https://www.youtube.com/watch?v=c33ojJ7kE7M&list=PLgXGHBqgT2TvpJ_p9L_yZKPifgdBOzdVH&index=170 영상을 보며 학습하였습니다.
참조 사이트 : https://startupdevelopers.tistory.com/238
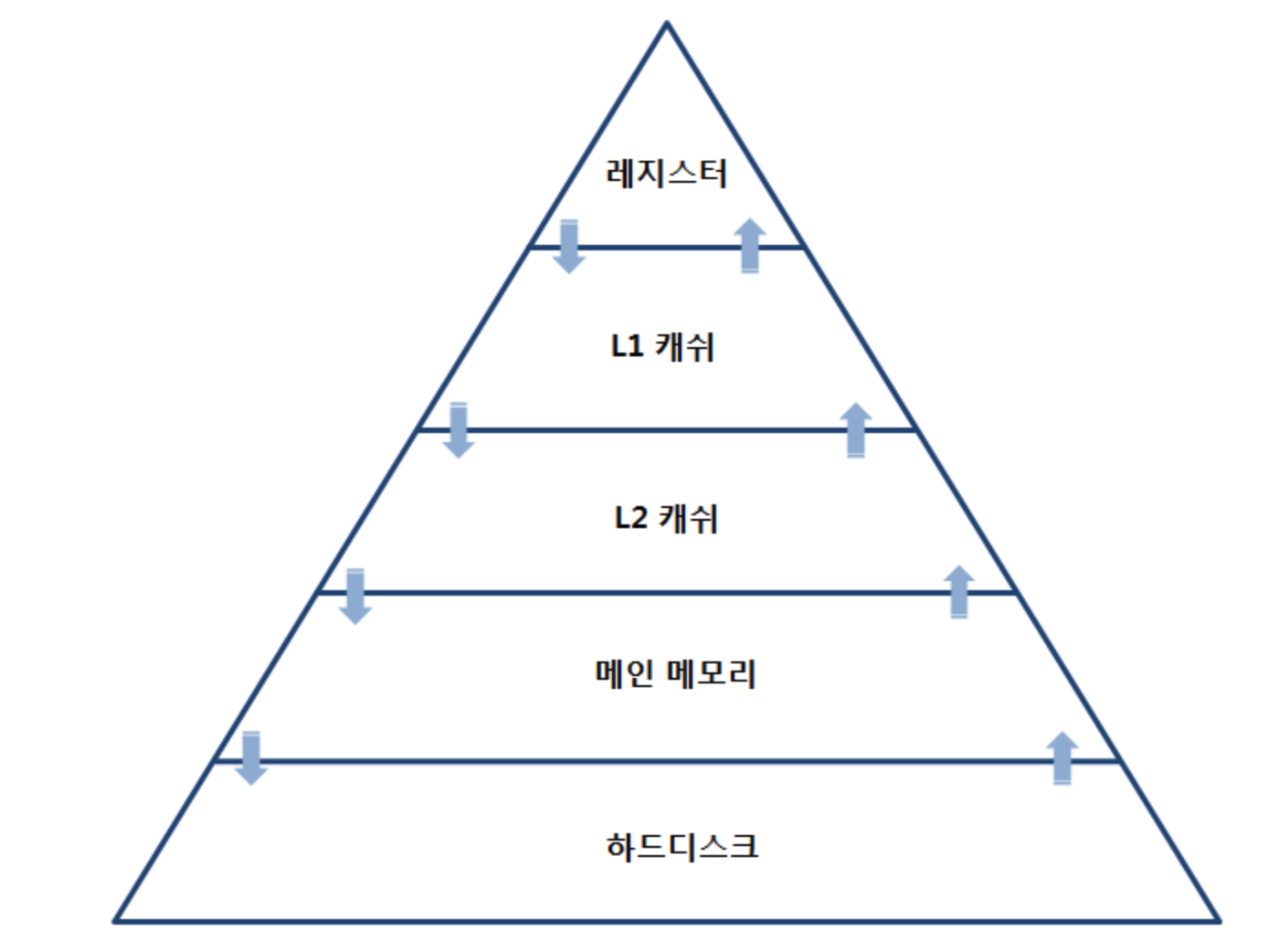
메모리 계층 구조
- 데이터를 저장하는 공간의 속도와 용량은 반비례 관계다.
