Paper Review
1.DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
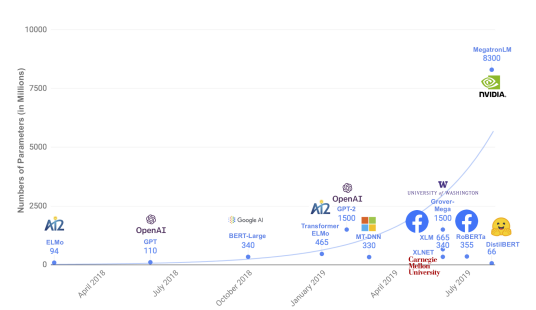
기존 문제점 BERT는 Pre-trained + finetuning 하여 사용 Pre-trained는 메모리 용량 및 프로세스 성능 등 많은 자원을 소요하는 문제 DistilBERT 개요 DistilBERT는 기존 BERT-base 보다 40% 가볍고, 60% 빠름
2.DoRA: Weight-Decomposed Low-Rank Adaptation
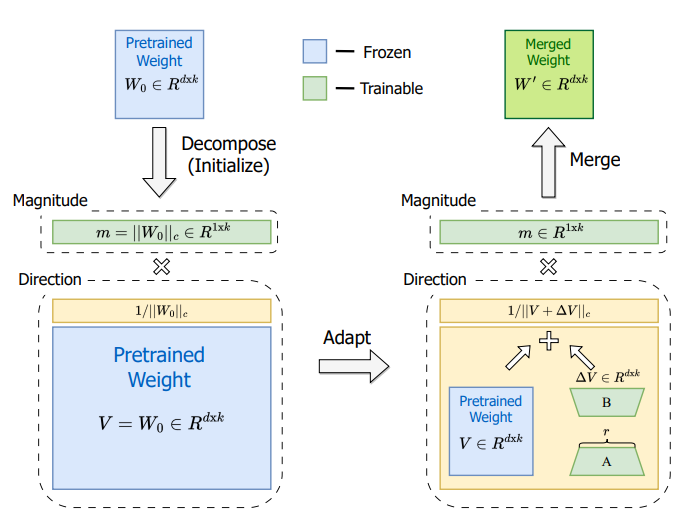
DoRA
3.SELF-INSTRUCT : Aligning Language Models with Self-Generated Instructions

Introduction 최근 언어 모델은 거대한 사이즈와 Instruction Data를 통한 학습으로 우수한 성능을 자랑한다 하지만,
4.On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
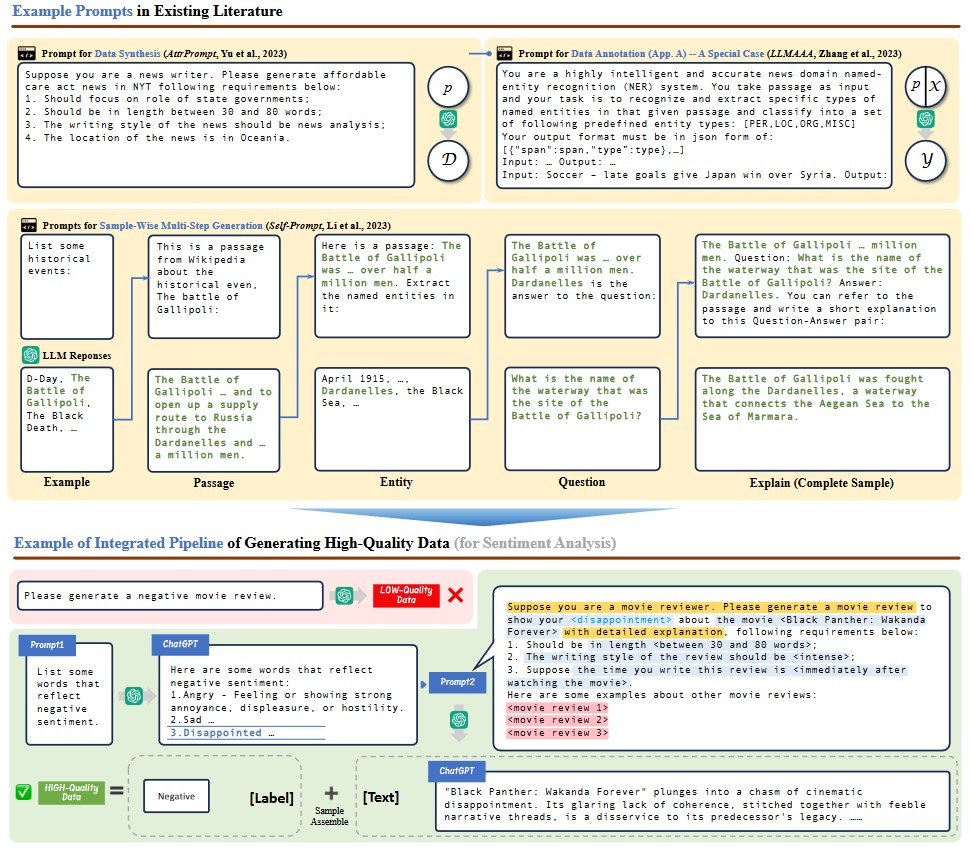
LLM 기반 합성 데이터 Survey
5.(PERHAPS) BEYOND HUMAN TRANSLATION: HARNESSING MULTI-AGENT COLLABORATION FOR TRANSLATING ULTRA-LONG LITERARY TEXTS(TRANS AGENT)

TRANSAGENTS
