- 위키독스: 시퀀스-투-시퀀스를 정리한 내용입니다.
Sequence-to-Sequence
시퀀스-투-시퀀스(Sequence-to-Sequence)는 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에 사용되는 모델이다. 예: 챗봇(질문-대답), 기계 번역(입력-번역문)
구조
seq2seq는 인코더-디코더 로 구성되어 있다.
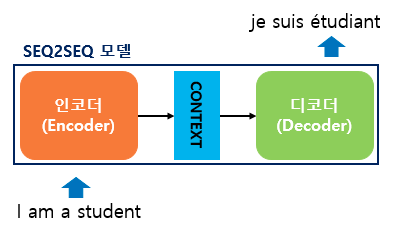
- 인코더: 입력 문장의 모든 단어를 순차적으로 입력받은 후 모든 단어 정보를 압축해 하나의 벡터로 만든다.
- 컨텍스트 벡터: 입력 문장의 모든 단어 정보가 압축된 벡터. 인코더의 출력이자 디코더의 입력이 된다.
- 디코더: 컨텍스트 벡터를 입력으로 받아 새로운 단어를 한 개씩 순차적으로 출력한다.
인코더와 디코더의 아키텍처 내부
인코더 아키텍처와 디코더 아키텍처의 내부는 각각 RNN 아키텍처로 구성되어 있다. 입력 문장을 받는 RNN 셀을 인코더, 출력 문장을 출력하는 RNN 셀을 디코더라고 한다. 그러나 성능 문제로 바닐라 RNN(기본)이 아니라 LSTM 셀이나 GRU 셀로 구성된다.
입력 문장은 단어 토큰화로 단어 단위로 쪼개지고 단어 토큰 각각은 RNN 셀의 각 시점의 입력이 된다. 인코더 RNN 셀은 모든 단어를 입력받고 인코더 RNN 셀의 마지막 시점의 은닉 상태가 컨텍스트 벡터가 된다. 디코더는 초기 입력으로 문장의 시작을 의미하는 심볼 <sos>이 들어가면 다음에 등장할 확률이 높은 단어를 예측한다. 컨텍스트 벡터는 디코더 RNN의 첫 번째 은닉상태가 된다.
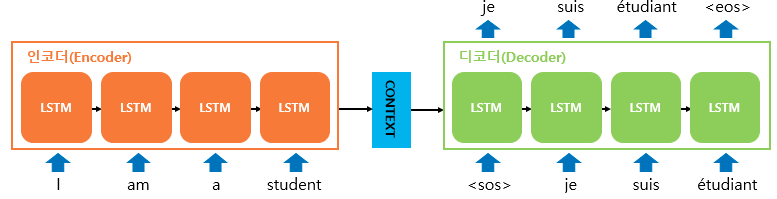
첫번째 시점의 디코더 RNN은 초기 입력으로 문장의 시작을 의미하는 심볼인 <sos>를 넣어 다음에 올 단어를 예측하고 그 예측한 단어를 다음 시점의 RNN 셀의 입력으로 넣는 과정을 문장의 끝을 의미하는 심볼인 <eos>이 나올 때까지 반복한다.
seq2seq는 훈련 과정과 테스트 과정의 작동 방식이 다르다.
- 훈련 과정: 훈련 과정에서는 다음 시점의 RNN 셀에 예측한 단어가 아니라 정답을 넣어준다. (교사 강요)
- 테스트 과정: 컨텍스트 벡터와 <sos>만을 입력으로 받아 다음에 올 단어를 예측하고, 그 단어를 다음 시점의 RNN 셀의 입력으로 넣는 행위를 반복한다.
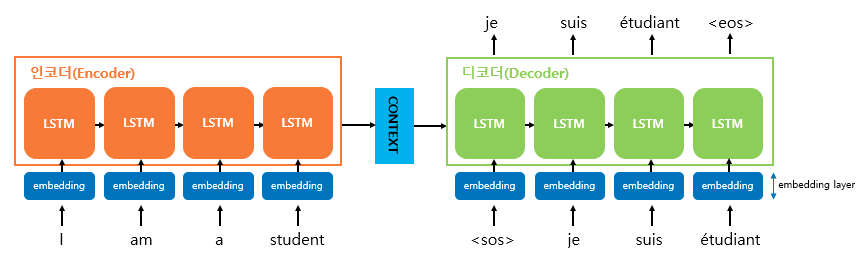
기계는 숫자를 잘 처리하므로 텍스트를 벡터로 바꾸는 워드 임베딩을 사용한다. 따라서 seq2seq에서는 인코더 이전과 디코더 이전에 임베딩 층을 두어 모든 단어가 임베딩 과정을 거치도록 한다.
RNN
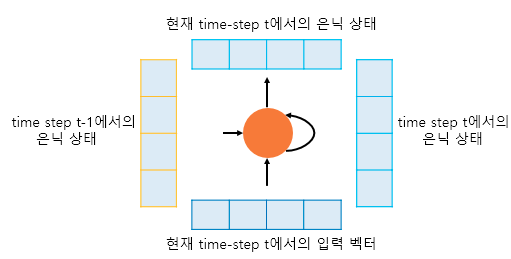
하나의 RNN 셀은 각 시점(time step)마다 2개의 입력을 받는다. RNN 셀은 이전 시점에서의 은닉 상태와 현재 상태에서의 입력 벡터를 입력으로 받아 현재 상태에서의 은닉 상태를 만든다. (이 때 현재 상태에서의 은닉 상태는 위에 다른 은닉층이나 출력층이 존재하면 위의 층으로 보낼 수 있다.) 현재 시점의 RNN 셀은 다음 시점의 RNN 셀의 입력으로 현재 상태에서의 은닉 상태를 입력으로 보낸다.
현재 시점에서의 은닉 상태는 과거 시점의 모든 은닉 상태의 값이 누적되어 있기 때문에 컨텍스트 벡터는 마지막 RNN 셀의 은닉 상태값이며 입력 문장의 모든 단어 토큰들의 정보를 요약해 담고 있다.
디코더는 인코더의 마지막 RNN 셀의 은닉 상태인 컨텍스트 벡터를 첫 번째 은닉 상태의 값으로 사용한다. 디코더의 첫 번째 RNN 셀은 첫 번째 은닉 상태의 값과 현재 시점에서의 입력값 <sos>로부터 다음에 등장할 단어를 예측한다. 첫 번째 RNN 셀로부터 예측된 단어는 다음 시점의 RNN 셀에서의 입력값이 된다. 두 번째 RNN 셀에서는 예측된 단어와 첫 번째 시점에서의 은닉 상태로부터 다음에 등장할 단어를 예측한다. 이 과정을 <eos>가 나올 때까지 계속 반복한다.
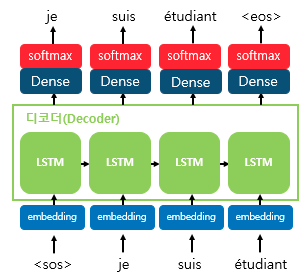
seq2seq 모델은 각 시점의 RNN 셀에서 출력 벡터가 나오면 소프트맥스 함수를 통과시켜 출력 시퀀스의 각 단어별 확률값을 반환하고 디코더는 출력 단어를 결정한다.
