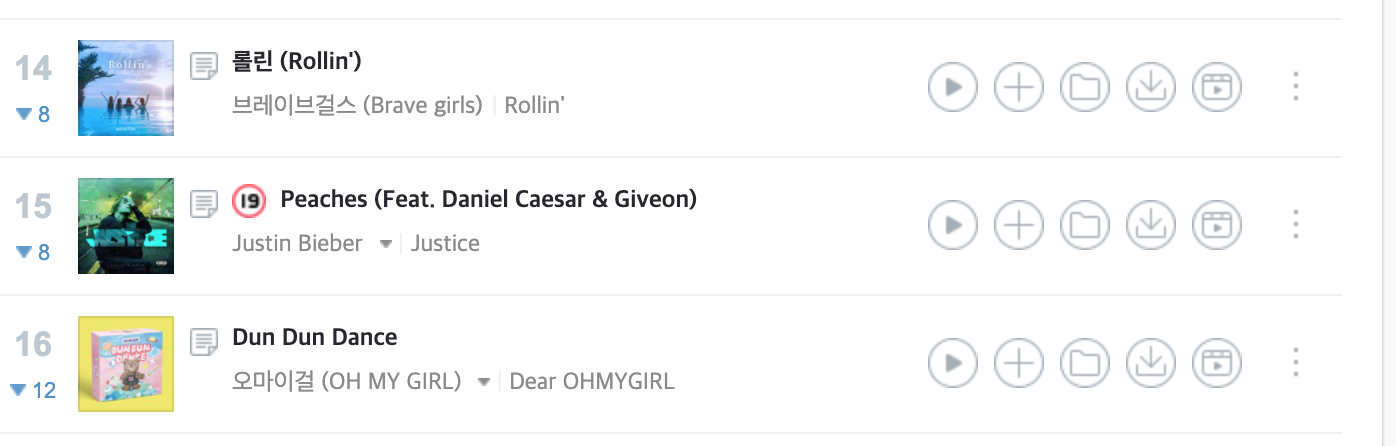
-
곡제목 앞에 붙은 19 표시 때문이었다.
-
➡ 곡제목의
.text결과에서는, 개행 기준으로.split('\n')해주고 리스트의 가장 마지막 요소(-1)만 인덱싱 해주어 원하는 값을 추출했다.
- 완성 🌟
- 출력 결과
/Users/hyun/Desktop/sparta/frontend/pythontrack/venv/bin/python /Users/hyun/Desktop/sparta/frontend/pythontrack/venv/genie.py
1 바라만 본다 MSG워너비 (M.O.M)
2 Next Level aespa
3 신호등 이무진
4 Weekend 태연 (TAEYEON)
5 치맛바람 (Chi Mat Ba Ram) 브레이브걸스 (Brave girls)
6 Butter 방탄소년단
7 나를 아는 사람 MSG워너비 (정상동기)
8 Permission to Dance 방탄소년단
9 비 오는 날 듣기 좋은 노래 (Feat. Colde) 에픽하이 (EPIK HIGH)
10 헤픈 우연 헤이즈 (Heize)
11 하루만 더 빅마마 (Big Mama)
12 비와 당신 이무진
13 Alcohol-Free TWICE (트와이스)
14 롤린 (Rollin') 브레이브걸스 (Brave girls)
15 Peaches (Feat. Daniel Caesar & Giveon) Justin Bieber
16 Dun Dun Dance 오마이걸 (OH MY GIRL)
17 Dynamite 방탄소년단
18 라일락 아이유 (IU)
19 안녕 (Hello) 조이 (JOY)
20 추적이는 여름 비가 되어 장범준
21 운전만해 (We Ride) 브레이브걸스 (Brave girls)
22 Celebrity 아이유 (IU)
23 러브 (Prod. by 로코베리) 로꼬 & 이성경
24 Bad Habits Ed Sheeran
25 상상더하기 MSG워너비
26 ASAP STAYC (스테이씨)
27 상상더하기 라붐 (LABOUM)
28 밤이 되니까 원슈타인
29 Timeless SG워너비
30 좋아좋아 조정석
31 Savage Love (Laxed - Siren Beat) (BTS Remix) Jawsh 685 & Jason Derulo & 방탄소년단
32 다정히 내 이름을 부르면 경서예지 & 전건호
33 내 손을 잡아 아이유 (IU)
34 사이렌 Remix (Feat. UNEDUCATED KID & Paul Blanco) 호미들
35 At My Worst Pink Sweat$
36 작은 것들을 위한 시 (Boy With Luv) (Feat. Halsey) 방탄소년단
37 OHAYO MY NIGHT 디핵 (D-Hack) & PATEKO
38 가을 우체국 앞에서 김대명
39 나는 너 좋아 장범준
40 멜로디 ASH ISLAND
41 Blueming 아이유 (IU)
42 밝게 빛나는 별이 되어 비춰줄게 송이한
43 에잇 (Prod. & Feat. SUGA of BTS) 아이유 (IU)
44 2002 Anne-Marie
45 LOVE DAY (2021) (바른연애 길잡이 X 양요섭, 정은지) 양요섭 & 정은지
46 아로하 조정석
47 흔들리는 꽃들 속에서 네 샴푸향이 느껴진거야 장범준
48 이제 나만 믿어요 임영웅
49 낙하 (With 아이유) AKMU (악뮤)
50 Off My Face Justin Bieber
종료 코드 0(으)로 완료된 프로세스
- Code
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
####print(soup)
# 1. 순위
# #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number
# 2. 곡 제목
# #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis
# 3. 가수
# #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis
musics = soup.select('#body-content > div.newest-list > div > table > tbody > tr') ## (주의!) tr 까지만 select 해줘야 함
for elem in musics:
if elem is None: ## (방어 코드)
continue
# 1번.
rank_pre = elem.select_one('td.number')
rank = list(rank_pre.text.strip().split('\n'))
####print(rank[0])
# 2번.
title_pre = elem.select_one('td.info > a.title.ellipsis')
####print(list(title_pre.text.split('\n'))) ## 결과 : ['19금', ' ', ' ', ' ', ' ', ' Peaches (Feat. Daniel Caesar & Giveon)']
title_list = list(line.strip() for line in list(title_pre.text.split('\n')))
####print(title_list) ## 결과 : ['', '19금', '', '', '', '', 'Peaches (Feat. Daniel Caesar & Giveon)']
title = title_list[-1]
# 3번.
artist_pre = elem.select_one('td.info > a.artist.ellipsis')
artist = artist_pre.text.strip()
####print(artist)
print(rank[0], title, artist)

AI, Big Data, Industrial Engineering