초록 (Abstract)
이 논문은 LLM과 tool-using agent를 활용하여 데이터 관리, 준비 및 분석 작업을 자동화하는 새로운 패러다임인 Data Agent를 제시한다. 현재 "Data Agent"라는 용어는 단순한 질의 응답 assistant부터 완전 자율적인 "데이터 과학자"에 이르기까지 일관성 없이 사용되어 능력과 책임의 경계를 모호하게 만들고 있다. 이러한 혼란을 해결하기 위해, 이 논문은 Level 0(L0, 자율성 없음)부터 Level 5(L5, 완전 자율성)까지 Data Agent의 계층적 분류를 제안한다. 이 분류를 바탕으로, Data Agent의 lifecycle 및 level-driven 관점을 소개하며, L0-L5 분류와 각 level을 구분하는 핵심적인 진화적 도약점을 설명한다. 또한, 데이터 관리, 준비, 분석 전반에 걸친 L0-L2 시스템을 검토하고, 감독하에 end-to-end 데이터 워크플로우를 자율적으로 조정하려는 Proto-L3 시스템을 강조하며, proactive(L4) 및 generative(L5) Data Agent를 향한 연구 과제를 논의한다. 이 논문은 현재 시스템의 실제적인 지도와 향후 10년간 Data Agent 개발을 위한 연구 로드맵을 제공하는 것을 목표로 한다.
1. 서론 (Introduction)
현대 데이터 생태계는 이질적이고 multimodal한 데이터 소스, 진화하는 스키마, 그리고 밀접하게 연결된 Data+AI 파이프라인으로 인해 점점 더 복잡해지고 있다. 동시에 LLM 기반 agent는 tool 사용, 계획, 반복적 추론에서 강력한 능력을 보여주었다. 그 결과 "Data Agent"라는 용어는 학계와 산업계에서 빠르게 인기를 얻었으며, 단순한 SQL 또는 BI 챗봇부터 완전 자율적인 "AI 데이터 과학자"로 마케팅되는 야심 찬 제품에 이르기까지 다양한 시스템을 포함한다. 공유된 어휘 없이는 근본적으로 다른 시스템들이 단일하고 과부하된 용어로 혼용되어 사용자 기대의 불일치, 실패 시 모호한 책임, 그리고 다른 접근 방식 간의 객관적인 비교의 어려움을 초래한다. 이러한 혼란을 해결하기 위해 이 튜토리얼은 L0(자율성 없음)부터 L5(완전 자율성)까지의 Data Agent 계층적 분류를 제시하며, task dominance와 책임이 인간 운영자에서 Data Agent로 점진적으로 전환되는 방식을 설명한다. 이 튜토리얼의 목표는 참가자들이 Data Agent의 현실적인 능력, 데이터 lifecycle 전반의 시스템을 이해하고, 더 높은 자율성을 향한 주요 연구 과제를 식별하도록 돕는 것이다.
1.1. 튜토리얼 개요 (Tutorial Overview)
이 튜토리얼은 3시간 분량으로, 140분간의 강의(Part I-IV)와 40분간의 Data Agent Playground(Part V)로 구성된다.
-
Part I: 문제 정의 및 예비 지식 (Problem Definition and Preliminaries) (30분)
- Data Agent의 동기와 문제 정의를 소개하고, 기존 "데이터 assistant" 시스템의 한계 및 자율성과 책임의 명시화 필요성을 강조한다.
- Data Agent를 보다 형식적으로 정의하고, 환경, 데이터 규모 및 구조, 오류 전파, 거버넌스 요구 사항과 같은 차원에서 일반적인 LLM agent와 대조한다.
- 주요 도전 과제(용어 모호성, lifecycle fragmentation, 자율성 vs. 거버넌스, 기술적 병목 현상)를 요약하고 level 기반 Data Agent 분류의 필요성을 설명한다.
