1. 피쳐 중요도
- 선형 모델의 각 피처 중요도는 해당 피처의 가중치의 절대값을 통해 평가
- 가중치의 절대값이 클수록, 해당 피처는 모델의 에측에 더 큰 영향을 미침
- 선형 모델에서 피처의 스케일이 다를 경우, 가중치를 직접 비교하기 전에 모든 피처를 동일한 스케일로 조정 (Standardscaler 일듯)
파일 가져오는것과, 트리 모델써서 피쳐 중요도 찾기
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
housing_df = pd.read_csv('californial_housing.csv')
housing_df.head()
# 피처와 타겟 변수 분리
X = housing_df.drop('target', axis=1)
y = housing_df['target']
model_dt = DecisionTreeRegressor(random_state=42)
model_dt.fit(X, y)
# 피처 중요도 추출
feature_importances_dt = model_dt.feature_importances_
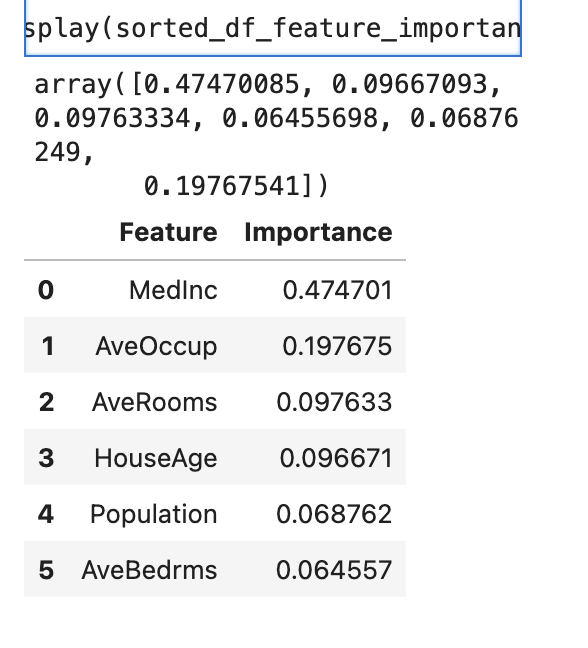
display(feature_importances_dt)
# feature_importances와 X.columns을 이용하여 중요도가 높은 순서로 정렬하여 출력
df_feature_importances_dt = pd.DataFrame({'Feature': X.columns, 'Importance': feature_importances_dt})
sorted_df_feature_importances_dt = df_feature_importances_dt.sort_values(by='Importance', ascending=False).reset_index(drop=True)
display(sorted_df_feature_importances_dt)여기서 각 피쳐 중요도는, 해당 피처의 중요도의 절대값으로 판단.
모델을 학습시킨 다음, featureimportances 함수 쓰는게 중요!
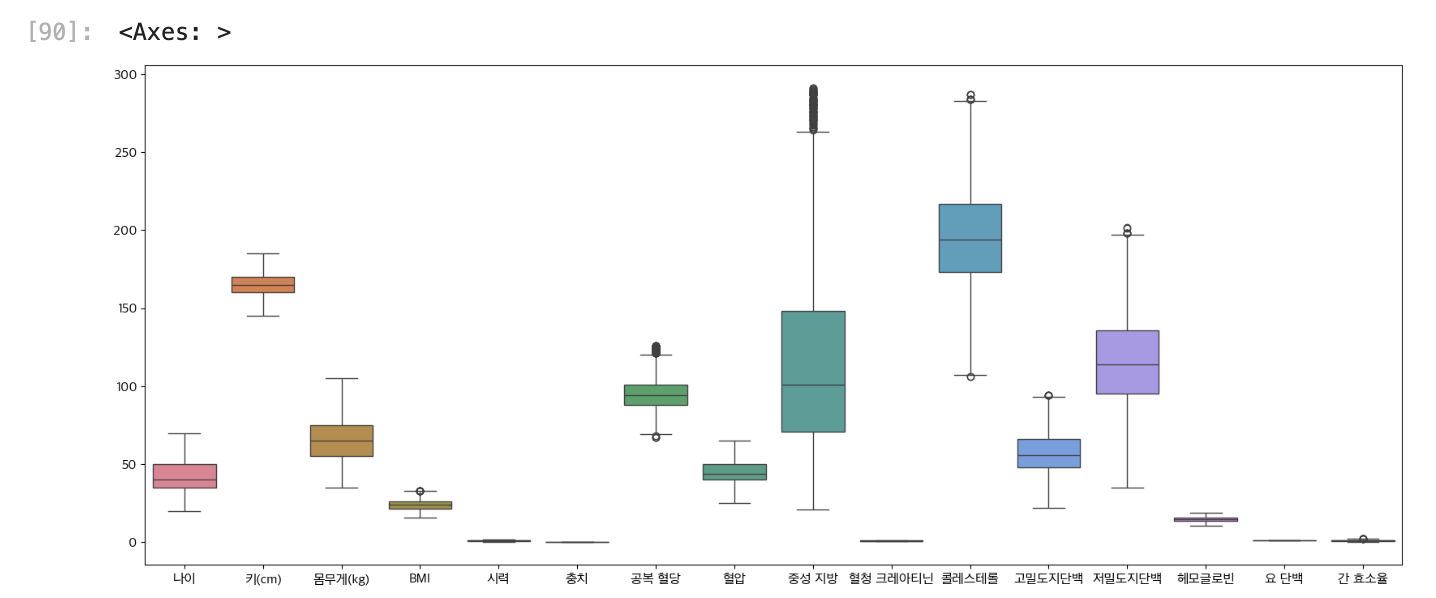
2. IQR 이상치 정리
이거는 quantile 함수나 percentile 함수 써서 데이터 outlier 들을 제거하는 방법
나는 quantile 함수를 활용해서 제거해봤다