6.[논문리뷰] CTIBench: A Benchmark for Evaluating LLMs in Cyber Threat Intelligence
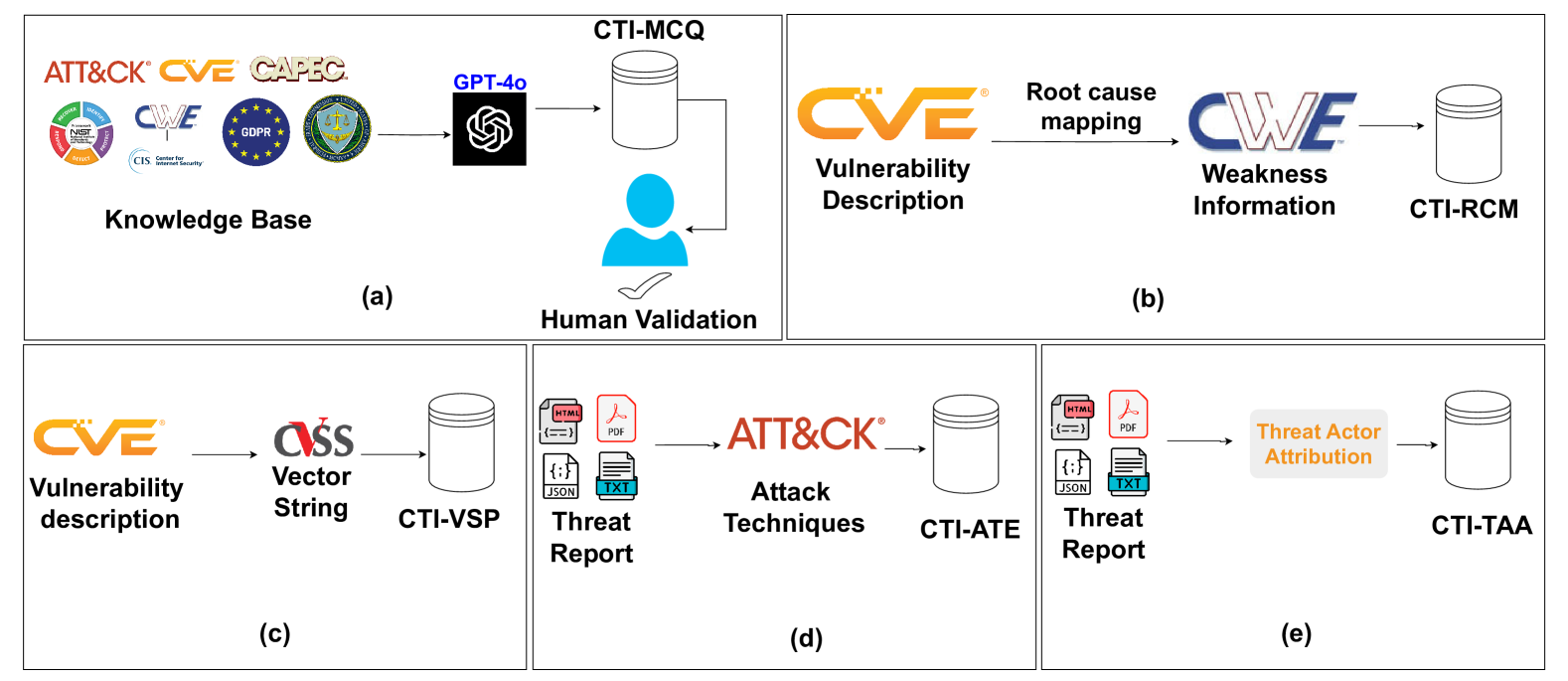
보안 환경에서 Cyber threat intelligence(CTI)는 위협을 이해하고 대응하기 위한 핵심 정보로서 중요한 역할을 함최근 LLM이 CTI 분야에서 잠재력을 보였으나, hallucination 문제에 대한 우려가 여전히 존재기존 벤치마크들은 LLM의 일반
7.[논문리뷰] REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS

인간은 task-oriented actions과 Verbal reasoning을 자연스럽게 결합할 수 있는 능력이 있다.
8. [논문리뷰] DEEP THINK WITH CONFIDENCE
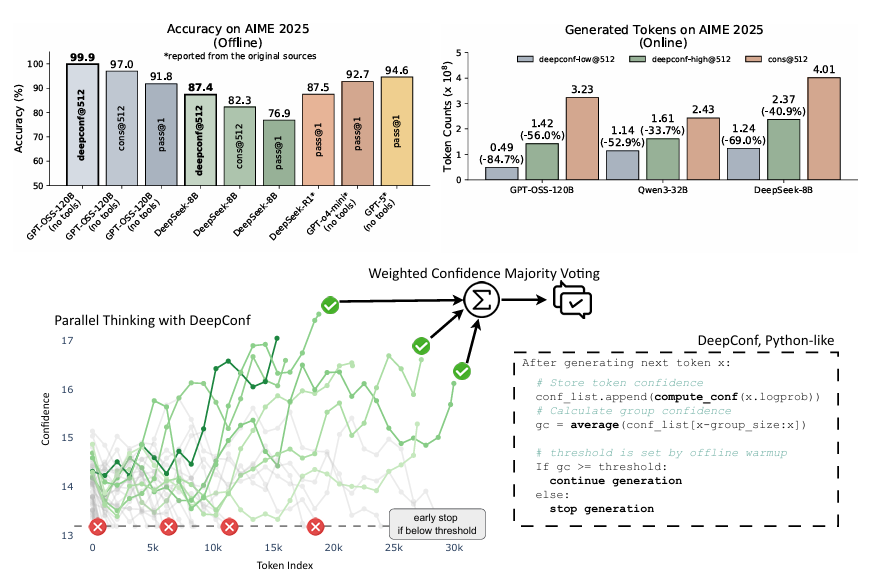
최근 LLM은 self-consistency를 통해 다양한 추론 trace를 샘플링한 뒤 다수결로 최종 답을 집계하여 추론 정확도를 높이는 방식을 보여주고 있다. 하지만 입력마다 많은 추론 trace를 생성하면 추론 오버헤드가 선형적으로 증가해 상당한 계산 비용을 초래
9.[논문리뷰] TIME-LLM: TIME SERIES FORECASTING BY REPROGRAMMING LARGE LANGUAGE MODELS
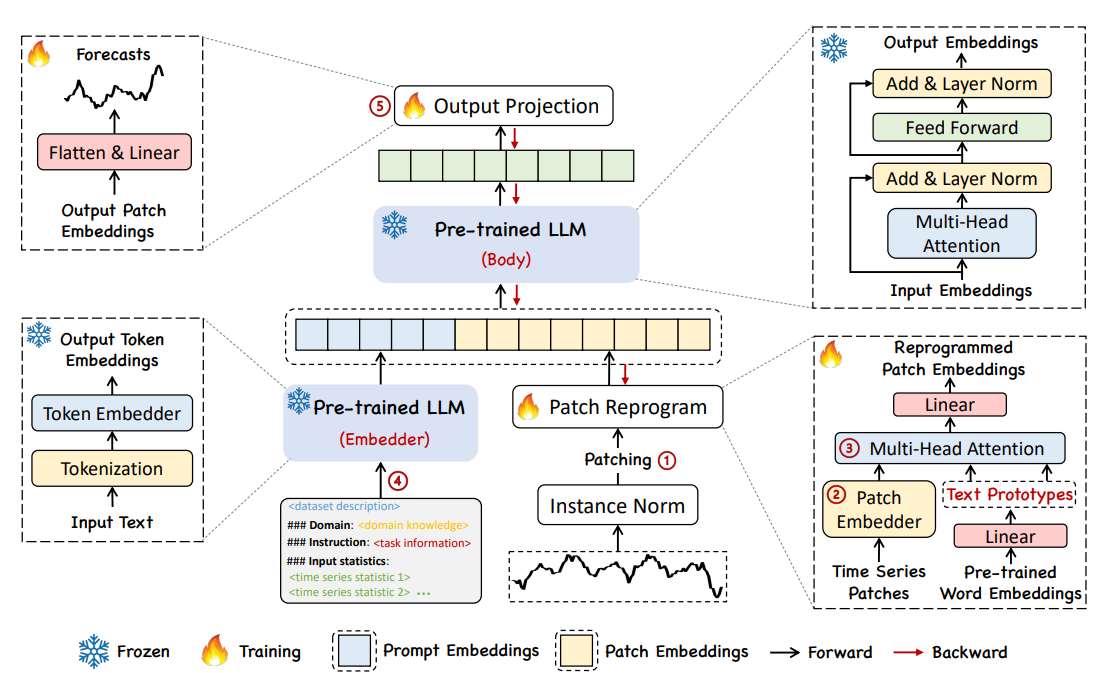
