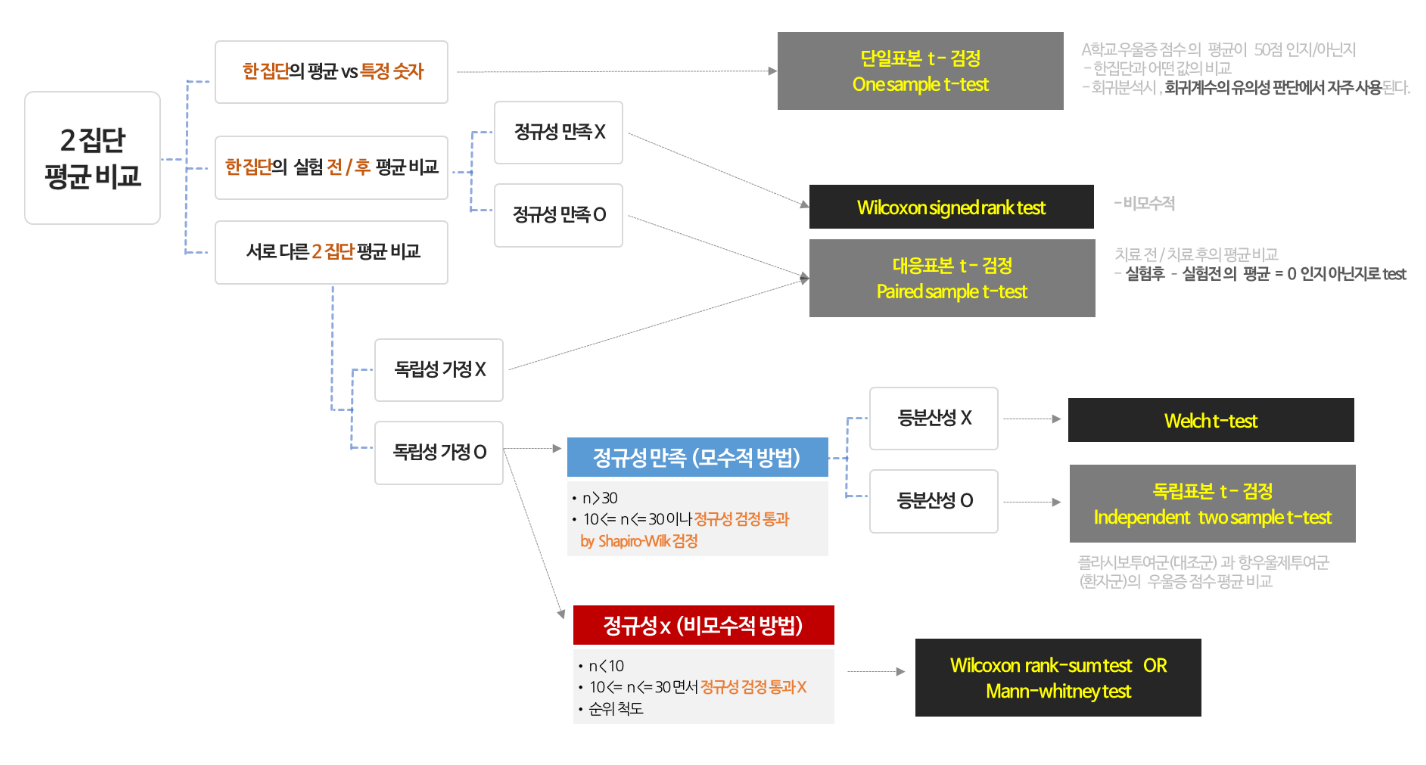
📃T-test 검정 로드맵
출처 : https://nittaku.tistory.com/459
독립성 검정(test of independence) : 서로 다른 요인들에 의해 분할되어 있는 경우 그 요인들이 관찰값에 영향을 주고 있는지 아닌지, 요인들이 서로 연관이 있는지 없는지를 검정. 두 개의 요인을 대상으로 함.
T-test 를 검정하기 전에 정규성과 등분산성을 만족하는지를 확인한다.
python 에서는 해당 검정을 도와주는 함수가 존재하는데 scipy.stats 라이브러리가 제공해준다. 그에 해당하는 함수는 아래에 적어놓았다.
📖shapiro(x)
정규성 확인 함수
pvalue 가 0.05 초과하면 만족한다.
반환값 : statistic 와 pvalue 를 반환한다.