-
Part II: 데이터 lifecycle 전반의 L0-L2 Data Agent (L0–L2 Data Agents Across the Data Lifecycle) (40분)
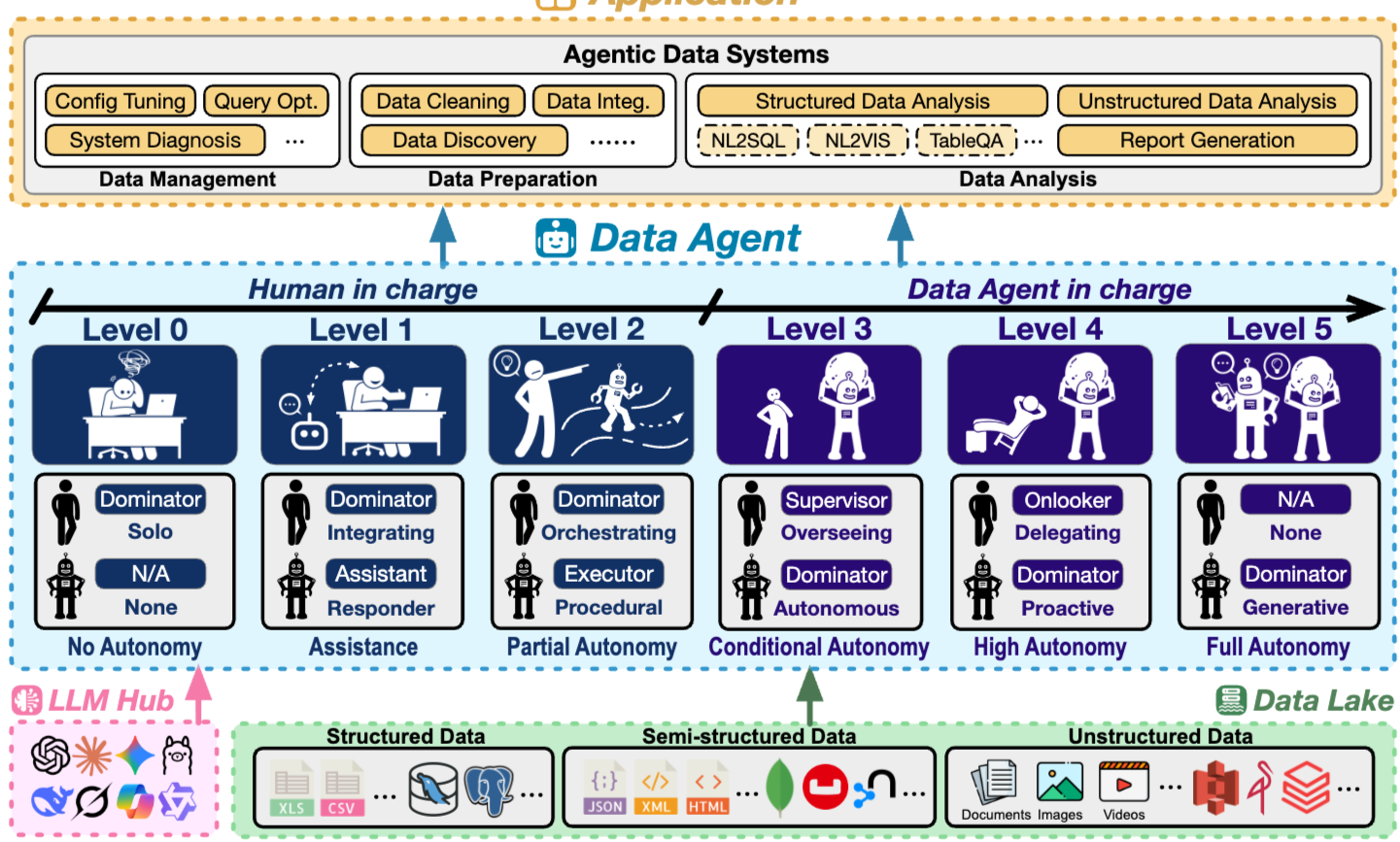
- 데이터 관리, 데이터 준비, 데이터 분석의 세 가지 데이터 lifecycle 단계에서 L0, L1, L2가 어떻게 나타나는지 개괄하고, Figure 1에 설명된 인간과 agent의 역할과 연결한다.
- 각 단계를 심층적으로 탐구한다.
- 데이터 관리: 수동 DBA(L0)에서 데이터베이스 튜닝/진단/쿼리 최적화 copilot(L1), 그리고 DBMS 및 모니터링 신호에 직접 접근하는 L2 agent로 진화한다.
- 데이터 준비: 스크립트 및 규칙(L0)에서 데이터 cleaning, integration, discovery를 위한 suggestion 스타일 copilot(L1), 그리고 외부 도구를 호출하고 실행 feedback을 통해 루프를 닫는 L2 agent로 진화한다.
- 데이터 분석: structured data analysis(Table QA, NL2SQL, NL2VIS), unstructured data analysis, report generation(prompt-response paradigm, L1)에서 state를 유지하고 SQL, plotting, retrieval tool을 호출하는 L2 environment-perceived analysis agent로 진화한다.
- 두 가지 예시(예: 데이터베이스 operation 및 BI analytics)를 사용하여 L0, L1, L2 간의 차이를 구체화한다. L0-L2의 재현되는 design pattern과 reliability boundary를 요약한다.