시계열 예측(time series forecasting)은 수요 예측, 재고 관리, 에너지 부하 예측, 기후 모델링 등 다양한 실제 시스템에서 핵심적인 역할을 한다. 그러나 기존 시계열 모델들은 특정 도메인 혹은 Task에 맞춰 개별적으로 설계되기 때문에 범용성이 부족
10.[논문리뷰] Efficient Code Embeddings from Code Generation Models
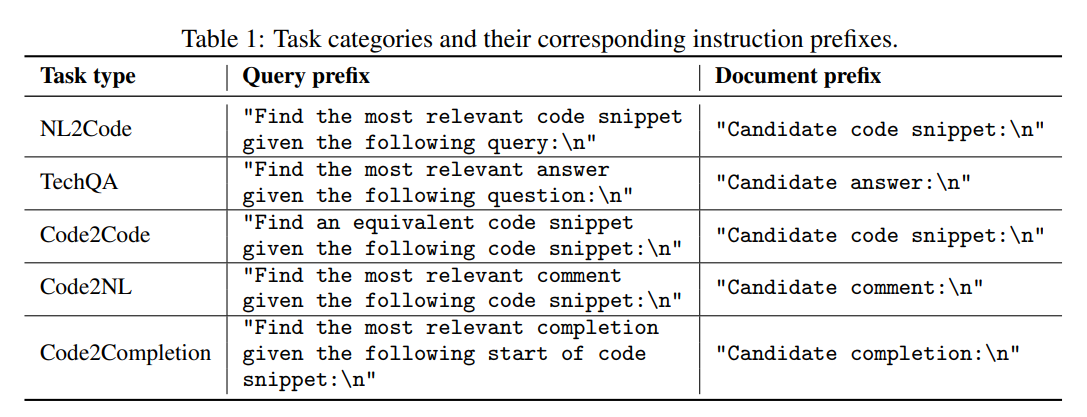
jina-code-embeddings는 자연어 질의로부터 코드를 검색하고, technical QA를 수행하며, 프로그래밍 언어 전반에서 의미적으로 유사한 코드 스니펫을 식별하기 위해 설계된 새로운 코드 임베딩 모델이다.
11.[논문리뷰] LLM-JEPA: Large Language Models Meet Joint Embedding Predictive Architectures

12.[논문리뷰] Generative Data Refinement: Just Ask for Better Data
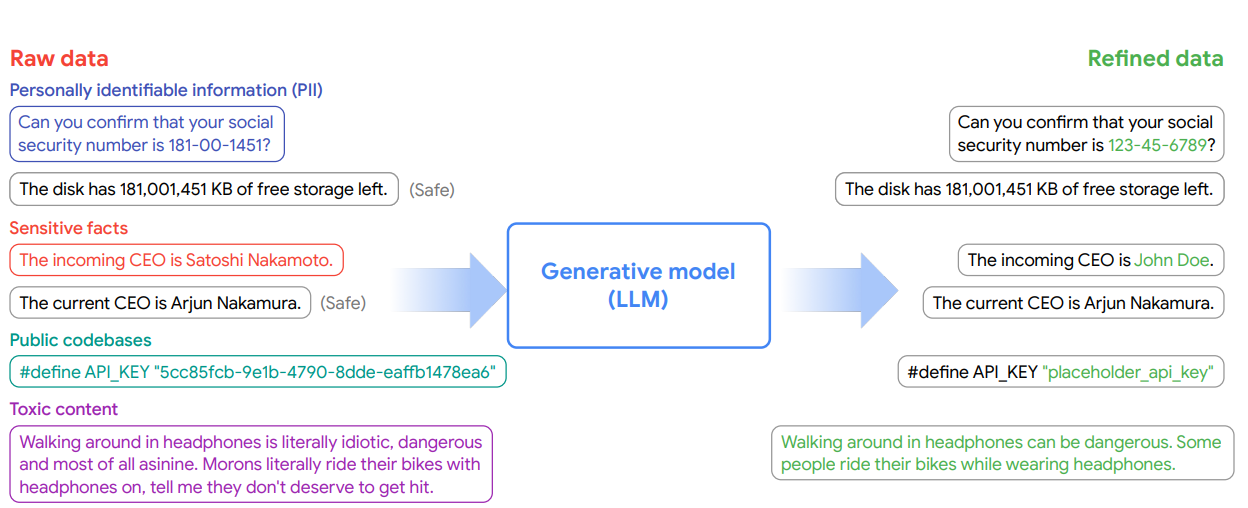
Introduction LLM의 성능은 사이즈뿐 아니라 학습 데이터의 양과 질에 결정적으로 좌우된다. 그러나 최근 분석에 따르면, 웹 인덱싱 데이터 증가 속도보다 LLM 학습 데이터셋 확장이 빠르게 진행되고 있어, 향후 10년 내 data exhaustion 이 예상된다. 이 문제를 해결하기 위한 기존 접근은 두 가지다: 웹 비공개 데이터 활용 – ...
