25년 11월 11일 빼빼로 데이다. 마트에서 빼빼로 사다가 좋아하는 애들한테 주는 날. .... 그렇다네 ㅎㅎ
이번 글에서 정리할 내용은 DBSCAN
DBSCAN은 Densiry-Based Spatial Clustering로 앞에서 했던 k-means나 mean shift랑 비슷한 느낌이라고 하는데, 사진을 보면 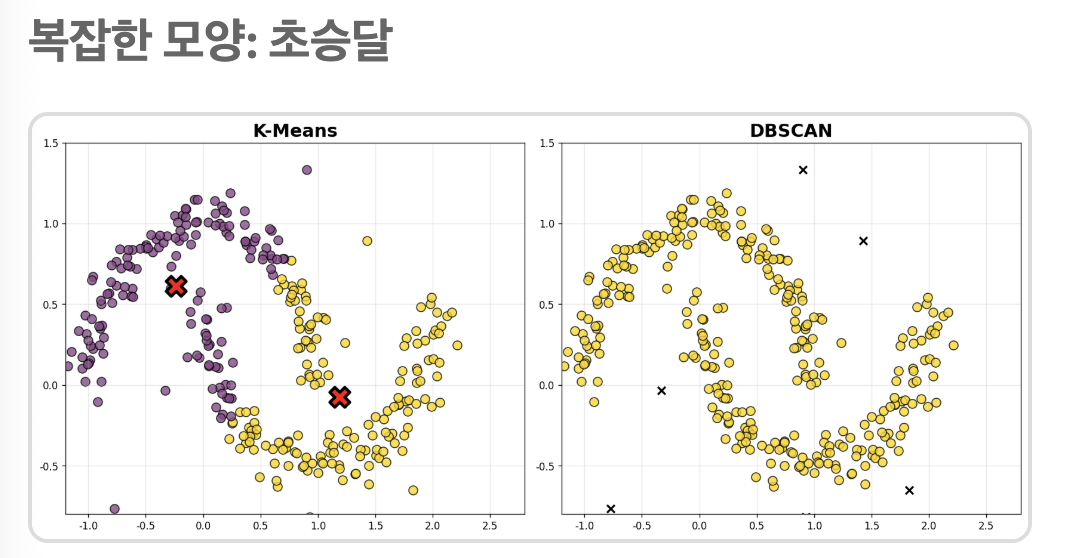
조금 더 복잡한 사진들을 군집으로 묶어서 보여주는 느낌. k-means는 제대로 초승달 모양을 확인하지 못하지만, dbscan은 제대로 보여준다.
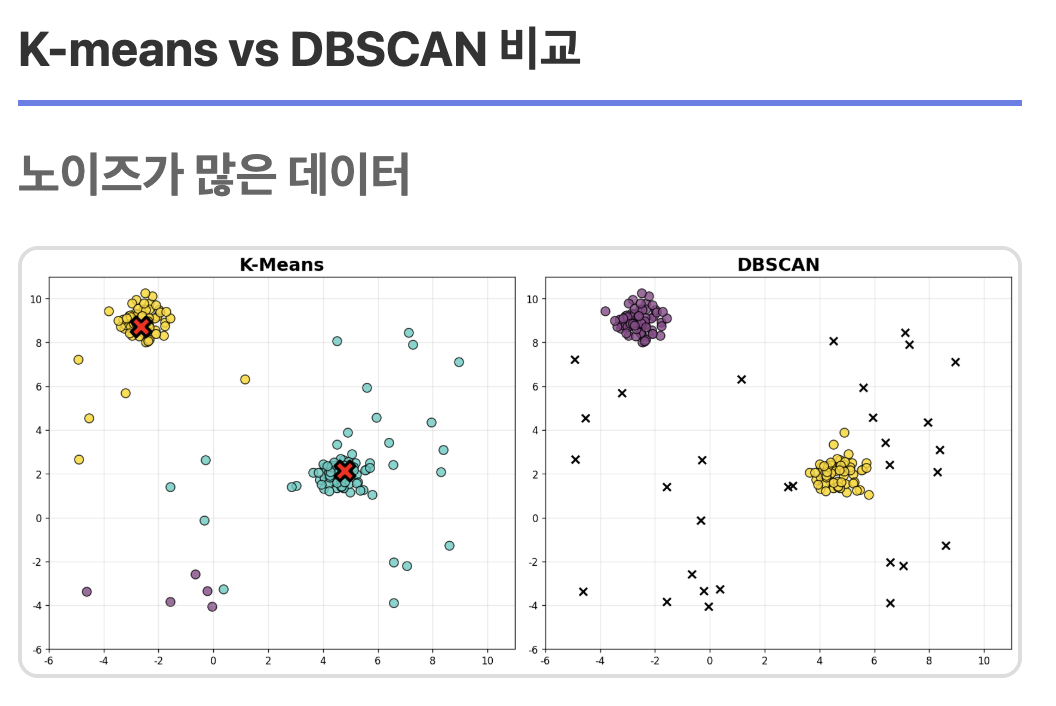
조금 더 보면 k-means는 데이터를 미리 정해둔 k개의 그룹으로 나눔. 모든 데이터를 그룹 안에 포함시켜야 하니, 평균에서 엄청 떨어진 노이즈들도 그룹 안에 포함시킨다.
반면에 dbscan은 데이터 밀도가 높은 곳을 '군집'으로 두고 밀도가 낮은거는 다 노이즈로 분류한다. 그렇기에 밀도가 높은 곳만 묶자(노이즈 제외)라고 생각하면 된다. (x자가 다 노이즈 표시된 것들)
필요한 모듈, 클래스들
sklearn.cluster 모듈의 DBSCAN클래스
sklearn.datasets 모듈의 make_moons 함수와 make_circles 함수
sklearn.neighbors 모듈의 NearestNeighbors 클래스
나머지는 matplotlib.pyplot랑 numpy 모듈이다
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons, make_circles
