LLM에 텍스트 빈도(Textual Frequency) 개념을 도입하는 Adam's Law 프레임워크를 제안한다. 기존 연구에서 텍스트 빈도가 인간의 인지 과정(예: 읽기 속도)과 관련 있음이 입증되었으나, LLM과의 관련성은 거의 연구되지 않았다. 이 연구는 입력 데이터의 빈도라는 새로운 관점을 제시하고, 이것이 LLM의 성능에 미치는 영향을 탐구한다.
1. 서론 (Introduction)
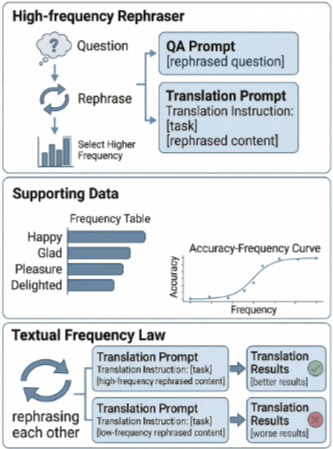
LLM은 CoT, 기계 번역, 공간 추론 등 다양한 능력을 보여주며, 최근에는 추론 과정의 길이를 늘리는 방향으로 연구가 진행된다. 훈련 데이터의 순서(예: 쉬운 것에서 어려운 것으로)도 중요한 요소로 부각된다. 그러나 어떤 종류의 데이터가 훈련에 유리한지에 대한 연구는 부족하다. 이전 연구들은 데이터의 품질과 양이 중요하다고 강조했으며, 큰 모델이 희귀 단어를 더 잘 예측한다는 점이 발견되었다. 또한 Cao et al. (2024)는 동일한 의미를 가진 다른 프롬프트가 LLM 성능에 큰 차이를 가져올 수 있음을 보였다. 이 논문은 동일한 의미를 가진 paraphrased 입력에 대해 빈도가 중요한지 탐구한다. 특히 텍스트 빈도가 LLM의 prompting과 fine-tuning에 영향을 미친다는 새로운 Textual Frequency Law(TFL)를 제안한다. 이는 고빈도 데이터가 pre-training 단계에서 더 자주 발생하여 LLM이 더 쉽게 이해할 수 있다는 가설에 기반한다.
이 논문의 주요 기여는 다음과 같다.
- Textual Frequency Law(TFL) 제안: 데이터의 의미가 동일할 때, prompting과 fine-tuning 시 고빈도 텍스트 데이터가 선호되어야 한다는 원칙을 제시한다.
- Textual Frequency Distillation(TFD) 제안: LLM이 생성한 story completion 데이터를 활용하여 온라인 리소스에서 수집한 빈도 추정치를 보강하는 방법을 제안한다.
- Curriculum Textual Frequency Training(CTFT) 제안: sentence-level 빈도가 낮은 데이터부터 높은 데이터 순서로 LLM을 fine-tuning하는 새로운 학습 방법을 제안한다.
2. 선행 연구 (Prior Works)
- Textual Frequency: 텍스트 빈도는 인간의 신경 활성화와 관련이 있으며, 고빈도 단어가 더 강한 신경 반응을 유발한다. AI 분야에서는 단어 빈도가 semantic retrieval에 영향을 미치며, 대형 모델이 희귀 단어를 더 잘 예측한다는 연구 결과가 있다.
- Paraphrasing on Language Models: Paraphrasing은 LLM 평가, 데이터 오염 완화, 데이터 증강 등 다양한 NLP 연구에 활용된다. 이 논문은 동일한 의미를 가진 paraphrases 중 어떤 빈도의 paraphrases가 computational budget이 제한된 상황에서 더 유용한지 탐구한다.
