
Self-Attention의 시조격이라 할 수 있는 Transformer!
Pytorch 공식 구현체를 분석하며 그 구성을 파악해보도록 하겠습니다. 😎
https://pytorch.org/docs/stable/\_modules/torch/nn/modules/transformer.html#Transformer
Self-Attention
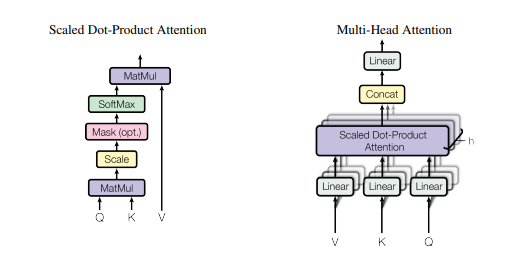
- Self-Attention은 기존의 Weight 기반 Attention에서 한 발짜국 더 나아가, FC 연산만으로도 Attention을 활용하여 더 높은 성능을 가져올 수 있음을 보인 개념입니다.
- NLP에서는 문장 내부의 단어들 간, 조금 더 넓게는 문단 내부의 단어간 상호 관계 및 중요도를 고려야하여 Embedding을 실시하여, 고차원의 manifold에 더 잘 mapping될 수 있게 합니다.
- Vision에서는 이후 ViT 모델이 등장하며 하나의 Image의 각 patch들이 NLP에서의 단어 역할을 하며 local feature에 집중되는 Convolution 연산과 달리, high resolution에서도 큰 그림을 보며 학습할 수 있게 되었습니다.
분석 순서
👀 가장 큰 Module인 nn.Transformer로부터 세부 모듈까지 diggin!
1. Tranformer
2. TransformerEncoder
3. TransformerDecoder
4. TransformerEncoderLayer
5. TransformerDecoderLayer
6. MultiheadAttention
7. multi_head_attention_forward
😁 참고로 모든 소스 코드는 Pytorch 공식 소스코드를 가져왔습니다.
Tranformer
import copy
from typing import Optional, Any, Union, Callable, Tuple
import torch
from torch import Tensor
from .. import functional as F
from .module import Module
from .activation import MultiheadAttention
from .container import ModuleList
from .dropout import Dropout
from .linear import Linear
from .normalization import LayerNorm
from .linear import NonDynamicallyQuantizableLinear
from torch.nn.init import constant_, xavier_normal_, xavier_uniform_
from torch.nn.parameter import Parameter
from .module import Module
__all__ = ['Transformer', 'TransformerEncoder', 'TransformerDecoder', 'TransformerEncoderLayer', 'TransformerDecoderLayer']
class Transformer(Module):
r"""A transformer model. User is able to modify the attributes as needed. The architecture
is based on the paper "Attention Is All You Need". Ashish Vaswani, Noam Shazeer,
Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and
Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information
Processing Systems, pages 6000-6010.
Args:
d_model: the number of expected features in the encoder/decoder inputs (default=512).
nhead: the number of heads in the multiheadattention models (default=8).
num_encoder_layers: the number of sub-encoder-layers in the encoder (default=6).
num_decoder_layers: the number of sub-decoder-layers in the decoder (default=6).
dim_feedforward: the dimension of the feedforward network model (default=2048).
dropout: the dropout value (default=0.1).
activation: the activation function of encoder/decoder intermediate layer, can be a string
("relu" or "gelu") or a unary callable. Default: relu
custom_encoder: custom encoder (default=None).
custom_decoder: custom decoder (default=None).
layer_norm_eps: the eps value in layer normalization components (default=1e-5).
batch_first: If ``True``, then the input and output tensors are provided
as (batch, seq, feature). Default: ``False`` (seq, batch, feature).
norm_first: if ``True``, encoder and decoder layers will perform LayerNorms before
other attention and feedforward operations, otherwise after. Default: ``False`` (after).
Examples::
>>> transformer_model = nn.Transformer(nhead=16, num_encoder_layers=12)
>>> src = torch.rand((10, 32, 512))
>>> tgt = torch.rand((20, 32, 512))
>>> out = transformer_model(src, tgt)
Note: A full example to apply nn.Transformer module for the word language model is available in
https://github.com/pytorch/examples/tree/master/word_language_model
"""
def __init__(self, d_model: int = 512, nhead: int = 8, num_encoder_layers: int = 6,
num_decoder_layers: int = 6, dim_feedforward: int = 2048, dropout: float = 0.1,
activation: Union[str, Callable[[Tensor], Tensor]] = F.relu,
custom_encoder: Optional[Any] = None, custom_decoder: Optional[Any] = None,
layer_norm_eps: float = 1e-5, batch_first: bool = False, norm_first: bool = False,
device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(Transformer, self).__init__()
# custom 여부
if custom_encoder is not None:
self.encoder = custom_encoder
# 없으면 걍 있는 TransformerEncoderLayer 사용
else:
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first, norm_first,
**factory_kwargs)
encoder_norm = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
# 위의 정의된 TransformerEncoderLayer 기반으로 Encoder block 생성
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
# custom 여부
if custom_decoder is not None:
self.decoder = custom_decoder
# 없으면 걍 있는 TransformerDecoderLayer 사용
else:
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first, norm_first,
**factory_kwargs)
decoder_norm = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
# 위의 정의된 TransformerDecoderLayer 기반으로 Decoder block 생성
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
self.batch_first = batch_first
def forward(self, src: Tensor, tgt: Tensor, src_mask: Optional[Tensor] = None, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r"""Take in and process masked source/target sequences.
Args:
src: the sequence to the encoder (required).
tgt: the sequence to the decoder (required).
src_mask: the additive mask for the src sequence (optional). # 마스킹
tgt_mask: the additive mask for the tgt sequence (optional). # 마스킹
memory_mask: the additive mask for the encoder output (optional). # decoder에 전달될 encoding 결과 masking
src_key_padding_mask: the ByteTensor mask for src keys per batch (optional).
tgt_key_padding_mask: the ByteTensor mask for tgt keys per batch (optional).
memory_key_padding_mask: the ByteTensor mask for memory keys per batch (optional).
Shape:
- src: :math:`(S, E)` for unbatched input, :math:`(S, N, E)` if `batch_first=False` or
`(N, S, E)` if `batch_first=True`. # (batch Number, Sequnce number, Embedding)
- tgt: :math:`(T, E)` for unbatched input, :math:`(T, N, E)` if `batch_first=False` or
`(N, T, E)` if `batch_first=True`. # (64, 60, 256)
- src_mask: :math:`(S, S)` or :math:`(N\cdot\text{num\_heads}, S, S)`.
- tgt_mask: :math:`(T, T)` or :math:`(N\cdot\text{num\_heads}, T, T)`.
- memory_mask: :math:`(T, S)`.
- src_key_padding_mask: :math:`(S)` for unbatched input otherwise :math:`(N, S)`.
- tgt_key_padding_mask: :math:`(T)` for unbatched input otherwise :math:`(N, T)`.
- memory_key_padding_mask: :math:`(S)` for unbatched input otherwise :math:`(N, S)`.
Note: [src/tgt/memory]_mask ensures that position i is allowed to attend the unmasked
positions. If a ByteTensor is provided, the non-zero positions are not allowed to attend
while the zero positions will be unchanged. If a BoolTensor is provided, positions with ``True``
are not allowed to attend while ``False`` values will be unchanged. If a FloatTensor
is provided, it will be added to the attention weight.
[src/tgt/memory]_key_padding_mask provides specified elements in the key to be ignored by
the attention. If a ByteTensor is provided, the non-zero positions will be ignored while the zero
positions will be unchanged. If a BoolTensor is provided, the positions with the
value of ``True`` will be ignored while the position with the value of ``False`` will be unchanged.
- output: :math:`(T, E)` for unbatched input, :math:`(T, N, E)` if `batch_first=False` or
`(N, T, E)` if `batch_first=True`. # (batch Number, Target sequence length, Embedding)
Note: Due to the multi-head attention architecture in the transformer model,
the output sequence length of a transformer is same as the input sequence
(i.e. target) length of the decoder.
where S is the source sequence length, T is the target sequence length, N is the
batch size, E is the feature number
Examples:
>>> # xdoctest: +SKIP
>>> output = transformer_model(src, tgt, src_mask=src_mask, tgt_mask=tgt_mask)
"""
is_batched = src.dim() == 3
if not self.batch_first and src.size(1) != tgt.size(1) and is_batched:
raise RuntimeError("the batch number of src and tgt must be equal")
elif self.batch_first and src.size(0) != tgt.size(0) and is_batched:
raise RuntimeError("the batch number of src and tgt must be equal")
if src.size(-1) != self.d_model or tgt.size(-1) != self.d_model:
raise RuntimeError("the feature number of src and tgt must be equal to d_model")
# src, 필요하면 src_mask 까지 함께 전달
memory = self.encoder(src, mask=src_mask, src_key_padding_mask=src_key_padding_mask)
# 결과로 나온 memory도 함께 전달
output = self.decoder(tgt, memory, tgt_mask=tgt_mask, memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
return output
# mask 생성 method
@staticmethod
def generate_square_subsequent_mask(sz: int, device='cpu') -> Tensor:
r"""Generate a square mask for the sequence. The masked positions are filled with float('-inf').