-
Part III: L3 Data Agent 및 Proto-L3 시스템 (L3 Data Agents and Proto-L3 Systems) (45분)
- L3를 공식적으로 정의하고 L2에서 L3로의 핵심적인 진화적 도약을 설명한다.
- LLM orchestrator, semantic operator, task DAG optimization, tool evolution을 탐구하여 다재다능하고 cross-task 워크플로우를 지원하는 학계의 대표적인 Proto-L3 시스템을 제시하고, 그 아키텍처, 지원되는 task, orchestration 전략 및 한계를 논의한다.
- 클라우드 데이터 플랫폼 및 lakehouse의 산업용 "Data Agent" 제품을 분석하고, 해당 level에 매핑하며, 공통 design pattern(예: DAG 기반 pipeline orchestration, planner-executor 분리, multi-agent collaboration mechanism) 및 현재 병목 현상(예: 미리 정의된 operator/tool, 제한된 causal/meta reasoning, 제약된 task coverage, human-crafted guardrail에 대한 강한 의존성)을 강조한다.
-
Part IV: L4-L5 및 연구 로드맵 (Towards L4–L5 and Research Roadmap) (25분)
- L4 Data Agent의 비전을 proactive, long-lived, self-governing component로 상세히 설명하며, Data+AI 생태계를 지속적으로 모니터링하고, 문제와 기회를 자율적으로 발견하며, 명시적 지시 없이 파이프라인을 조정하는 능력을 강조한다.
- L5 Data Agent를 새로운 solution, 알고리즘 및 패러다임을 발명할 수 있는 generative 데이터 과학자로 소개한다.
- 주요 미해결 문제(자율적 orchestration 및 다양성, causal 및 meta reasoning, intrinsic motivation 및 task discovery, long-horizon planning 및 trade-off, 안전 및 거버넌스, 자율성 벤치마크)를 요약한다.
-
Part V: Data Agent Playground - hands-on 탐색 및 토론 (Data Agent Playground — Hands-on Exploration and Discussion) (40분)
- 몇 가지 구체적인 Data Agent 워크플로우를 살펴보고, L1/L2/Proto-L3 agent가 단계별로 어떻게 작동하는지 보여주며, 참가자들이 직접 Data Agent 프로토타입을 시도하도록 초대한다. 참가자들은 자신의 환경에 맞는 agent를 스케치하거나 개선하고, L0-L5 스펙트럼에 배치하며, 자율성, 거버넌스, 신뢰성의 주요 trade-off를 논의하도록 권장된다. 이어서 Part IV의 연구 로드맵과 연결되는 Q&A 세션이 진행된다.
1.2. 우리의 범위와 목표 (Our Scope and Goals)
-
기존 튜토리얼과의 차별점 (Our Distinction from Existing Tutorials)
- Level 기반 관점 (Level-based view): 자율성, 능력, 책임을 명시적으로 연결하는 Data Agent의 level 기반 관점(L0-L5)을 채택하여 각 level의 "Data Agent"가 무엇을 할 수 있고 무엇을 할 수 없는지 쉽게 추론할 수 있도록 한다.
- Holistic lifecycle 관점 (Holistic lifecycle perspective): 개별 task를 독립적으로 다루기보다는 통합된 Data Agent 프레임워크 내에서 데이터 관리, 데이터 준비, 데이터 분석을 함께 다루는 holistic lifecycle 관점을 취한다.
- 진화적 도약 및 로드맵 (Evolutionary leaps and roadmap): level 간의 진화적 도약, 특히 중요한 L2→L3 및 L3→L4 전환을 강조하고, proactive(L4) 및 generative(L5) Data Agent를 향한 연구 로드맵을 제시한다.
-
대상 독자 및 학습 결과 (Target Audience and Learning Outcomes)
데이터베이스, 데이터 마이닝, 머신러닝, AI agent, 데이터 중심 AI 연구자, 데이터 플랫폼, lakehouse, 엔터프라이즈 데이터 스택을 구축하는 시스템 개발자 및 실무자, 그리고 Data Agent 분야에 진입하고자 하는 학생들을 포함한 광범위한 SIGMOD 청중을 대상으로 한다.
튜토리얼이 끝나면 참가자들은 L0-L5 프레임워크를 사용하여 기존 및 미래 시스템을 위치시키고, Data Agent와 일반 LLM agent를 구별하며, "Data Agent"에 대한 vendor의 주장을 해석하고 검증하며, 자신의 응용 프로그램에 적합한 자율성 level을 선택하고, perception, planning, tool, memory, governance와 같은 주요 design dimension에 대해 추론할 수 있다.