3. 제안 방법 (Proposed Approach)
3.1 Task Formulation: LLM을 Seq2Seq 신경망으로 간주하며, P(y | i, x) = 를 최대화한다. 여기서 i는 지시문, x는 입력, y는 생성된 출력이다.
3.2 Textual Frequency Law (TFL): TFL은 prompting과 fine-tuning 모두에 대해 동일한 의미를 가진 paraphrases 집합 P 내에서 가장 높은 sentence-level textual frequency를 가진 x를 선택하도록 제안한다. 이는 argmax_{x∈P} (sfreq(x, D))로 표현된다. sentence-level 빈도 sfreq(x, D)는 word-level 빈도 wfreq(x_k, D)의 역정규화된 곱으로 추정된다: sfreq(x, D) = K_s (1/Q * Π_{k=1}^K wfreq(x_k, D)). 여기서 D는 임의의 텍스트 코퍼스이며, K_s는 정규화 상수이다.
- Prompting: LLM에 출력을 생성하도록 프롬프트할 때, 더 높은
x가 사용되어야 한다. - Fine-tuning: LLM을 fine-tuning할 때, 더 높은 빈도를 가진
x가 원하는 ground truth 출력y와 함께 사용되어야 한다.
3.3 Textual Frequency Distillation (TFD): 온라인 리소스에서 얻은 초기 빈도 추정치(F1)를 보강하기 위해 TFD를 제안한다. TFD는 LLM에 <textual data>에 대한 story completion을 요청하여 distilled dataset D'를 생성한다. 이를 통해 새로운 빈도 추정치 F2 = sfreq(x, D')를 얻는다. 최종 빈도 F(x)는 F1과 F2의 가중 합으로 계산된다: F(x) = αF1(x) + (1 + ζ1(F1(x) = 0))βF2(x). 여기서 α, β, ζ는 하이퍼파라미터이며, ζ는 F1에서 빈도가 무시할 만한 경우 distilled frequency의 효과를 강화하는 요소이다.
3.4 Curriculum Textual Frequency Training (CTFT): fine-tuning 시 빈도 정보를 활용하는 방법이다. 훈련 세트 T의 N개 인스턴스에 대해 각 에포크마다 sort_xn∈T (F(xn))와 같이 낮은 빈도에서 높은 빈도 순서로 데이터를 정렬하여 훈련한다.
3.5 Textual Frequency Paired Dataset (TFPD): 이 연구의 목표에 적합한 데이터셋이 부족하여 TFPD를 직접 구축한다. GSM8K, FLORES-200, CommonsenseQA 데이터셋의 영어 문장을 GPT-4o-mini로 rephrase하여 고빈도 및 저빈도 paraphrase 쌍을 생성한다. 세 명의 인간 annotator가 rephrased 문장의 의미 동일성을 검증하여, 모든 annotator가 의미가 동일하다고 판단한 샘플만 보존한다. 최종적으로 GSM8K에서 738쌍, FLORES-200에서 526쌍을 얻는다. fine-tuning 실험에서는 TFPD를 훈련 데이터로 사용한다.
4. 실험 설정 (Experimental Setup)
4.1 Evaluation Metrics: Math Reasoning에서는 Accuracy, Machine Translation에서는 chrF, BLEU, COMET 점수를 사용한다.
4.2 Baselines: Closed-source LLM으로 GPT-4o-mini와 DeepSeek-V3를, open-source LLM으로 doubao-1.5-pro-32k 및 qwen2.5-7b-instruct를 사용한다. fine-tuning 실험은 qwen2.5-7b-instruct에서 LoRA fine-tuning을 사용한다. Llama-3.3-70B-Instruct도 Math Reasoning에 사용된다. TFL을 reverse 설정(고빈도에서 저빈도로 fine-tuning) 및 전통적인 curriculum learning(쉬운 것에서 어려운 것으로)과 비교한다.
4.3 Off-the-shelf Frequency Estimation: Zipf frequency를 사용하여 off-the-shelf 빈도를 추정한다.
4.4 Language Selection: FLORES-200에서 100개 언어를 무작위로 선택하여 prompting 실험에 사용한다. CTFT 실험에는 Kabuverdianu, Kikuyu, Pangasinan, Standard Latvian을 사용한다.
