하이퍼 파라미터가 무어냐...
요거는 모델이 배우지 않은 설정값 이라고 봄
요리 하기전에 요리 어떻게 할지 전부 알고 있는 상태(어떤 냄비 쓸지, 불 세기는 어떻게 할지, 몇분 요리할지 등등)
이는 하이퍼 파라미터에 따라 성능이 달라지는데, 최적값은 어떻게 찾는게 좋을까..?
일단 파라미터는 모델이 학습 중에 배우는 값, like weight, bias
하이퍼 파라미터는 학습 전에 우리가 설정하는 값, like Learning rate, Batch size 등등 다양하다
조정해야 할 하이퍼 파라미터 값들
1. Learning Rate
2. Batch Size
3. Regularization (람다)
4. 모델 구조 (딥러닝)
5. Optimizer, Activation function, Epochs 등등
1. Logistic Regression 하이퍼 파라미터
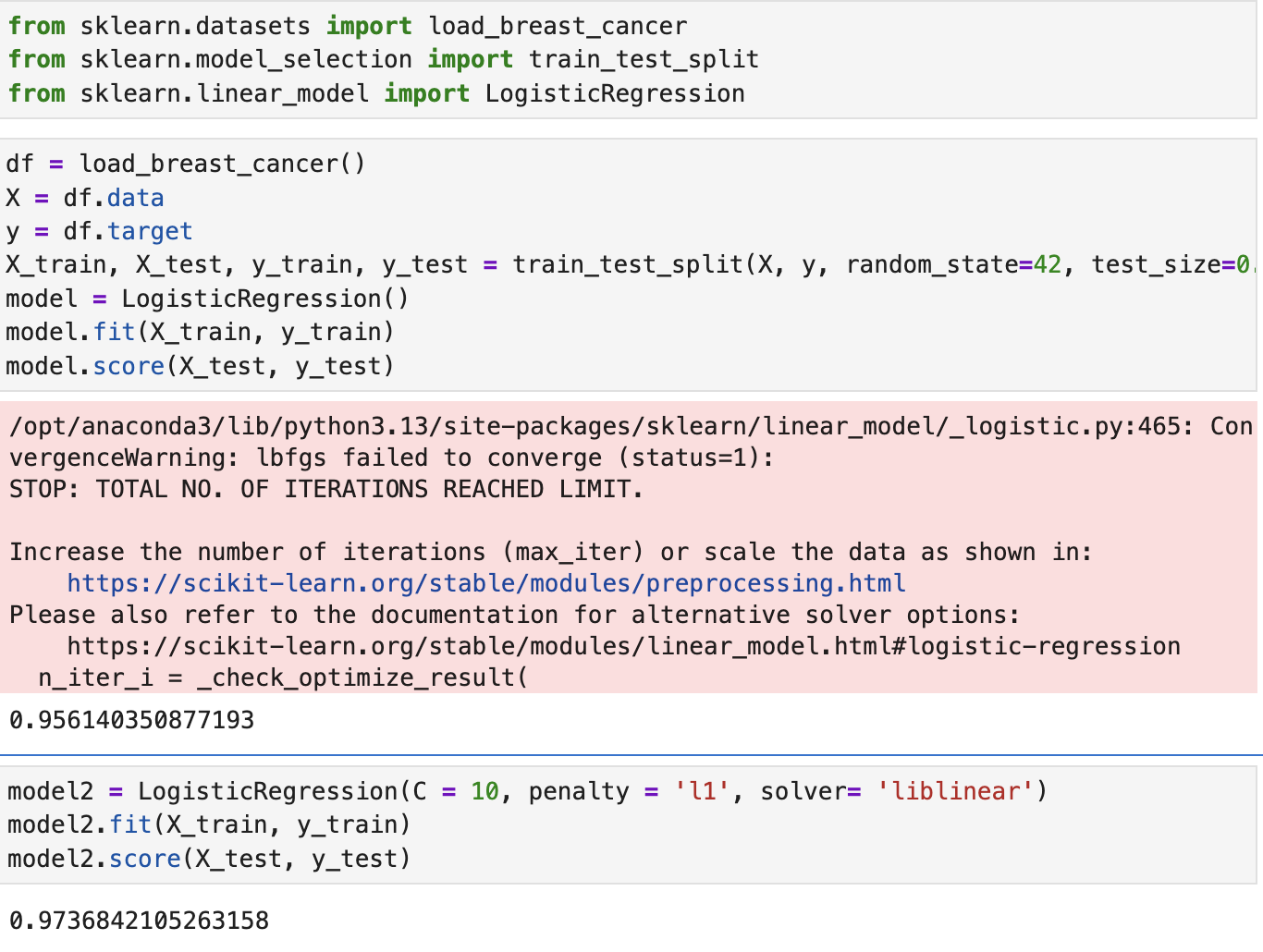
간단하게 보기만 해석만 하면, LogisticRegression 에 C값으로 10(default 는 1), penalty = 'l1', solver = 'liblinear'을 추가로 넣어주었다.