2. 튜토리얼 개요 (Tutorial Outline)

2.1. 배경 및 문제 정의 (Background and Problem Definition)
-
2.1.1. 문제 설명: Data Agent란 무엇인가? (Problem Description: What is a Data Agent?)
- 비공식적으로 Data Agent는 데이터 관련 task(예: configuration tuning, 데이터 cleaning, integration, exploration, analysis)를 수행하기 위해 Data+AI ecosystem을 조정하는 LLM 기반 아키텍처이다.
- 형식적으로 Data Agent 는 환경 (예: DBMS, code interpreter, API 등) 내에서 raw data 에 대해 작동하며, LLM 을 사용하여 데이터 관련 task 를 해결하기 위해 출력 를 생성한다: .
-
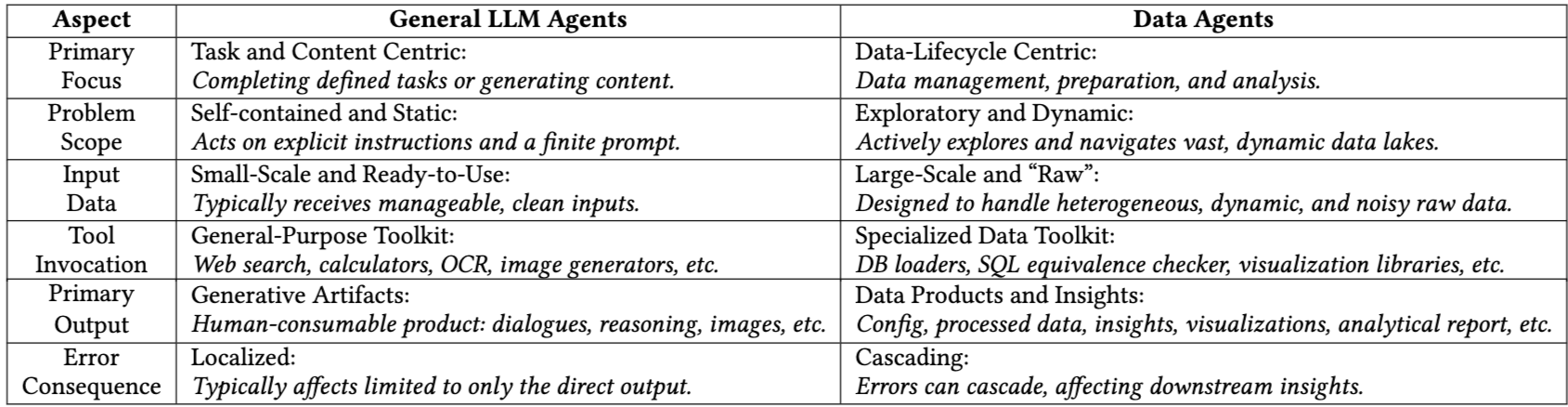
2.1.2. Task Landscape 및 Data Agent vs. 일반 LLM Agent (Task Landscape and Data Agents vs. General LLM Agents)
- Data Agent는 관계형 데이터베이스, 데이터 웨어하우스 및 lakehouse, 데이터 lake, ETL/ELT 파이프라인, BI tool, ML 서비스를 아우르는 현대 Data+AI ecosystem 내에서 작동한다.
- Table 1은 Data Agent와 일반 LLM agent 간의 주요 차이점을 요약한다.
- Primary Focus: 일반 LLM agent는 task 및 content 중심(정의된 task 완료 또는 content 생성)인 반면, Data Agent는 data-lifecycle 중심(데이터 관리, 준비, 분석)이다.
- Problem Scope: 일반 LLM agent는 self-contained 및 static(명시적 지시와 유한한 prompt에 따라 작동)인 반면, Data Agent는 exploratory 및 dynamic(방대하고 동적인 데이터 lake를 적극적으로 탐색하고 탐색)이다.
- Input Data: 일반 LLM agent는 small-scale 및 ready-to-use 데이터를 사용하는 반면, Data Agent는 large-scale 및 "raw" 데이터를 처리한다.
- Tool Invocation: 일반 LLM agent는 general-purpose toolkit(웹 검색, 계산기 등)을 사용하는 반면, Data Agent는 specialized data toolkit(DB loader, SQL equivalence checker, visualization library 등)을 사용한다.
- Primary Output: 일반 LLM agent는 generative artifact(대화, 추론, 이미지 등)를 생성하는 반면, Data Agent는 data product 및 insight(configuration, 처리된 데이터, insight, visualization, analytical report 등)를 생성한다.