📖levene(*samples, center='median', proportiontocut=0.05)
등분산성 검정하는 levene 검정 수행, 모수 검정 시 사용
Levene 테스트는 모든 입력 샘플이 분산이 동일한 모집단에서 추출된다는 귀무 가설을 테스트합니다. bartlettLevene의 검정은 정규성에서 상당한 편차가 있는 경우 Bartlett 검정의 대안입니다 .
- pvalue 가 0.05 초과하면 만족한다.
- 반환값 : statistic 와 pvalue 를 반환한다.📝모수 : 확률을 표현한, 대표적인 연속확률분포이며, 세상의 모든 현상을 설명하는 정규분포를 대표하는 값은 평균과 분산입니다.
이 평균과 분산을 통계에서는 모수(parameter)라 부릅니다.
📖bartlett(*samples)
등분산에 대한 Bartlett 검정을 수행합니다, 비모수 검정 시 사용하며
Bartlett의 테스트는 모든 입력 샘플이 분산이 동일한 모집단에서 추출된다는 귀무 가설을 테스트합니다. 상당히 비정규 모집단의 표본에 대해서는 Levene의 검정이 levene더 강력합니다.
- pvalue 가 0.05 초과하면 만족한다.
- 반환값 : statistic 와 pvalue 를 반환한다.📝비모수 : 비모수는 데이터가 정규분포가 아니며 데이터의 표본 수가 적거나 부족하고 데이터가 서로 독립적인 경우입니다.
❗두 집단의 정규성과 등분산성을 검정하여 만족하는지 않하는지에 따라 검정 방법이 달라지게 된다.
📖정규성O, 등분산성O -> independent two sample t-test 진행
scipy.stats.ttest_ind(a, b, axis=0, equal_var=True, nan_policy='propagate', permutations=None, random_state=None, alternative='two-sided', trim=0)두 개의 독립적인 점수 샘플의 평균 에 대한 T-검정을 계산합니다 .
이것은 2개의 독립적인 표본이 동일한 평균(예상) 값을 갖는다는 귀무 가설에 대한 검정입니다. 이 테스트는 기본적으로 모집단의 분산이 동일하다고 가정합니다.
- 반환값 : statistic 와 pvalue 를 반환한다.
📖정규성을 만족하지 못할 경우
2가지의 검정방법으로 나누어지는데 wilcoxon() 과 mannwhitneyu() 이다.
📖wilcoxon()
scipy.stats.wilcoxon(x, y=None, zero_method='wilcox', correction=False, alternative='two-sided', method='auto', *, axis=0, nan_policy='propagate', keepdims=False)
- 두 집단의 크기가 같을 경우 wilcoxon 검정을 진행한다.
Wilcoxon 부호 순위 검정은 두 개의 관련 쌍 표본이 동일한 분포에서 나온다는 귀무 가설을 검정합니다. 특히 차이의 분포가 0에 대해 대칭인지 테스트합니다. 이는 paired T-test의 비모수적 버전입니다.x - y
📖mannwhitneyu()
scipy.stats.mannwhitneyu(x, y, use_continuity=True, alternative='two-sided', axis=0, method='auto', *, nan_policy='propagate', keepdims=False)
- 두 집단의 크기가 같을 경우 mannwhitneyu 검정을 진행한다.
Mann-Whitney U 테스트는 샘플 x 의 기본 분포가 샘플 y 의 기본 분포와 동일하다는 귀무 가설의 비모수 테스트입니다 . 분포 사이의 위치 차이 테스트로 자주 사용됩니다.
📌서로 대응인 두 집단(동일집단)의 평균 차이 검정(paired samples t-test)
처리 이전과 처리 이후를 각각의 모집단으로 판단하여, 동일한 관찰 대상으로부터 처리 이전과 처리 이후를 1:1로 대응시킨 두 집단으로 부터
의 표본을 대응표본(paired sample)이라고 한다.
대응인 두 집단의 평균 비교는 동일한 관찰 대상으로부터 처리 이전의 관찰과 이후의 관찰을 비교하여 영향을 미친 정도를 밝히는데 주로 사용
하고 있다. 집단 간 비교가 아니므로 등분산 검정을 할 필요가 없다.
해당 검정도 scipy 에서 제공해주고 있다.
📖ttest_rel()
scipy.stats.ttest_rel(a, b, axis=0, nan_policy='propagate', alternative='two-sided', *, keepdims=False)점수 a와 b의 두 관련 샘플에 대한 t-검정을 계산합니다.
이것은 두 개의 관련되거나 반복된 표본이 동일한 평균(예상) 값을 갖는다는 귀무가설에 대한 검정입니다.