할 때 내가 한것 외에 수정된 부분이 있는데, num_cols에다가 X.select_dtypes(include = "number").columns를 묶어서 숫자형 컬럼만 대상으로 계산 한 것임.

여기 num_cols 에는 칼럼들 이름들만 들어가 있다.
전처리 할 때 애초에 문자형 데이터를 숫자형으로 엔코딩 해주기는 하는데, 그래도 이렇게 하는게 더 에러 뜰 확률을 조금이나마 줄여 준다고 한다.
import pandas as pd
# 숫자형 컬럼만 대상으로 하는 게 보통 좋음
num_cols = X.select_dtypes(include="number").columns
# 처음에는 전부 True인 마스크 (모든 행을 살려두고 시작)
mask = pd.Series(True, index=X.index)
for col in num_cols:
Q1 = X[col].quantile(0.25)
Q3 = X[col].quantile(0.75)
IQR = Q3 - Q1
upper = Q3 + 1.5 * IQR
lower = Q1 - 1.5 * IQR
# 해당 컬럼에서만 유효한 값
col_mask = (X[col] >= lower) & (X[col] <= upper)
# 전체 마스크에 AND로 누적
mask &= col_mask
# 루프 다 돈 뒤에 한 번만 필터링
X_clean = X[mask].copy()
y_clean = y[mask].copy()결과 파일. for문을 사용해서
3. 표준화 StandardScaler
학습 하기 전에 데이터 스케일링
scaler = StandardScaler()를 적용해서
거리기반 모델들이 피쳐들을 학습할 때 전부 동일한 조건에서 학습하도록 해줌
요 두 과정을 거치면 굿
# 피처 스케일링
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
4. 가중치(계수) coefficient
각 피쳐의 영향력 있는 숫자들
위에서 하고 마지막에 가중치들 각각 피쳐별로 구할 때
# 피처의 가중치를 피처 중요도로 사용 (스케일링된 모델)
feature_importances_lr = abs(model_lr_scaled.coef_)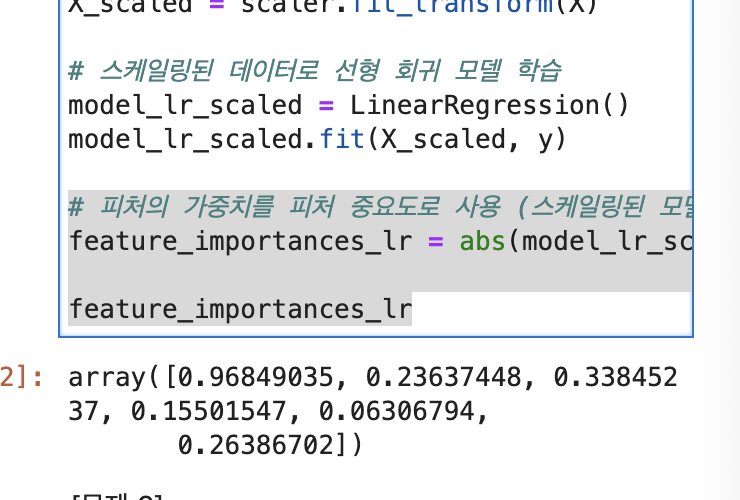
5. 피처선택
1. 필터 방법(filter)
모델 학습 전에 피처들의 통계적 특성을 평가하여 중요도를 측정하는 방법.
