😋 지난 Generative Model 학습 결과에 이어, 이번에는 좀 더 성능이 개선된 결과를 가져왔어요!
😙 여러 알고리즘도 시도해 보았구요. 그럼 한번 보러 가시죠!
(데이터셋 등 기본 세팅은 지난 글과 동일하니, 1편을 참고해 주세요)
Model
Diffusion-GAN
GAN 아키텍처를 좀 더 성능이 뛰어나다고 알려진 Diffusion-GAN 알고리즘으로 변경하여 학습했어요.
Diffusion-GAN의 제일 큰 특징은 이름에서도 알 수 있듯, Diffusion Process를 GAN에 적용했다는 점이에요. 그렇다면, 먼저 Diffusion이 무엇인지 간단하게 정리하고 가시죠.
Diffusion?
Diffusion의 뜻은 '확산' 입니다. Diffusion 계열의 알고리즘은 이름 그대로 '확산'의 개념을 알고리즘에 적용하여 모델을 학습하게 되는데요.
간단히 설명하자면, Diffusion Process는 원본 이미지에 아주 작은 Noise(Gaussian)를 더하게 됩니다. 그리고, 계속해서 time step을 가지고 계속 계속 더해나가죠.
그리고, 수백~수천 회 이를 반복하면 원본 이미지는 결국 Noise 이미지가 됩니다!
이 Noise 이미지를 딥러닝 모델로 다시 복원하는 작업을 진행하게 되지요. 이러한 학습을 반복하게 되면, 결국 특정 Noise를 이 딥러닝 모델에게 던져줄 때 '새로운 이미지를 생성'하게 됩니다.
GAN이랑은 조금 다른 방향성의 생성 모델이에요!
Diffusion 알고리즘의 중요한 점은, '조금씩 바꾼다' 는 점이에요. 마치 향수를 뿌리면, 향수 분자들이 공기 안으로 촥 퍼지는 것처럼요. 그리고! 마치 딥러닝 모델을 학습시키는 건 이 공기중의 향수 분자들을 time step에 따라 조금씩 조금씩 시간을 돌려 '원래 향수가 어떤 존재였는지'를 복원하는 것이라고 볼 수 있어요!
이 원본 이미지에 더해주는 Noise가 Gaussian인 것도, 이러한 공기중의 분자 퍼짐이 아주 작은 time step별로 나누었을 때 Gaussian을 따르더라! 라는 사실을 기반으로 모델링한 것이라고 해요. 이 부분이 아주 저도 흥미로웠어요 :)

위의 고양이 사진을 예시로 들면, 오른쪽으로 향하는 화살표가 고양이 사진에 Noise를 더하는 것이에요. 반대로 왼쪽으로 향하는 화살표는 Noise에서 고양이를 복원하는 것이구요. 학습이 잘 된다면, 특정 Noise를 던졌을 때, 세상에 없는 귀여운 고양이를 생성해낼거에요!
위 설명한 내용은 아래 두 논문을 간단히 설명한 것이고, 구현체 링크도 함께 달아둘게요. 😎
Denoising Diffusion Probabilistic Models : https://arxiv.org/abs/2006.11239
Diffusion Models Beat GANs on Image Synthesis : https://arxiv.org/abs/2105.05233
Guided Diffusion (구현체) : https://github.com/openai/guided-diffusion
그리고, Diffusion 계열의 생성 모델은 GAN 계열 생성 모델보다 고품질의 이미지 데이터를 생성해내며, 덜 Overfitting 된다고 알려져 있어요.
와~ 그럼 Diffusion과 GAN 두개를 합친건가?
😏 맞아요! 아주 추리력이 예리하시군요.
하지만 Diffusion Process의 모든 것과 GAN을 합쳤다고 보기에는 약간 무리가 있어요.
기본 Structure가 GAN에 기반을 두었기 때문에 Diffusion의 Concept을 GAN에 적용한 것이라고 생각해 주시면 되겠어요!
