1. 멀티 인덱스
멀티 인덱스는 하나 이상의 인덱스를 사용하여 데이터프레임의 행과 열을 구조화하는 방법이다.
이는 다차원 데이터를 보다 효율적으로 관리하고 분석할 수 있게 해준다.
1. set_index()로 멀티 인덱스 설정
data = {
"도시" : ["서울", "서울", "부산", "부산"],
"년도" : [2021, 2022, 2021, 2022],
"인구수" : [9700000, 9720000, 3400000, 3450000]
}
df = pd.DataFrame(data)
# "도시"와 "년도"를 멀티 인덱스로 설정
df_multi_index = df.set_index(["도시", "년도"])
print(df_multi_index)
2. pd.MultiIndex.from_tuples()로 멀티 인덱스 생성
- 지금 단계에서는 직접 매핑하는 모습을 띄기 때문에 불필요하다는 생각이 듦
# 멀티 인덱스를 튜플로 직접 생성
index = pd.MultiIndex.from_tuples([
("서울", 2021),
("서울", 2022),
("부산", 2021),
("부산", 2022),
], names = ["도시", "년도"])
# 데이터프레임에 적용
df_multi_index = pd.DataFrame({"인구수" : [9700000, 9720000, 3400000, 3450000]},index = index)
print(df_multi_index)
멀티 인덱스 데이터 접근
- 이 부분에서 멀티 인덱스의 장점이 보임
- DataFrame > Series의 index는 자동 매핑됨
슬라이싱
- 단 주의해야 할 것은 판다스가 멀티 인덱스를 사용하는 것에는 성능적인 것의 이점이 있어서 인데 슬라이싱을 통해 구간의 데이터를 쉽게 선택하고자 할 때 데이터가 정렬되어 있지 않다면 에러가 발생되게 된다
xs()를 사용한 멀티 인덱스 교차 선택
- xs()는 특정 레벨에서 데이터를 선택하거나, 레벨을 넘어서 데이터를 선택할 때 유용함
df_multi_index.loc["서울"] # 연도 인덱스로 추가 접근이 가능해짐
# 즉
df_multi_index.loc["서울", 2021]
# 이렇게 말이다
# 인덱스 확인방법은
df_multi_index.loc["서울"].index