- Error Consequence: 일반 LLM agent의 오류는 localized(주로 직접적인 출력에만 영향)인 반면, Data Agent의 오류는 cascading(다운스트림 insight에 영향)이다.
-
2.1.3. 주요 도전 과제 (Key Challenges)
- 모호한 용어 및 과장된 주장 (Ambiguous terminology and overstated claims): 공유된 어휘 없이 매우 다른 자율성 level을 가진 시스템들이 모두 "Data Agent"로 마케팅되어 혼란과 오해를 초래한다.
- 데이터 lifecycle 전반의 fragmentation (Fragmentation across the data lifecycle): Data Agent는 데이터 관리, 데이터 준비, 데이터 분석을 이질적이고 multi-modal한 데이터 lake 전반에서 다루어야 하지만, 대부분의 기존 작업은 개별 task 또는 단계를 고립적으로 다루므로 end-to-end 능력과 trade-off에 대한 추론을 어렵게 한다.
- 자율성 vs. 거버넌스 (Autonomy vs. governance): 자율성이 증가함에 따라 책임 할당, 안전한 운영 영역 정의, 보증 제공이 더욱 중요하고 도전적으로 된다.
- 기술적 병목 현상 (Technical bottlenecks): 더 높은 자율성 level로 나아가기 위해서는 perception, long-horizon planning 및 orchestration, memory 및 continual adaptation, causal 및 meta reasoning, 동적 환경과의 견고한 상호 작용 분야에서 발전이 필요하다.
2.2. Data Agent의 L0-L5 계층 구조 (The L0–L5 Hierarchy of Data Agents)
SAE J3016 운전 자동화 표준에서 영감을 받아, L0부터 L5까지 6단계의 Data Agent 자율성 분류를 채택한다. Figure 1에 요약된 바와 같이, Data Agent는 6가지 자율성 level로 구성된다.
-
L0: 자율성 없음 (No Autonomy)
- Data Agent의 개입이 전혀 없다. 데이터 관리, 준비, 분석의 모든 task는 인간이 수동으로 수행한다.
-
L1: 지원 (Assistance)
- L1 Data Agent는 stateless, prompt-response 프레임워크 내에서 작동한다. 질문에 답하거나, 코드 스니펫을 생성하거나, 쿼리를 제안할 수 있지만, 환경을 인지하거나 상호 작용하지는 않는다. 인간은 모든 제안을 실행하고 검증할 전적인 책임을 진다.
- Figure 1에서 Data Agent의 역할은 Responder이며, 인간이 Dominator이다.
-
L2: 부분 자율성 (Partial Autonomy)
L2 Data Agent는 데이터 lake, DBMS, code interpreter, 외부 API를 포함한 환경을 인지하고 상호 작용할 수 있는 능력을 얻는다. memory를 가질 수 있으며, 인간이 조정하는 파이프라인 내에서 task-specific 절차를 자율적으로 실행하기 위해 tool을 호출할 수 있다.
Figure 1에서 Data Agent의 역할은 Procedural Executor이며, 인간이 Dominator이다.
-
L3: 조건부 자율성 (Conditional Autonomy)
- L3 Data Agent는 인간의 감독하에 광범위한 task를 위해 맞춤형 데이터 파이프라인을 자율적으로 조정하고 실행할 것으로 예상된다. 높은 level의 사용자 의도를 해석하고 end-to-end 워크플로우를 주도하며, 인간은 supervisor 역할을 한다.
- Figure 1에서 Data Agent의 역할은 Orchestrating Supervisor이며, Data Agent가 Dominator이다.
-
L4: 높은 자율성 (High Autonomy)
- L4 Data Agent는 높은 자율성과 신뢰성을 달성하여 인간의 감독과 명시적인 지시가 필요 없다. Data+AI ecosystem을 proactive하게 모니터링하고, 데이터 lake에서 문제와 기회를 자율적으로 발견하며, 이를 해결하기 위해 파이프라인을 조정하는 데 완전히 위임된다.
- Figure 1에서 Data Agent의 역할은 Proactive Dominator이며, Data Agent가 Dominator이다.
-
L5: 완전 자율성 (Full Autonomy)
- L5 Data Agent는 기존 방법을 적용하는 것을 넘어 새로운 solution, 알고리즘 및 패러다임을 발명할 수 있는 완전 자율적이고 generative 데이터 과학자로 구상된다. 인간의 개입이 불필요해진다.
- Figure 1에서 Data Agent의 역할은 Generative Dominator이며, Data Agent가 Dominator이다.