from sklearn.neighbors import NearestNeighbors
import matplotlib.pyplot as plt
import numpy as npmakemoons: 반달 모양(두 개의 달)으로 데이터 생성
n_samples: 점 200개 찍을것임
noise: 0.05 인데 값이 커질수록 더 흐트러짐
X1, : _를 한 이유는 y 값은 필요 없다는 뜻, 모양만 보여주면 된다는 뜻
factor 는 0과 1사이에 원 크기 비율
요 위아래는 X2[:, 0] +=3 해줘서 위치를 옮긴거랑, 옮기지 않은 거 차이. 추가로 저 선으로 되어 있는 원이 X1이고 점으로 되어있는게 X2이다.
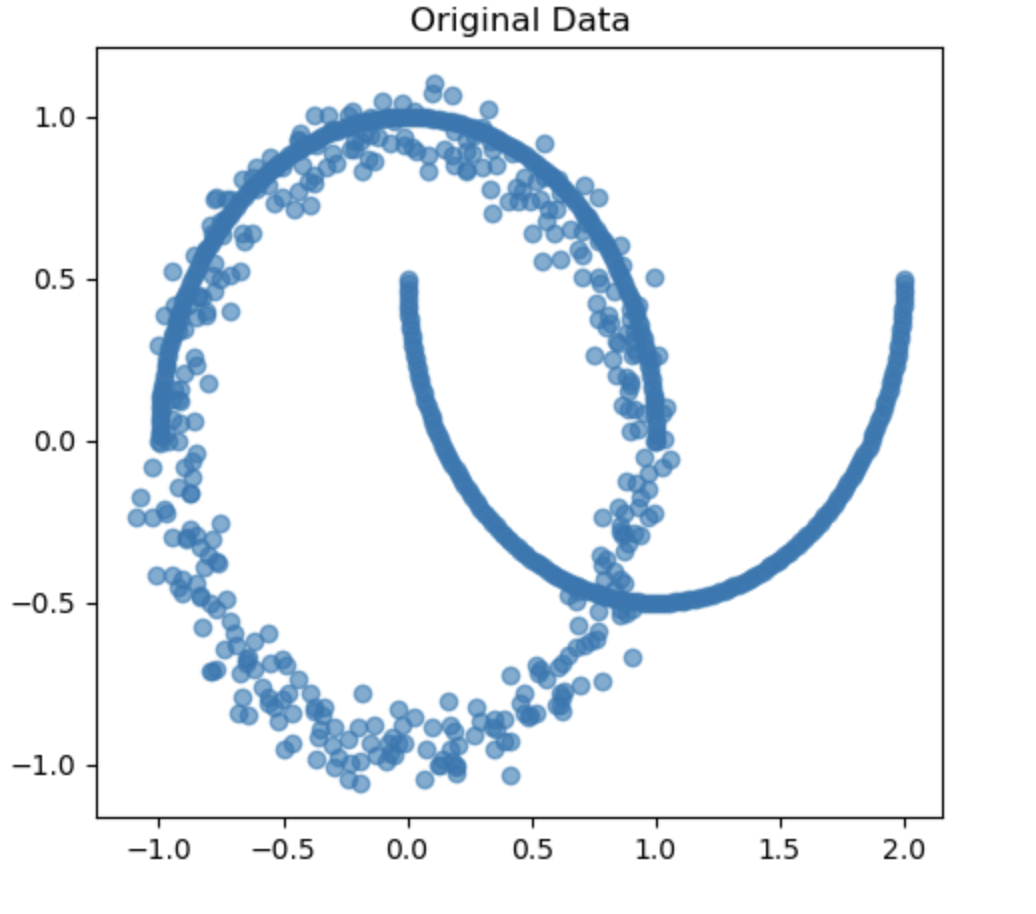
마지막에는 앞에서 mean shift 한것처럼 X1, X2데이터를 vstack으로 합쳐준다
또 궁금헀던게 moons 위치가 왜 저렇게 만들어지지? 했는데 기본적으로 함수 안에서 이미 위치가 정해져 있는 상태란다. make circle은 0.0이 기준인데 저기 위에서 x축으로 3만큼 이동시킨 것임.
# 복잡한 모양 데이터 생성
X1, _ = make_moons(n_samples=200, noise=0.05, random_state=0)
X2, _ = make_circles(n_samples=200, noise=0.05, factor=0.5, random_state=0)
X2[:, 0] += 3 # 위치 이동