# 해보면 서울의 모든 인덱스 값인 연도가 보이게 된다
# 슬라이싱 -> 부산에 해당하는 값들만 뽑아오게 함
df_multi_index = df_multi_index.sort_index()
df_multi_index.loc["부산":"부산"]
# xs() : "도시" 레벨 단에서 "서울"의 데이터를 선택함, 즉 "도시" 단은 보이지 않게 됨
df_multi_index.xs("서울", level="도시")unstack()과 stack()으로 인덱스 변환
- unstack()은 멀티 인덱스 -> 열로 변환
- stack()은 열 -> 인덱스로 변환
그룹화와 함께 사용
-
멀티 인덱스는 그룹화와 함께 사용할 때 더 강력해짐. 그룹화된 데이터를 멀티 인덱스로 변환하여 복잡한 분석을 수행할 수 있음
-
그룹화를 하면 자동으로 멀티 인덱싱이 되어짐
data = {
"도시" : ["서울", "서울", "부산", "부산"],
"년도" : [2021, 2022, 2021, 2022],
"인구수" : [9700000, 9720000, 3400000, 3450000],
"소독" : [6000, 6200, 3000, 3300]
}
df = pd.DataFrame(data)
grouped_df = df.groupby(["도시", "년도"]).mean()
# 그룹화만 진행했는데도 멀티 인덱싱 이점 사용 가능
grouped_df.loc["서울"]2. 데이터프레임 재구조화
pivot()을 사용한 피벗 테이블 생성
- pivot() 함수는 열 데이터를 행 또는 열로 이동시켜 새로운 데이터프레임을 만듦
- 사용처 : 서브 테이블을 만들고자 할 때
melt()를 사용한 데이터 구조 해체
- melt() 함수는 피벗된 데이터를 다시 긴 형식으로 변환할 때 사용됨
- 즉, 여러 열을 하나의 열로 통합하는데 유용함
- 열의 갯수가 많을 때 (연도별로 데이터가 나타나는 경우)에 유용함
# id_vars는 남겨둘 것
# value_vars는 같이 나타낼 것
melted_df = pd.melt(df, id_vars=["날짜", "도시"], value_vars=["온도", "습도"])
melted_dfstack()과 unstack()을 사용한 데이터 변환
