Deep Learning Zero To All
1.[모두를 위한 딥러닝] #01-03. ML 용어 정리 및 Simple linear regression_2022.05.02

SUPERVISED LEARNING레이블이 정해져있음 = 학습 데이터이 supervised learning은 크게 두가지 문제로 분류된다.UNSUPERVISED LEARNING일일히 우리가 레이블 주기 어려운 경우가 있음, 또는 비슷한 단어들이 모아져있고 그에 대해
2.[모두를 위한 딥러닝] #04-05. Simple Linear Regression LAB_2022.05.05
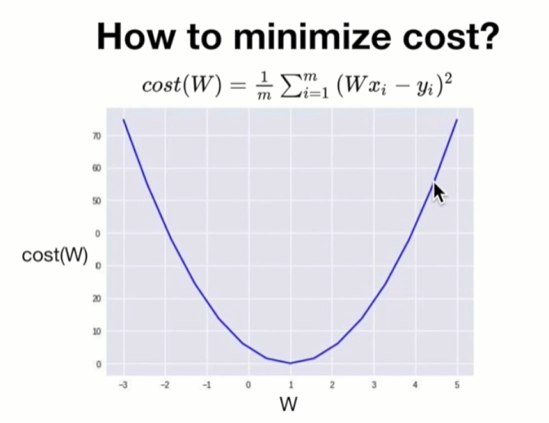
Gradient descent 알고리즘 tensorflow 로 구현아래 코드로 대체https://colab.research.google.com/drive/1UMlt29PShlFchI1H0iZoTnnkPRAWtbPz
3.[모두를 위한 딥러닝] #07-08. Multi variable linear regression_2022.05.06
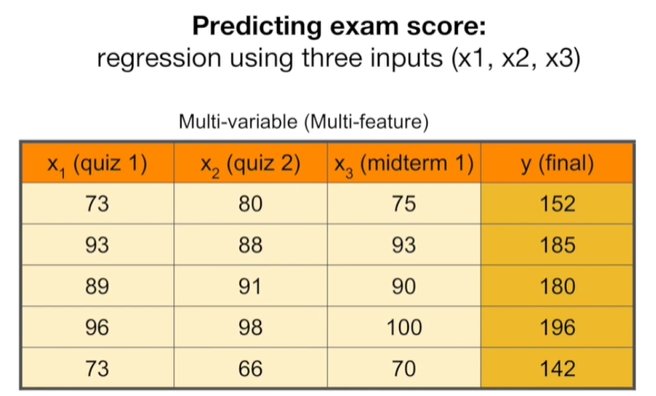
https://colab.research.google.com/drive/1UMlt29PShlFchI1H0iZoTnnkPRAWtbPz변수를 하나만 설정하는 것보다 여러개를 설정했을 때, 결과값을 더 잘 예측할 수 있기 때문에 multi variable linea
4.[모두를 위한 딥러닝] #09-12. Logistic Regression_2022.05.11
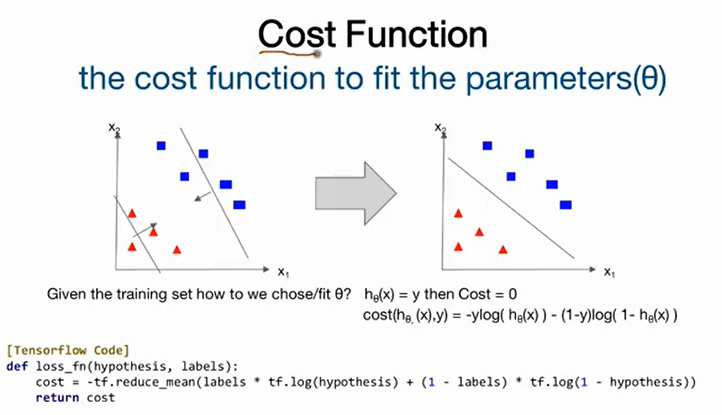
Summary
5.[모두를 위한 딥러닝] #12-15. Softmax Regression_2022.05.12
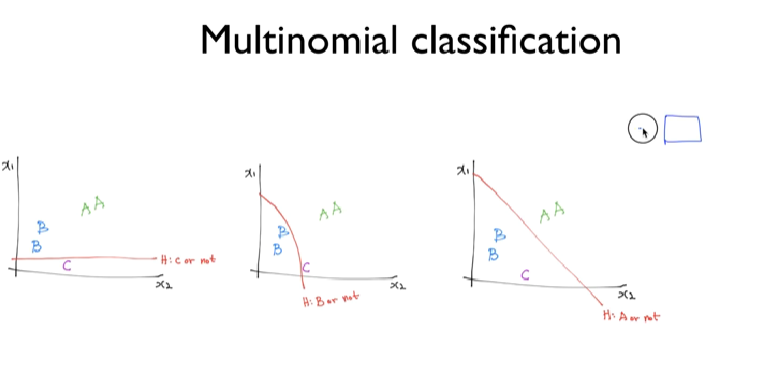
logistic regression에서는 binary classification만 가능했었다.이를 multi class 구분으로 확장하기 위해 사용되는 것이 softmax이다.Cross entropy 에서는 A or B 로 1,0 or 0,1 로써 서로 구분을 하는거지
6.[모두를 위한 딥러닝] #16-20. application and tips_2022.05.24

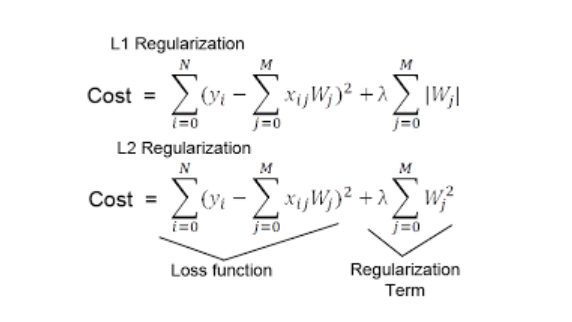
L2 Norm
7.[모두를 위한 딥러닝] #1-20. Summary_[1]BN_ 2022.05.26
