LightGBM 개념
일단 데이터를 분석하는게 가장 중요하다.
여기 월간 데이콘 신용카드 사용자 연체 예측 AI 경진대회 데이터의 칼럼을 보면,
family_type 이 있는데 이는 범주형 데이터니 숫자로 변형해준다
LightGBM 모델은 결측치와 범주형 변수를 자동으로 처리할 수 있는 기능이 있어, 모델 학습에서 별도의 전처리 없이도 학습 가능! LightGBM 모델의 자체 결측치 및 범주형 변수 처리 능력에만 의존하는 것은 성능 향상에 한계가 있음. LightGBM 모델을 기본 모델로 사용하면서 다양한 전처리 기법과 결합하여 성틍 비교하는 접근방식 필요
Gradient Boosting 방식을 통해 이저너 모델의 오차를 다음 트리가 보완해나가는 방법으로 평가지표 올림. 매 반복마다 현재 예측의 loss 를 계산하고 loss의 gradient(경사 방향)/hessian(경사의 급감도) 계산 그걸 가장 잘 줄이는 트리를 선택 그리고 마지막에 예측 업데이트
base_lgbm = LGBMClassifier(random_state = 42)
base_lgbm.fit(X_train, y_train)<데이터 처리> 요거는 학습에 따른 검증 데이터 로그 손실 추이
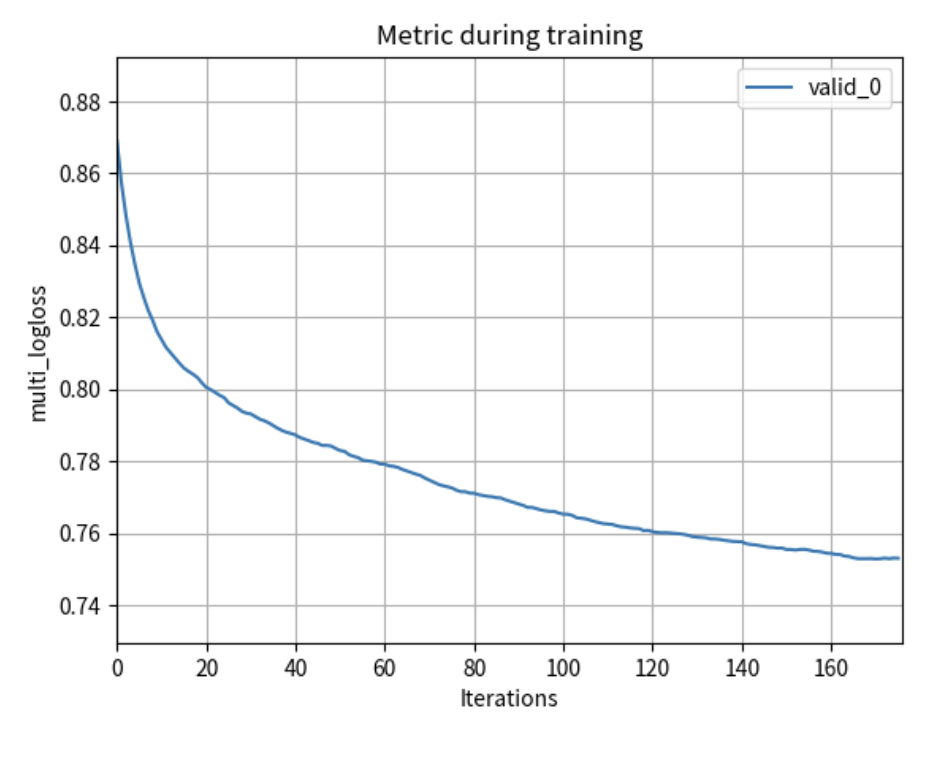
import lightgbm as lgb
import matplotlib.pyplot as plt
# 모델 학습 중 사용된 metric과 동일한 'multi_logloss'를 사용
loss_plot = lgb.plot_metric(tuning_lgbm.evals_result_, metric='multi_logloss')
plt.show()<데이터 처리2> 모델의 피처 중요도 평가
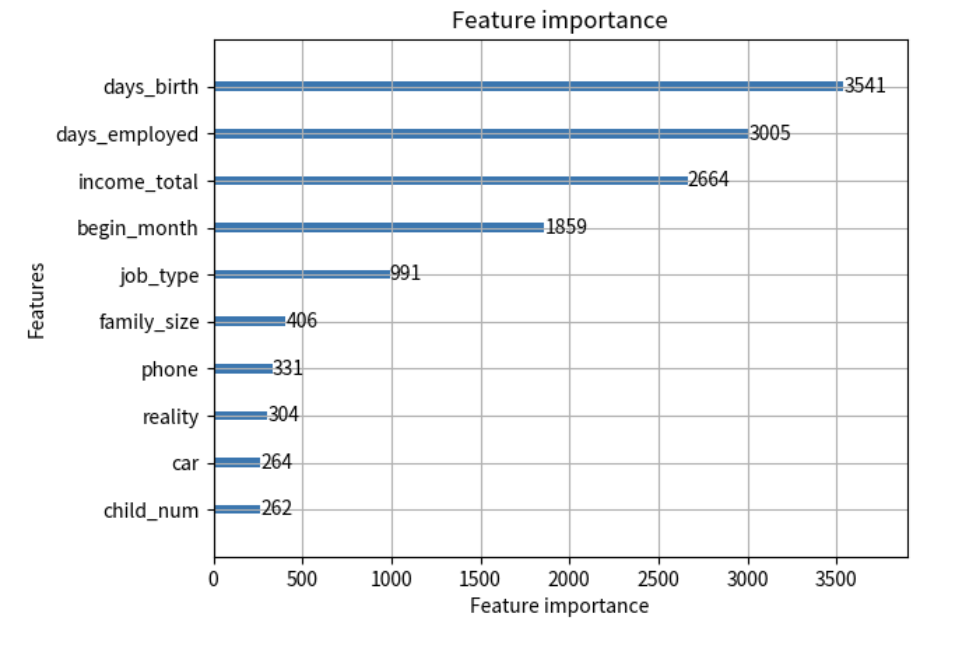
importance_plot = lgb.plot_importance(tuning_lgbm.booster_, max_num_features=10)
plt.show()XGBoost 랑 LightGBM 모델
XGBoost 는 Level-wise 접근 방식으로 모든 노드를 같은 레벨에서 확장한다
같은 깊이에 있는 모든 노들을 동시에 뻗음
시간이 오래걸리는 대신에 과적합 위험 적음.