2.3. L0-L2: 수동 워크플로우에서 부분 자율성으로 (L0–L2: From Manual Workflows to Partial Autonomy)
2.3.1. 데이터 관리 (Data Management)
- L0: DBA는 전문 지식과 trial-and-error에 의존하여 knob, index configuration, execution plan을 수동으로 튜닝한다.
- L1: LLM은 tuning suggestion 또는 rewritten query를 생성하는 query-responsive assistant로 사용된다. prompt-response 방식으로 작동하며, 인간이 통합하고 검증해야 하는 권장 사항을 반환한다. 예: -Tune [19], E2ETune [23], Andromeda [9].
- L2: Data Agent는 DBMS 및 모니터링 정보에 직접 접근한다. workload statistics를 관찰하고, tuning experiment를 실행하며, human-designed 워크플로우를 따르면서 decision loop에서 configuration을 조정하거나 query를 재작성할 수 있다. 예: Rabbit [67], R-Bot [69], D-Bot [97].
2.3.2. 데이터 준비 (Data Preparation)
- L1: Data Agent는 주로 suggestion engine으로 작동한다. 예: RetClean [51], LakeFill [83] (결측치 추론 및 imputation), LLMClean [4] (cleaning task를 위한 규칙 생성), Narayan et al. [52] (스키마 매치 또는 entity correspondence 제안), AutoDDG [88], LLMCTA [27] (데이터셋 요약, metadata, 또는 column annotation 생성). Homomorphic compression [21]은 Data Agent의 계산 비용을 줄이면서 semantic integrity를 유지하는 유망한 방법이다.
- L2: Data Agent는 query responder를 넘어 데이터베이스 또는 데이터 lake와 직접 상호 작용하여 cleaning 및 transformation operation을 실행하고, constraint를 검증하며, 실행 feedback을 기반으로 전략을 조정하고, 더 많은 데이터가 탐색됨에 따라 integration 결정 사항을 반복적으로 개선한다. 예: CleanAgent [57], MegaTran [32] (데이터 cleaning), SEED [10], Agent-OM [58] (데이터 integration), LEDD [3], DBDescGen [37] (데이터 discovery).
2.3.3. 데이터 분석 (Data Analysis)
- L1: 주로 Table QA [11, 64, 86], NL2SQL [30, 42, 56, 99], NL2VIS [36, 43, 46, 49], textual 또는 multimodal Document QA [14, 59, 70, 79, 80]와 같은 LLM-driven question-answering assistant를 볼 수 있으며, curated dataset에 대한 사용자 질문에 응답하거나, 입력 테이블 또는 문서에 대해 작동하는 report generator [6, 65, 71]가 있다.
- L2: Data Agent는 static querying을 넘어 multi-step analytical process에 동적으로 참여, 검증 및 개선한다. SQL engine [29, 31], plotting library [53, 81, 85], retrieval module [25, 78, 92]과 같은 tool을 호출하며, analysis의 반복적 탐색 및 개선을 지원한다 [13, 54, 84].
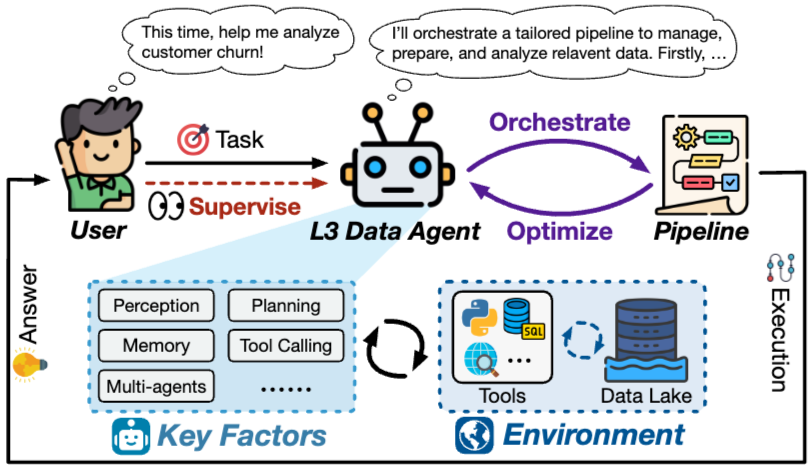
2.4. L3: 자율 Data Agent를 향한 노력 (L3: Striving for Autonomous Data Agents)
2.4.1. Executor에서 Dominator로 (From Executor to Dominator)
L2에서는 인간이 전체 파이프라인을 설계하고, Data Agent는 인간이 지정한 워크플로우 내에서 특정 절차를 실행한다. 대조적으로 L3에서는 Data Agent가 높은 level의 사용자 의도를 해석하고 데이터 관리, 준비, 분석에 걸친 파이프라인을 자율적으로 조정할 것으로 예상된다. 실행 중 Data Agent는 feedback과 중간 결과를 기반으로 파이프라인을 조정하며, 인간은 파이프라인 설계자가 아니라 주로 계획과 결과를 검토하는 supervisor 역할을 한다. 이처럼 task dominance와 주요 책임이 인간에서 Data Agent로 전환된다. Figure 3은 L3 Data Agent의 일반적인 모습을 보여주며, 자율적인 파이프라인 조정 및 최적화에서의 조건부 자율성을 강조한다.