Annealing the learning rate (Decay)셋 다 입력값의 범위를 조정함으로써, 모델의 일반화성능을 높이기 위한 방법.Normalization = 입력값(보통 픽셀값의 범위= 0~255)의 범위를 0~1로 조정.Standardization = 입력값
8.[모두를 위한 딥러닝] #1-20. Summary_[2]Optimizer_ 2022.05.26
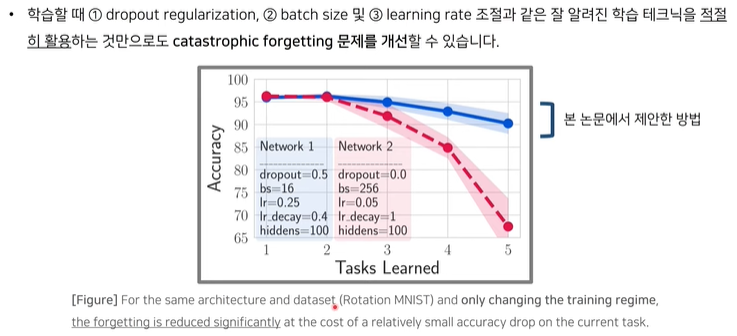
GD (Gradient Descent)단순 GD의 문제점Stable SGD: Understanding the Role of Training Regimes in Continual Learning (NIPS 2020)ex) object detection하나의 입력 -> 여
9.[모두를 위한 딥러닝] #21. 딥러닝의 기본 개념: 시작과 XOR 문제_ 2022.06.01
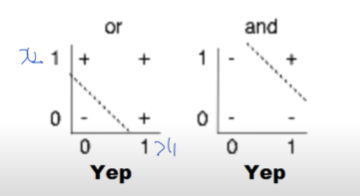
딥러닝은 XOR문제에서 답을 선형적으로 구분하는 Line을 찾으려는 노력에서 시작되었다. AND/OR Problem은 linearly 하게 separate할 수 있는 line이 존재한다.하지만 아래와 같은 XOR문제는 선형방정식으로 풀지 못한다. \-> train 불가
10.[모두를 위한 딥러닝] #23. XOR 문제 logistic regression으로 풀기_ 2022.06.01
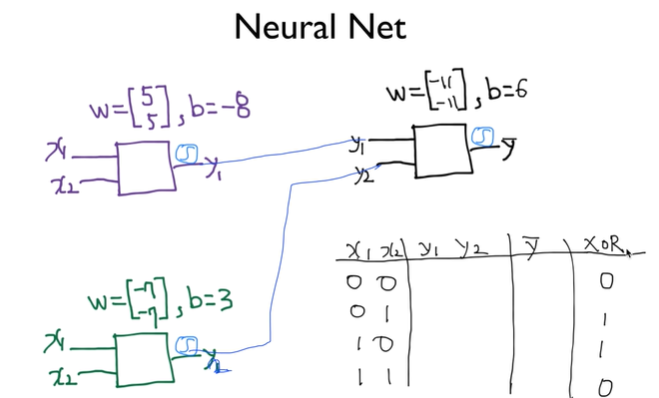
\*각각의 network는 logistic regression이라고 가정.=>
11.[모두를 위한 딥러닝] Backpropagation & Forward 2022.06.01
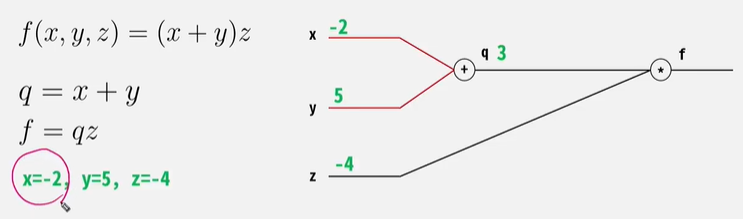
target과 모델이 예측한 값의 차이= loss를 뒤로 전달하면서, 각 node의 weigt를 갱신시켜줌!아무리 깊고 복잡한 층으로 구성되어 있다 하더라도 Chain Rule을 활용하여 미분 값을 얻어낼 수 있다.Forward Pass 시 Local Gradient를
12.[모두를 위한 딥러닝] #Why Relu?(not sigmoid)_ 2022.06.01
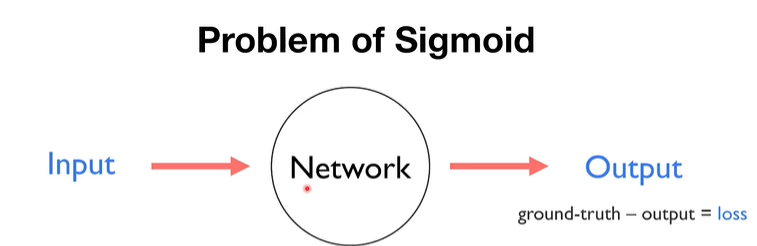
gradient => 그래프로 표현 =>매우 작은 gradient값을 전달받아, 계속 곱해지면서, 결국 값이 손실되는 현상 x가 0보다 크면 gradient는 y=x의 기울기 즉 항상 1이다 = 자기 자신의 값을 갖는다=> 잘 전달됨문제: x가 0보다 크면 gradie
13.[모두를 위한 딥러닝] #Weight Initialization_ 2022.06.01