c 값은 세기를 조절하는 숫자로, c 값이 커지면 과적합이 발생할 수 있고, c 값이 작아지면 엄청 끈이 느슨해진다고 보면 됨.
penalty는 l1이라는 규제 사용인데, 쓸모없는 것들을 0으로 만들어 보통 l1, l2가 쓰이는 것에 따라 콤보로 묶이는 solver가 이렇게 있다.
2. Grid Search
요거는 모든 조합을 직접 지정해주고 하나하나 돌려봐서 최적의 조합을 도출하는 방법
필요한 거는 sklearn.model_selection의 GridSearchCV클래스랑 똑같이 선형회귀 클래스를 가지고 온다.
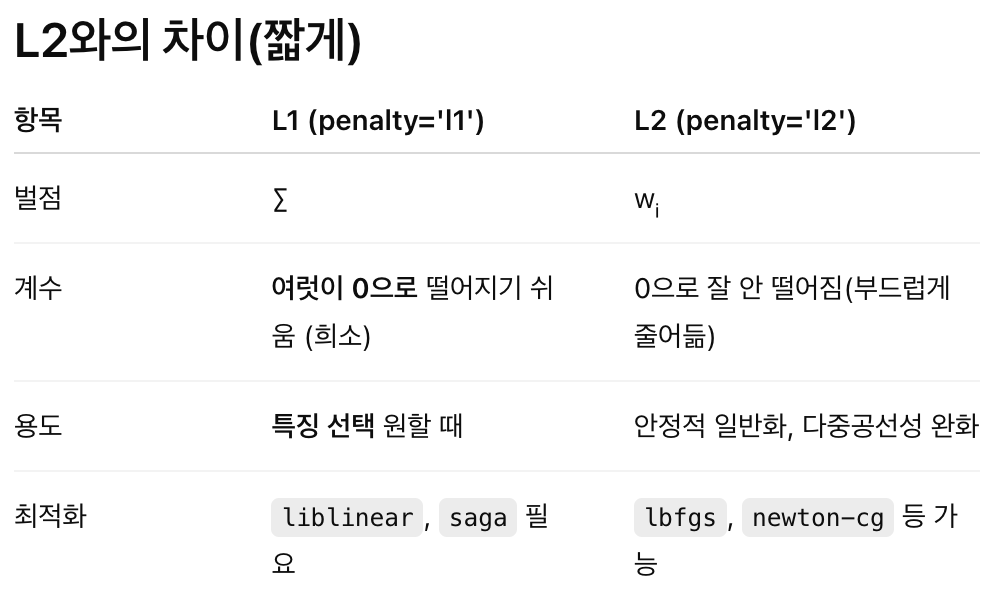
흐음, l1, l2는 빡센 규제랑 느슨한 규제라고 생각하면 되고, solver 방식은 l1, l2랑 같이 오는 셋트매뉴라고 생각하면 된다. 위에 L2차이 사진 보면 같이 묶이는 것들 보이네
나는 위에 사진 보고 solver 값으로 lbfgs랑 newton-cg 추가해서 넣어주었다.