13.[논문리뷰] Understanding and Mitigating Language Confusion in LLMs
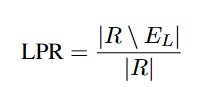
Introduction 초기 LLM은 영어에 중점을 두었지만, 최근 모델들은 다국어 기능을 강화하고 있다. 하지만 비영어권 사용자들은 여전히 높은 지연 시간, 비용 증가, 성능 저하 등으로 인해 불편을 겪을 때가 있다. LLM은 사용자의 의도를 이해하고 문법, 스타
14.[논문리뷰] Retrieval-Augmented Generation for AI-Generated Content: A Survey (1)

최근 몇 년 사이 인공지능 생성 콘텐츠(AIGC, AI-Generated Content)가 폭발적으로 발전했다. LLM, Stable Diffusion이나 DALL·E 같은 이미지 생성 모델, 그리고 비디오 생성 모델까지 다양한 양식의 생성 모델이 등장하면서 AI가 만
15.[논문 리뷰] Large Language Models for Information Retrieval: A Survey (1)
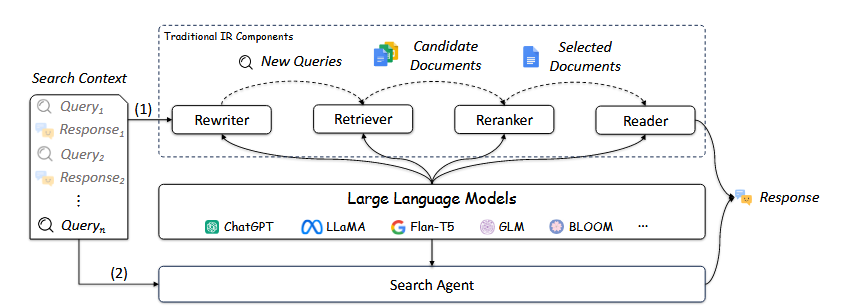
정보 접근은 인간의 기본적인 일상적 요구로 원하는 정보를 신속하게 획득하고자 하는 요구를 충족시키기 위해 다양한 정보검색(IR) 시스템이 개발되었다.
16.[논문리뷰] ORAK: A FOUNDATIONAL BENCHMARK FOR TRAINING AND EVALUATING LLM AGENTS ON DIVERSE VIDEO GAMES
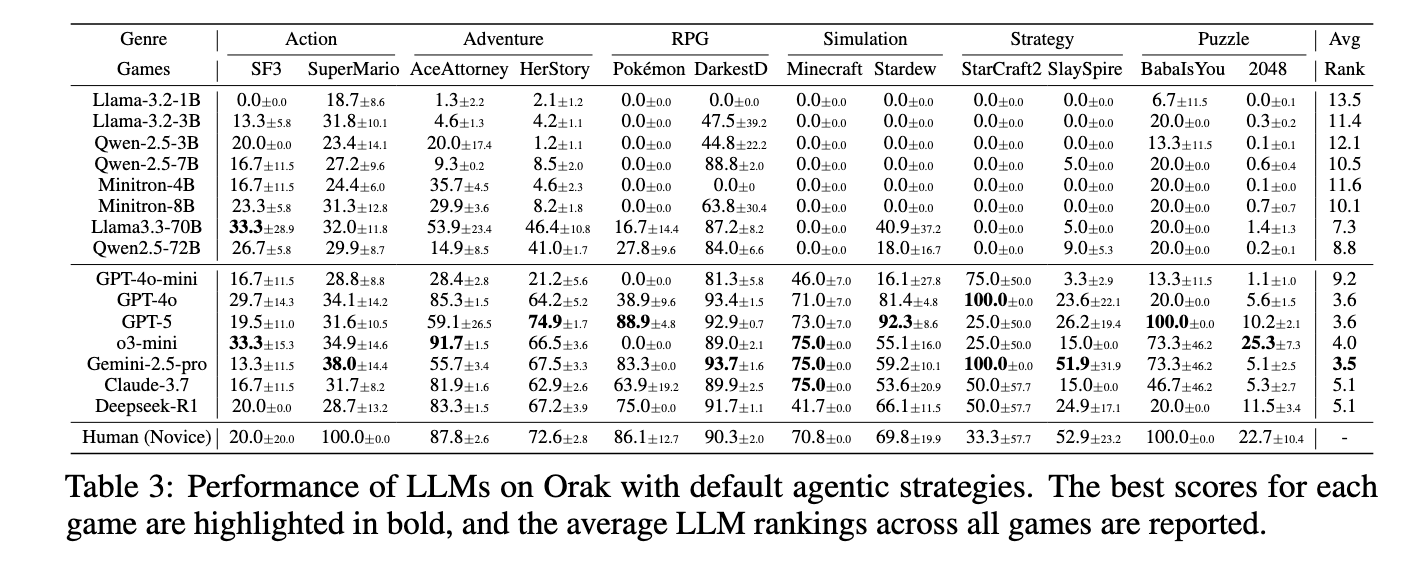
LLM play games 벤치마크 연구
17.LATE CHUNKING: CONTEXTUAL CHUNK EMBEDDINGS USING LONG-CONTEXT EMBEDDING MODELS

summary 짧은 텍스트 세그먼트를 임베딩했을 때 의미가 과압축될 가능성은 낮기 때문에, dense vector based 검색 시스템에서는 짧은 텍스트 세그먼트가 더 나은 성능을 발휘하는 경우가 많다. 그럼에도, 청킹은 주변 청크의 맥락 정보를 잃어 최적이 아닌 표현이 될 수 있다. 본 연구에서는 long context 임베딩 모델을 통해 특정 문서...