데이터가 작고 과적합이 걱정될 때 + 안정성이 중요할 때 사용
LightGBM 는 Leaf-wise 방식을 사용해 손실 감소가 가장 큰 리크에서 성장을 수행한다.
손실을 가장 많이 줄일 수 있는 leaf 하나를 골라 거기만 집중적으로 확장
학습속도 빠르고 정확도가 큼 (큰 데이터의 경우), 작은 데이터먼 과적합 위험
큰 데이터에서 속도가 중요하고 성능 극대화가 목표일 때!
import pandas as pd
import time
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from xgboost import XGBClassifier
train = pd.read_csv('당뇨_train.csv')
target_col = 'Outcome'
target = train[target_col]
train = train.drop(['ID', target_col], axis = 1)
# 2. 학습 / 검증 데이터 분리
X_train, X_valid, y_train, y_valid = train_test_split(train, target, test_size=0.2, random_state=42)
# LightGBM 모델 학습
start_lgbm = time.time()
model_lgbm_classifier = LGBMClassifier(random_state = 42)
model_lgbm_classifier.fit(X_train, y_train)
end_lgbm = time.time()
# XGBoost 모델 학습
start_xgb = time.time()
model_xgb_classifier = XGBClassifier(random_state = 42)
model_xgb_classifier.fit(X_train, y_train)
end_xgb = time.time()
valid_score_lgbm_classifier = model_lgbm_classifier.score(X_valid, y_valid)
valid_score_xgb_classifier = model_xgb_classifier.score(X_valid, y_valid)
print("LGBM Classifier Validation Score:", valid_score_lgbm_classifier)
print("XGB Classifier Validation Score:", valid_score_xgb_classifier)
print("LGBM 모델의 학습 시간은", end_lgbm-start_lgbm,"초 입니다.")
print("XGB 모델의 학습 시간은", end_xgb-start_xgb,"초 입니다.")범주형 데이터 (object type) category로 바꾼다음 각 카테고리 범주형 라벨링 확인
# 독립, 종속변수 설정 및 고유값(title) 제거
train_target = train['box_off_num']
train_independent = train.drop(['title', 'box_off_num'], axis = 1)
test_independent = test.drop('title', axis = 1)
# 데이터 타입이 object인 칼럼(column) 찾기
object_cols = [col for col in train_independent.columns if train_independent[col].dtype == "object"]
# 데이터 타입이 object인 칼럼의 자료형을 category로 변경
train_independent[object_cols] = train_independent[object_cols].astype('category')
test_independent[object_cols] = test_independent[object_cols].astype('category')
# 자료형 변경 확인
train_independent.info()
for col in object_cols[:3]: # 앞 3개만 (원하면 [:]로 전체)
print(f"\n[{col}] value -> code")
inv = {v: i for i, v in enumerate(train_independent[col].cat.categories)}
# 앞 10개만 보기
for k in list(inv.keys())[:10]:
print(k, "->", inv[k])l2 점수 개념
l2 score는 값들의 제곱갑(또는 제곱합의 제곱근) 얼마나 크냐를 재는 수치

ex 원점에서 (3, 4) 점의 값이 얼마나 크냐? 이때의 l2점수는 5!
ex 실제 값이 3, 5, 1 이고 / 예측값이 2, 5, 3 이면 (3-1)² + (5-5)² + (1-3)² = 8(l2점수)
요게 바로 MSE(Mean Squared Error)의 핵심
booster_
피쳐 중요도 확인
lgb.plotimportance 클래스는 lightgb 모델이 학습한 booster 형태의 데이터를 필요로 해서 붙여 주어야 함.
인코딩 작업
사람이 이해하는 문자/범주 데이터를
컴퓨터(모델)가 계산할 수 있는 "숫자"로 바꾸는 작업
but LightGBM 모델은 자체적으로 인코딩 작업을 하기 때문에 object 타입의 데이터를 가지고 있는 칼럼들만 category 타입으로 바꿔주면 됨!