liblinear - 작고 단순한 데이터
saga - 여러방향으로 동시에 뛰어내림, 대용량 데이터 가능
lbfgs - 기본값, 속도+정확도 균형 좋음
newton-cg 수학적으로 정밀하게 계산, 다중분류, 정교모델에 좋음
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(max_iter=1000, random_state=42)
param_grid = {
'C' : [0.001, 0.01, 0.1, 1, 10, 100, 150],
'penalty': ['l1', 'l2'],
'solver' : ['liblinear', 'saga']
}GridSearchCV는 입력한 모델의 제일 좋은 조합을 찾아주는 '자동실험기'
estimator = 실험에 쓸 기본 모델(선형 회귀)
param_grid = 실험할 설정값(위에 dict으로 되어있음)
cv = 5 요거는 5개의 데이터 조각으로 평가(4개로 학습, 1개로 평가 한다는 뜻)
scoring = 'accuracy'모델 평가 기준을 정확도로 지정한다는 뜻
n_jobs = 1 cpu 한개만 사용한다는 뜻. 2개로 올리면 알바 2명 쓴다고 생각하면 됨(조금 빨라짐). 만약 가능한 모든 CPU 코어 다 쓰고 싶다고 하면 -1 넣어주면 됨!
verbose = 2 요거는 진행상황을 전부 보여줘! 한다는 뜻. 만약 보기 싫으면 0이나 1넣어주면 된다!
grid_search = GridSearchCV(
estimator = model,
param_grid=param_grid,
cv = 5,
scoring='accuracy',
n_jobs=1,
verbose=2
)마지막으로는 이제 학습을 시켜주면 되는데, 위에 grid_search 객체안에 여러 내장함수(메서드)들이 들어 있다. 여기에 train 데이터로 학습 시켜준다. cv= 5는 5개로 나눠서 4개 1개 학습할거야 라고 선언하는거고, 아래 fit은 이제 계획 다 해놨으니 학습을 실제로 해버리는 것임.
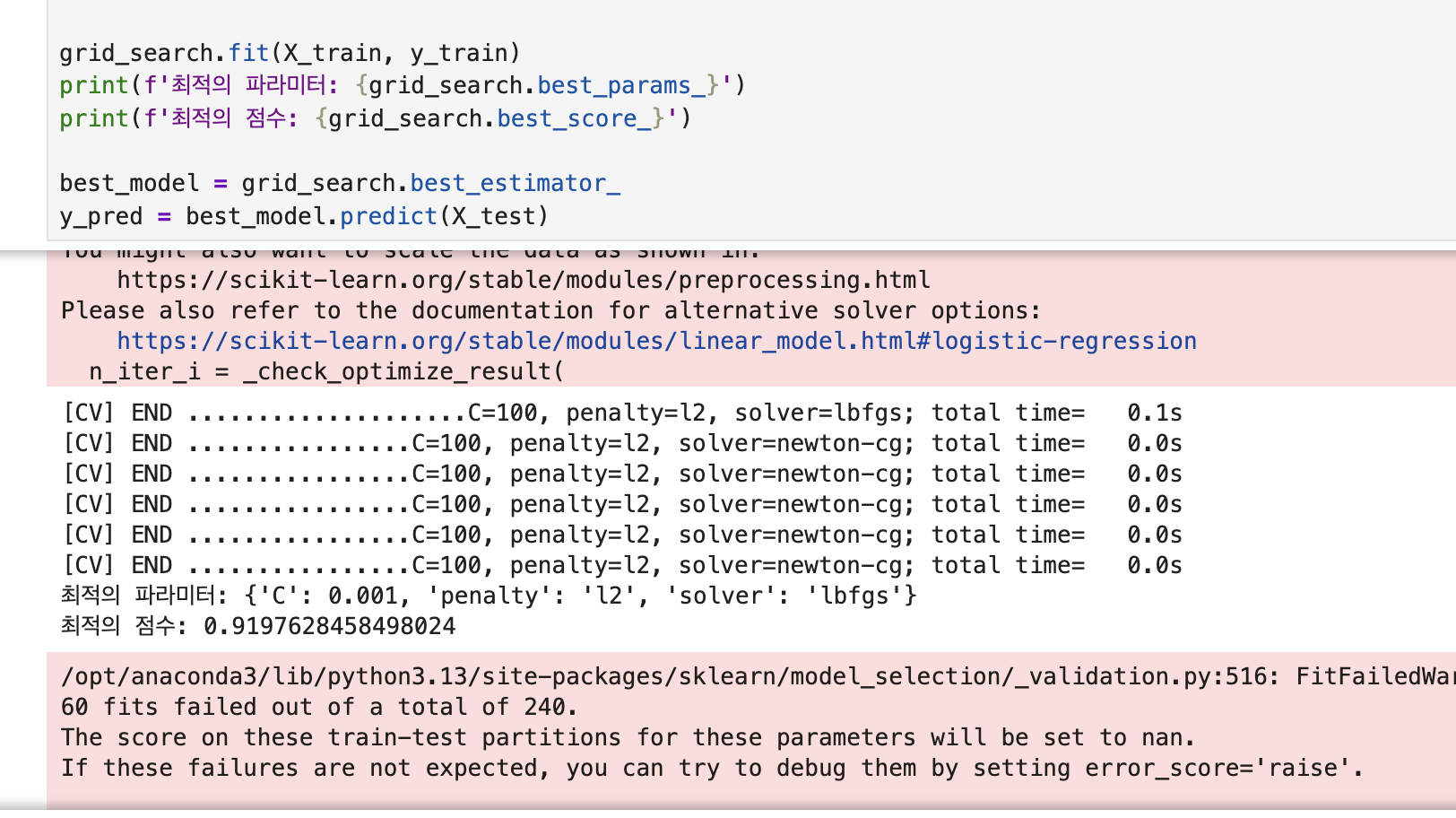
그 다음에 bestparams를 해주면 최적의 파라미터들이 어떻게 선정되었는지 dict 값으로 여주고(위에있음) bestscore를 해 주어서 그때의 점수가 어떻게 되었는지 보여줌!