X = np.vstack([X1, X2])아래 코드 설명을 해보자면, k = 4는 한 점 주변에서 가장 가까운 4개의 친구를 찾아보자라는 뜻
그리고 NearestNeighbors(n_neighbors=k)라는 가장 가까운점 k개를 찾아주는 도우미 기계 사용. 이 기계는 모든 점의 위치를 보고 '누가 누구랑 가까운지' 계산 준비
fit으로 neighbors statements를 학습한다음
이웃들을 찾는 함수 kneighbors에다가 X를 넣어준다.

여기 코드 설명 보면 returns 값으로 indices값이랑 distances 값들을 인자로 가짐 여기 설명에서는 indices가 먼저 나온다고 되어있는데, 노노 저기 위에 코드처럼 첫번째 리스트 값이 거리고 두번째 리스트 값이 indices(index 복수형)임
# K-distance 그래프로 eps 찾기
k = 4 # min_samples 후보
neighbors = NearestNeighbors(n_neighbors=k)
neighbors.fit(X)
distances, indices = neighbors.kneighbors(X)여기 아래는 모든 점이 자기에서 k번째로 가까운 이웃까지 얼마나 떨어져 있는지 차례대로 정리해놓은 것. 그 중에서 distances[:, k-1]는 k-1번째 열만 골라서 쓴다는 뜻. 요약하자면 distances[:.1]은 모든 점의 두 번째 이웃 거리를 한 줄로 세운거다. 1이 아니라 2라면, 모든 점의 세 번째 이웃 거리(자기 제외 2번째 먼)들을 한 줄로 쭉 세운다고 보면 됨.