Unmasked positions are filled with float(0.0).
"""
return torch.triu(torch.full((sz, sz), float('-inf'), device=device), diagonal=1)
# xavier로 init
def _reset_parameters(self):
r"""Initiate parameters in the transformer model."""
for p in self.parameters():
if p.dim() > 1:
xavier_uniform_(p)
# module deepcopy하여 N개만큼 modulelist에 넣어줌
def _get_clones(module, N):
return ModuleList([copy.deepcopy(module) for i in range(N)])
TransformerEncoder
# line 70
class TransformerEncoder(Module):
r"""TransformerEncoder is a stack of N encoder layers. Users can build the
BERT(https://arxiv.org/abs/1810.04805) model with corresponding parameters.
Args:
encoder_layer: an instance of the TransformerEncoderLayer() class (required).
num_layers: the number of sub-encoder-layers in the encoder (required).
norm: the layer normalization component (optional).
enable_nested_tensor: if True, input will automatically convert to nested tensor
(and convert back on output). This will improve the overall performance of
TransformerEncoder when padding rate is high. Default: ``True`` (enabled).
Examples::
>>> encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8)
>>> transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=6)
>>> src = torch.rand(10, 32, 512) # source seq length, bs, emb
>>> out = transformer_encoder(src)
"""
__constants__ = ['norm']
# 기본적으로 __init__은 설정값 초기화 수행
def __init__(self, encoder_layer, num_layers, norm=None, enable_nested_tensor=True, mask_check=True):
super(TransformerEncoder, self).__init__()
self.layers = _get_clones(encoder_layer, num_layers) # layer 복사해서 list 안에 넣어주기
self.num_layers = num_layers
self.norm = norm
self.enable_nested_tensor = enable_nested_tensor
self.mask_check = mask_check
def forward(self, src: Tensor, mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r"""Pass the input through the encoder layers in turn.
Args:
src: the sequence to the encoder (required).
mask: the mask for the src sequence (optional).
src_key_padding_mask: the mask for the src keys per batch (optional).
Shape:
see the docs in Transformer class.
"""
# key padding masking 형 boolean or float만 가능
if src_key_padding_mask is not None:
_skpm_dtype = src_key_padding_mask.dtype
if _skpm_dtype != torch.bool and not torch.is_floating_point(src_key_padding_mask):
raise AssertionError(
"only bool and floating types of key_padding_mask are supported")
# forward 수행
output = src
convert_to_nested = False
first_layer = self.layers[0] # 복사한 첫번째 layer
src_key_padding_mask_for_layers = src_key_padding_mask # None이면 masking 안함
why_not_sparsity_fast_path = '' # ?
str_first_layer = "self.layers[0]"
# 안내문 transformerendcoderlayer가 아닐경우
if not isinstance(first_layer, torch.nn.TransformerEncoderLayer):
why_not_sparsity_fast_path = f"{str_first_layer} was not TransformerEncoderLayer"
elif first_layer.norm_first :
why_not_sparsity_fast_path = f"{str_first_layer}.norm_first was True"
elif first_layer.training:
why_not_sparsity_fast_path = f"{str_first_layer} was in training mode"
elif not first_layer.self_attn.batch_first:
why_not_sparsity_fast_path = f" {str_first_layer}.self_attn.batch_first was not True"
elif not first_layer.self_attn._qkv_same_embed_dim:
why_not_sparsity_fast_path = f"{str_first_layer}.self_attn._qkv_same_embed_dim was not True"
elif not first_layer.activation_relu_or_gelu:
why_not_sparsity_fast_path = f" {str_first_layer}.activation_relu_or_gelu was not True"
elif not (first_layer.norm1.eps == first_layer.norm2.eps) :
why_not_sparsity_fast_path = f"{str_first_layer}.norm1.eps was not equal to {str_first_layer}.norm2.eps"
elif not src.dim() == 3:
why_not_sparsity_fast_path = f"input not batched; expected src.dim() of 3 but got {src.dim()}"
elif not self.enable_nested_tensor:
why_not_sparsity_fast_path = "enable_nested_tensor was not True"
elif src_key_padding_mask is None:
why_not_sparsity_fast_path = "src_key_padding_mask was None"
elif (((not hasattr(self, "mask_check")) or self.mask_check)
and not torch._nested_tensor_from_mask_left_aligned(src, src_key_padding_mask.logical_not())):
why_not_sparsity_fast_path = "mask_check enabled, and src and src_key_padding_mask was not left aligned"
elif output.is_nested:
why_not_sparsity_fast_path = "NestedTensor input is not supported"
elif mask is not None:
why_not_sparsity_fast_path = "src_key_padding_mask and mask were both supplied"
elif first_layer.self_attn.num_heads % 2 == 1:
why_not_sparsity_fast_path = "num_head is odd"
elif torch.is_autocast_enabled():
why_not_sparsity_fast_path = "autocast is enabled"
# transformerendcoderlayer인 경우
if not why_not_sparsity_fast_path:
tensor_args = (
src,
first_layer.self_attn.in_proj_weight,
first_layer.self_attn.in_proj_bias,
first_layer.self_attn.out_proj.weight,
first_layer.self_attn.out_proj.bias,
first_layer.norm1.weight,
first_layer.norm1.bias,
first_layer.norm2.weight,
first_layer.norm2.bias,
first_layer.linear1.weight,
first_layer.linear1.bias,
first_layer.linear2.weight,
first_layer.linear2.bias,
)
# True if any of the elements of relevant_args have __torch_function__ implementations, False otherwise.
# https://pytorch.org/docs/stable/notes/extending.html#extending-torch
if torch.overrides.has_torch_function(tensor_args):
why_not_sparsity_fast_path = "some Tensor argument has_torch_function"
elif not (src.is_cuda or 'cpu' in str(src.device)):
why_not_sparsity_fast_path = "src is neither CUDA nor CPU"
elif torch.is_grad_enabled() and any(x.requires_grad for x in tensor_args):
why_not_sparsity_fast_path = ("grad is enabled and at least one of query or the "
"input/output projection weights or biases requires_grad")
if (not why_not_sparsity_fast_path) and (src_key_padding_mask is not None):
convert_to_nested = True
output = torch._nested_tensor_from_mask(output, src_key_padding_mask.logical_not(), mask_check=False)
src_key_padding_mask_for_layers = None
# 실제 forward 진행부
for mod in self.layers:
output = mod(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask_for_layers)
# nestedtensor?
if convert_to_nested:
output = output.to_padded_tensor(0.)
# normalization
if self.norm is not None:
output = self.norm(output)
# done.
return outputTransformerDecoder
# 디코더~
class TransformerDecoder(Module):
r"""TransformerDecoder is a stack of N decoder layers
Args:
decoder_layer: an instance of the TransformerDecoderLayer() class (required).
num_layers: the number of sub-decoder-layers in the decoder (required).
norm: the layer normalization component (optional).
Examples::
>>> decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8)
>>> transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers=6)
>>> memory = torch.rand(10, 32, 512)
>>> tgt = torch.rand(20, 32, 512)
>>> out = transformer_decoder(tgt, memory)
"""
__constants__ = ['norm']
def __init__(self, decoder_layer, num_layers, norm=None):
super(TransformerDecoder, self).__init__()
# 인코더와 상동
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = LayerNorm
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r"""Pass the inputs (and mask) through the decoder layer in turn.
Args:
tgt: the sequence to the decoder (required).
memory: the sequence from the last layer of the encoder (required).
tgt_mask: the mask for the tgt sequence (optional).
memory_mask: the mask for the memory sequence (optional).
tgt_key_padding_mask: the mask for the tgt keys per batch (optional).
memory_key_padding_mask: the mask for the memory keys per batch (optional).
Shape:
see the docs in Transformer class.
"""
output = tgt
# 수행~ : memory from encoder, mask 주의
for mod in self.layers:
output = mod(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
# norm
if self.norm is not None:
output = self.norm(output)
return output
# act return
def _get_activation_fn(activation: str) -> Callable[[Tensor], Tensor]:
if activation == "relu":
return F.relu
elif activation == "gelu":
return F.gelu
raise RuntimeError("activation should be relu/gelu, not {}".format(activation))TransformerEncoderLayer
# 드디어 Encoderlayer!
class TransformerEncoderLayer(Module):
r"""TransformerEncoderLayer is made up of self-attn and feedforward network.
This standard encoder layer is based on the paper "Attention Is All You Need".
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez,
Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in
Neural Information Processing Systems, pages 6000-6010. Users may modify or implement
in a different way during application.