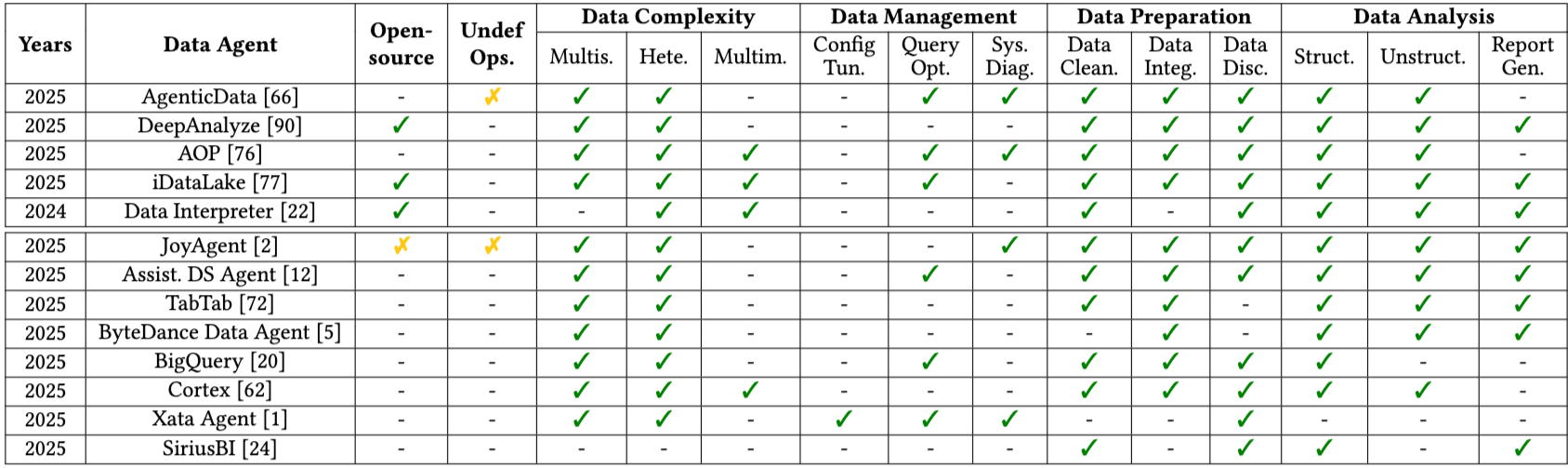
2.4.2. 연구 분야의 Proto-L3 Data Agent (Proto-L3 Data Agents in Research)
최근 연구 시스템은 부분적인 L3 능력을 보이기 시작한다. LLM 기반 orchestrator [66], 미리 정의된 operator [76, 77], workflow optimization [22, 76], tool library [90]를 사용하여 이기종 시스템 전반의 multi-step 워크플로우를 조정하고, 단일 agentic process 내에서 데이터 lifecycle의 여러 단계를 포괄하며, long-running interaction에서 state를 유지하여 계획을 개선하고 실수를 수정할 수 있다. 이러한 Proto-L3 agent는 일반적으로 curated tool 및 데이터가 있는 제약된 환경에서 작동하지만, execution 중심 L2 agent에서 orchestration 중심 L3 시스템으로의 전환을 연구하기 위한 구체적인 testbed를 제공한다.
- Table 2: 학계 연구 및 산업 제품의 대표적인 Proto-L3 Data Agent 비교 (Comparison of Representative Proto-L3 Data Agents from Academia Research and Industry Products)
- Open-source: 오픈 소스 여부
- Undef Ops.: 미리 정의되지 않은 operator 활용 능력
- Data Complexity: Multi-source (Multis.), Heterogeneous (Hete.), Multimodal (Multim.)
- Data Management: Config Tun., Query Opt., Sys. Diag.
- Data Preparation: Data Clean., Data Integ., Data Disc.
- Data Analysis: Struct., Unstruct., Report Gen.