18.LumberChunker: Long-Form Narrative Document Segmentation
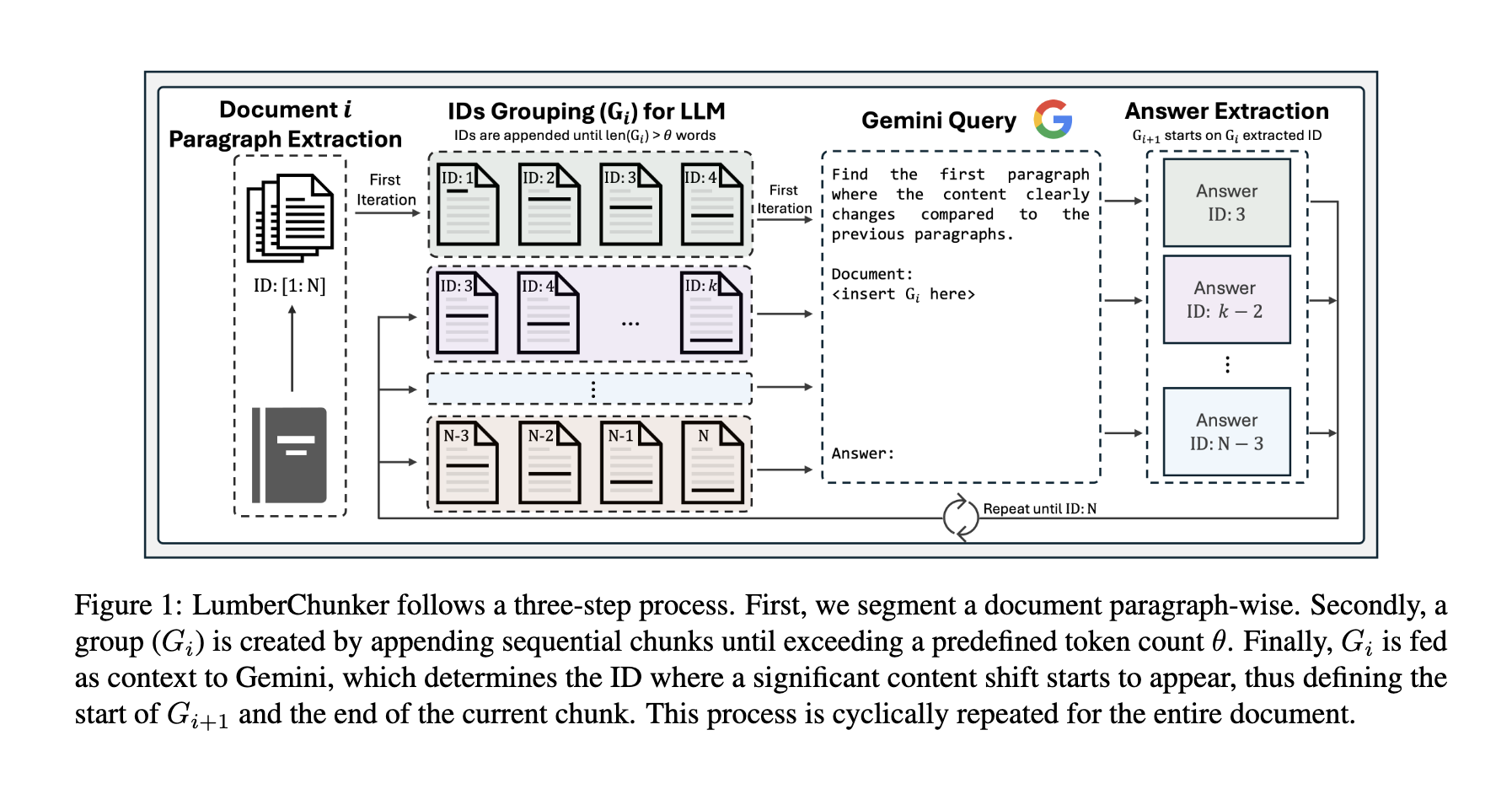
현대 NLP 태스크는 관련된 문맥 정보를 검색하기위해 dense retrieval 방법에 의존하고 있다.
19.AutoChunker: Structured Text Chunking and its Evaluation

Introduction 본 논문은 RAG 시스템의 핵심 단계인 text chunking 문제를 다룬다. 기존 청킹 방식(문장 단위, 일정 길이 단위, 구조 기반 등)은 실제 서비스 문서의 복잡한 구조나 노이즈를 충분히 처리하지 못해, 의미 단위가 잘게 분리되거나 불필요한 내용이 포함되는 한계를 가진다. 이러한 문제는 검색 품질 저하, 불완전한 컨텍스트 제...