- 속도가 빠른 메모리 일수록 용량이 작다.
- 용량이 큰 저장장치는 속도가 느리다.
- 둘다 잡기에는 비용이 너무 많이든다.
- 그래서 데이터 저장 공간은 속도와 용량에따라 특성에 맞게 역할을 나누어서 사용한다.
- 데이터 저장공간을 속도-용량 순서대로 쌓으면 마치 피라미드와 같은 현상이 나타난다.(Memory Hierarchy)
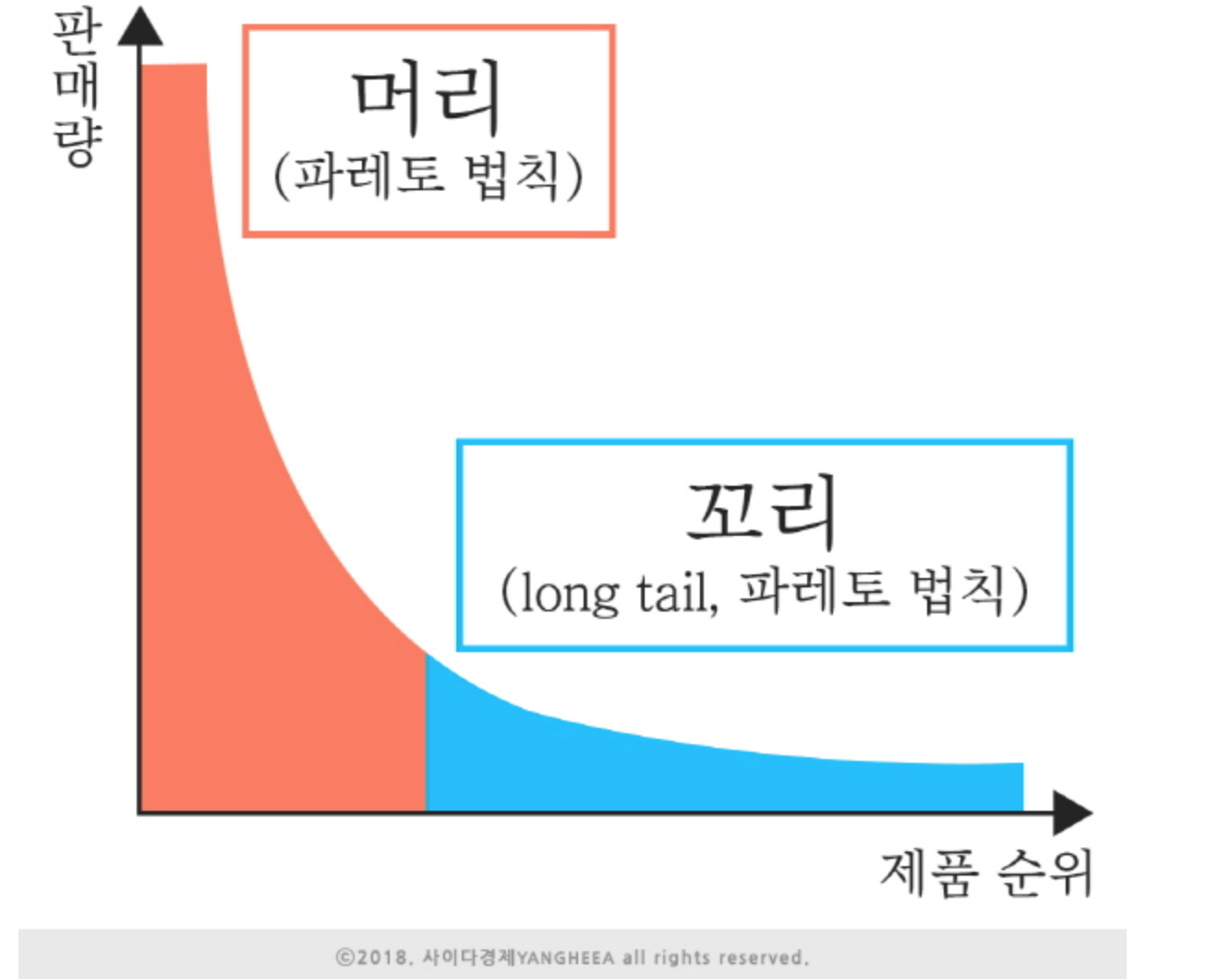
파레토의 법칙
- 이탈리아 경제학자 빌프레도 파레토가 발견한 현상
- 원인 중 상위 20%가 전체 결과의 80%를 만든다는 법칙
- 2대 8법칙 이라고도 한다.