Args:
d_model: the number of expected features in the input (required). # input emb dim
nhead: the number of heads in the multiheadattention models (required).
dim_feedforward: the dimension of the feedforward network model (default=2048).
dropout: the dropout value (default=0.1).
activation: the activation function of the intermediate layer, can be a string
("relu" or "gelu") or a unary callable. Default: relu
layer_norm_eps: the eps value in layer normalization components (default=1e-5). # layer norm!
batch_first: If ``True``, then the input and output tensors are provided
as (batch, seq, feature). Default: ``False`` (seq, batch, feature).
norm_first: if ``True``, layer norm is done prior to attention and feedforward
operations, respectively. Otherwise it's done after. Default: ``False`` (after).
Examples::
>>> encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8)
>>> src = torch.rand(10, 32, 512)
>>> out = encoder_layer(src)
Alternatively, when ``batch_first`` is ``True``:
>>> encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8, batch_first=True)
>>> src = torch.rand(32, 10, 512)
>>> out = encoder_layer(src)
Fast path:
# forward 가 optimize 되는 요건 이하~
forward() will use a special optimized implementation if all of the following
conditions are met:
- Either autograd is disabled (using ``torch.inference_mode`` or ``torch.no_grad``) or no tensor
argument ``requires_grad``
- training is disabled (using ``.eval()``)
- batch_first is ``True`` and the input is batched (i.e., ``src.dim() == 3``)
- activation is one of: ``"relu"``, ``"gelu"``, ``torch.functional.relu``, or ``torch.functional.gelu``
- at most one of ``src_mask`` and ``src_key_padding_mask`` is passed
- if src is a `NestedTensor <https://pytorch.org/docs/stable/nested.html>`_, neither ``src_mask``
nor ``src_key_padding_mask`` is passed
- the two ``LayerNorm`` instances have a consistent ``eps`` value (this will naturally be the case
unless the caller has manually modified one without modifying the other)
If the optimized implementation is in use, a
`NestedTensor <https://pytorch.org/docs/stable/nested.html>`_ can be
passed for ``src`` to represent padding more efficiently than using a padding
mask. In this case, a `NestedTensor <https://pytorch.org/docs/stable/nested.html>`_ will be
returned, and an additional speedup proportional to the fraction of the input that
is padding can be expected.
"""
__constants__ = ['batch_first', 'norm_first']
def __init__(self, d_model: int, nhead: int, dim_feedforward: int = 2048, dropout: float = 0.1,
activation: Union[str, Callable[[Tensor], Tensor]] = F.relu,
layer_norm_eps: float = 1e-5, batch_first: bool = False, norm_first: bool = False,
device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(TransformerEncoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first,
**factory_kwargs)
# Implementation of Feedforward model
self.linear1 = Linear(d_model, dim_feedforward, **factory_kwargs)
self.dropout = Dropout(dropout)
self.linear2 = Linear(dim_feedforward, d_model, **factory_kwargs)
self.norm_first = norm_first
self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.norm2 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.dropout1 = Dropout(dropout)
self.dropout2 = Dropout(dropout)
# Legacy string support for activation function.
if isinstance(activation, str):
activation = _get_activation_fn(activation)
# We can't test self.activation in forward() in TorchScript,
# so stash some information about it instead.
if activation is F.relu or isinstance(activation, torch.nn.ReLU):
self.activation_relu_or_gelu = 1
elif activation is F.gelu or isinstance(activation, torch.nn.GELU):
self.activation_relu_or_gelu = 2
else:
self.activation_relu_or_gelu = 0
self.activation = activation
def __setstate__(self, state):
super(TransformerEncoderLayer, self).__setstate__(state)
if not hasattr(self, 'activation'):
self.activation = F.relu
def forward(self, src: Tensor, src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r"""Pass the input through the encoder layer.
Args:
src: the sequence to the encoder layer (required).
src_mask: the mask for the src sequence (optional).
src_key_padding_mask: the mask for the src keys per batch (optional).
Shape:
see the docs in Transformer class.
"""
# src 도 masking 할거니 : 보통 안함
if src_key_padding_mask is not None:
_skpm_dtype = src_key_padding_mask.dtype
if _skpm_dtype != torch.bool and not torch.is_floating_point(src_key_padding_mask):
raise AssertionError(
"only bool and floating types of key_padding_mask are supported")
# see Fig. 1 of https://arxiv.org/pdf/2002.04745v1.pdf
why_not_sparsity_fast_path = ''
if not src.dim() == 3:
why_not_sparsity_fast_path = f"input not batched; expected src.dim() of 3 but got {src.dim()}"
elif self.training:
why_not_sparsity_fast_path = "training is enabled"
elif not self.self_attn.batch_first :
why_not_sparsity_fast_path = "self_attn.batch_first was not True"
elif not self.self_attn._qkv_same_embed_dim :
why_not_sparsity_fast_path = "self_attn._qkv_same_embed_dim was not True"
elif not self.activation_relu_or_gelu:
why_not_sparsity_fast_path = "activation_relu_or_gelu was not True"
elif not (self.norm1.eps == self.norm2.eps):
why_not_sparsity_fast_path = "norm1.eps is not equal to norm2.eps"
elif src_mask is not None:
why_not_sparsity_fast_path = "src_mask is not supported for fastpath"
elif src.is_nested and src_key_padding_mask is not None:
why_not_sparsity_fast_path = "src_key_padding_mask is not supported with NestedTensor input for fastpath"
elif self.self_attn.num_heads % 2 == 1:
why_not_sparsity_fast_path = "num_head is odd"
elif torch.is_autocast_enabled():
why_not_sparsity_fast_path = "autocast is enabled"
if not why_not_sparsity_fast_path:
tensor_args = (
src,
self.self_attn.in_proj_weight,
self.self_attn.in_proj_bias,
self.self_attn.out_proj.weight,
self.self_attn.out_proj.bias,
self.norm1.weight,
self.norm1.bias,
self.norm2.weight,
self.norm2.bias,
self.linear1.weight,
self.linear1.bias,
self.linear2.weight,
self.linear2.bias,
)
# We have to use list comprehensions below because TorchScript does not support
# generator expressions.
if torch.overrides.has_torch_function(tensor_args):
why_not_sparsity_fast_path = "some Tensor argument has_torch_function"
elif not all((x.is_cuda or 'cpu' in str(x.device)) for x in tensor_args):
why_not_sparsity_fast_path = "some Tensor argument is neither CUDA nor CPU"
elif torch.is_grad_enabled() and any(x.requires_grad for x in tensor_args):
why_not_sparsity_fast_path = ("grad is enabled and at least one of query or the "
"input/output projection weights or biases requires_grad")
if not why_not_sparsity_fast_path:
return torch._transformer_encoder_layer_fwd(
src,
self.self_attn.embed_dim,
self.self_attn.num_heads,
self.self_attn.in_proj_weight,
self.self_attn.in_proj_bias,
self.self_attn.out_proj.weight,
self.self_attn.out_proj.bias,
self.activation_relu_or_gelu == 2,
self.norm_first,
self.norm1.eps,
self.norm1.weight,
self.norm1.bias,
self.norm2.weight,
self.norm2.bias,
self.linear1.weight,
self.linear1.bias,
self.linear2.weight,
self.linear2.bias,
# TODO: if src_mask and src_key_padding_mask merge to single 4-dim mask
src_mask if src_mask is not None else src_key_padding_mask,
1 if src_key_padding_mask is not None else
0 if src_mask is not None else
None,
)
# self attention + feed forward (norm 따라 서순은 다름)
x = src
if self.norm_first:
x = x + self._sa_block(self.norm1(x), src_mask, src_key_padding_mask)
x = x + self._ff_block(self.norm2(x))
else:
x = self.norm1(x + self._sa_block(x, src_mask, src_key_padding_mask))
x = self.norm2(x + self._ff_block(x))
return x
# self-attention block : x, x, x -> q, k, v
def _sa_block(self, x: Tensor,
attn_mask: Optional[Tensor], key_padding_mask: Optional[Tensor]) -> Tensor:
x = self.self_attn(x, x, x,
attn_mask=attn_mask,
key_padding_mask=key_padding_mask,
need_weights=False)[0]
return self.dropout1(x)
# feed forward block
def _ff_block(self, x: Tensor) -> Tensor:
x = self.linear2(self.dropout(self.activation(self.linear1(x))))
return self.dropout2(x)TransformerDecoderLayer
# decoder layer!!
class TransformerDecoderLayer(Module):
r"""TransformerDecoderLayer is made up of self-attn, multi-head-attn and feedforward network.
This standard decoder layer is based on the paper "Attention Is All You Need".
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez,
Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in
Neural Information Processing Systems, pages 6000-6010. Users may modify or implement
in a different way during application.
# 포인트는 뭐다?
# 1. q k v 가 encoder랑 다르다.
# 2. masking!
Args:
d_model: the number of expected features in the input (required).
nhead: the number of heads in the multiheadattention models (required).
dim_feedforward: the dimension of the feedforward network model (default=2048).
dropout: the dropout value (default=0.1).
activation: the activation function of the intermediate layer, can be a string
("relu" or "gelu") or a unary callable. Default: relu
layer_norm_eps: the eps value in layer normalization components (default=1e-5).
batch_first: If ``True``, then the input and output tensors are provided
as (batch, seq, feature). Default: ``False`` (seq, batch, feature).
norm_first: if ``True``, layer norm is done prior to self attention, multihead
attention and feedforward operations, respectively. Otherwise it's done after.