20.MoC: Mixtures of Text Chunking Learners for Retrieval-Augmented Generation System
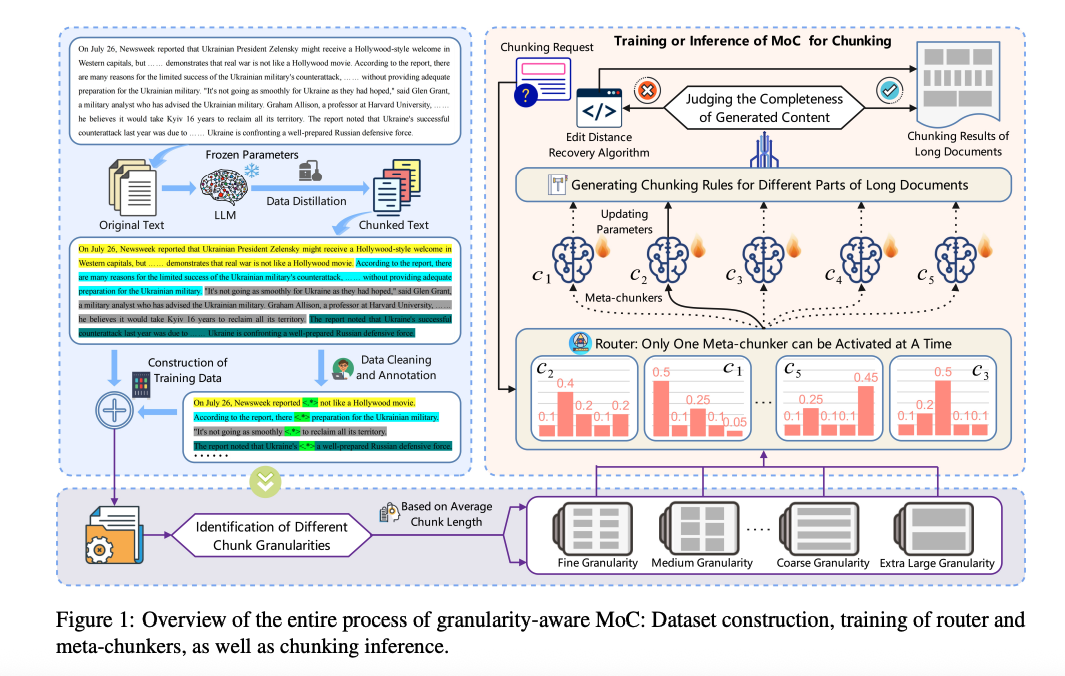
Introduction RAG(Retrieval-Augmented Generation) 시스템에서 텍스트 청킹은 가장 기본적인 전처리 단계임에도 불구하고, 실제로는 큰 주목을 받지 못해왔다. 대부분의 시스템은 고정 길이 기반 혹은 임베딩 유사도 기반 청킹을 사용하며,
21.How Good are LLM-based Rerankers? An Empirical Analysis of State-of-the-Art Reranking Models
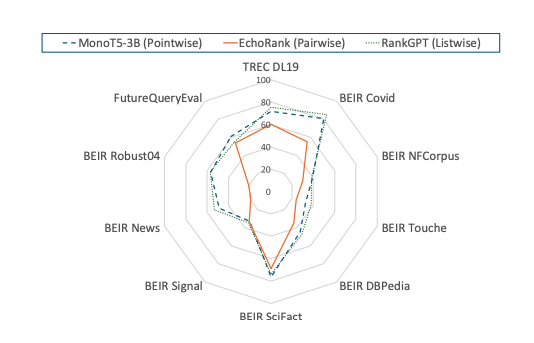
Abstract 본 연구는 IR 태스크에서 사용되는 reranking 기법들을 대상으로, 대규모 언어 모델(LLM) 기반 방법, 경량(contextual) 모델, 그리고 zero-shot 접근법을 포함한 체계적이고 포괄적인 실험적 비교를 수행한다. 총 22개의 reranking 방법과, 사용된 LLM에 따라 파생된 40개의 변형을 평가 대상으로 삼았으며,...
22.MMDOCIR: Benchmarking Multimodal Retrieval for Long Documents

Abstract 멀티모달 문서 검색은 다양한 형태의 멀티모달 컨텐츠를 식별하고 검색하는 것이 목표이다. 이 태스크의 수요가 높아지고 있음에도, 성능을 효과적으로 평가할 수 있는 포괄적이고 견고한 벤치마크가 부족하다. 이 격차를 해소하기 위해, 해당 연구는 페이지 수준과 레이아웃 수준 검색의 고유한 태스크를 포함한 MMDocIR이라는 새로운 벤치마크를 소개...
23.DocVQA: A Dataset for VQA on Document Images
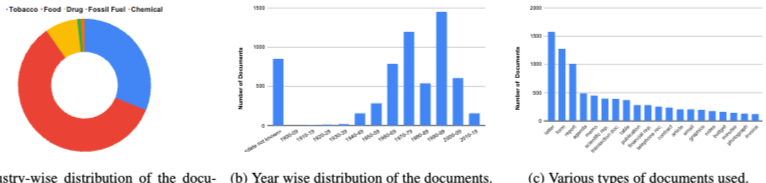
문서 이미지에 대한 시각 질의 응답(VQA)을 위한 새로운 데이터셋인 DocVQA를 제안한다.
24.LAD-RAG: Layout-aware Dynamic RAG for Visually-Rich Document Understanding
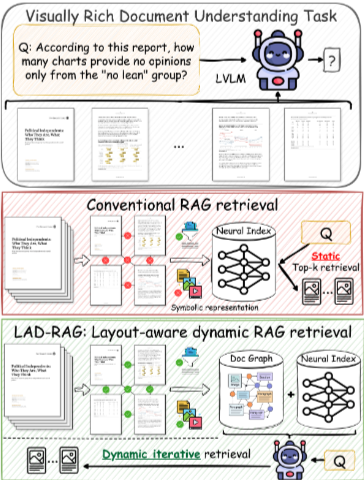
Absctract 시각적으로 풍부한 문서(VRD)에 대한 질의응답은 고립된 내용뿐만 아니라 문서의 구조적 조직과 페이지 간 의존성에 대한 추론도 필요하다. 그러나 기존의 검색 증강 생성(RAG) 방식은 문서 수집 단계에서 내용을 고립된 청크로 인코딩하여 구조적 및 페이지 간 의존성을 손실한다. 또한, 질의나 문맥의 특정 요구 사항과 관계없이 추론 시 고정...
25.VisDoM: Multi-Document QA with Visually Rich Elements Using Multimodal Retrieval-Augmented Generation
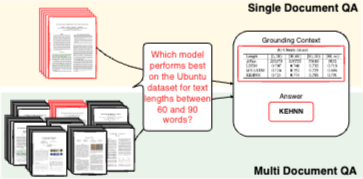
Introduction 정보가 풍부한 환경에서 PDF 문서는 재무, 법률, 과학 연구 등 다양한 분야에서 정보를 저장하고 전파하는 데 중요한 역할을 한다. 이러한 문서는 종종 텍스트, 시각 자료 및 표 형식 데이터가 풍부하게 혼합되어 있어 정보 검색 시스템에 고유한 과제를 제기한다. 데이터베이스와 같은 구조화된 형식과 달리 PDF는 본질적으로 비구조화되...