- Table 2는 AgenticData [66], DeepAnalyze [90], AOP [76], iDataLake [77], Data Interpreter [22], JoyAgent [2], Assist. DS Agent [12], TabTab [72], ByteDance Data Agent [5], BigQuery [20], Cortex [62], Xata Agent [1], SiriusBI [24]와 같은 시스템들의 기능을 비교하여 제시한다.
2.4.3. 산업용 Data Agent 제품 (Industrial Data-Agent Products)
산업 플랫폼(예: 클라우드 데이터 웨어하우스 및 lakehouse)은 상업용 "Data Agent" 제품 [20, 62]을 제공하기 시작했다. 이들은 실제 L0-L3 level에 어떻게 매핑되는지, 어떤 보증(예: human-in-the-loop confirmation, logging, rollback)을 제공하는지, 그리고 일반적인 한계 및 design trade-off를 분석한다.
2.4.4. 현재 병목 현상 및 격차 (Current Bottlenecks and Gaps)
현재 시스템이 완전한 L3 자율성을 실현하는 것을 방해하는 몇 가지 격차를 식별한다.
- 제한된 pipeline orchestration 능력과 미리 정의된 operator에 대한 의존성
- cascading error를 진단하고 방지하기 위한 불충분한 higher-order, causal, meta-reasoning
- 변화하는 데이터 및 workload가 있는 동적 환경에 적응하기 어려움
- 정렬 및 채택을 위한 human-crafted reinforcement learning setup에 대한 높은 의존성
2.5. L4-L5: 비전 및 연구 로드맵 (L4–L5: Vision and Research Roadmap)
2.5.1. L4: Proactive, High-Autonomy Data Agent (L4: Proactive, High-Autonomy Data Agents)
L4 Data Agent는 Data+AI ecosystem의 proactive, long-lived, self-governing component로 구상된다. 명시적인 사용자 요청에 단순히 반응하는 대신, L4 agent는 데이터 lake, 시스템, 모델을 지속적으로 모니터링하고, 데이터 드리프트, 성능 저하, 스키마 변경과 같은 현상을 감지하며, 유익한 materialization, 누락된 index, 유망한 분석 워크플로우와 같은 기회를 식별한다. 이들은 이러한 task 중에서 우선순위를 정하고, 명시적인 지시 없이 이를 해결하기 위한 파이프라인을 설계하고 조정하며, 인간 감독이 없는 상황에서도 신뢰성, 안전성, 거버넌스 제약 조건 내에서 작동할 것으로 예상된다.
2.5.2. L5: Generative Data Agent (L5: Generative Data Agents)
L5 Data Agent는 기존 기술을 배포하는 것을 넘어선다. 기존 접근 방식이 불충분할 경우 새로운 알고리즘이나 representation을 가설화하고, 이러한 가설을 테스트하기 위한 실험을 설계하고 분석하며, 시간이 지남에 따라 자신의 solution을 반복적으로 개선한다. 이 비전에서 Data Agent는 데이터베이스 및 ML 시스템의 사용자일 뿐만 아니라 그 진화에 적극적으로 기여한다. L5로 나아가기 위해서는 물리적 설계, 쿼리 재작성 전략, 데이터 cleaning 정책, 학습 절차와 같은 높은 level의 design choice를 조작할 수 있는 추상화와, 실행 가능한 시스템에 기반을 두고, 원리적인 진단, 비교, 대체 설계의 개선을 지원하는 causal 및 meta reasoning이 필요하다.
2.5.3. 연구 기회 (Research Opportunities)
L0-L5 계층 구조는 핵심 데이터 관리 문제와 밀접하게 관련된 여러 연구 방향을 제시한다.
- 중앙 질문은 Data Agent가 방대하고 이질적인 데이터 lake를 어떻게 인지하고 행동해야 하는지이다. 어떤 index, materialized view, summary 또는 학습된 representation이 "감각" 역할을 해야 하는지, 이러한 구조가 tool로 어떻게 노출되는지, 그리고 agent가 성능, 데이터 품질, 거버넌스 보증을 보존하면서 관리, 준비, 분석에 걸쳐 복잡한 파이프라인을 어떻게 조정할 수 있는지에 대한 질문이 있다.
- 두 번째 주제는 Data Agent가 현실적인 환경에서 어떻게 훈련되고 평가되는지이다. 여기서 운영 로그, configuration history, telemetry는 훈련 corpora를 구축하고, 시간 경과에 따른 agent 정책을 조정하며, 오류 및 개선에 대한 causal 및 meta reasoning을 지원하는 기초가 될 수 있다. 이는 전통적인 task level 정확도를 넘어 자율성, 견고성, 적응성 및 안전성을 포착하는 벤치마크 및 방법론을 요구한다.