계산비용이 낮고 빠르며, 대규모 데이터 스케일링 용이
ex) 상관계수, 상호정보량, 카이제곱 검정 등. 연관성이 낮은 피쳐들 제거
2. 래퍼 방법(wrapper)
실제로 데이터를 바탕으로 모델을 여러 번 학습시키면서, 각각의 피쳐 집합이 얼마나 좋은 성능을 내는지를 평가.
각각의 피쳐 집합이 얼마나 좋은 성능을 내는지 평가. 최적의 피쳐 조합 찾아냄.
사이킷런의 feature_selection 모듈에서 SequentialFeatureSelector 클래스 사용한다.
코드 학습 단계는
1. 모델 파이프 라인으로 묶어서 그 안에 scaler와 logisticRegressor 모델
2. SequentialFeatureSelector 으로 피처 모델 선택. 이때 estimator에 파이프 라인 모델 넣으면 됨. direction으로 'forward'으로 하나씩 추가해 나가는 방식.
3. sfs 피처 모델 학습.
4. 선택된 피처 확인
from sklearn.linear_model import LogisticRegression
from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
# 1. 모델 + 스케일러 파이프라인 정의
model = Pipeline([
("scaler", StandardScaler()),
("clf", LogisticRegression(max_iter=1000))
])
# 2. 순차적 피처 선택 (Forward Selection)
sfs = SequentialFeatureSelector(
estimator=model, # 이 모델 성능으로 피처 선택
n_features_to_select=5, # 고를 피처 개수
direction="forward", # 하나씩 추가해 나가는 방식
cv=5, # 5폴드 교차검증으로 성능 평가
n_jobs=-1 # 코어 여러 개 있으면 병렬 처리
)
# 3. 피처 선택 실행 (X, y는 기존 데이터)
sfs.fit(X, y)
# 4. 선택된 피처 확인
selected_mask = sfs.get_support() # True/False 마스크
selected_features = X.columns[selected_mask]
print("선택된 피처들:")
print(selected_features)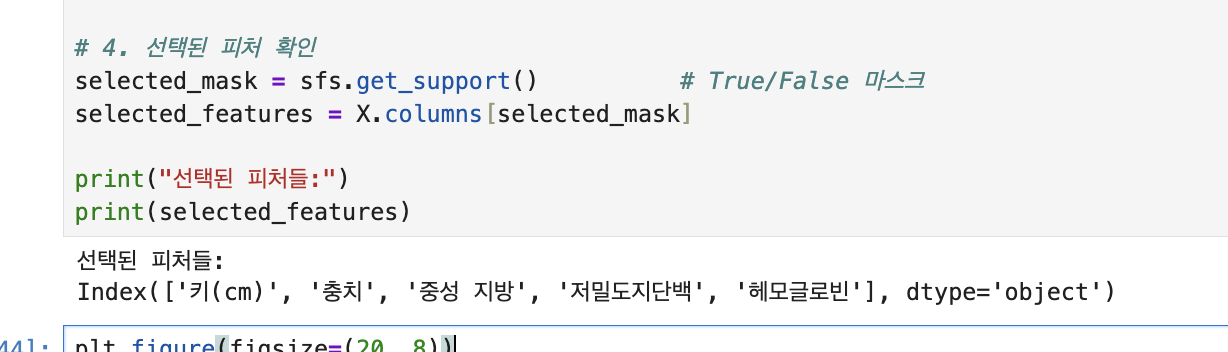
하나하나 다 빼보면서 돌려본것보단 못 나오긴 했는데, 그래도 기본 평균 이상은 잘 나오는듯.
래퍼 방법 써서 나온 피처가 키(cm) 충치 중성 지방 저밀도지단백 헤모글로빈
요렇게 나와서 이대로 돌려봤다.
3. 임베디드 방법 (Embedded Methods)
피처 선택을 모델 학습 과정 자체에 내장하는 매우 효율적인 접근법
모델이 스스로 피처의 중요도를 계산하고, 불필요한 피처를 거의 무시하는 방식을 사용하는데,
임베디드 방식은 LightGBM, XGBoost, CatBoost 같은 트리 기반 모델에서 자동적으로 information / split gain을 사용하여 의미없는 피처를 사실상 제거하게 됨.
그렇지만, 기계적으로 피처를 제거하는 방식은 아니기에, 원시적인 방법으로 중요도를 판단하고 넣고 빼고하는 거는 개발자의 역량에 달려있는 듯.