# k번째 거리만 (자기 자신 제외)
k_distances = np.sort(distances[:, k-1])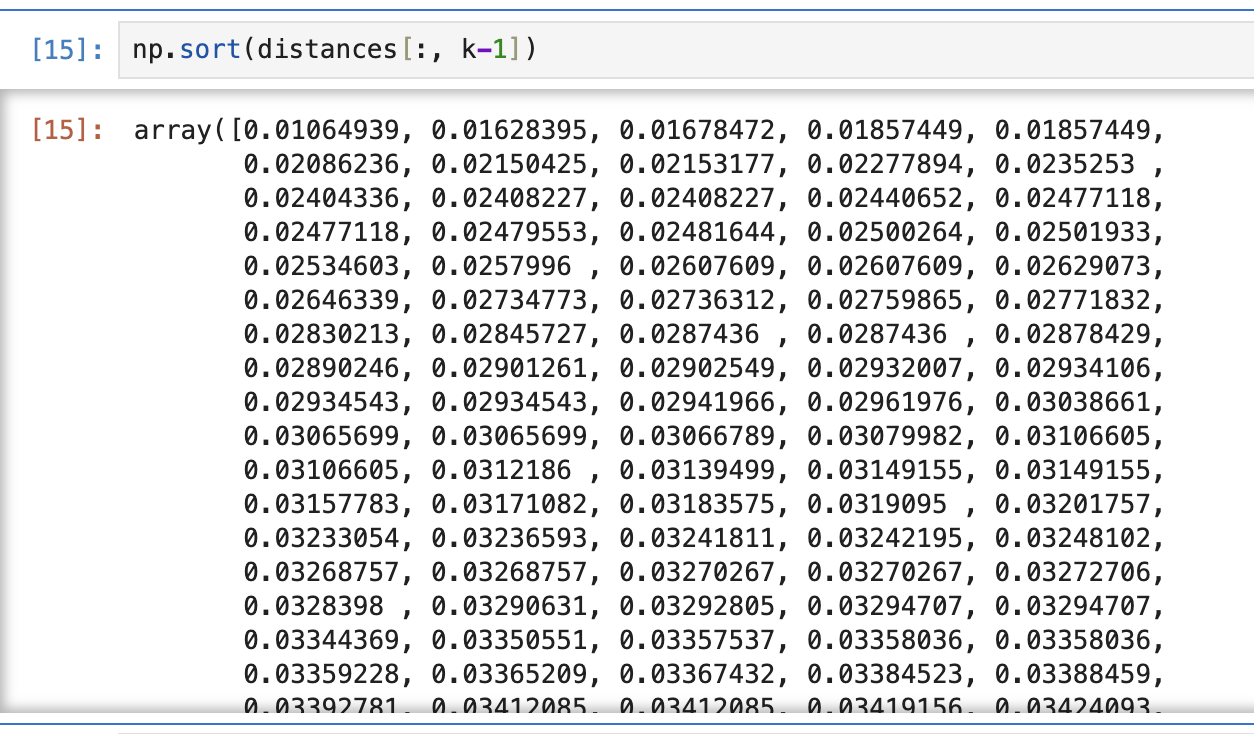
위에 코드에 대한 결과값을 가져오면 이렇게 나온다. distance의 모양은 (샘플개수, k)이다. 위에서 k(가장가까운 점의 n번째)가 4라고 지정했으니, 자기 제외 3번째 먼 점들의 거리 데이터를 일렬로 쭉 나열한 거
그렇게 한다음 plt.figure에다가 plt.plot 데이터로 (k_distances)값 (아까 거리 값들 일렬로 정렬한 값 데이터)를 그래프로 쭉 그려주면
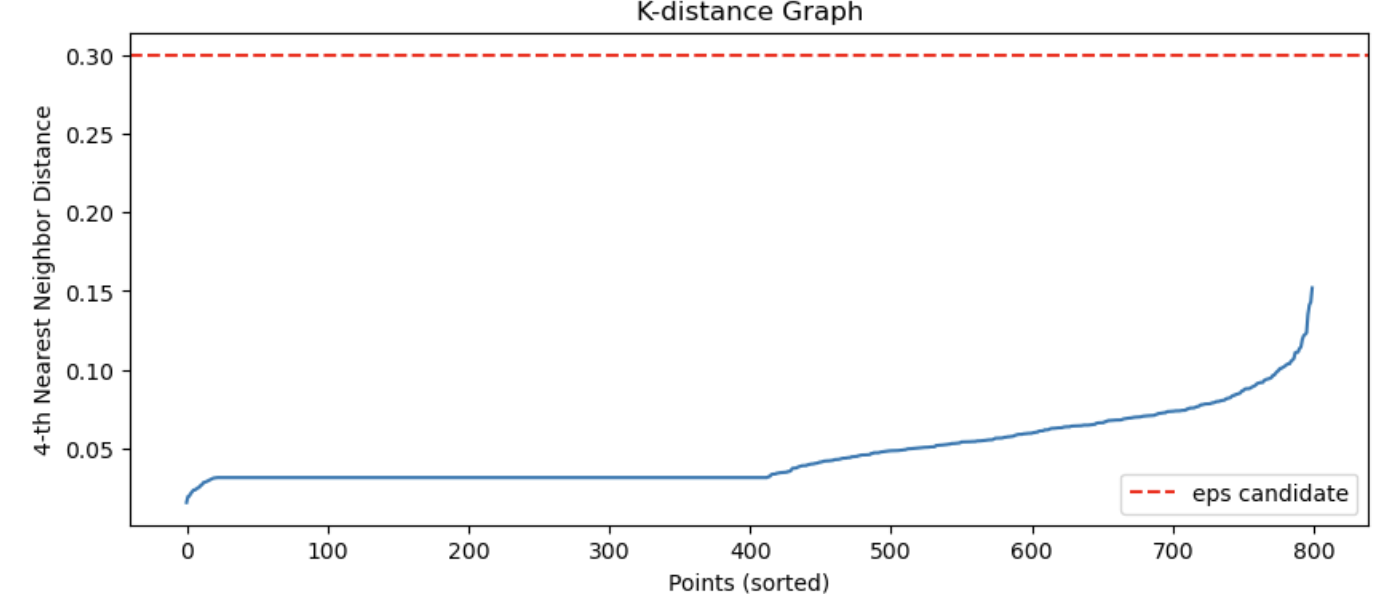
요렇게 나온다. 위에서는 eps값이 어느정도로 해야 좋은지 그래프로 그려보고 확인하는 정도임.
dbscan 적용방법
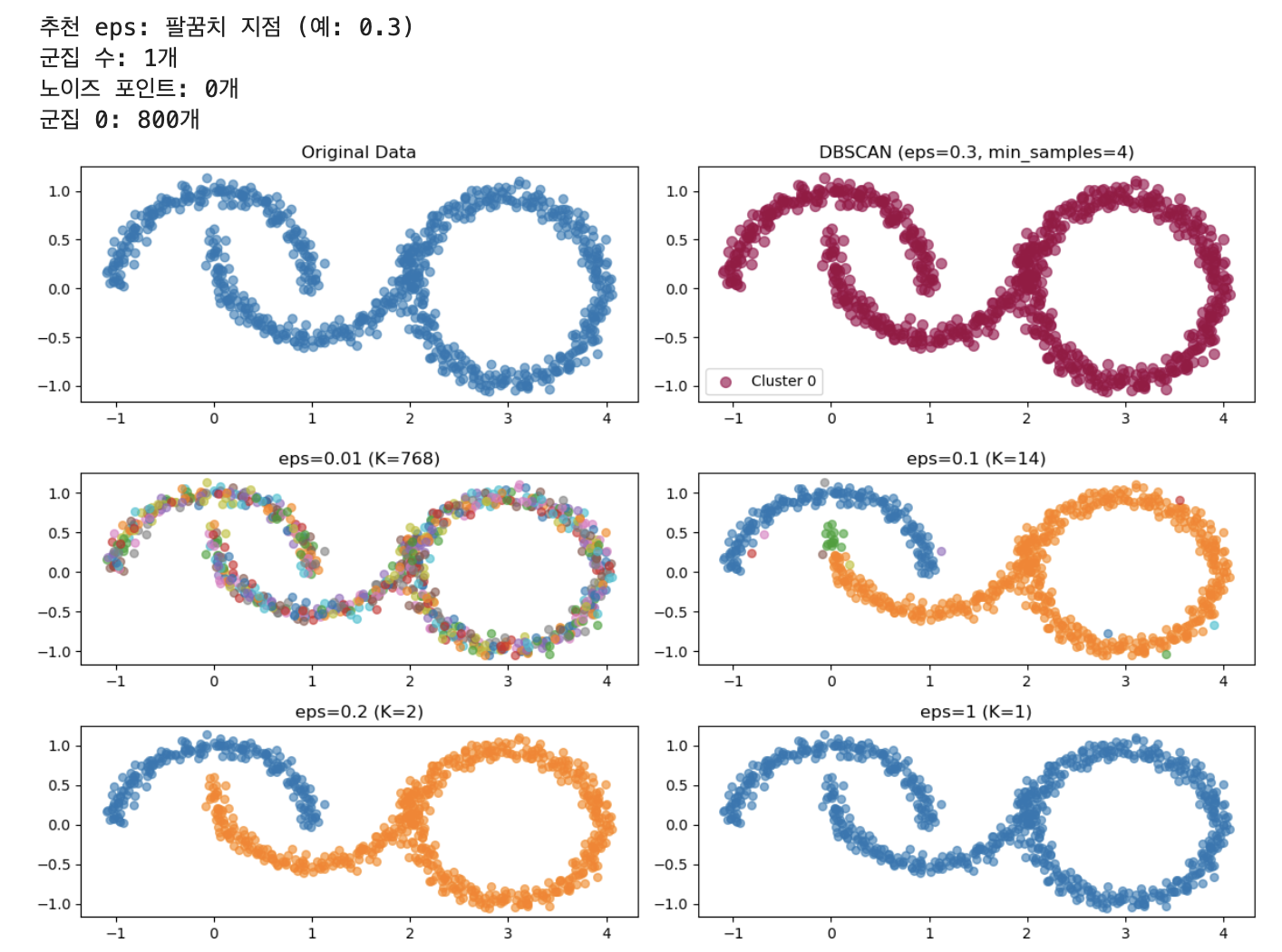
그래프를 확인해보면 y값 0.3정도에서 확 꺾이는 것을 볼 수 있다. min_samples= 는 위에 k 값이랑 같이 따라가야 한다. labels 에는 위의 dbscan 값을 fit_predict(X) 를 사용해서 fit으로 학습한다음, predict()으로 판단 결과 라벨을 붙이는 과정
그 다음으로 n_clusters=는 labels 즉 라벨 종류 갯수가 몇개인지(무리가 몇개인지)
마지막으로 n_noise는 라벨이 -1(노이즈 값)으로 나오는 것들을 센다