26.Benchmarking Retrieval-Augmented Multimodal Generation for Document Question Answering

MMDocRAG
27.Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps

서론 기존 기계 독해(MRC) 모델은 SQuAD 벤치마크에서 인간 수준을 뛰어넘는 성능을 보였지만, 자연어에 대한 완전한 이해를 의미하지는 않는다. 특히 적대적 방법론을 사용하면 현재 모델들이 자연어를 정확하게 이해하지 못함을 알 수 있다. 또한, 기존 멀티-홉(multi-hop) 데이터셋의 많은 예시들이 실제로 멀티-홉 추론을 요구하지 않는다는 문제점이...
28.MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries
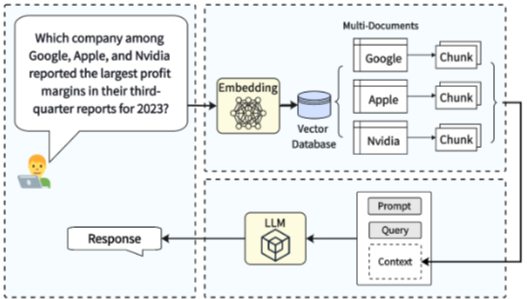
서론 LLM은 외부 지식을 검색해 활용하는 RAG (Retrieval-Augmented Generation) 시스템을 통해 hallucination을 완화하고 응답 품질을 향상시킨다. 그러나 기존 RAG 시스템은 여러 개의 evidence를 검색하고 종합적으로 추론해야 하는 multi-hop queries에 적합하지 않으며, 이러한 multi-hop 쿼...
29.HopRAG: Multi-Hop Reasoning for Logic-Aware Retrieval-Augmented Generation
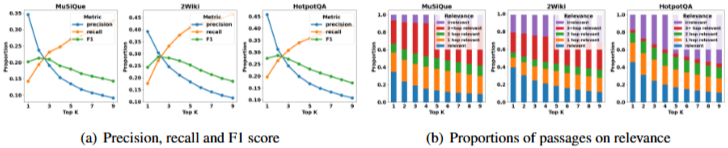
서론 기존 Retrieval-Augmented Generation 시스템은 어휘적 또는 의미적 유사성에 주로 의존하여 논리적 관련성을 놓치는 경우가 많다. 이로 인해 검색 결과가 불완전해지고(예: 간접적으로만 관련된 구절을 검색하거나 필요한 구절을 놓침) LLM의 응답이 부정확하거나 불완전해질 수 있다. 특히 multi-hop 또는 다중 문서 QA 작...
30.ReAgent: Reversible Multi-Agent Reasoning for Knowledge-Enhanced Multi-Hop QA
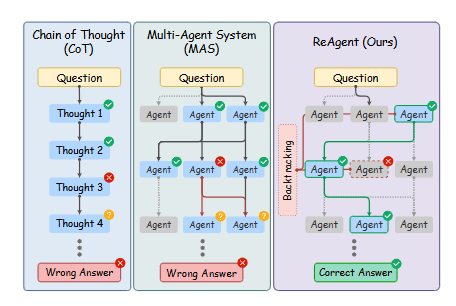
Multi-hop QA의 어려운 점은 오류 전파로, 초기 실수가 최종 결과에 영향을 미치는 점이다.
31.KOBLEX: Open Legal Question Answering with Multi-hop Reasoning

서론 LLM은 일반 도메인에서 뛰어난 성능을 보이며 현재 법률과 같은 전문 도메인으로 확장되고 있다. 기존 법률 벤치마크는 LLM의 법률 능력을 평가하기 위해 제안되었으나, open-ended 및 provision-grounded QA을 평가하는 데에는 한계가 있었다. 특히 복잡한 법률 질문은 실제 법률 조문에 근거한 답변을 요구하지만, 기존 벤치마크는...
32.DEO: Training-Free Direct Embedding Optimization for Negation-Aware Retrieval
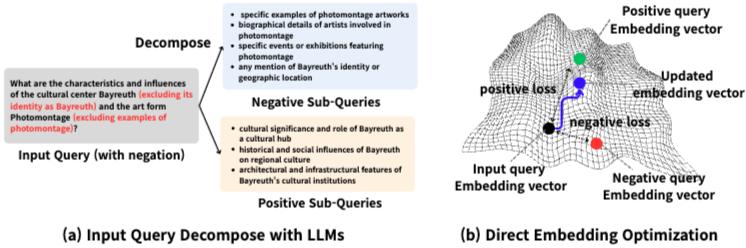
DEO는 훈련 과정 없이(training-free) 부정(negation) 및 제외(exclusion) 질의에 대한 검색 성능을 향상시키는 방법론이다.
33.Language models can learn implicit multi-hop reasoning, but only if they have lots of training data
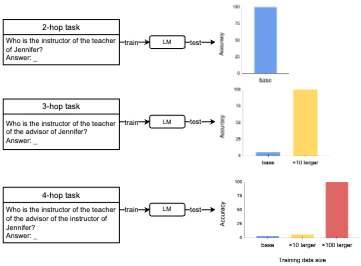
언어 모델이 implicit multi-hop reasoning을 학습하는 능력과 그에 필요한 자원을 조사한다.
34.Back Attention: Understanding and Enhancing Multi-Hop Reasoning in Large Language Models
Abstract 이 논문은 LLM이 “Mozart의 어머니의 배우자” 같은 질의를 처리할 때, 겉으로는 중간 추론 과정을 생성하지 않아도 내부적으로 여러 단계를 거쳐 답을 낸다는 점에 주목한다. 저자들은 이런 잠재적 멀티홉 추론(latent multi-hop reasoning) 이 실제로 어떤 방식으로 이뤄지는지 분석하기 위해 logit flow라는 해...