4.5 Translation Prompt: 1-shot translation prompt 형식을 명시한다.
5. 결과 (Results)
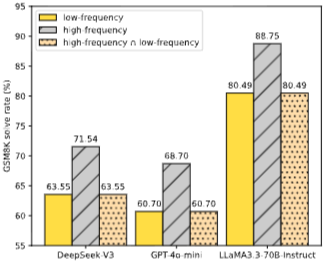
5.1 Prompting on Math Reasoning: Figure 2는 Math Reasoning 작업에서 TFPD를 사용한 prompting 실험의 전반적인 정확도를 보여준다. DeepSeek-V3, GPT-4o-mini, LlaMA3.3-70B-Instruct 등 모든 모델에서 고빈도 파티션이 저빈도 파티션보다 높은 정확도를 보인다. 고빈도 버전은 저빈도 파티션에서 모델이 잘못 답변한 샘플을 개선하며, 원래 올바르게 답변한 샘플의 성능은 유지한다.
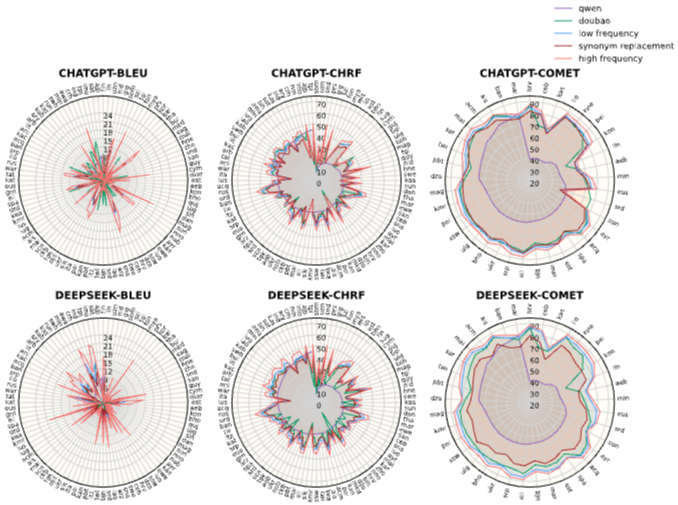
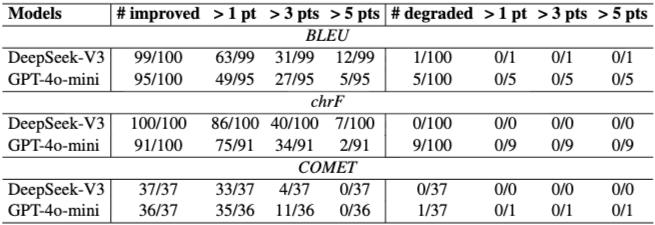
5.2 Prompting on Neural Machine Translation: Figure 3은 Neural Machine Translation(NMT)에서 TFPD 데이터셋을 사용한 결과를 보여준다. 고빈도 rephrase를 사용하는 것이 TFL이 제시하는 바와 같이 전반적으로 더 나은 결과를 가져온다. Table 3은 NMT 개선 통계를 보여주며, 대부분의 언어 쌍에서 고빈도 파티션 사용 시 BLEU, chrF, COMET 점수가 향상된다. 성능 저하가 발생하더라도 1점 미만으로 미미하다.

5.3 Prompting on Commonsense Reasoning: Table 2는 Commonsense Reasoning(CR) 작업에서 고빈도 파티션이 저빈도 파티션을 능가함을 보여주며, 제안된 빈도 법칙의 효과를 실험적으로 입증한다.
