Lab-02 Simple Linear Regression LAB
학습 내용
- Gradient descent의 개념
- Gradient descent 알고리즘 tensorflow 로 구현
조건: 단일 variable(x)
Cost function format
hypothesis는 가설함수, 모델이 예측한 가상의 값 자체임, 손실값을 나타내는 것은 cost function임.
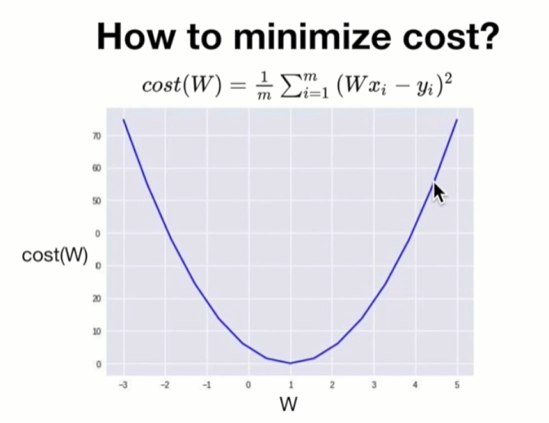

Engineering에서 가장 큰 문제는?
최적화
이때 관여하는 것 = 이득 최대화, 손실 최소화
손실 최소화의 대표적인 알고리즘 = Gradient descent algorithm
Gradient descent algorithm (경사하강 알고리즘)
- 경사 하강 알고리즘은 비용 함수(cost function) J(θ(0),θ(1))를 최소화 하는 θ를 구하는 알고리즘.

- := : 대입 연산자
θ 값을 갱신한다는 의미. - 'α 뒤에 곱해져있는 것': 비용 함수 J의 미분값.
- α : learning rate
갱신되는 θ 값의 속도.
아무리 미분값이 크더라도 α가 작다면 갱신되는 속도가 느려짐.
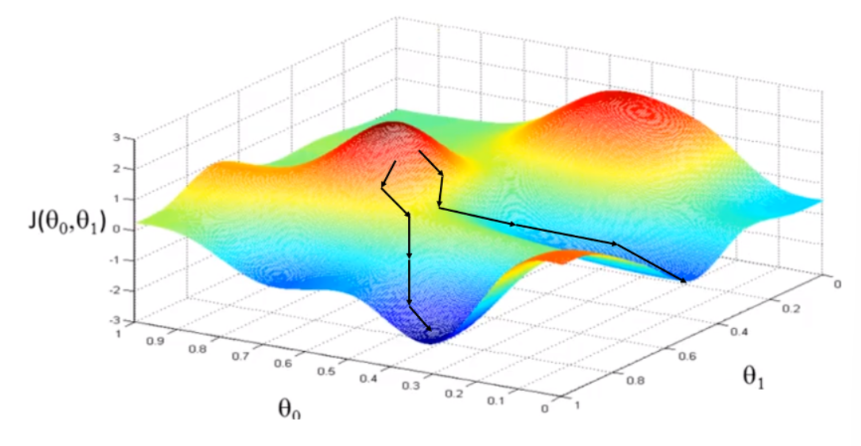
Gradient descent algorithm의 동작과정
-
start at 0,0 (or any other value)
θ에 대해 임의의 초기값, 즉 시작점을 잡는다. -
Update = W와 b값은 cost(w,b)가 줄어들 수 있는 방향으로 지속적으로 바뀜.
-
최소점(=local minimum)에 도달할 때까지 반복
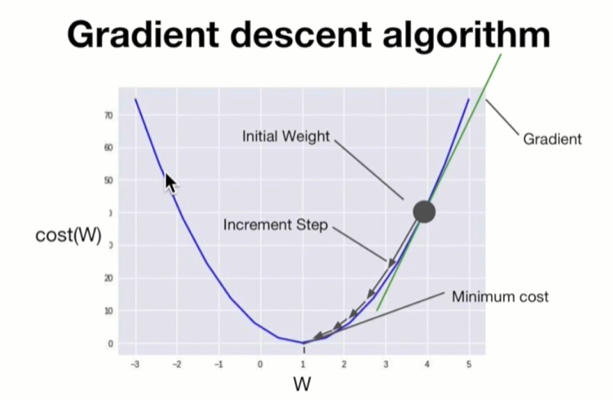
Gradient descent formal definition
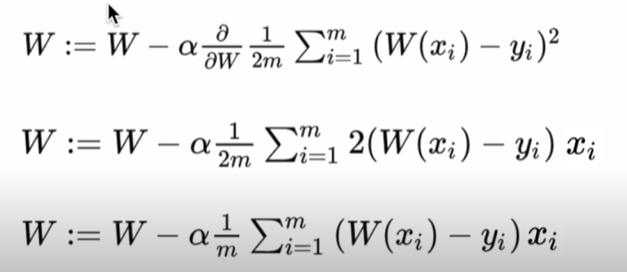
-> alpha = learining rate
학습의 수렴속도를 결정하는 요소
이해 안 된 부분:
cost function format에서(강의 13분)
cost function을 W로 미분할 때, 굳이 2로 나누어줄 필요가 없다. 2로 나누어주면 궁극적으로 alpha 값을 2로 나누어준 결과가 되기 때문 ??

veloger