# DBSCAN 적용
dbscan = DBSCAN(eps=0.3, min_samples=4)
labels = dbscan.fit_predict(X)
n_clusters = len(set(labels)) - (1 if -1 in labels else 0)
n_noise = list(labels).count(-1)
print(f"군집 수: {n_clusters}개")
print(f"노이즈 포인트: {n_noise}개")요 아래는 각 군집 크기를 세주는 과정 for문을 써서 각 라벨이 labels == 1 일때랑 labels == 2일 때 쭉 해서 각각의 군집이 가지고 있는 count들을 세 주는 함수
# 각 군집 크기
for i in range(n_clusters):
count = np.sum(labels == i)
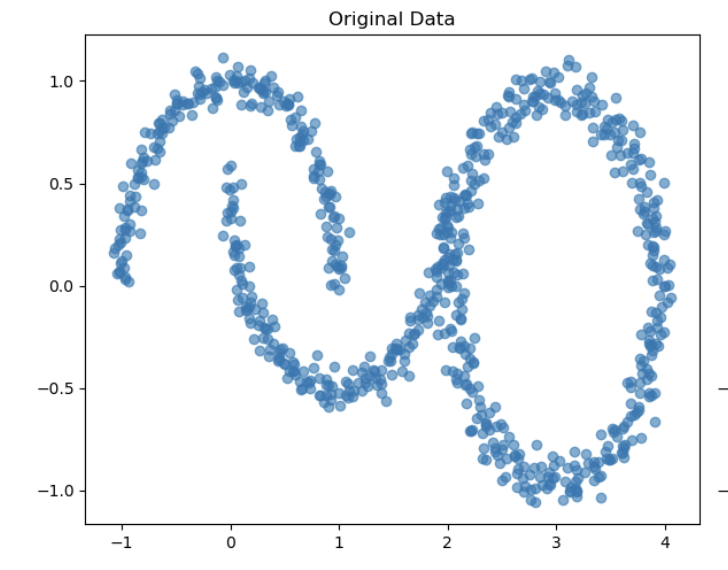
print(f"군집 {i}: {count}개")그리고 시각화 해보면 요렇게 나온다. 항상 plt.figure 해줘야 사이즈 변경할 수 있는거 잊지말고, scatter그래프로 그려주었는데, x 축에는 X행렬의 모든 행의 0번째(눈으로는 첫번째) 열, y 축으로는 X행렬 모든 행의 1번째(눈으로는 2번째)열을 데이터로 입력 해 주었다.
plt.figure(figsize=(12, 5))
# 원본
plt.subplot(1, 2, 1)
plt.scatter(X[:, 0], X[:, 1], alpha=0.6)