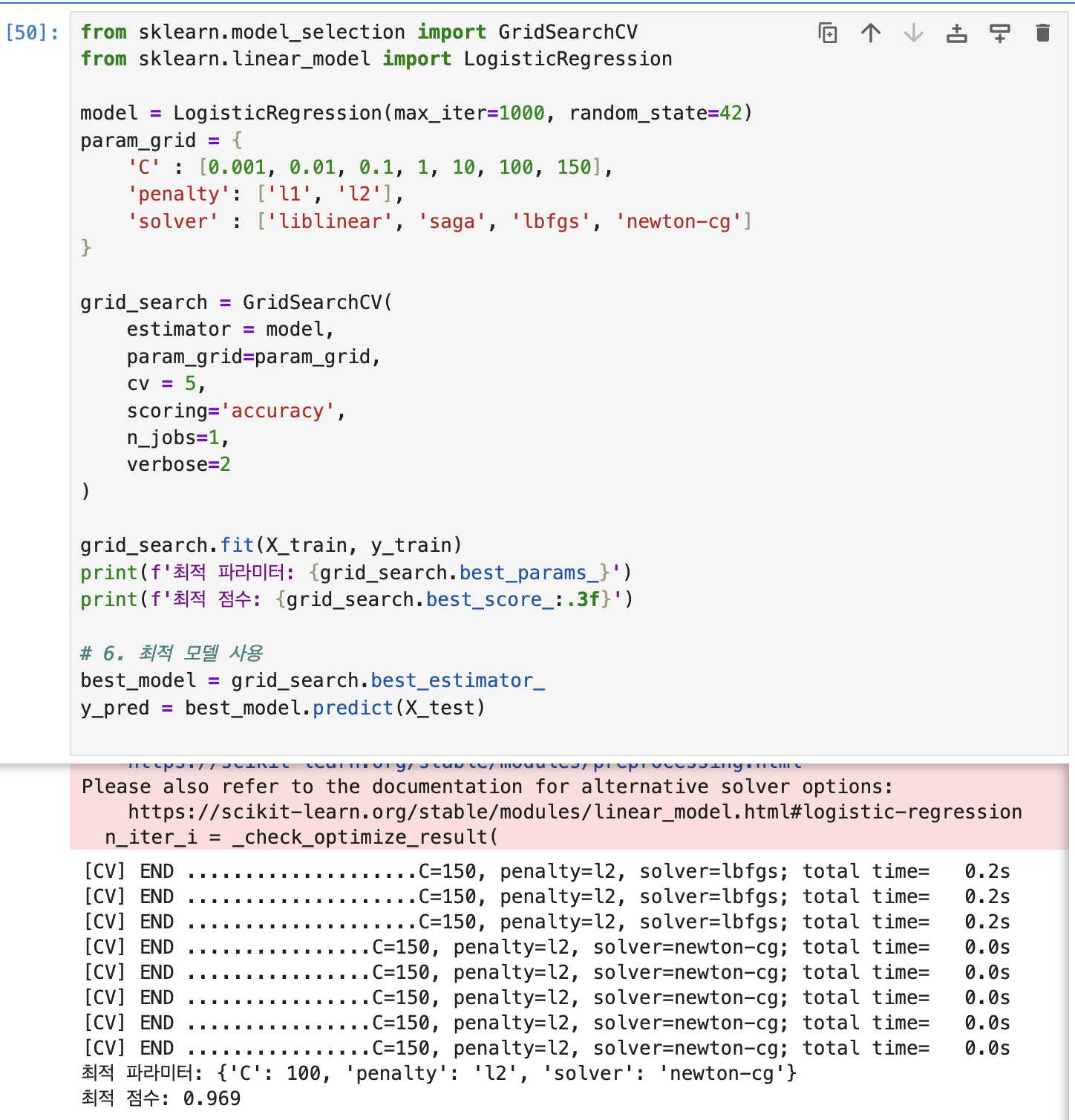
grid_search.fit(X_train, y_train)
print(f'최적 파라미터: {grid_search.best_params_}')
print(f'최적 점수: {grid_search.best_score_:.3f}')
# 6. 최적 모델 사용
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)이 다음은 실제로 모든 데이터 값들을 전부 프린트 해보며는 요렇게 된다.
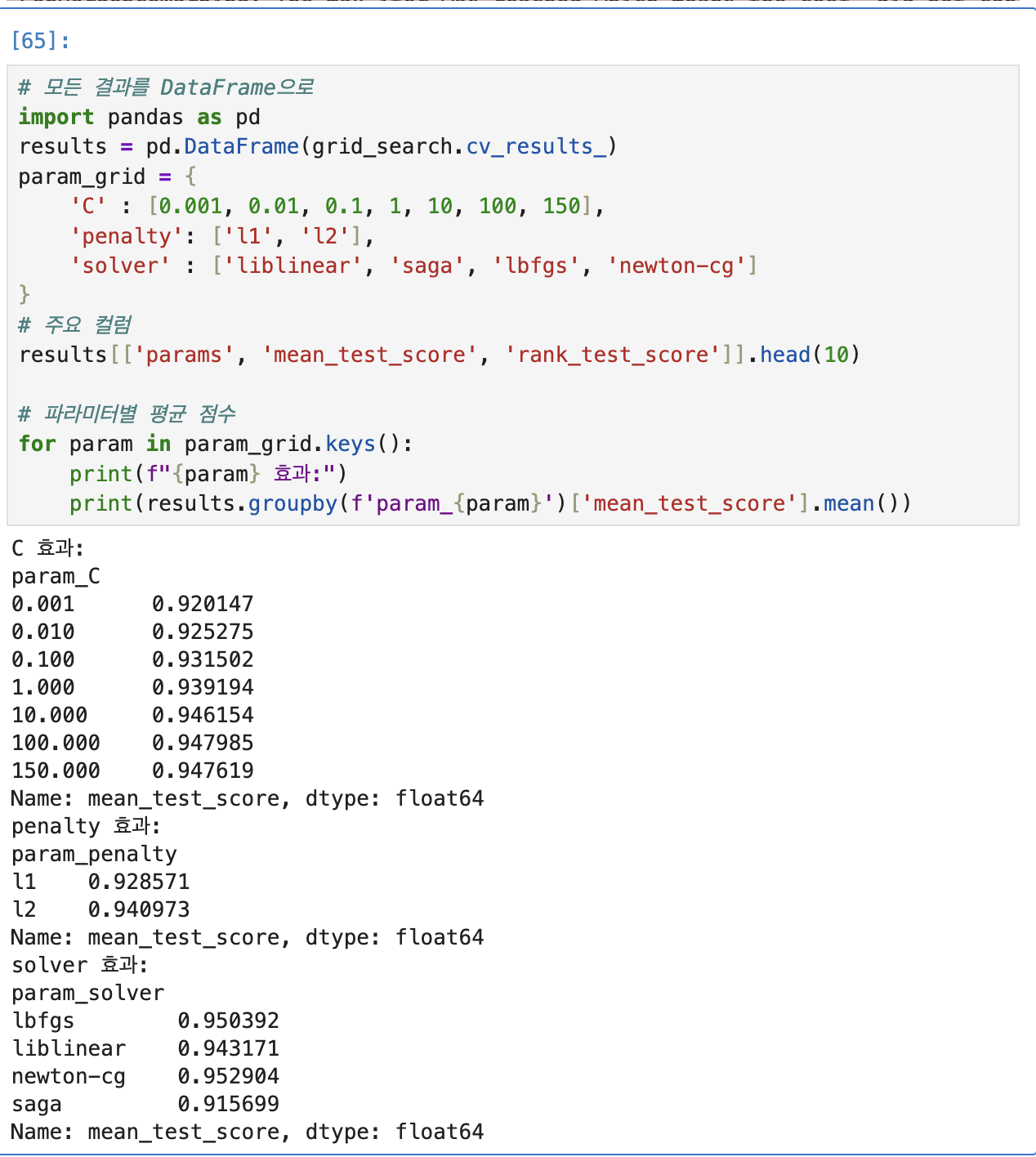
그리고 result에다가 gridsearch.cv_results instances를 붙여 이미 결과가 나온 값들을 딕셔너리 형식으로 저장된 값을 가져온다.

요런 값들이 있다, 이 중에 params(파라미터 조합, 딕셔너리), mean_test_score, rank_test_score 칼럼만 가져와서 프린트 한다는 뜻.

