
😎 Generative Models를 주제로 Side Project를 수행하는 중입니다.
😁 이에, 관련된 실험 결과를 간단히 정리하려 해요!
Goal
적은 양의 데이터셋으로 적절한 성능으로 이미지를 Generate할 수 있는 생성 모델
학습을 수행하다 보면, 항상 학습 데이터의 imbalance는 마주칠 수 밖에 없는 문제이죠 🤣
특히나, 제조 업계는 더더욱 그렇습니다. 왜냐? 불량 데이터는 정말 없는데 정상 데이터만 한가득이거든요.
불량 데이터 수집을 위해 데이터를 오랜 시간 모으는 일도 비일비재하고, 시간이 부족하여 imbalanced dataset으로 학습한 모델이 성능도 안나오는 경우도 흔하죠.
이를 위해, 초 대형 데이터셋이 아니어도 학습을 위한 적절한 수준의 데이터셋을 생성할 수 있는 생성 모델 학습을 해내는 것이 목표입니다.
(D/L 모델 학습에 사용할 예정이기 때문에, 현실적으로 가능한 256 * 256 * 1 / 256 * 256 * 3 shape 이미지 생성을 목표로 합니다.)
Generative Model Serving 구축
적절한 모델이 학습되었다고 하여, 이것을 그대로 각자 사용할 수는 없지요.
Model Serving(inference) 및 새 데이터가 들어왔을 때 추가 학습(train)을 위한 웹 서비스를 구축해내는 것이 또 하나의 목표입니다.
Dataset?
Kaggle의 GC10-DET Dataset을 제일 먼저 활용했어요.
이 데이터셋이 현업 사용 제조 데이터셋과 가장 유사한 오픈 데이터셋으로 보여서요 :)
현재 학습시는 일단 4번 Label만 사용하여 학습을 진행하였고 (Uncoditional GAN) 추후 cGAN 기반 모델을 학습한다면, 전체 데이터셋을 사용할 수도 있을 것 같아요!


(데이터 크기가 약 2000 * 1000 으로 꽤나 거대해서, 256 * 256으로 resize하여 사용할 예정이에요.)
그 외, Pokemon dataset도 활용하였습니다.