Default: ``False`` (after).
Examples::
>>> decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8)
>>> memory = torch.rand(10, 32, 512)
>>> tgt = torch.rand(20, 32, 512)
>>> out = decoder_layer(tgt, memory)
Alternatively, when ``batch_first`` is ``True``:
>>> decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8, batch_first=True)
>>> memory = torch.rand(32, 10, 512)
>>> tgt = torch.rand(32, 20, 512)
>>> out = decoder_layer(tgt, memory) # 요느낌 참고
"""
__constants__ = ['batch_first', 'norm_first']
def __init__(self, d_model: int, nhead: int, dim_feedforward: int = 2048, dropout: float = 0.1,
activation: Union[str, Callable[[Tensor], Tensor]] = F.relu,
layer_norm_eps: float = 1e-5, batch_first: bool = False, norm_first: bool = False,
device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(TransformerDecoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first,
**factory_kwargs)
self.multihead_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first,
**factory_kwargs)
# Implementation of Feedforward model
self.linear1 = Linear(d_model, dim_feedforward, **factory_kwargs)
self.dropout = Dropout(dropout)
self.linear2 = Linear(dim_feedforward, d_model, **factory_kwargs)
self.norm_first = norm_first
self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.norm2 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.norm3 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.dropout1 = Dropout(dropout)
self.dropout2 = Dropout(dropout)
self.dropout3 = Dropout(dropout)
# Legacy string support for activation function.
if isinstance(activation, str):
self.activation = _get_activation_fn(activation)
else:
self.activation = activation
def __setstate__(self, state):
if 'activation' not in state:
state['activation'] = F.relu
super(TransformerDecoderLayer, self).__setstate__(state)
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None, memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r"""Pass the inputs (and mask) through the decoder layer.
Args:
tgt: the sequence to the decoder layer (required).
memory: the sequence from the last layer of the encoder (required).
tgt_mask: the mask for the tgt sequence (optional).
memory_mask: the mask for the memory sequence (optional).
tgt_key_padding_mask: the mask for the tgt keys per batch (optional).
memory_key_padding_mask: the mask for the memory keys per batch (optional).
Shape:
see the docs in Transformer class.
"""
# see Fig. 1 of https://arxiv.org/pdf/2002.04745v1.pdf
x = tgt
if self.norm_first:
x = x + self._sa_block(self.norm1(x), tgt_mask, tgt_key_padding_mask) # masking 된걸로 self attention 한판 때리기! : 만약 첫단어면 자기 자신밖에 못하겠군.
x = x + self._mha_block(self.norm2(x), memory, memory_mask, memory_key_padding_mask) # 거기에다가 memory와 attention 때리기!
x = x + self._ff_block(self.norm3(x))
else:
x = self.norm1(x + self._sa_block(x, tgt_mask, tgt_key_padding_mask))
x = self.norm2(x + self._mha_block(x, memory, memory_mask, memory_key_padding_mask))
x = self.norm3(x + self._ff_block(x))
return x
# self-attention block
def _sa_block(self, x: Tensor,
attn_mask: Optional[Tensor], key_padding_mask: Optional[Tensor]) -> Tensor: # self attention
x = self.self_attn(x, x, x,
attn_mask=attn_mask, # 이거는 masking이 무조건 들어감
key_padding_mask=key_padding_mask,
need_weights=False)[0]
return self.dropout1(x)
# multihead attention block
def _mha_block(self, x: Tensor, mem: Tensor,
attn_mask: Optional[Tensor], key_padding_mask: Optional[Tensor]) -> Tensor:
x = self.multihead_attn(x, mem, mem, # q : x, k : mem, v : mem => 즉, MEMORY의 DB에게 물어보는 것. MEMORY는 모두 self-attention이 먹은 상태.
attn_mask=attn_mask, # 논문 기반으로 봤을 때, memory의 masking은 오히려 성능을 떨어뜨리지 않을까 생각이 듬 : 따라서, 아마 특수 상황을 제외하고는 잘 사용하지 않지 않을까?
key_padding_mask=key_padding_mask, # 그런데 mask를 먹여주는 정확한 timing은 언제지? MHE class 참고. (바로 아래)
need_weights=False)[0]
return self.dropout2(x)
# feed forward block
def _ff_block(self, x: Tensor) -> Tensor:
x = self.linear2(self.dropout(self.activation(self.linear1(x))))
return self.dropout3(x)MultiheadAttention
# 드디어 가장 깊은 곳까지 왔다! Multi-head Attention!
class MultiheadAttention(Module):
r"""Allows the model to jointly attend to information
from different representation subspaces as described in the paper:
`Attention Is All You Need <https://arxiv.org/abs/1706.03762>`_.
Multi-Head Attention is defined as:
.. math::
\text{MultiHead}(Q, K, V) = \text{Concat}(head_1,\dots,head_h)W^O
where :math:`head_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)`.
``forward()`` will use a special optimized implementation if all of the following
conditions are met:
- self attention is being computed (i.e., ``query``, ``key``, and ``value`` are the same tensor. This
restriction will be loosened in the future.)
- Either autograd is disabled (using ``torch.inference_mode`` or ``torch.no_grad``) or no tensor argument ``requires_grad``
- training is disabled (using ``.eval()``)
- dropout is 0
- ``add_bias_kv`` is ``False``
- ``add_zero_attn`` is ``False``
- ``batch_first`` is ``True`` and the input is batched
- ``kdim`` and ``vdim`` are equal to ``embed_dim``
- at most one of ``key_padding_mask`` or ``attn_mask`` is passed
- if a `NestedTensor <https://pytorch.org/docs/stable/nested.html>`_ is passed, neither ``key_padding_mask``
nor ``attn_mask`` is passed
If the optimized implementation is in use, a
`NestedTensor <https://pytorch.org/docs/stable/nested.html>`_ can be passed for
``query``/``key``/``value`` to represent padding more efficiently than using a
padding mask. In this case, a `NestedTensor <https://pytorch.org/docs/stable/nested.html>`_
will be returned, and an additional speedup proportional to the fraction of the input
that is padding can be expected.
Args:
embed_dim: Total dimension of the model.
num_heads: Number of parallel attention heads. Note that ``embed_dim`` will be split
across ``num_heads`` (i.e. each head will have dimension ``embed_dim // num_heads``).
dropout: Dropout probability on ``attn_output_weights``. Default: ``0.0`` (no dropout).
bias: If specified, adds bias to input / output projection layers. Default: ``True``.
add_bias_kv: If specified, adds bias to the key and value sequences at dim=0. Default: ``False``.
add_zero_attn: If specified, adds a new batch of zeros to the key and value sequences at dim=1.
Default: ``False``.
kdim: Total number of features for keys. Default: ``None`` (uses ``kdim=embed_dim``).
vdim: Total number of features for values. Default: ``None`` (uses ``vdim=embed_dim``).
batch_first: If ``True``, then the input and output tensors are provided
as (batch, seq, feature). Default: ``False`` (seq, batch, feature).
Examples::
>>> # xdoctest: +SKIP
>>> multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
>>> attn_output, attn_output_weights = multihead_attn(query, key, value)
"""
__constants__ = ['batch_first']
bias_k: Optional[torch.Tensor]
bias_v: Optional[torch.Tensor]
# initial setting
def __init__(self, embed_dim, num_heads, dropout=0., bias=True, add_bias_kv=False, add_zero_attn=False,
kdim=None, vdim=None, batch_first=False, device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(MultiheadAttention, self).__init__()
self.embed_dim = embed_dim
self.kdim = kdim if kdim is not None else embed_dim
self.vdim = vdim if vdim is not None else embed_dim
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.batch_first = batch_first
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
# qkv embed dim이 다른 경우
if not self._qkv_same_embed_dim:
self.q_proj_weight = Parameter(torch.empty((embed_dim, embed_dim), **factory_kwargs))
self.k_proj_weight = Parameter(torch.empty((embed_dim, self.kdim), **factory_kwargs))
self.v_proj_weight = Parameter(torch.empty((embed_dim, self.vdim), **factory_kwargs))
self.register_parameter('in_proj_weight', None)
# qkv embed dim이 같은 경우 (보통의 경우) => 아마 self.in_proj_weight를 그냥 indexing해서 사용할 것 같음
else:
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim), **factory_kwargs))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
if bias:
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim, **factory_kwargs))
else:
self.register_parameter('in_proj_bias', None)
self.out_proj = NonDynamicallyQuantizableLinear(embed_dim, embed_dim, bias=bias, **factory_kwargs)
if add_bias_kv:
self.bias_k = Parameter(torch.empty((1, 1, embed_dim), **factory_kwargs))
self.bias_v = Parameter(torch.empty((1, 1, embed_dim), **factory_kwargs))
else:
self.bias_k = self.bias_v = None
self.add_zero_attn = add_zero_attn
self._reset_parameters()
# param init
def _reset_parameters(self):
if self._qkv_same_embed_dim:
xavier_uniform_(self.in_proj_weight)
else:
xavier_uniform_(self.q_proj_weight)
xavier_uniform_(self.k_proj_weight)
xavier_uniform_(self.v_proj_weight)
if self.in_proj_bias is not None:
constant_(self.in_proj_bias, 0.)
