- 위키독스: 피드 포워드 신경망 언어 모델(NNLM)를 정리한 내용입니다.
피드 포워드 신경망 언어 모델(NNLM)
기존의 통계적 언어모델은 한 번도 보지 못한 데이터에 대한 확률을 0으로 부여하는 등 언어를 정확히 모델링할 수 없다는 희소 문제가 있었다. 이 문제를 해결하기 위해 언어 모델이 단어의 유사도를 학습하게 한 신경망 언어모델(NNLM)이 탄생했다.
학습 과정
- 예문 : "what will the fat cat sit on"
- 입력(what, will, the, fat, cat) -> 언어모델 -> 출력(sit)
- 학습 코퍼스의 모든 단어를 원-핫 인코딩한다.
모든 단어는 단어 집합(vocabulary)의 크기의 차원을 가지는 원-핫 벡터이며, 이 원-핫 벡터는 훈련을 위한 NNLM의 입력이자 예측을 위한 레이블이다.
-
윈도우 크기 n만큼의 단어만 언어모델에 입력한다. 즉 예측할 단어 앞의 n개의 단어만 참고한다.
-
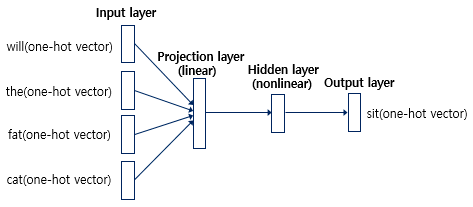
NNLM - 4개의 층으로 구성된 인공신경망(윈도우 크기가 4라고 가정)
-
입력층(input layer): 4개의 단어 'will, the, fat, cat'의 원-핫 벡터
-
투사층(projection layer): 입력과 가중치 행렬의 연산 (활성화 함수는 존재하지 않으므로 선형층(linear layer)이다.)
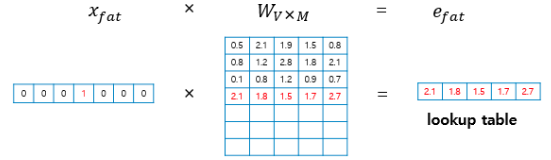
투사층의 크기가 M이고 단어집합의 크기가 V라면, 각 입력 단어들(크기: 1xV)은 VxM 크기의 가중치 행렬 W와 곱해져 1xM 크기의 행렬이 나온다. 원-핫 벡터인 입력과 가중치 행렬 W의 곱은 W행렬의 i번째 행을 그대로 읽어오는 것과 동일하므로 이 작업을 룩업 테이블(lookup table)이라고 부른다.
룩업 테이블 과정을 거친 후의 M차원의 단어 벡터는 초기에는 랜덤한 값을 가지지만 학습 과정에서 값이 변경된다. 이 단어 벡터를 임베딩 벡터(embedding vector)라고 한다.
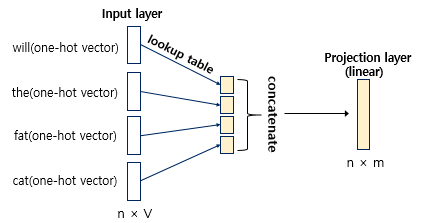
투사층에서 모든 임베딩 벡터들의 값은 연결(concatenation)된다.투사층:
(예측할 단어: 문장에서 t번째 단어, n: 윈도우 크기, lookup: 룩업테이블 함수, ;: 연결 기호) -
은닉층(hidden layer)
투사층의 결과는 h의 크기를 가지는 은닉층을 통과한다. 즉 은닉층의 입력이 가중치와 곱해진 후 편향이 더해져 활성화 함수의 입력이 된다. 따라서 은닉층은 비선형층(nonlinear layer)이다.은닉층:
(: 가중치, 편향, tanh: 활성화함수) -
출력층(Output layer): 예측할 단어 sit의 원-핫 벡터(오차를 구하기 위해 사용될 예정)
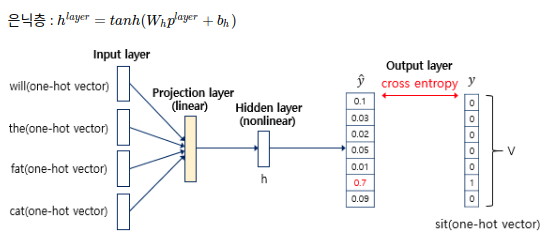
은닉층의 출력은 V의 크기의 출력층을 통과한다. 여기서 또다른 가중치와 곱해지고 편향을 더하면 입력이었던 원-핫 벡터와 같은 V차원의 벡터를 얻는다. 활성화함수인 소프트맥스(softmax) 함수를 지나면서 벡터의 각 원소는 0과 1사이의 실수값을 가지고 총합은 1인 상태가 된다. NNLM의 예측값인 의 j번째 인덱스의 값은 j번째 단어가 다음 단어일 확률이다.
출력층:
은 실제 정답인 단어 y의 원-핫 벡터의 값과 가까워져야 하므로 손실함수로 cross-entropy 함수를 사용해 손실을 구하고, 역전파가 이루어지면서 가중치 행렬들이 학습된다. 이 과정에서 임베딩 벡터값도 학습된다.
NNLM의 이점과 한계
-
이점: 밀집 벡터로 단어의 유사도를 표현해 희소 문제를 해결했다. n-gram 언어모델보다 저차원이므로 저장 공간을 적게 사용할 수 있다.
-
단점: 정해진 n개의 단어만 사용하므로 한정된 문맥만 참고한다. 따라서 다양한 길이의 입력 시퀀스를 제대로 처리하기 힘들다.