(피카츄는 귀여워요!)
https://www.kaggle.com/datasets/kvpratama/pokemon-images-dataset
Model?
GAN 기반 모델 활용
Valina GAN / LSGAN / DCGAN 등의 기본 형태 모델을 사용하였으나, (아시다시피) 성능 기대치가 낮은 모델이어서 학습이 정상적으로 수행됨 까지만 확인하였어요.
GAN : https://arxiv.org/abs/1406.2661
LSGAN : https://arxiv.org/pdf/1611.04076.pdf
DCGAN : https://arxiv.org/pdf/1511.06434.pdf
워낙 유명한 개념이기 때문에, GAN의 기본 설명 및 컨셉은 아래 링크를 따라가시면 쉽게 이해할 수 있을거에요 :)
https://pseudo-lab.github.io/Tutorial-Book/chapters/GAN/Ch1-Introduction.html
StyleGAN2 + ADA
GAN의 History의 골자가 되는 중요한 논문들이 너무나 많지만, 해당 설명은 추후에 진행하는 것으로 하죠. :)
일단은 현재 가지고 있는 데이터셋 기반으로 성능이 얼마나 나오는지 확인하기 위해, 현재 사용 가능한 환경 (T4 GPU 1장, colab) 하에서 사용 가능하고, 성능도 나쁘지 않은 알고리즘을 선정했어요.
StyleGAN2 + ADA : https://github.com/NVlabs/stylegan2-ada-pytorch
GAN 아키텍처는 성능이 뛰어나다고 알려져 있는 StyleGAN2을 차용했고, 더하여 Discriminator의 학습시 Overfitting을 방지하여 성능을 올린 학습 방식이 ADA (Adaptive Discriminator Augmentation) 이에요.
간단히 말하면, 학습 / 추론시 모두 Augmentation을 적용하여 Discriminator의 빠른 Overfitting을 방지하고 이를 통해 Generator가 더욱 잘 학습될 수 있게 돕는다고 생각해 주시면 될 것 같아요.
또한, Augmentation을 강하게 줌으로써, 기존 GAN 학습시 필요했던 Dataset보다 적은 양의 Data (약 1k) 정도로도 학습이 진행되는 모습을 보여주었지요.
데이터 양이 적은 상황에서 Generative Model을 생성해야 하는 현재 상황에 유용한 기법이에요 :)
Training Generative Adversarial Networks with
Limited Data : https://arxiv.org/pdf/2006.06676.pdf
😎 자, 그러면 데이터셋도 찾고, 알고리즘도 선정했고, Implementation 코드까지 확보하였으니 성능을 한번 확인하러 가시죠!
Experiment!
Train
실험 환경 : T4 GPU 1장 (VRAM 16GB) / Python 3.7.14 / cuda v11.2
Dataset 확보
학습을 위해서는, dataset을 zip 파일로 묶어주는게 필요해요.
(설명에서는 folder도 지원한다고 써있지만 저는 에러가 나서..)
import os
# Google Drive 이하 data Path
train_data_dir = '/content/drive/MyDrive/GAN_때문이야/dataset/4'
os.environ['train_data_dir'] = train_data_dir
# Google Drive 이하에 해당 zip으로 묶인 256x256 데이터셋을 저장해줍니다.
!python dataset_tool.py --source=$train_data_dir --dest=/content/stylegan2-ada-pytorch/metal256x256.zip --width=256 --height=256학습
실험 cfg1 : --cfg=paper256 --gpus=1 --kimg=1000
실험 cfg2 : --cfg=auto --gpus=1 --kimg=1000
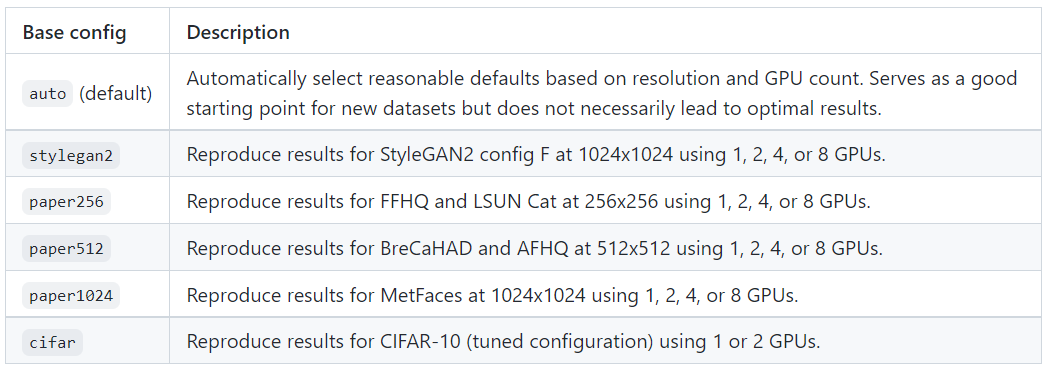
config의 설명은 아래와 같습니다! 😋
그리고, train run!
os.environ['model_save_dir'] = model_save_dir
!python train.py --outdir=$model_save_dir --data=/content/stylegan2-ada-pytorch/metal256x256.zip --cfg=paper256 --gpus=1 --kimg=1000kimg는 학습을 위한 hyperparameter로써 epoch과 비슷한 개념이라고 이해하시면 될 것 같아요.
아래 도표는 V100 기준 kimg에 따른 학습 소요시간이 나와 있어요.
V100(32GB)에 비해서 VRAM이 절반 수준인 T4(16GB)로 학습했기 때문에, 학습 시간이 2배정도 차이가 날 줄 알았는데...! 4배 가까이 차이가 났어요. 😅
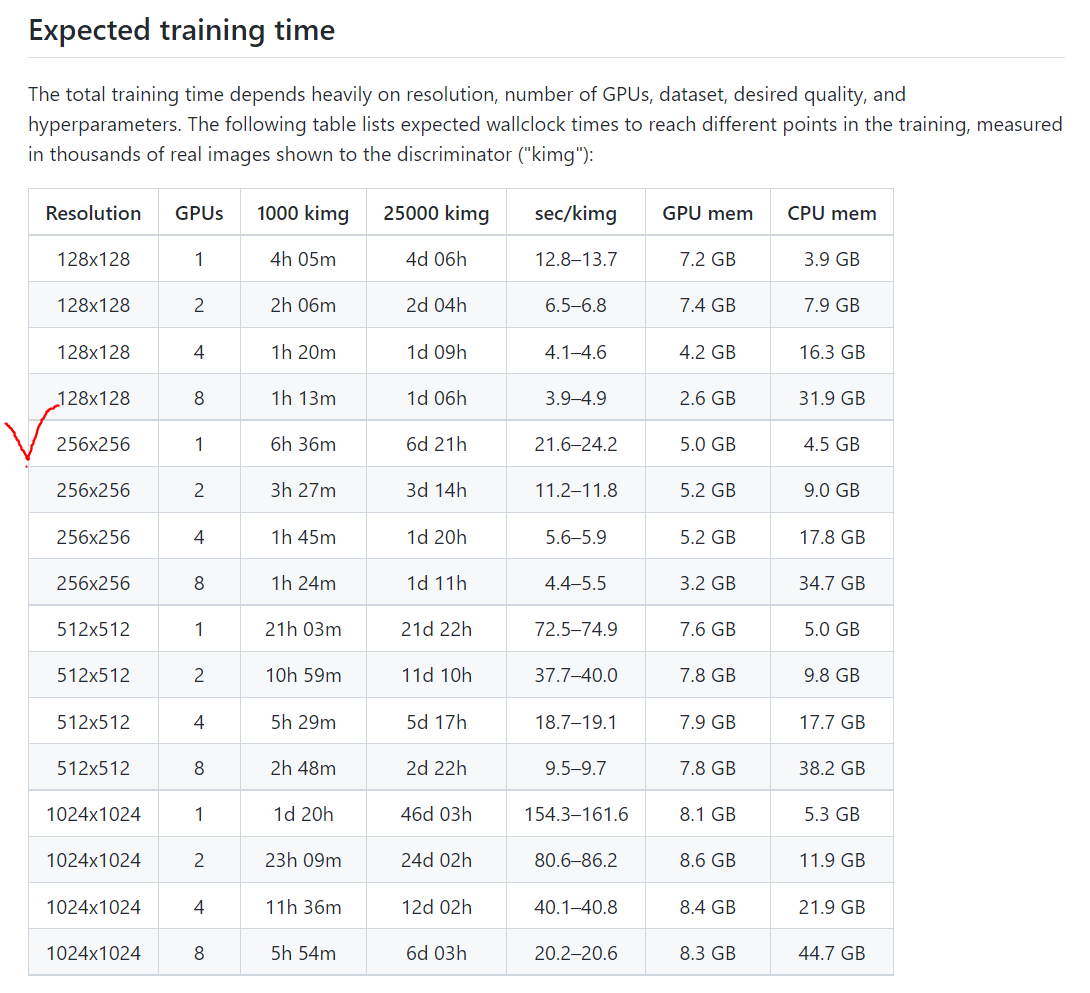
colab session이 아무리 오래 가져가봤자 약 24시간 정도인데, 900 kimg를 채 돌리지 못하고 뻗었어요. 🤣 (이 세션은 심지어 18h 이후에 끊긴 듯.... 😂)