constant_(self.out_proj.bias, 0.)
if self.bias_k is not None:
xavier_normal_(self.bias_k)
if self.bias_v is not None:
xavier_normal_(self.bias_v)
def __setstate__(self, state):
# Support loading old MultiheadAttention checkpoints generated by v1.1.0
if '_qkv_same_embed_dim' not in state:
state['_qkv_same_embed_dim'] = True
super(MultiheadAttention, self).__setstate__(state)
# forward! let's go!
def forward(self, query: Tensor, key: Tensor, value: Tensor, key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True, attn_mask: Optional[Tensor] = None,
average_attn_weights: bool = True) -> Tuple[Tensor, Optional[Tensor]]:
r"""
Args:
query: Query embeddings of shape :math:`(L, E_q)` for unbatched input, :math:`(L, N, E_q)` when ``batch_first=False``
or :math:`(N, L, E_q)` when ``batch_first=True``, where :math:`L` is the target sequence length,
:math:`N` is the batch size, and :math:`E_q` is the query embedding dimension ``embed_dim``.
Queries are compared against key-value pairs to produce the output.
See "Attention Is All You Need" for more details.
key: Key embeddings of shape :math:`(S, E_k)` for unbatched input, :math:`(S, N, E_k)` when ``batch_first=False``
or :math:`(N, S, E_k)` when ``batch_first=True``, where :math:`S` is the source sequence length,
:math:`N` is the batch size, and :math:`E_k` is the key embedding dimension ``kdim``.
See "Attention Is All You Need" for more details.
value: Value embeddings of shape :math:`(S, E_v)` for unbatched input, :math:`(S, N, E_v)` when
``batch_first=False`` or :math:`(N, S, E_v)` when ``batch_first=True``, where :math:`S` is the source
sequence length, :math:`N` is the batch size, and :math:`E_v` is the value embedding dimension ``vdim``.
See "Attention Is All You Need" for more details.
key_padding_mask: If specified, a mask of shape :math:`(N, S)` indicating which elements within ``key``
to ignore for the purpose of attention (i.e. treat as "padding"). For unbatched `query`, shape should be :math:`(S)`.
Binary and byte masks are supported.
For a binary mask, a ``True`` value indicates that the corresponding ``key`` value will be ignored for
the purpose of attention. For a float mask, it will be directly added to the corresponding ``key`` value.
need_weights: If specified, returns ``attn_output_weights`` in addition to ``attn_outputs``.
Default: ``True``.
attn_mask: If specified, a 2D or 3D mask preventing attention to certain positions. Must be of shape
:math:`(L, S)` or :math:`(N\cdot\text{num\_heads}, L, S)`, where :math:`N` is the batch size,
:math:`L` is the target sequence length, and :math:`S` is the source sequence length. A 2D mask will be
broadcasted across the batch while a 3D mask allows for a different mask for each entry in the batch.
Binary, byte, and float masks are supported. For a binary mask, a ``True`` value indicates that the
corresponding position is not allowed to attend. For a byte mask, a non-zero value indicates that the
corresponding position is not allowed to attend. For a float mask, the mask values will be added to
the attention weight.
average_attn_weights: If true, indicates that the returned ``attn_weights`` should be averaged across
heads. Otherwise, ``attn_weights`` are provided separately per head. Note that this flag only has an
effect when ``need_weights=True``. Default: ``True`` (i.e. average weights across heads)
Outputs:
- **attn_output** - Attention outputs of shape :math:`(L, E)` when input is unbatched,
:math:`(L, N, E)` when ``batch_first=False`` or :math:`(N, L, E)` when ``batch_first=True``,
where :math:`L` is the target sequence length, :math:`N` is the batch size, and :math:`E` is the
embedding dimension ``embed_dim``.
- **attn_output_weights** - Only returned when ``need_weights=True``. If ``average_attn_weights=True``,
returns attention weights averaged across heads of shape :math:`(L, S)` when input is unbatched or
:math:`(N, L, S)`, where :math:`N` is the batch size, :math:`L` is the target sequence length, and
:math:`S` is the source sequence length. If ``average_attn_weights=False``, returns attention weights per
head of shape :math:`(\text{num\_heads}, L, S)` when input is unbatched or :math:`(N, \text{num\_heads}, L, S)`.
.. note::
`batch_first` argument is ignored for unbatched inputs.
"""
is_batched = query.dim() == 3
if key_padding_mask is not None:
_kpm_dtype = key_padding_mask.dtype
if _kpm_dtype != torch.bool and not torch.is_floating_point(key_padding_mask):
raise AssertionError(
"only bool and floating types of key_padding_mask are supported")
why_not_fast_path = ''
if not is_batched:
why_not_fast_path = f"input not batched; expected query.dim() of 3 but got {query.dim()}"
elif query is not key or key is not value:
# When lifting this restriction, don't forget to either
# enforce that the dtypes all match or test cases where
# they don't!
why_not_fast_path = "non-self attention was used (query, key, and value are not the same Tensor)"
elif self.in_proj_bias is not None and query.dtype != self.in_proj_bias.dtype:
why_not_fast_path = f"dtypes of query ({query.dtype}) and self.in_proj_bias ({self.in_proj_bias.dtype}) don't match"
elif self.in_proj_weight is not None and query.dtype != self.in_proj_weight.dtype:
# this case will fail anyway, but at least they'll get a useful error message.
why_not_fast_path = f"dtypes of query ({query.dtype}) and self.in_proj_weight ({self.in_proj_weight.dtype}) don't match"
elif self.training:
why_not_fast_path = "training is enabled"
elif not self.batch_first:
why_not_fast_path = "batch_first was not True"
elif self.bias_k is not None:
why_not_fast_path = "self.bias_k was not None"
elif self.bias_v is not None:
why_not_fast_path = "self.bias_v was not None"
elif self.dropout:
why_not_fast_path = f"dropout was {self.dropout}, required zero"
elif self.add_zero_attn:
why_not_fast_path = "add_zero_attn was enabled"
elif not self._qkv_same_embed_dim:
why_not_fast_path = "_qkv_same_embed_dim was not True"
elif attn_mask is not None:
why_not_fast_path = "attn_mask was not None"
elif query.is_nested and key_padding_mask is not None:
why_not_fast_path = "key_padding_mask is not supported with NestedTensor input"
elif self.num_heads % 2 == 1:
why_not_fast_path = "num_heads is odd"
elif torch.is_autocast_enabled():
why_not_fast_path = "autocast is enabled"
if not why_not_fast_path:
tensor_args = (
query,
key,
value,
self.in_proj_weight,
self.in_proj_bias,
self.out_proj.weight,
self.out_proj.bias,
)
# We have to use list comprehensions below because TorchScript does not support
# generator expressions.
if torch.overrides.has_torch_function(tensor_args):
why_not_fast_path = "some Tensor argument has_torch_function"
elif not all([(x.is_cuda or 'cpu' in str(x.device)) for x in tensor_args]):
why_not_fast_path = "some Tensor argument is neither CUDA nor CPU"
elif torch.is_grad_enabled() and any([x.requires_grad for x in tensor_args]):
why_not_fast_path = ("grad is enabled and at least one of query or the "
"input/output projection weights or biases requires_grad")
if not why_not_fast_path:
return torch._native_multi_head_attention(
query,
key,
value,
self.embed_dim,
self.num_heads,
self.in_proj_weight,
self.in_proj_bias,
self.out_proj.weight,
self.out_proj.bias,
key_padding_mask if key_padding_mask is not None else attn_mask,
need_weights,
average_attn_weights,
1 if key_padding_mask is not None else 0 if attn_mask is not None else None)
any_nested = query.is_nested or key.is_nested or value.is_nested
assert not any_nested, ("MultiheadAttention does not support NestedTensor outside of its fast path. " +
f"The fast path was not hit because {why_not_fast_path}")
if self.batch_first and is_batched:
# make sure that the transpose op does not affect the "is" property
if key is value:
if query is key:
query = key = value = query.transpose(1, 0)
else:
query, key = [x.transpose(1, 0) for x in (query, key)]
value = key
else:
query, key, value = [x.transpose(1, 0) for x in (query, key, value)]
if not self._qkv_same_embed_dim:
# 보통 multi_head_attention_forward 사용해서 실제 MHE가 실행될 듯
attn_output, attn_output_weights = F.multi_head_attention_forward(
query, key, value, self.embed_dim, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.bias_k, self.bias_v, self.add_zero_attn,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask, use_separate_proj_weight=True,
q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight,
v_proj_weight=self.v_proj_weight, average_attn_weights=average_attn_weights)
else:
# 보통 multi_head_attention_forward 사용해서 실제 MHE가 실행될 듯
attn_output, attn_output_weights = F.multi_head_attention_forward(
query, key, value, self.embed_dim, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.bias_k, self.bias_v, self.add_zero_attn,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask, average_attn_weights=average_attn_weights)
if self.batch_first and is_batched:
return attn_output.transpose(1, 0), attn_output_weights
else:
return attn_output, attn_output_weights
'''
MHA class는 값 정의와 환경 설정쪽에 많은 분기 소요
'''
# MHA shape check!
def _mha_shape_check(query: Tensor, key: Tensor, value: Tensor,
key_padding_mask: Optional[Tensor], attn_mask: Optional[Tensor], num_heads: int):