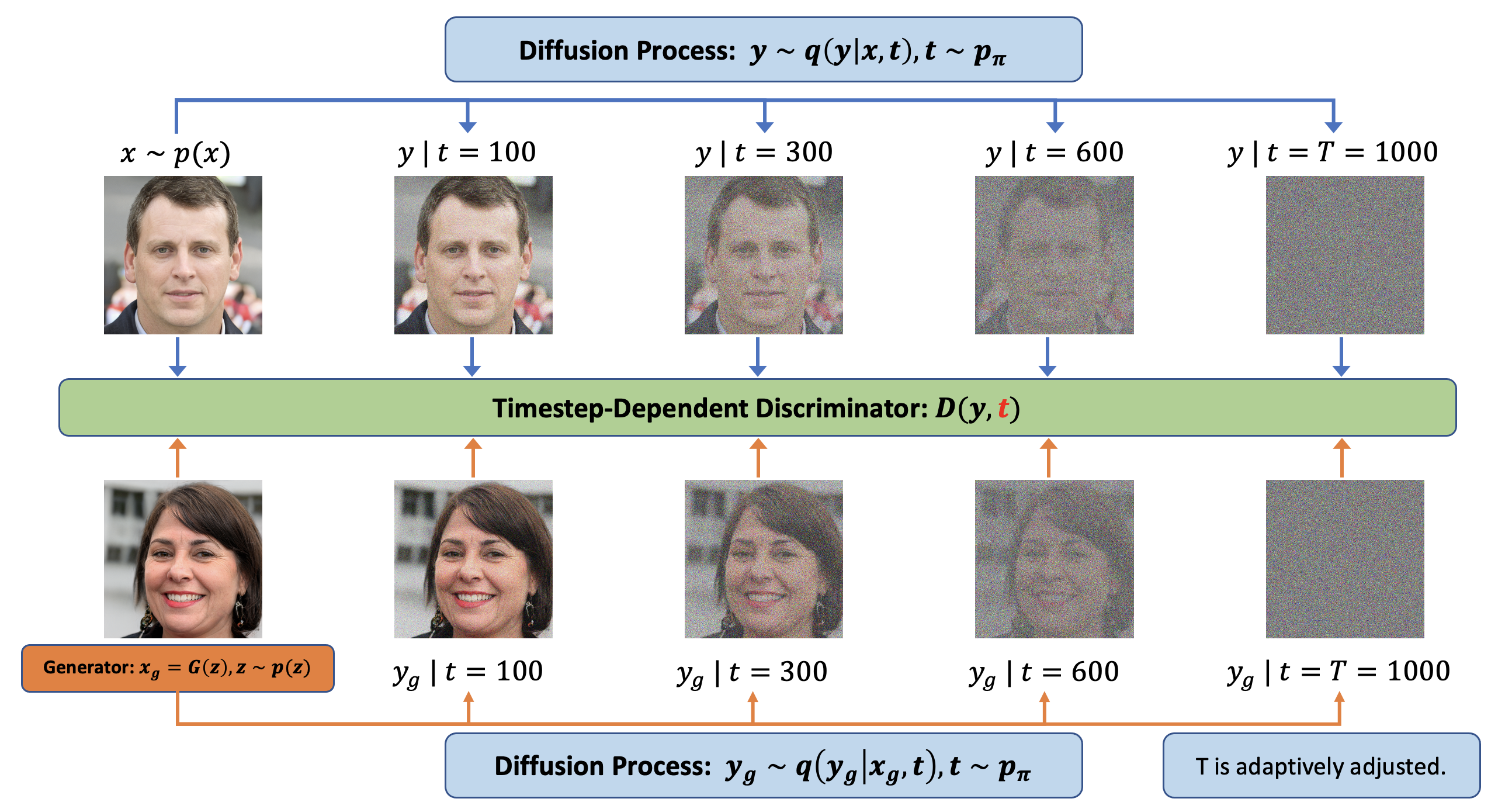
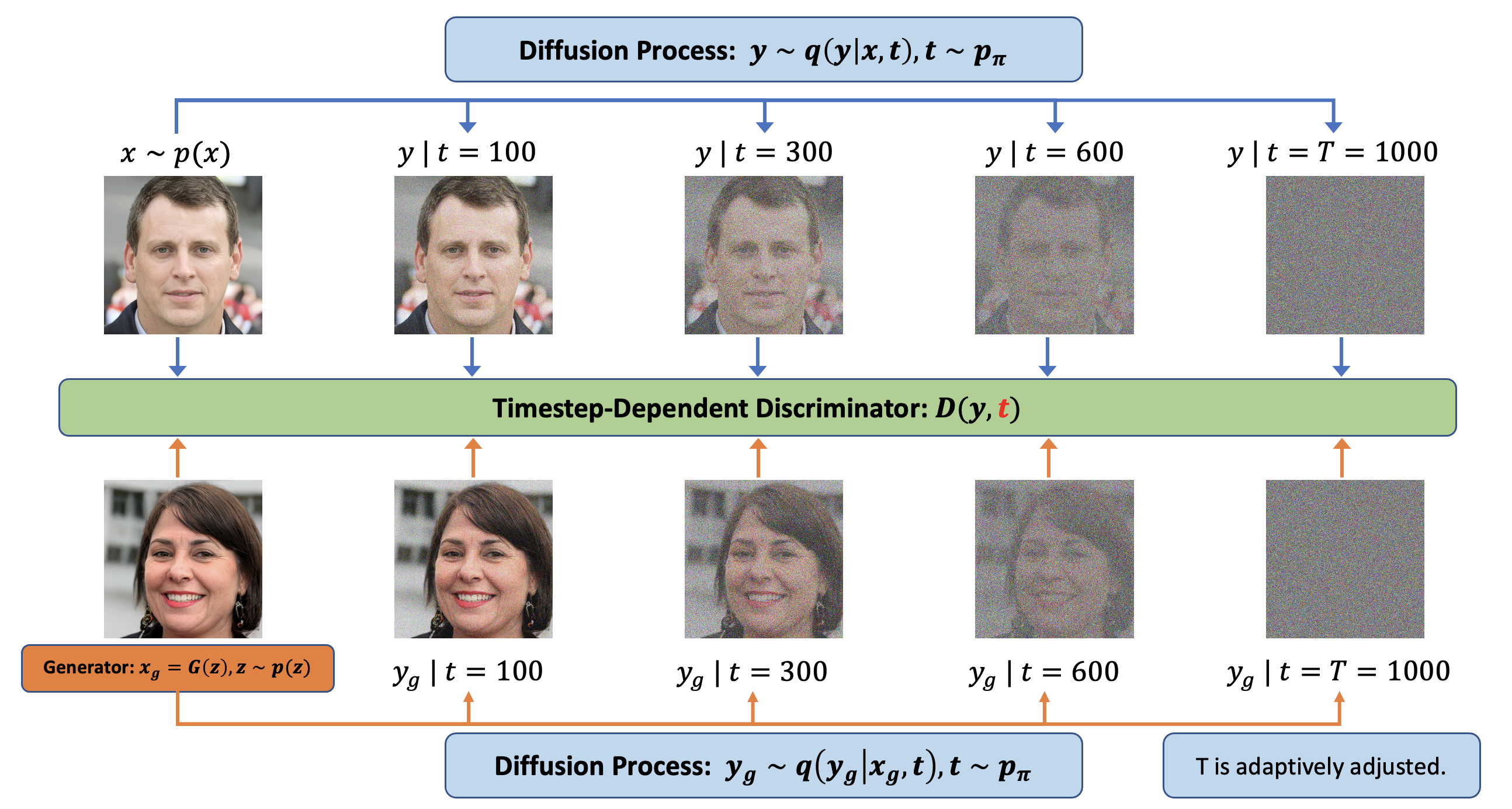
위의 그림이 Diffusion GAN의 거의 모든 내용을 설명하고 있다고 이해하시면 되어요.
가장 큰 차이는 그림과 같이:
1. Discriminator(판별자)의 결과값을 구할때 'Diffusion Process가 적용된 이미지'를 input으로 받음
2. Discriminator(판별자)의 결과값을 구할때 'Diffusion Process의 time step'를 input으로 받음
이에요.
이러한 사용방식은 사실, Diffusion을 일종의 Data Augmentation 방식으로 사용했다고 생각하면 이해가 빠를 것 같아요. 사실 그렇기도 하구요.
이전 글에서 알아봤던 StyleGANv2 + ADA에서 ADA가 Adaptive Data Augment였던 만큼, GAN 모델의 성능을 끌어올리기 위해서는 다양하고 새로운 Augmentation이 많이 적용되는데요. 이러한 Diffusion idea를 GAN에 적용했다고 볼 수 있겠네요.
Diffusion-GAN: Training GANs with Diffusion (https://arxiv.org/pdf/2206.02262.pdf)
Abstract (일부)
A rich set of experiments on diverse datasets show that DiffusionGAN can provide stable and data-efficient GAN training, bringing consistent performance improvement over strong GAN baselines for synthesizing photorealistic images.