- 여러 곳에서 관찰할 수 있다.
- 인구의 20%가 전체 부의 80%를 가지고있다.
- 잘 팔리는 제품 20%가 매출의 80%를 차지한다.
- 많이 쓰이는 단어 20%가 언어 사용빈도의 80%를 차지한다.
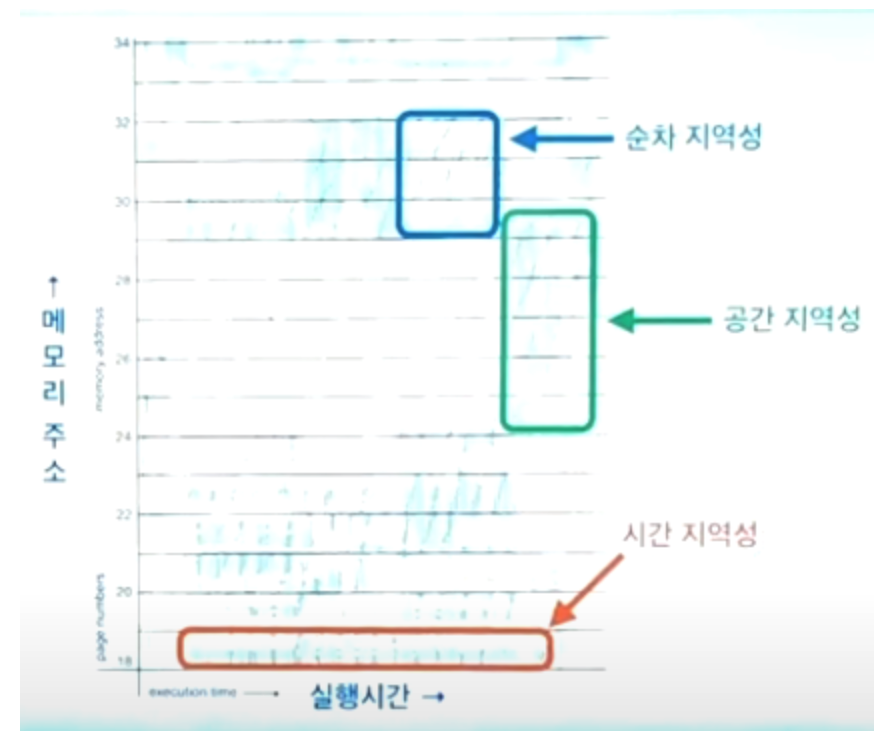
데이터 지역성의 원리
- 자주 쓰이는 데이터는 시간적 혹은 공간적으로 한 곳에 몰려 있을 가능성이 높다.
-
시간 지역성(temporal Locality) : for문에 조건변수(int i=0;)을 선언했을 때, 해당 변수는 for문이 끝나기 전까지 계속 쓰일 확률이 높은 것
-
공간 지역성(Spatial Locality) : 예를 들어 for문에서 어떤 배열에 접근했을 때, 해당 배열이 위치한 메모리 공간의 내용은 for문이 끝나기 전까지 계속 쓰일 확률이 높은 것
- for문에서 array[0], [1], [2].. 와 같이 배열에 접근할 때, 다음번에는 array[3]에 접근할 확률이 높은 것을 따로 분류하여 순차지역성(Sequential Locality)라고 부르기도 한다.