# Verifies the expected shape for `query, `key`, `value`, `key_padding_mask` and `attn_mask`
# and returns if the input is batched or not.
# Raises an error if `query` is not 2-D (unbatched) or 3-D (batched) tensor.
# Shape check.
if query.dim() == 3:
# Batched Inputs
is_batched = True
assert key.dim() == 3 and value.dim() == 3, \
("For batched (3-D) `query`, expected `key` and `value` to be 3-D"
f" but found {key.dim()}-D and {value.dim()}-D tensors respectively")
if key_padding_mask is not None:
assert key_padding_mask.dim() == 2, \
("For batched (3-D) `query`, expected `key_padding_mask` to be `None` or 2-D"
f" but found {key_padding_mask.dim()}-D tensor instead")
if attn_mask is not None:
assert attn_mask.dim() in (2, 3), \
("For batched (3-D) `query`, expected `attn_mask` to be `None`, 2-D or 3-D"
f" but found {attn_mask.dim()}-D tensor instead")
elif query.dim() == 2:
# Unbatched Inputs
is_batched = False
assert key.dim() == 2 and value.dim() == 2, \
("For unbatched (2-D) `query`, expected `key` and `value` to be 2-D"
f" but found {key.dim()}-D and {value.dim()}-D tensors respectively")
if key_padding_mask is not None:
assert key_padding_mask.dim() == 1, \
("For unbatched (2-D) `query`, expected `key_padding_mask` to be `None` or 1-D"
f" but found {key_padding_mask.dim()}-D tensor instead")
if attn_mask is not None:
assert attn_mask.dim() in (2, 3), \
("For unbatched (2-D) `query`, expected `attn_mask` to be `None`, 2-D or 3-D"
f" but found {attn_mask.dim()}-D tensor instead")
if attn_mask.dim() == 3:
expected_shape = (num_heads, query.shape[0], key.shape[0])
assert attn_mask.shape == expected_shape, \
(f"Expected `attn_mask` shape to be {expected_shape} but got {attn_mask.shape}")
else:
raise AssertionError(
f"query should be unbatched 2D or batched 3D tensor but received {query.dim()}-D query tensor")
return is_batched
# 뭐 걸리지만 않으면 zeros_like로 masking 뽑아 줌
def _canonical_mask(
mask: Optional[Tensor],
mask_name: str,
other_type: Optional[DType],
other_name: str,
target_type: DType,
check_other: bool = True,
) -> Optional[Tensor]:
if mask is not None:
_mask_dtype = mask.dtype
_mask_is_float = torch.is_floating_point(mask)
if _mask_dtype != torch.bool and not _mask_is_float:
raise AssertionError(
f"only bool and floating types of {mask_name} are supported")
if check_other and other_type is not None:
if _mask_dtype != other_type:
warnings.warn(
f"Support for mismatched {mask_name} and {other_name} "
"is deprecated. Use same type for both instead."
)
if not _mask_is_float:
mask = (
torch.zeros_like(mask, dtype=target_type)
.masked_fill_(mask, float("-inf"))
)
return mask
def _in_projection_packed(
q: Tensor,
k: Tensor,
v: Tensor,
w: Tensor,
b: Optional[Tensor] = None,
) -> List[Tensor]:
r"""
Performs the in-projection step of the attention operation, using packed weights.
Output is a triple containing projection tensors for query, key and value.
Args:
q, k, v: query, key and value tensors to be projected. For self-attention,
these are typically the same tensor; for encoder-decoder attention,
k and v are typically the same tensor. (We take advantage of these
identities for performance if they are present.) Regardless, q, k and v
must share a common embedding dimension; otherwise their shapes may vary.
w: projection weights for q, k and v, packed into a single tensor. Weights
are packed along dimension 0, in q, k, v order.
b: optional projection biases for q, k and v, packed into a single tensor
in q, k, v order.
Shape:
Inputs:
- q: :math:`(..., E)` where E is the embedding dimension
- k: :math:`(..., E)` where E is the embedding dimension
- v: :math:`(..., E)` where E is the embedding dimension
- w: :math:`(E * 3, E)` where E is the embedding dimension
- b: :math:`E * 3` where E is the embedding dimension
Output:
- in output list :math:`[q', k', v']`, each output tensor will have the
same shape as the corresponding input tensor.
"""
E = q.size(-1)
if k is v:
if q is k:
# self-attention
proj = linear(q, w, b)
# reshape to 3, E and not E, 3 is deliberate for better memory coalescing and keeping same order as chunk()
proj = proj.unflatten(-1, (3, E)).unsqueeze(0).transpose(0, -2).squeeze(-2).contiguous()
return proj[0], proj[1], proj[2]
else:
# encoder-decoder attention
w_q, w_kv = w.split([E, E * 2])
if b is None:
b_q = b_kv = None
else:
b_q, b_kv = b.split([E, E * 2])
q_proj = linear(q, w_q, b_q)
kv_proj = linear(k, w_kv, b_kv)
# reshape to 2, E and not E, 2 is deliberate for better memory coalescing and keeping same order as chunk()
kv_proj = kv_proj.unflatten(-1, (2, E)).unsqueeze(0).transpose(0, -2).squeeze(-2).contiguous()
return (q_proj, kv_proj[0], kv_proj[1])
else:
w_q, w_k, w_v = w.chunk(3)
if b is None:
b_q = b_k = b_v = None
else:
b_q, b_k, b_v = b.chunk(3)
return linear(q, w_q, b_q), linear(k, w_k, b_k), linear(v, w_v, b_v)
from torch._C import _infer_size, _add_docstr
# 걍 linear 다. (c implementation)
linear = _add_docstr(
torch._C._nn.linear,
r"""
linear(input, weight, bias=None) -> Tensor
Applies a linear transformation to the incoming data: :math:`y = xA^T + b`.
This operation supports 2-D :attr:`weight` with :ref:`sparse layout<sparse-docs>`
{sparse_beta_warning}
This operator supports :ref:`TensorFloat32<tf32_on_ampere>`.
Shape:
- Input: :math:`(*, in\_features)` where `*` means any number of
additional dimensions, including none
- Weight: :math:`(out\_features, in\_features)` or :math:`(in\_features)`
- Bias: :math:`(out\_features)` or :math:`()`
- Output: :math:`(*, out\_features)` or :math:`(*)`, based on the shape of the weight
""".format(**sparse_support_notes))
pad = _add_docstr(
torch._C._nn.pad,
'')
# attention projection let's go!!!
def _in_projection(
q: Tensor,
k: Tensor,
v: Tensor,
w_q: Tensor,
w_k: Tensor,
w_v: Tensor,
b_q: Optional[Tensor] = None,
b_k: Optional[Tensor] = None,
b_v: Optional[Tensor] = None,
) -> Tuple[Tensor, Tensor, Tensor]:
r"""
Performs the in-projection step of the attention operation. This is simply
a triple of linear projections, with shape constraints on the weights which
ensure embedding dimension uniformity in the projected outputs.
Output is a triple containing projection tensors for query, key and value.
Args:
q, k, v: query, key and value tensors to be projected.
w_q, w_k, w_v: weights for q, k and v, respectively.
b_q, b_k, b_v: optional biases for q, k and v, respectively.
Shape:
Inputs:
- q: :math:`(Qdims..., Eq)` where Eq is the query embedding dimension and Qdims are any
number of leading dimensions.
- k: :math:`(Kdims..., Ek)` where Ek is the key embedding dimension and Kdims are any
number of leading dimensions.
- v: :math:`(Vdims..., Ev)` where Ev is the value embedding dimension and Vdims are any
number of leading dimensions.