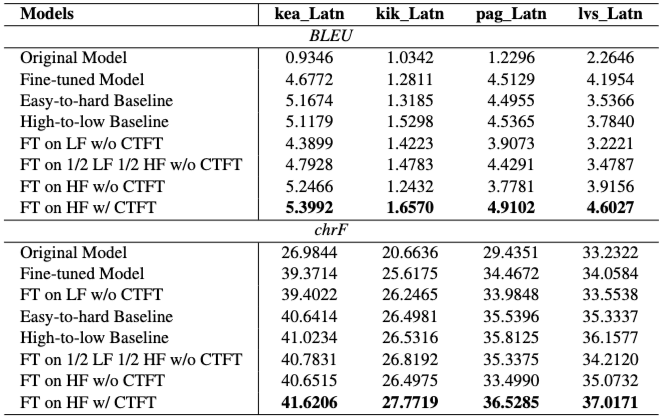
5.4 Fine-tuning on Neural Machine Translation: Table 4는 NMT fine-tuning 실험 결과를 제시한다.
- 고빈도 파티션이 ground-truth 데이터보다 우수: 원본 FLORES-200 데이터셋으로 fine-tuning한 baseline보다 TFPD의 고빈도 파티션으로 fine-tuning한 모델(TFD 또는 CTFT 없이)이 더 나은 성능을 보인다.
- 고빈도 파티션이 저빈도 파티션보다 우수: 저빈도 파티션으로 fine-tuning한 경우보다 고빈도 파티션으로 fine-tuning한 경우 성능이 더 좋다. 저빈도 파티션의 절반을 고빈도 파티션으로 대체해도 결과가 개선된다.
- CTFT가 fine-tuning에 유용: CTFT를 사용하여 낮은 빈도에서 높은 빈도 순서로 모델을 훈련하는 것이 모든 실험에서 가장 좋은 성능을 달성한다.
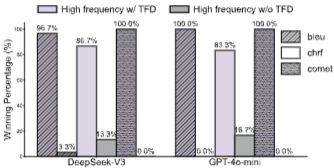
5.5 Analysis on TFD: Figure 4는 TFD에 대한 ablation study 결과를 보여주며, TFD를 제거하면 성능이 저하된다. Figure 5는 TFD에 사용되는 데이터 양과 성능 개선 사이의 관계를 보여주며, 더 많은 데이터가 사용될수록 성능 향상이 커진다.
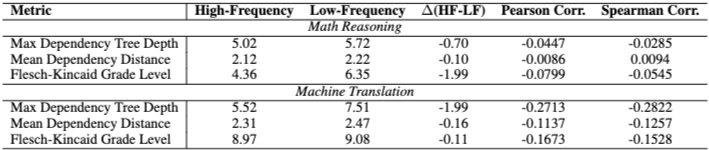
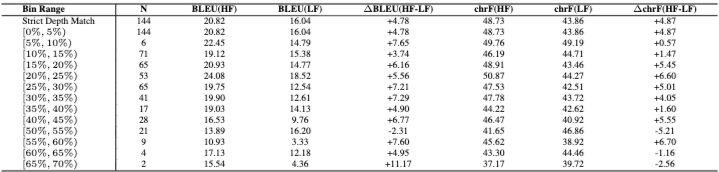
5.6 Correlation on Frequency: Textual frequency와 최종 번역 성능 간의 강한 상관관계(특히 영어에서 일부 언어로의 번역에서 1.0)가 나타난다. Table 5는 textual complexity와 frequency 간의 상관관계가 매우 약함을 보여주어, TFL이 전통적인 curriculum learning과 구분되는 유용성을 강화한다. Table 6은 대부분의 경우 고빈도 프롬프트가 더 나음을 보여준다.