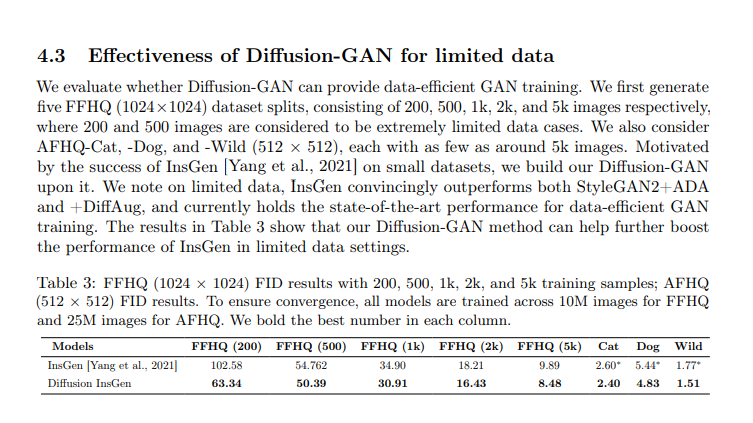
위의 초록 및 결론부에서도 Diffusion GAN에서 특히나 해결하고 싶었던 문제인 Data-Efficient GAN Training에 대해서 좋은 결과를 얻었다고 서술하고 있으며, 제 실험에서도 더 좋게 보입니다 :)
Experiment
Train
실험 환경 : T4 GPU 1장 (VRAM 16GB) / Python 3.7.14 / cuda v11.2
Dataset
학습을 위한 json file을 만들고, 이를 원본 이미지 파일과 함께 zip으로 묶어 dataset을 만들어야 해요 :)
아래 코드는 데이터셋 생성을 위한 dataset.json을 생성하는 과정이에요.
import glob
# train_data_dir이 dataset 가장 상위 폴더
org_td_list = [ele for ele in glob(os.path.join(train_data_dir, '**'), recursive=True) if ele.endswith('.jpg')]
label_list = sorted(os.listdir(train_data_dir), key=lambda x: int(x))
label_dict = {l : int(idx) for idx, l in enumerate(label_list)}
dataset_dict = {}
dataset_dict['labels'] = []
for small_td_path in org_td_list:
label = os.path.basename(os.path.dirname(small_td_path))
label_num = label_dict[label]
tmp_list = [os.path.join(label, os.path.basename(small_td_path)), label_num]
dataset_dict['labels'].append(tmp_list)
import json
with open(os.path.join(train_data_dir, 'dataset.json'), 'w') as f:
json.dump(dataset_dict, f)그리고 이걸 아래 함수로 dataset zip file을 생성해요 😄
!python dataset_tool.py --source=/content/Diffusion-GAN/diffusion-projected-gan/new_dataset/small_train --dest=/content/Diffusion-GAN/diffusion-projected-gan/new_metal_gc10_15_25_org_256x256.zip --resolution=256x256학습
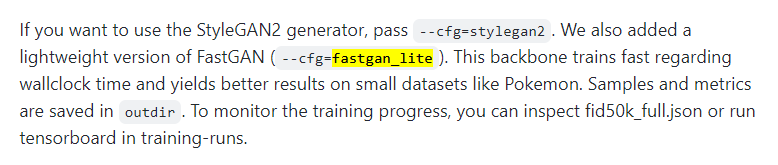
실험 cfg : --cond=True --cfg=fastgan_lite --gpus=1 --kimg=500 --snap=25 --batch=16
backbone은 fastgan_lite를 선택했으며, diffusion-projected-gan을 사용했어요.
backbone의 선택은 Projected-GAN의 구현체의 옵션을 그대로 따라온 것인데요. 아래 논문 기반의 구현체에요.
Projected GANs Converge Faster : https://www.cvlibs.net/publications/Sauer2021NEURIPS.pdf
간단히 Projected-GAN에 대해 설명하자면, 이 알고리즘은 기존의 Discriminator가 학습할 때 물론 pretrained model을 가져와서 학습을 진행하지만, 이게 학습하기가 어렵고 잘 안된다고 주장해요. 그래서, 기존 Discriminator가 단순 classification 모델과 동일한 역할을 했다고 하면, Projected-GAN의 Discriminator는 각 분류의 Layer의 결과값을 1x1 conv하여 D에 전달하거나 (CCM), 3x3 conv하여 D에 전달해요.