- w_q: :math:`(Eq, Eq)`
- w_k: :math:`(Eq, Ek)`
- w_v: :math:`(Eq, Ev)`
- b_q: :math:`(Eq)`
- b_k: :math:`(Eq)`
- b_v: :math:`(Eq)`
Output: in output triple :math:`(q', k', v')`,
- q': :math:`[Qdims..., Eq]`
- k': :math:`[Kdims..., Eq]`
- v': :math:`[Vdims..., Eq]`
"""
Eq, Ek, Ev = q.size(-1), k.size(-1), v.size(-1)
# shape 확인 제대로 하고
assert w_q.shape == (Eq, Eq), f"expecting query weights shape of {(Eq, Eq)}, but got {w_q.shape}"
assert w_k.shape == (Eq, Ek), f"expecting key weights shape of {(Eq, Ek)}, but got {w_k.shape}"
assert w_v.shape == (Eq, Ev), f"expecting value weights shape of {(Eq, Ev)}, but got {w_v.shape}"
assert b_q is None or b_q.shape == (Eq,), f"expecting query bias shape of {(Eq,)}, but got {b_q.shape}"
assert b_k is None or b_k.shape == (Eq,), f"expecting key bias shape of {(Eq,)}, but got {b_k.shape}"
assert b_v is None or b_v.shape == (Eq,), f"expecting value bias shape of {(Eq,)}, but got {b_v.shape}"
# linear 연산 수행 : w, b => affine transformation
return linear(q, w_q, b_q), linear(k, w_k, b_k), linear(v, w_v, b_v)
def _in_projection_packed(
q: Tensor,
k: Tensor,
v: Tensor,
w: Tensor,
b: Optional[Tensor] = None,
) -> List[Tensor]:
r"""
Performs the in-projection step of the attention operation, using packed weights.
Output is a triple containing projection tensors for query, key and value.
Args:
q, k, v: query, key and value tensors to be projected. For self-attention,
these are typically the same tensor; for encoder-decoder attention,
k and v are typically the same tensor. (We take advantage of these
identities for performance if they are present.) Regardless, q, k and v
must share a common embedding dimension; otherwise their shapes may vary.
w: projection weights for q, k and v, packed into a single tensor. Weights
are packed along dimension 0, in q, k, v order.
b: optional projection biases for q, k and v, packed into a single tensor
in q, k, v order.
Shape:
Inputs:
- q: :math:`(..., E)` where E is the embedding dimension
- k: :math:`(..., E)` where E is the embedding dimension
- v: :math:`(..., E)` where E is the embedding dimension
- w: :math:`(E * 3, E)` where E is the embedding dimension
- b: :math:`E * 3` where E is the embedding dimension
Output:
- in output list :math:`[q', k', v']`, each output tensor will have the
same shape as the corresponding input tensor.
"""
E = q.size(-1)
if k is v:
if q is k:
# self-attention
proj = linear(q, w, b)
# reshape to 3, E and not E, 3 is deliberate for better memory coalescing and keeping same order as chunk()
proj = proj.unflatten(-1, (3, E)).unsqueeze(0).transpose(0, -2).squeeze(-2).contiguous()
return proj[0], proj[1], proj[2]
else:
# encoder-decoder attention
w_q, w_kv = w.split([E, E * 2])
if b is None:
b_q = b_kv = None
else:
b_q, b_kv = b.split([E, E * 2])
q_proj = linear(q, w_q, b_q)
kv_proj = linear(k, w_kv, b_kv)
# reshape to 2, E and not E, 2 is deliberate for better memory coalescing and keeping same order as chunk()
kv_proj = kv_proj.unflatten(-1, (2, E)).unsqueeze(0).transpose(0, -2).squeeze(-2).contiguous()
return (q_proj, kv_proj[0], kv_proj[1])
else:
w_q, w_k, w_v = w.chunk(3)
if b is None:
b_q = b_k = b_v = None
else:
b_q, b_k, b_v = b.chunk(3)
return linear(q, w_q, b_q), linear(k, w_k, b_k), linear(v, w_v, b_v)multi_head_attention_forward
# 진짜 진짜 the last 끝판왕 : 진짜 forwarding!
def multi_head_attention_forward(
query: Tensor,
key: Tensor,
value: Tensor,
embed_dim_to_check: int,
num_heads: int,
in_proj_weight: Optional[Tensor],
in_proj_bias: Optional[Tensor],
bias_k: Optional[Tensor],
bias_v: Optional[Tensor],
add_zero_attn: bool,
dropout_p: float,
out_proj_weight: Tensor,
out_proj_bias: Optional[Tensor],
training: bool = True,
key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True,
attn_mask: Optional[Tensor] = None,
use_separate_proj_weight: bool = False,
q_proj_weight: Optional[Tensor] = None,
k_proj_weight: Optional[Tensor] = None,
v_proj_weight: Optional[Tensor] = None,
static_k: Optional[Tensor] = None,
static_v: Optional[Tensor] = None,
average_attn_weights: bool = True,
is_causal: bool = False,
) -> Tuple[Tensor, Optional[Tensor]]:
r"""
Args:
query, key, value: map a query and a set of key-value pairs to an output.
See "Attention Is All You Need" for more details.
embed_dim_to_check: total dimension of the model.
num_heads: parallel attention heads.
in_proj_weight, in_proj_bias: input projection weight and bias.
bias_k, bias_v: bias of the key and value sequences to be added at dim=0.
add_zero_attn: add a new batch of zeros to the key and
value sequences at dim=1.
dropout_p: probability of an element to be zeroed.
out_proj_weight, out_proj_bias: the output projection weight and bias.
training: apply dropout if is ``True``.
key_padding_mask: if provided, specified padding elements in the key will
be ignored by the attention. This is an binary mask. When the value is True,
the corresponding value on the attention layer will be filled with -inf.
need_weights: output attn_output_weights.
attn_mask: 2D or 3D mask that prevents attention to certain positions. A 2D mask will be broadcasted for all
the batches while a 3D mask allows to specify a different mask for the entries of each batch.
is_causal: If specified, applies a causal mask as attention mask, and ignores
attn_mask for computing scaled dot product attention.
Default: ``False``.
use_separate_proj_weight: the function accept the proj. weights for query, key,
and value in different forms. If false, in_proj_weight will be used, which is
a combination of q_proj_weight, k_proj_weight, v_proj_weight.
q_proj_weight, k_proj_weight, v_proj_weight, in_proj_bias: input projection weight and bias.
static_k, static_v: static key and value used for attention operators.
average_attn_weights: If true, indicates that the returned ``attn_weights`` should be averaged across heads.
Otherwise, ``attn_weights`` are provided separately per head. Note that this flag only has an effect
when ``need_weights=True.``. Default: True
Shape:
Inputs:
- query: :math:`(L, E)` or :math:`(L, N, E)` where L is the target sequence length, N is the batch size, E is
the embedding dimension.
- key: :math:`(S, E)` or :math:`(S, N, E)`, where S is the source sequence length, N is the batch size, E is
the embedding dimension.
- value: :math:`(S, E)` or :math:`(S, N, E)` where S is the source sequence length, N is the batch size, E is
the embedding dimension.
- key_padding_mask: :math:`(S)` or :math:`(N, S)` where N is the batch size, S is the source sequence length.
If a FloatTensor is provided, it will be directly added to the value.
If a BoolTensor is provided, the positions with the
value of ``True`` will be ignored while the position with the value of ``False`` will be unchanged.
- attn_mask: 2D mask :math:`(L, S)` where L is the target sequence length, S is the source sequence length.
3D mask :math:`(N*num_heads, L, S)` where N is the batch size, L is the target sequence length,
S is the source sequence length. attn_mask ensures that position i is allowed to attend the unmasked
positions. If a BoolTensor is provided, positions with ``True``
are not allowed to attend while ``False`` values will be unchanged. If a FloatTensor
is provided, it will be added to the attention weight.
- static_k: :math:`(N*num_heads, S, E/num_heads)`, where S is the source sequence length,
N is the batch size, E is the embedding dimension. E/num_heads is the head dimension.
- static_v: :math:`(N*num_heads, S, E/num_heads)`, where S is the source sequence length,
N is the batch size, E is the embedding dimension. E/num_heads is the head dimension.
Outputs:
- attn_output: :math:`(L, E)` or :math:`(L, N, E)` where L is the target sequence length, N is the batch size,
E is the embedding dimension.
- attn_output_weights: Only returned when ``need_weights=True``. If ``average_attn_weights=True``, returns
attention weights averaged across heads of shape :math:`(L, S)` when input is unbatched or
:math:`(N, L, S)`, where :math:`N` is the batch size, :math:`L` is the target sequence length, and
:math:`S` is the source sequence length. If ``average_attn_weights=False``, returns attention weights per
head of shape :math:`(num_heads, L, S)` when input is unbatched or :math:`(N, num_heads, L, S)`.