6. 결론 (Conclusions)
이 논문은 TFL, TFD, CTFT로 구성된 LLM을 위한 텍스트 빈도 프레임워크를 제안한다. 프레임워크는 prompting과 fine-tuning 시 고빈도 입력을 사용할 것을 제안하며, 이는 curriculum learning과 결합하여 최종 성능을 향상할 수 있다. Math Reasoning, Machine Translation, Commonsense Reasoning, Agentic Tool Calling 작업에 대한 실험 결과와 광범위한 분석은 제안된 텍스트 빈도 프레임워크의 효과를 입증한다. 입력이 다르더라도 LLM의 최종 출력이 텍스트 빈도와 양의 상관관계를 보인다는 점은 제안된 프레임워크의 타당성을 뒷받침한다.
제한점 (Limitations):
- Story completion을 통한 빈도 추정은 계산 비용이 발생할 수 있지만, closed-source LLM의 훈련 코퍼스를 얻을 필요가 없다는 장점이 있다.
- A. Scope and Proof Strategy: Textual Frequency Law(TFL)에 대한 형식적인 증명을 제공한다. TFL은 동일한 의미를 가진 두 텍스트 시퀀스 중 고빈도 시퀀스가 언어 모델에서 더 낮은 negative log-likelihood(NLL) loss를 유발한다는 것을 의미한다.
- Part I (Section D): Zipf의 법칙 하에서 token-level NLL loss와 토큰 빈도 순위 간의 관계를 설정한다.
- Part II (Section E): sentence-level 빈도 측정을 도입하고 marginal 예측과 conditional 예측 간의 차이를 고려하여 token-level 결과를 sentence-level로 확장한다.
- Section F: 수학적 결론(loss ordering)과 경험적 관찰(task performance ordering) 간의 관계를 논의한다.
- Section H: 이론적 프레임워크의 한계를 설명한다.
- D. Part I: Token-Level Results:
- Step 1: Self-Information under Zipf’s Law: Zipf의 법칙에 따라 토큰 의 self-information(이상적인 NLL)은 ()로 표현되며, 이는 에 대한 선형 관계를 나타낸다.
- Step 2: Model Loss Bounded by Approximation Error: Assumption 2에 의해 모델의 marginal 토큰-레벨 NLL loss 는 이상적인 NLL 에 라는 근사 오차를 더한 값으로 표현된다: , 여기서 이다.
- Theorem 1 (Token-Level Semi-Log Linearity): Assumption 1과 2하에서 marginal token-level NLL loss는 를 만족한다.
- Theorem 2 (Sufficient Condition for Strict Token-Level Monotonicity): 인 두 토큰 에 대해 가 성립하는 충분조건은 이다. 이는 근사 오차가 Zipf가 유도하는 간격보다 작을 때만 단조성이 보장됨을 의미한다.
- E. Part II: Sentence-Level Extension:
- Setup: 문장 의 autoregressive 모델이 계산하는 loss 와 Assumption 4에 따른 log sentence-frequency 를 정의한다.
- Step 4: Decomposing Sentence-Level Loss: 각 토큰 의 conditional loss는 이상적인 marginal NLL , marginal 근사 오차 , 그리고 contextual discrepancy 의 합으로 분해된다: . 이를 문장 전체에 대해 평균하면 가 된다.
- Theorem 3 (Sentence-Level Loss–Frequency Relationship): Assumption 1, 2, 3, 4 하에서 sentence-level NLL loss는 를 만족하며, 여기서 이다. 즉, sentence-level loss는 negative log sentence-frequency에 근사하며, 그 오차는 로 bounded된다.
- Theorem 4 (Textual Frequency Law — Sufficient Condition): 인 두 paraphrases 와 에 대해 가 성립하는 충분조건은 이다. 이는 두 paraphrase 간의 로그 빈도 비율이 모든 오차 경계의 합보다 커야 함을 의미한다.
윤리적 고려 사항 (Ethical Statement): ACL ARR Code of Ethics를 준수한다. 사용된 데이터셋은 잘 알려져 있으며, 데이터 전처리는 외부 텍스트 리소스를 사용하지 않는다. LLM 사용으로 인한 잠재적인 공격적 콘텐츠 생성은 알려진 문제이며, 저자의 견해를 반영하지 않는다.