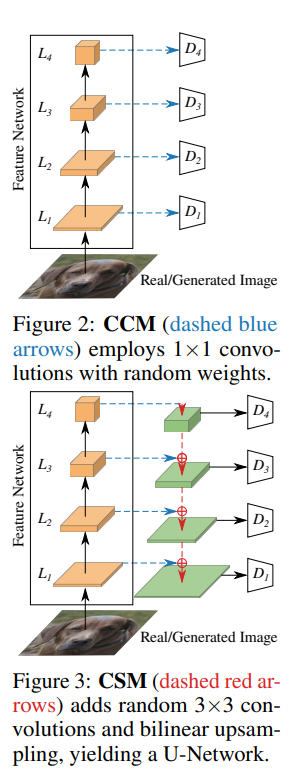
이러한 부분이 GAN 모델의 수렴 속도 및 성능을 크게 향상시켰고, 좋은 결과를 가져왔어요.
실제로 앞서 학습한 StyleGANv2 + ADA 모델보다 실험에서 훨씬 빠르게 수렴함을 보였어요.
fastgan_lite가 pokemon 같이 작은 size의 dataset일 경우 좋은 결과를 가져온다고 설명하고 있어요. 우리 GC10-DET dataset도 그리 양이 많지 않으니 해당 옵션을 차용했어요.
학습 소요시간은 약 10시간정도 소요되었고, FID는 43정도 나오네요.

그럼, 생성된 데이터를 비교해 보죠.
추론 및 비교
Real Image

Generated Image



이제 육안으로 보았을 때는 사실 어느 이미지가 실제 제조 데이터인지 구분이 쉽지 않을 정도에요! 😎
그래서, 이게 실제 학습에 도움이 돼?
이 Imbalanced Dataset을 사용해서 EfficientnetB1 모델을 학습시켜 보았습니다!
모델 학습 스펙은 아래와 같아요 😝
Pytorch 1.7.1 / cuda 11.0
ImageNet Pretrained Model 사용 (Epoch 50)
Augmentation : Flip / RandomResizeCrop
Optimizer : Adam
Lr Scheduler : (7 epoch, 0.1)
Cross-Entropy Loss
Dataset 분류 구조는 아래와 같아요 😄
| Punching Hole | welding line | cresent gap | water spot | oil spot | silk spot | inclusion | rolled out | crease | waist folding | |
|---|---|---|---|---|---|---|---|---|---|---|
| Gen | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 15 | 25 | 20 |
| Train | 155 | 198 | 160 | 211 | 143 | 500 | 152 | 15 | 25 | 100 |
| Val | 44 | 55 | 46 | 58 | 41 | 131 | 44 | 16 | 28 | 30 |
😌 간단히 설명하자면, Gen은 Generative Model을 학습할때 사용한 데이터의 숫자 (Train에서 추출했어요!)
😋 그리고 Train / Val은 분류 모델을 학습하기 위해 사용된 데이터의 숫자에요.
😋 roll_out / crease class가 각각 imbalance한(데이터가 적은) class이구요.
🤗 각각 70장 / 90장을 GAN으로 생성하여 학습 데이터셋에 추가하였어요.
그리고, 그 결과는!!
| Case | Best Validation Set Accuracy | Validation Set F1 Score |
|---|---|---|
| Imbalanced Dataset | 0.835 | 0.832 |
| GAN 생성 데이터 추가 Dataset | 0.859 | 0.8556 |
😎 Validation Set Accuracy / Validation Set F1 Score 모두 상승한 모습을 확인할 수 있습니다!
특히, Data Imbalance로 고통받던
rolled_out class는 6.25% (7/16 → 8/16), crease class는 21% (16/28 → 22/28)로 정합도가 대폭 상승했어요! 🤩
이 부분은 데이터 수집이 어려운 제조 공정, 혹은 다른 도메인에서 GAN으로 생성한 데이터를 사용해 성능을 끌어올릴 수 있다는 말이겠죠!
😝 이렇게 Generative Model로 데이터를 생성하고, 실제 효용성까지 확인해서 뿌듯하네요!
😏 다음에도 재미있는 실험으로 또 새로운 글을 가져와보도록 할게요!
🤗 읽어주셔서 감사합니다!
(참고) 실험에 사용한 colab list
Diffusion-Projected-GAN 학습 : https://colab.research.google.com/drive/1ayEqrOONRGk_i-BlxX48MYO88JG8gQBO?usp=sharing
EfficientnetB1 학습 : https://colab.research.google.com/drive/151o54cHny53tTHDM4Rns5GaZAnQW4nSs?usp=sharing

이해부터 실험까지 잘 설명해주셔서 감사합니다!