"""
tens_ops = (query, key, value, in_proj_weight, in_proj_bias, bias_k, bias_v, out_proj_weight, out_proj_bias)
if has_torch_function(tens_ops):
return handle_torch_function(
multi_head_attention_forward,
tens_ops,
query,
key,
value,
embed_dim_to_check,
num_heads,
in_proj_weight,
in_proj_bias,
bias_k,
bias_v,
add_zero_attn,
dropout_p,
out_proj_weight,
out_proj_bias,
training=training,
key_padding_mask=key_padding_mask,
need_weights=need_weights,
attn_mask=attn_mask,
is_causal=is_causal,
use_separate_proj_weight=use_separate_proj_weight,
q_proj_weight=q_proj_weight,
k_proj_weight=k_proj_weight,
v_proj_weight=v_proj_weight,
static_k=static_k,
static_v=static_v,
average_attn_weights=average_attn_weights,
)
is_batched = _mha_shape_check(query, key, value, key_padding_mask, attn_mask, num_heads)
# For unbatched input, we unsqueeze at the expected batch-dim to pretend that the input
# is batched, run the computation and before returning squeeze the
# batch dimension so that the output doesn't carry this temporary batch dimension.
if not is_batched:
# unsqueeze if the input is unbatched
query = query.unsqueeze(1)
key = key.unsqueeze(1)
value = value.unsqueeze(1)
if key_padding_mask is not None:
key_padding_mask = key_padding_mask.unsqueeze(0)
# set up shape vars
tgt_len, bsz, embed_dim = query.shape
src_len, _, _ = key.shape
key_padding_mask = _canonical_mask(
mask=key_padding_mask,
mask_name="key_padding_mask",
other_type=_none_or_dtype(attn_mask),
other_name="attn_mask",
target_type=query.dtype
)
if is_causal:
attn_mask = None
# emb dim 체크
assert embed_dim == embed_dim_to_check, \
f"was expecting embedding dimension of {embed_dim_to_check}, but got {embed_dim}"
if isinstance(embed_dim, torch.Tensor):
# embed_dim can be a tensor when JIT tracing
head_dim = embed_dim.div(num_heads, rounding_mode='trunc')
else:
head_dim = embed_dim // num_heads
# MH에 대해 나눠진 embed check
assert head_dim * num_heads == embed_dim, f"embed_dim {embed_dim} not divisible by num_heads {num_heads}"
if use_separate_proj_weight:
# allow MHA to have different embedding dimensions when separate projection weights are used
assert key.shape[:2] == value.shape[:2], \
f"key's sequence and batch dims {key.shape[:2]} do not match value's {value.shape[:2]}"
else:
assert key.shape == value.shape, f"key shape {key.shape} does not match value shape {value.shape}"
#
# compute in-projection
#
if not use_separate_proj_weight:
assert in_proj_weight is not None, "use_separate_proj_weight is False but in_proj_weight is None"
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
else:
assert q_proj_weight is not None, "use_separate_proj_weight is True but q_proj_weight is None"
assert k_proj_weight is not None, "use_separate_proj_weight is True but k_proj_weight is None"
assert v_proj_weight is not None, "use_separate_proj_weight is True but v_proj_weight is None"
if in_proj_bias is None:
b_q = b_k = b_v = None
else:
b_q, b_k, b_v = in_proj_bias.chunk(3)
q, k, v = _in_projection(query, key, value, q_proj_weight, k_proj_weight, v_proj_weight, b_q, b_k, b_v)
# prep attention mask
attn_mask = _canonical_mask(
mask=attn_mask,
mask_name="attn_mask",
other_type=_none_or_dtype(key_padding_mask),
other_name="key_padding_mask",
target_type=q.dtype,
check_other=False,
)
if attn_mask is not None:
# ensure attn_mask's dim is 3
if attn_mask.dim() == 2:
correct_2d_size = (tgt_len, src_len)
if attn_mask.shape != correct_2d_size:
raise RuntimeError(f"The shape of the 2D attn_mask is {attn_mask.shape}, but should be {correct_2d_size}.")
attn_mask = attn_mask.unsqueeze(0)
elif attn_mask.dim() == 3:
correct_3d_size = (bsz * num_heads, tgt_len, src_len) # batch size
if attn_mask.shape != correct_3d_size:
raise RuntimeError(f"The shape of the 3D attn_mask is {attn_mask.shape}, but should be {correct_3d_size}.")
else:
raise RuntimeError(f"attn_mask's dimension {attn_mask.dim()} is not supported")
# add bias along batch dimension (currently second)
if bias_k is not None and bias_v is not None:
assert static_k is None, "bias cannot be added to static key."
assert static_v is None, "bias cannot be added to static value."
k = torch.cat([k, bias_k.repeat(1, bsz, 1)]) # repeat => 해당 dim으로만 늘리기 : batch size만큼 늘리기!
v = torch.cat([v, bias_v.repeat(1, bsz, 1)])
if attn_mask is not None:
attn_mask = pad(attn_mask, (0, 1))
if key_padding_mask is not None:
key_padding_mask = pad(key_padding_mask, (0, 1))
else:
assert bias_k is None
assert bias_v is None
#
# reshape q, k, v for multihead attention and make em batch first
#
q = q.view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1) # 배치 먼저
if static_k is None:
k = k.view(k.shape[0], bsz * num_heads, head_dim).transpose(0, 1) # 배치 먼저
else:
# TODO finish disentangling control flow so we don't do in-projections when statics are passed
assert static_k.size(0) == bsz * num_heads, \
f"expecting static_k.size(0) of {bsz * num_heads}, but got {static_k.size(0)}"
assert static_k.size(2) == head_dim, \
f"expecting static_k.size(2) of {head_dim}, but got {static_k.size(2)}"
k = static_k
if static_v is None:
v = v.view(v.shape[0], bsz * num_heads, head_dim).transpose(0, 1) # 배치 먼저
else:
# TODO finish disentangling control flow so we don't do in-projections when statics are passed
assert static_v.size(0) == bsz * num_heads, \
f"expecting static_v.size(0) of {bsz * num_heads}, but got {static_v.size(0)}"
assert static_v.size(2) == head_dim, \
f"expecting static_v.size(2) of {head_dim}, but got {static_v.size(2)}"
v = static_v
# add zero attention along batch dimension (now first)
if add_zero_attn:
zero_attn_shape = (bsz * num_heads, 1, head_dim)
k = torch.cat([k, torch.zeros(zero_attn_shape, dtype=k.dtype, device=k.device)], dim=1)
v = torch.cat([v, torch.zeros(zero_attn_shape, dtype=v.dtype, device=v.device)], dim=1)
if attn_mask is not None:
attn_mask = pad(attn_mask, (0, 1))
if key_padding_mask is not None:
key_padding_mask = pad(key_padding_mask, (0, 1))
# update source sequence length after adjustments
src_len = k.size(1)
# merge key padding and attention masks
if key_padding_mask is not None:
assert key_padding_mask.shape == (bsz, src_len), \
f"expecting key_padding_mask shape of {(bsz, src_len)}, but got {key_padding_mask.shape}"
key_padding_mask = key_padding_mask.view(bsz, 1, 1, src_len). \
expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
if attn_mask is None:
attn_mask = key_padding_mask
else:
attn_mask = attn_mask + key_padding_mask
# adjust dropout probability
if not training:
dropout_p = 0.0
#
# (deep breath) calculate attention and out projection
#
if need_weights:
B, Nt, E = q.shape
q_scaled = q / math.sqrt(E)
if attn_mask is not None:
attn_output_weights = torch.baddbmm(attn_mask, q_scaled, k.transpose(-2, -1)) # https://pytorch.org/docs/stable/generated/torch.baddbmm.html => batch matrix-matrix product add bias
else:
attn_output_weights = torch.bmm(q_scaled, k.transpose(-2, -1))
attn_output_weights = softmax(attn_output_weights, dim=-1)
if dropout_p > 0.0:
attn_output_weights = dropout(attn_output_weights, p=dropout_p)
attn_output = torch.bmm(attn_output_weights, v)
attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len * bsz, embed_dim)
attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
attn_output = attn_output.view(tgt_len, bsz, attn_output.size(1))
# optionally average attention weights over heads
attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
if average_attn_weights:
attn_output_weights = attn_output_weights.mean(dim=1)
if not is_batched:
# squeeze the output if input was unbatched
attn_output = attn_output.squeeze(1)
attn_output_weights = attn_output_weights.squeeze(0)
return attn_output, attn_output_weights
else:
# attn_mask can be either (L,S) or (N*num_heads, L, S)
# if attn_mask's shape is (1, L, S) we need to unsqueeze to (1, 1, L, S)
# in order to match the input for SDPA of (N, num_heads, L, S)
if attn_mask is not None:
if attn_mask.size(0) == 1 and attn_mask.dim() == 3:
attn_mask = attn_mask.unsqueeze(0)
else:
attn_mask = attn_mask.view(bsz, num_heads, -1, src_len)
q = q.view(bsz, num_heads, tgt_len, head_dim)
k = k.view(bsz, num_heads, src_len, head_dim)
v = v.view(bsz, num_heads, src_len, head_dim)
attn_output = scaled_dot_product_attention(q, k, v, attn_mask, dropout_p, is_causal) # 이거 그냥 c로 구현되어 있음 => 결국 가장 궁금했던 attention 치는 부분은 C로 구현해서 최적화를 했다~ 로 귀결.
attn_output = attn_output.permute(2, 0, 1, 3).contiguous().view(bsz * tgt_len, embed_dim)
attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
attn_output = attn_output.view(tgt_len, bsz, attn_output.size(1))
if not is_batched:
# squeeze the output if input was unbatched
attn_output = attn_output.squeeze(1)
return attn_output, None

MLOps, ML Engineer. 데이터에서 시스템으로, 시스템에서 가치로.