plt.title('Original Data')
colors 는 그냥 색깔 입혀주는 거고
라벨 배열에서 k번 클러스터에 속한 점만 true가 되는 필터를 만듬
나머지도 쭉 이해해 보려 했는데, 일단 지금은 관련 개념만 하고 넘어가는게 좋을 듯 싶다. 전부 그래프 어떻게 꾸며주는지 알려주는 내용. 그래도 나중에 AI형님한테 여쭤보려면, DBSCAN이 나눈 그룹 무리를 각자 다른 색깔로 그림 표시하고 싶다는 뜻이다.
# DBSCAN 결과
plt.subplot(1, 2, 2)
colors = plt.cm.Spectral(np.linspace(0, 1, n_clusters))
for k, col in zip(range(n_clusters), colors):
class_member_mask = (labels == k)
xy = X[class_member_mask]
plt.scatter(xy[:, 0], xy[:, 1], c=[col], alpha=0.6,
label=f'Cluster {k}', s=50)
# 노이즈
noise_mask = (labels == -1)
if np.any(noise_mask):
plt.scatter(X[noise_mask, 0], X[noise_mask, 1],
c='black', marker='x', s=50, label='Noise')
plt.title(f'DBSCAN (eps={0.3}, min_samples={4})')
plt.legend()
plt.tight_layout()
plt.show()요 아래는 다양한 eps 값들 가지고 비교해보는 값들
# 다양한 eps 비교
eps_values = [0.2, 0.3, 0.5, 0.8]
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
for idx, eps in enumerate(eps_values):
dbscan = DBSCAN(eps=eps, min_samples=4)
labels = dbscan.fit_predict(X)
n_clusters = len(set(labels)) - (1 if -1 in labels else 0)
ax = axes[idx // 2, idx % 2]
# 군집 그리기
for k in range(n_clusters):
mask = (labels == k)
ax.scatter(X[mask, 0], X[mask, 1], alpha=0.6, s=30)
# 노이즈
noise_mask = (labels == -1)
if np.any(noise_mask):
ax.scatter(X[noise_mask, 0], X[noise_mask, 1],
c='black', marker='x', s=30)
ax.set_title(f'eps={eps} (K={n_clusters})')
plt.tight_layout()
plt.show()요 아래는 eps 값이랑 이것저것 가지고 논 것들.