뭐~ 어쨌든! 2개의 config로 1000kimg까지는 돌려보지 못했지만! 약 800kimg까지는 돌려본 모델이 생성이 되었습니다. 😎
그러면, 모델이 Generate한 이미지를 보러 가시죠! 😊
Inference (Generate Image)
추론을 위해서는, 해당 Implementation에서 제공하는 generate.py 스크립트를 실행하면 됩니다!
다만, Grayscale Image에 대해서는 생성시 오류가 발생해요😅😅
이 부분을 위해, gerenerate.py의 아래 부분 수정을 해주세요 😁
# generate.py : line 121
# PIL.Image.fromarray(img[0].cpu().numpy(), 'RGB').save(f'{outdir}/seed{seed:04d}.png') # 주석처리
# 아래 내용으로 수정 (indent 주의)
if img.shape[-1] == 3:
PIL.Image.fromarray(img[0].cpu().numpy(), 'RGB').save(f'{outdir}/seed{seed:04d}.png')
else:
PIL.Image.fromarray(np.squeeze(img[0][:-2].cpu().numpy()), 'L').save(f'{outdir}/seed{seed:04d}.png')좋아요! 그러면 추론 준비가 완료되었어요. 이미지 생성하러 가시죠!
# outdir : generated image 저장 path
# network : 학습된 generator 가중치 path
!python generate.py \
--outdir=/content/drive/MyDrive/GAN_때문이야/model/20221005/00015-metal256x256-auto1-kimg1000/test_gen/out_test_train_t025 \
--trunc=0.25 \
--seeds=$sample_nums \
--network=/content/drive/MyDrive/GAN_때문이야/model/20221005/00015-metal256x256-auto1-kimg1000/network-snapshot-000800.pkl😎 잘 되는군요!

Data Evaluation
real data
아래의 데이터를 256 * 256 으로 변형하여 학습이 진행되었습니다.

변환된 데이터는 아래와 같습니다.




실험 cfg1 : --cfg=paper256 --gpus=1 --kimg=1000


실험 cfg2 : --cfg=auto --gpus=1 --kimg=1000





디테일은 조금 아쉽지만, cfg2에서의 결과는 그래도 슬슬 엇비슷해져가 보이는 것 같네요 😎
마치며
위의 실험을 진행한 colab link입니다 😋
cfg1's colab : https://colab.research.google.com/drive/1BDfVvtQkV2hlNaAUuFs3Gy4m3qEYk3kf?usp=sharing
chf2's colab : https://colab.research.google.com/drive/1BE1bMmL4MQRb6N9AOeRCdziIiWPGRSaV?usp=sharing
😊 생성된 데이터를 봤을 때, 1000kimg까지 정상적으로 학습만 진행된다면, 나쁘지 않은 퀄리티(256 * 256)의 데이터를 생성해내는 것으로 보여요.
😗 다만, 학습용 데이터를 200장 이상 사용한 점 / 학습 시간이 24시간 소요된 점은 개선이 필요해요.
Next!
😉 더 적은 데이터셋으로 안정적인 학습을 해낼 수 있는 부분에 대한 Research가 필요해 보여요.
😎 학습의 수렴이 훨씬 빠르다고 알려진 Projected GAN / 요즘 핫한 Diffusion GAN 또한 적용해 봐야겠어요.
😺 글이 길어져서 pokemon data를 사용한 모델은 다음 글에서 소개하도록 할게요.
😏 그럼, 여기까지 읽어주셔서 감사해요! 다음 글은 더 알찬글로 돌아올게요 :)