- stack()은 열 데이터를 인덱스의 하위 레벨로 이동시키고,
- unstack()은 그 반대 작업을 수행함
- 멀티 인덱스 데이터프레임에서 유용함
- 중복된 인덱스가 있을 경우 unstack()을 수행하게 되면 에러가 발생할 수 있음
행과 열 삭제하기
- drop() 함수 사용
- axis=0은 행을, axis=1은 열을 삭제함
# 열 삭제
df_dropped = df.drop(columns=["습도"])
# 행 삭제
df_dropped_row = df.drop(index=0)알고리즘 - 2차원 배열
🧚
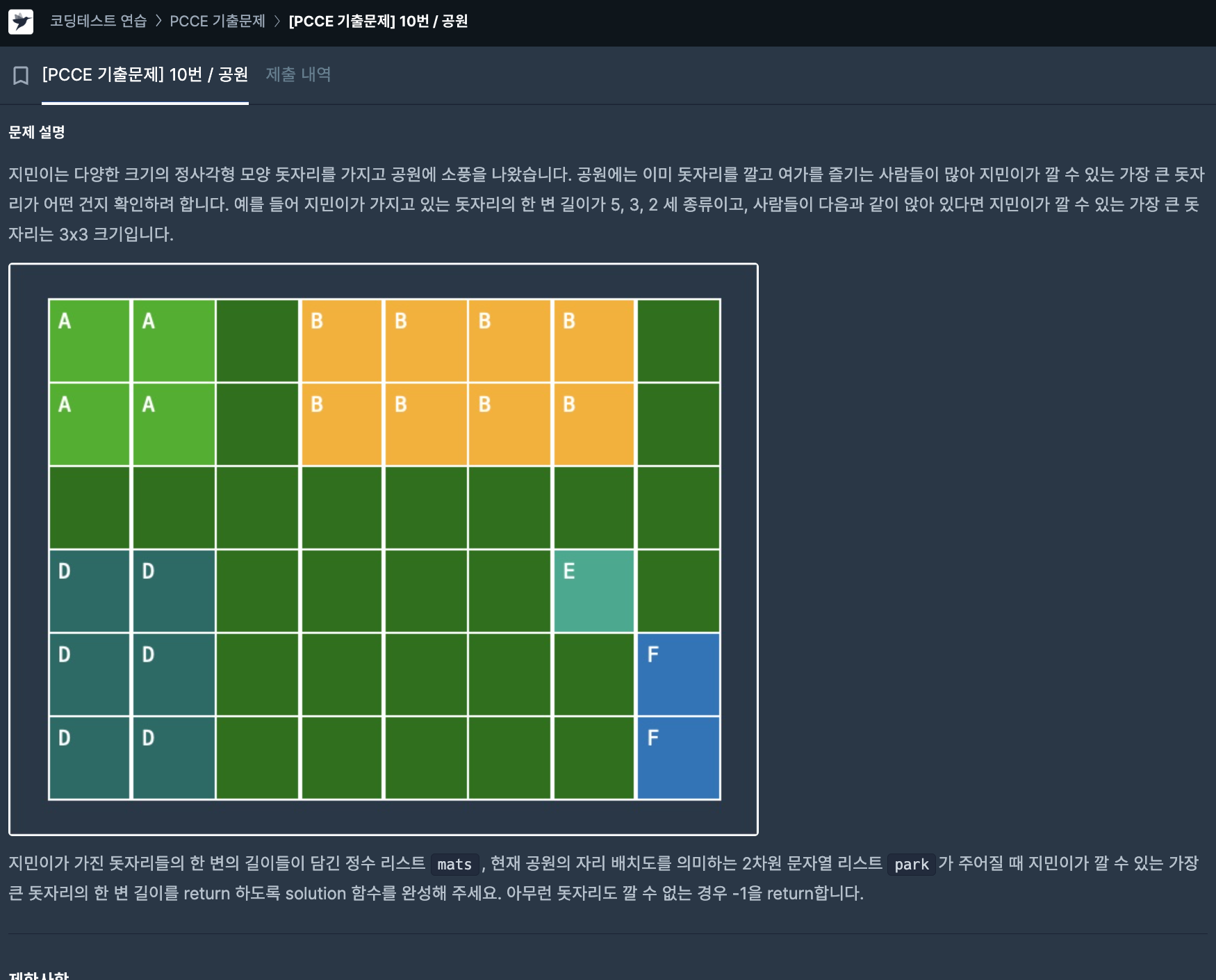
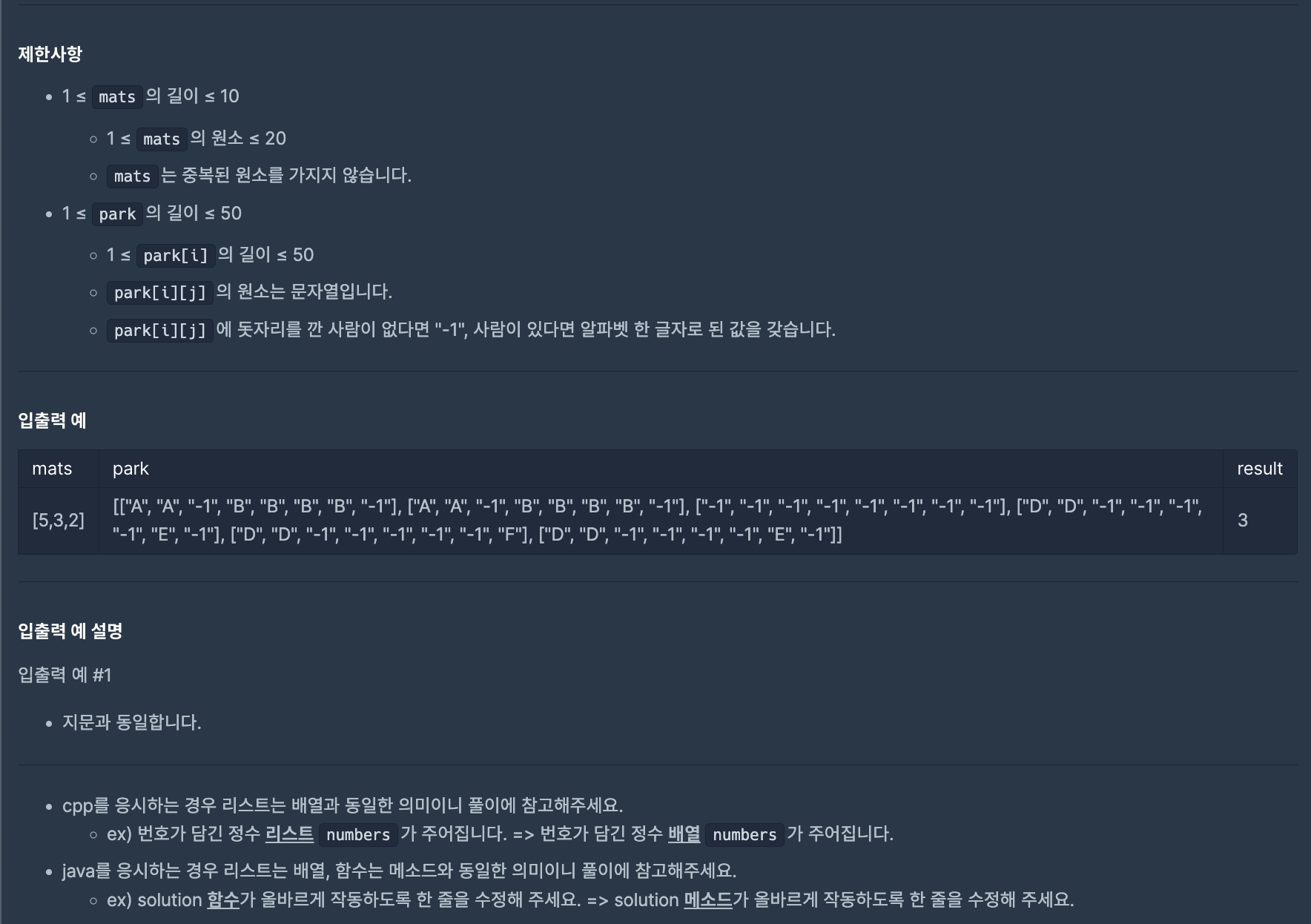
2차원 배열을 잘 다룰 수 있는지가 관건이 되었던 문제이다.
- -1이 integer 형이 아니라 string 형태임을 간과하고 반복해서 오류가 났었는데 이를 유의해서 해야겠다.
- 주어지는 park가 mat와는 다르게 정사각형이 아님을 간과했었다.
- 항상 반복문을 돌 때 +1을 놓쳐서 (닫힌 구간임을 염두하지 못하고) 같은 일부 테스트 코드를 실패하는 결과가 나타났었는데 이를 유의해 작성해야겠다.
📌
def solution(mats, park):
answer = -1
mats = sorted(mats)
length = len(park)
width = len(park[0])
# park 배열 직접 접근이 아닌 mat 크기를 이용한 접근으로 반복문을 돈다
for mat in mats:
for row in range(length-mat+1):
for col in range(width-mat+1):
cnt = 0
if park[row][col] != "-1":
continue
# 모든 쉘에 한해 매트를 깔 수 있는지를 확인하는 것이 아닌 -1에 해당하는 경우에만 반복문을 도는 것으로 한다
for i in range(row, row+mat):
for j in range(col, col+mat):
if park[i][j] == "-1":
cnt += 1
# 매트 크기 확인
if cnt == mat * mat:
answer = mat
return answer