results 값이 이렇게 나온다.
그 다음 param_grid의 keys 값들을 가져와서 결과를 이쁘게 도출.
Random Search
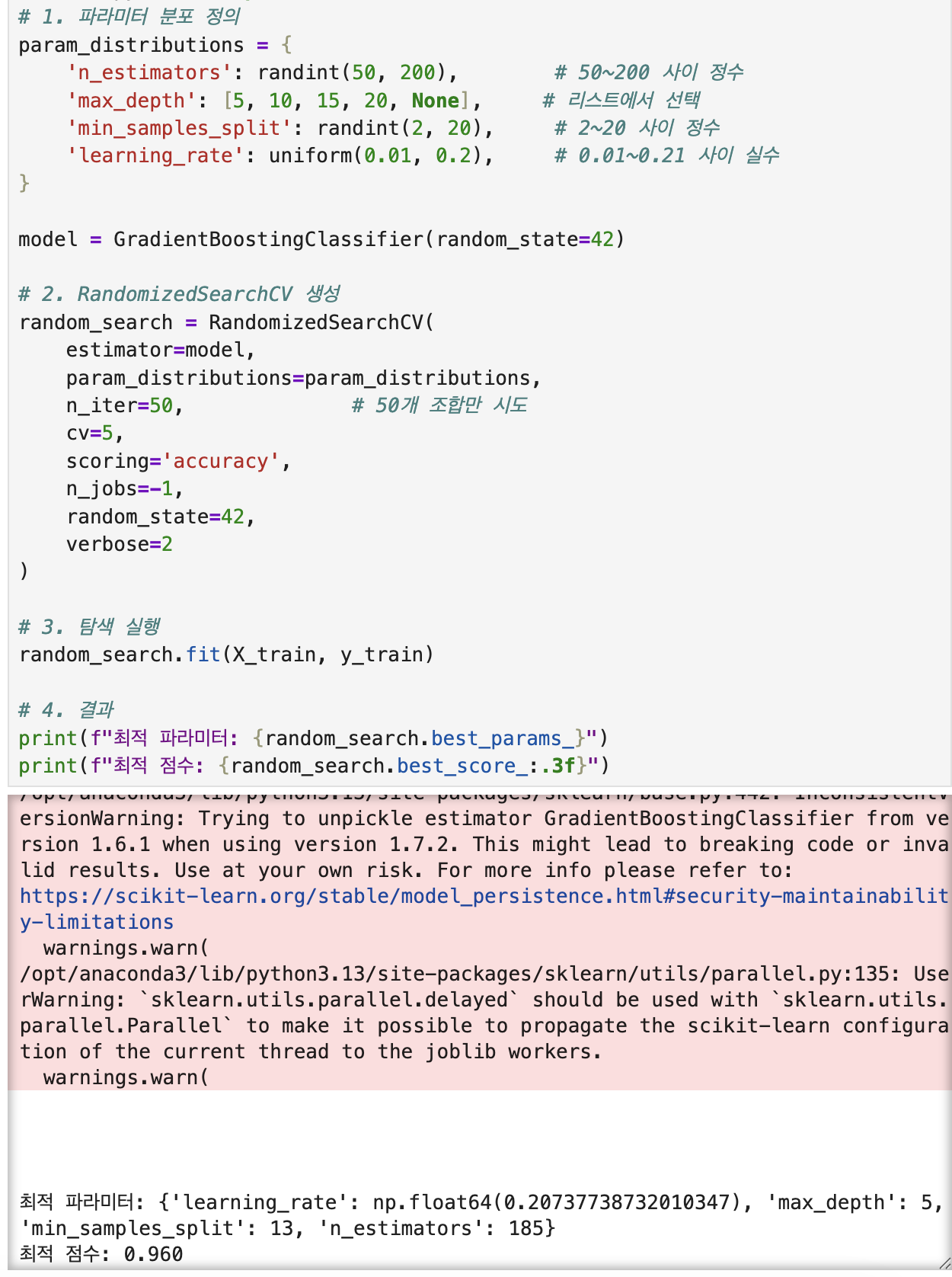
요녀석은 하이퍼 파라미터들을 무작위로 샘플링함 사용방법은 위에 grid search 형식이랑 비슷한데 다른점은 sklearn.model_selection으로 RandomizedSearchCV로 변경이 됨. 그러다보니 randomizedsearchCV 클래스에서 필요로 하는 param_distributions를 지정해 주어야 하고, 바로 그 위에 param_distributions를 딕셔너리 형태로 어떤 범위 안에서 정수를 나열할 건지 쭉 보여줌. 나머지는 grid_search랑 비슷해 보인다.
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform, randint
# 1. 파라미터 분포 정의
param_distributions = {
'n_estimators': randint(50, 200), # 50~200 사이 정수