-
캐시
- 명사 : 나중에 필요할 수도 잇는 무언가를 저장하였다가 신속하게 회수할 수 있는 보관 장소로, 어떤 식으로든 보호되거나 숨겨진다.
캐시의 작동 방식
- 원본 데이터(System-of-Record)와는 별개로 자주 쓰이는 데이터(Hot Data)들을 복사해둘 캐시 공간을 마련한다.
- 캐시 공간은 상수 시간등 낮은 시간 복잡도로 접근 가능한 곳을 주로 사용한다.(HashMap 같은)
- 데이터를 달라는 요청이 들어오면, 원본 데이터가 담긴 곳에 접근하기 전에 먼저 캐시 내부부터 찾는다.
- 캐시에 원하는 데이터가 없거나 너무 오래되어 최신성을 잃게 될 경우 그때 원본 데이터가 있는 곳에 접근하여 데이터를 요청해 가져온다. 이때 데이터를 가져오면서 캐시에도 해당 데이터를 복사하거나 갱신한다.
- 캐시에 원하는 데이터가 있으면 원본 데이터가 있는 공간에 접근하지 않고 캐시에서 바로 해당 데이터를 제공한다.(Cache hit)
- 캐시 공간은 작으므로, 공간이 모자라게 되면 안쓰는 데이터부터 삭제하여 공간을 확보한다.
CPU의 캐시메모리
- 현대의 CPU는 1초에 최고 수십억 번 작동 가능
- 아무리 빠른 주기억장치라도 CPU를 따라가기 어렵다.
- 그래서 SRAM이라는 특수한 메모리를 CPU에 넣어 캐시메모리로 사용
하드디스크, 데이터베이스
- 하드디스크나 ssd나 주기억 장치에 비하면 매우 느리다.
- 처리 효율을 올리려면 자주 쓰이는 데이터를 캐싱해두는 것이 좋다.
- 데이터베이스 또한 쿼리를 실행하여 하드디스크에서 데이터를 읽고 쓰는 것은 시간이 오래 걸리는 작업
- 대개 데이터베이스는 쓰기보다는 읽기가 많으므로, 자주 요청받는 쿼리의 결과를 캐싱해두면 효율이 오른다.
- 따라서 데이터베이스 자체에서 별도의 캐시를 운영한다
- JPA 영속성 컨텍스트도 캐시의 일종이다. (1차캐시)
CDN(Content Delivery Network)
- 유튜브의 메인 서버는 미국에 있다.
- 한국과 미국을 잇는 국제 인터넷 회선은 비싸고 용량을 늘리기도 어렵다.
- 구글은 각 통신사마다 Google Global Cache를 두어 인기 있는 유튜브 동영상은 미국 서버까지 접속할 필요 없이 국내 서버에서 처리하도록 하였다.
- 비싼 국제 회선 비용이 절감되고, 버퍼링이 줄어 고화질 서비스의 이용 경험이 개선되었다.
- 이처럼 세계 각지에 캐시 서버를 두어 전송속도를 높이고 부하를 분산하는 시스템이 CDN이다.
웹 캐시
- 네트워크를 통해 데이터를 가져오는 것은 하드디스크보다도 느릴 때가 많다.
- 그래서 웹 브라우저는 웹 페이지에 접속할 때 HTML, CSS, 자바스크립트, 이미지 등을 하드디스크나 메모리에 캐싱해 뒀다가 다음 번에 다시 접속할 때 이를 재사용한다. (브라우저 캐시)
- 웹 서버 또한 상당수의 경우 동적 웹 페이지라 할지라도 매번 내용이 바뀌지 않는 경우가 더 많으므로, 서버에서 생성한 HTML을 캐싱해 뒀다가 다음 번 요청에 이를 재활용 한다. (응답 캐시)
- 이와 유사하게, 클라이언트에서 자주 요청받는 내용은 웹 서버로 전달하지 않고 웹 서버 앞단의 프록시 서버에서 캐싱해둔 데이터를 바로 제공하기도 한다. (프록시 캐시)
브라우저 캐시
- 엡 서버에서 클라이언트에 보내는 HTTP 헤더에 캐시 지시자를 삽입하면, 클라이언트 웹 브라우저에서는 해당 지시자에 명시된 캐시 정책에 따라 캐싱을 실시한다.