'max_depth': [5, 10, 15, 20, None], # 리스트에서 선택
'min_samples_split': randint(2, 20), # 2~20 사이 정수
'learning_rate': uniform(0.01, 0.2), # 0.01~0.21 사이 실수
}
# 2. RandomizedSearchCV 생성
random_search = RandomizedSearchCV(
estimator=model,
param_distributions=param_distributions,
n_iter=50, # 50개 조합만 시도
cv=5,
scoring='accuracy',
n_jobs=-1,
random_state=42,
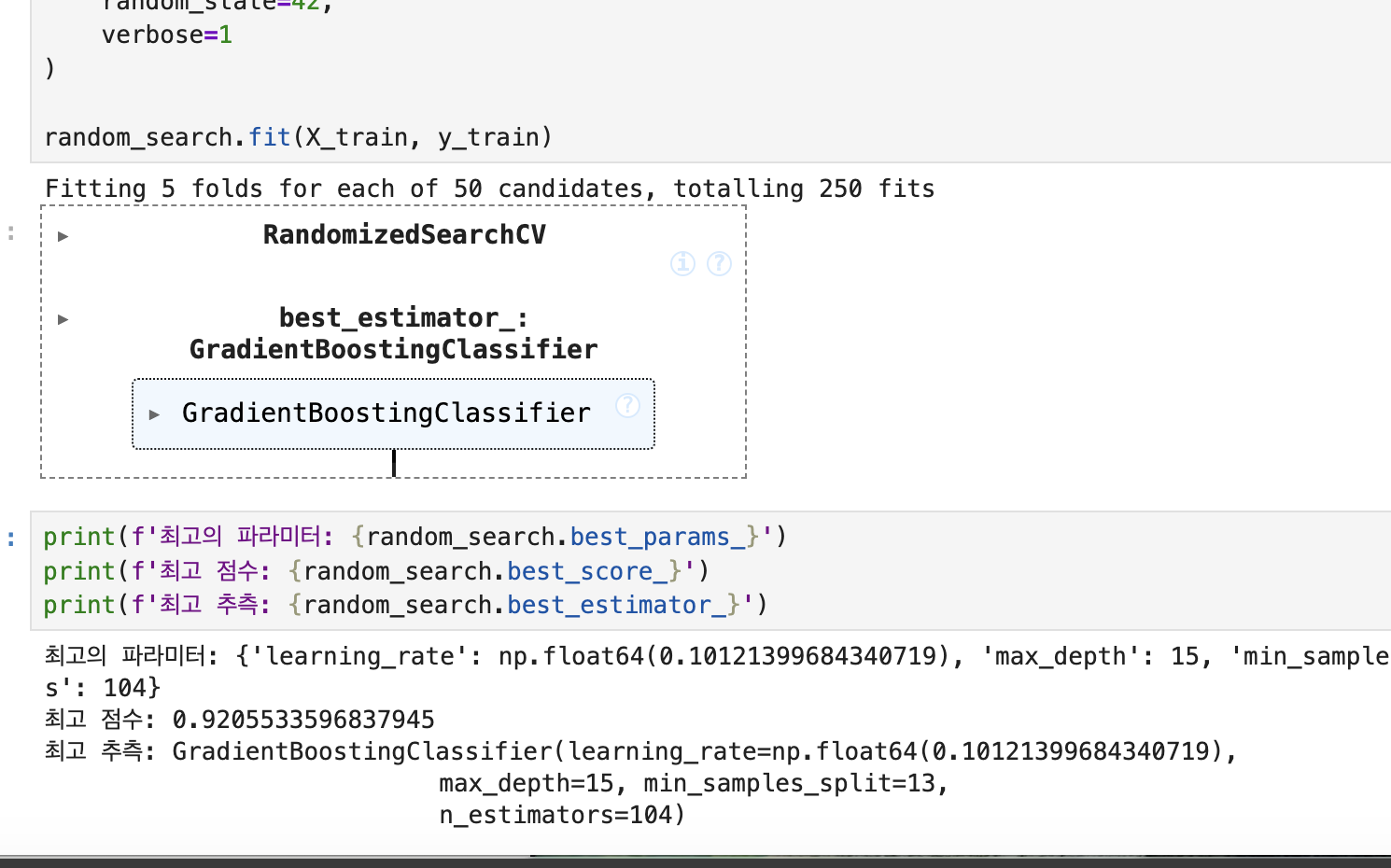
verbose=1학습하면 요렇게 나옴. 오 색깔 바뀐다 ㅋㅋ
# 3. 탐색 실행
random_search.fit(X_train, y_train)
그리고 이거 위에 코드랑 조금 다르긴 한데, 하다가 에러가 떠서 다시 찾아본다.
찾아보니, param_distributions안에 있는 하이퍼 파라미터들은 모두 트리 기반 모델 전용 하이퍼파라미터라 LogisticRegression으로 RandomizedSearchCV를 돌리면 invalid parameter가 뜬다.
왜 그런지 봤더니 GradientBoostingClassifier의 하이퍼파라미터 들은 저기 사진에 있는 n_estimators, max_depth, learning_rate 같은 것들이다보니 에러가 뜰수밖에 없음. 그렇기에 저 하이퍼 파라미터들을 사용해주려면 model로 선형회귀 대신에 GradientBoostingClassifier로 모델 바꿔주고 해야 값이 도출된다. (시간 오래걸리네 이거)
from sklearn.ensemble import GradientBoostingClassifiermodel로 로시즈틱 회귀 말고 이거 써주면 됨
과제리뷰
이게 근데 랜덤이어서 그런가 grid로 할 때가 당연히 점수가 잘 나올거라 했는데, grid 말고 random을 할 때가 점수가 잘 나올때도 있다. sklearn의 breast cancer 데이터