- 캐시의 유효 시간(max-age)이 지나도 캐시된 데이터가 바뀌지 않은 경우를 확인하기 위해 ETag라는 유효성 검사 토큰을 사용한다.
- 때로는 캐시 유효시간을 최대한 길게 잡으면서도 정적(static) 파일의 업데이트를 신속히 적용하기 위해 정적 파일의 이름 뒤에 별도의 토큰이나 버전 번호를 붙여야 하는 경우도 있다.
- 캐시 정책은 해당 웹페이지의 전반적인 상황에 따라 각 파일마다 다르게 적용되어야 한다. 적어도 정적 파일과 동적인 부분의 브라우저 캐싱 정책은 달라야한다. 비공개 정보가 담긴 페이지는 보안상 아예 캐싱을 막아야 할 수도 있다.
Redis
- 메모리 기반 오픈소스 NoSQL DBMS일종으로 웹 서비스에서 캐싱을 위해 많이 쓴다.
- Redis라는 이름은 Remote Dictionary Server의 약자이다.
- 여기서 Dictionary는 Java의 HashMap<Key, Value>을 생각하면 된다.
- 기본적으로 모든 데이터를 메모리에 저장하여 처리하므로 속도가 빠르다.
- 서버 재부팅 때 메모리의 데이터가 휘발되지 않게끔 데이터를 하드디스크에 기록할 수 있다.
- DBMS의 일종이므로, 명시적으로 삭제하지 않는 한 메모리에서 데이터를 삭제하지 않는다.
- 자체적으로 여러 가지 자료형을 지원한다.
EHcache
- Java의 표준 캐싱 API 명세인 JSR-107을 따르는 오픈소스 캐시 구현체
- Spring 프레임워크나 Hibernate ORM 등에서 바로 사용이 가능하다.
- 자바 진영에서 가장 널리 쓰인다고 한다.
- 캐시 저장공간을 속도에 따라 여러 등급(Tier)으로 나누어 메모리 계층 구조를 적용 가능
- 메모리에 캐시된 내용을 하드디스크에 기록 가능
- 대규모 서비스에서 캐시 서버 여럿을 클러스터로 묶을 수 있는 기능을 제공
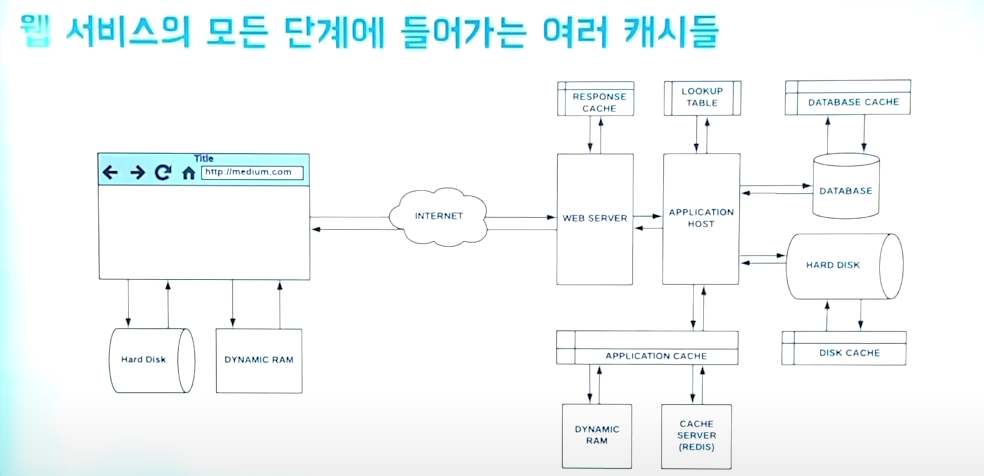
캐싱이라는 것은 정말 많은 곳에서 사용한다.
캐시를 이해하기 위해서 알아야 하는 기본 지식을 포함해서 설명을 해주셨는데 정말 도움이 많이 되었다.

꾸준하게 성실하게