35.Adam’s Law: Textual Frequency Law on Large Language Models
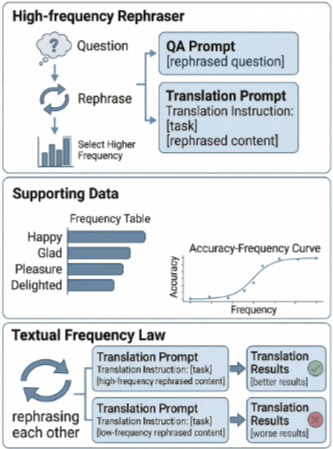
LLM에 텍스트 빈도(Textual Frequency) 개념을 도입하는 Adam's Law 프레임워크를 제안한다.
36.Data Agents: Levels, State of the Art, and Open Problems
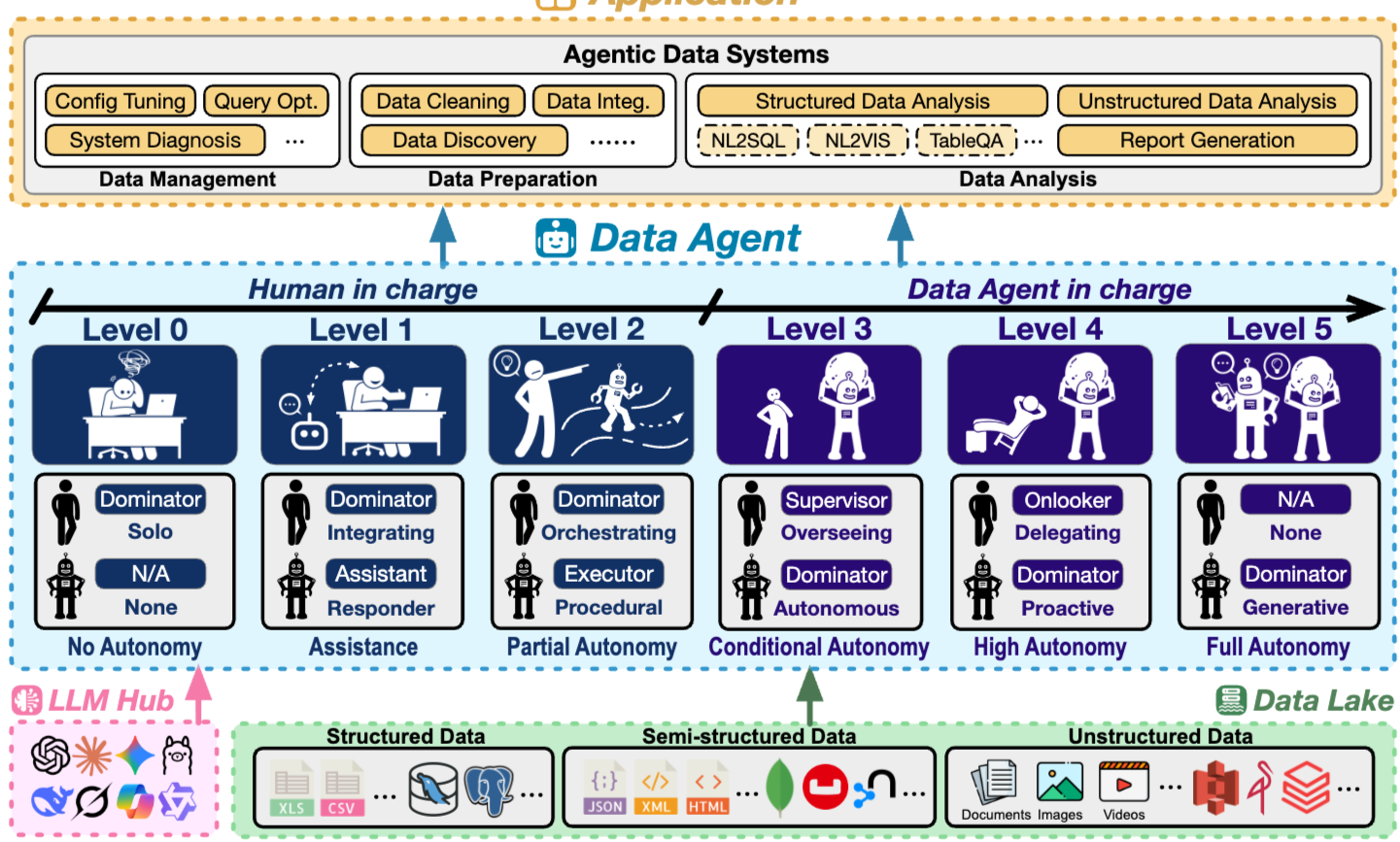
초록 (Abstract) 이 논문은 LLM과 tool-using agent를 활용하여 데이터 관리, 준비 및 분석 작업을 자동화하는 새로운 패러다임인 Data Agent를 제시한다. 현재 "Data Agent"라는 용어는 단순한 질의 응답 assistant부터 완전 자율적인 "데이터 과학자"에 이르기까지 일관성 없이 사용되어 능력과 책임의 경계를 모호...
37.A Survey on Employing Large Language Models for Text-to-SQL Tasks
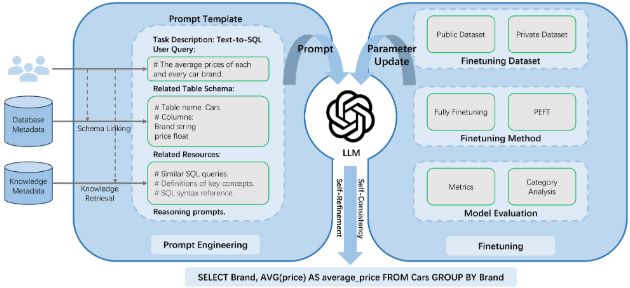
LLM 기반 Text-to-SQL 방법론의 현황을 체계적으로 검토하며, 고전적인 벤치마크 및 LLM 시대의 새로운 벤치마크, 평가 메트릭을 제시한다. 주요 방법론인 prompt engineering과 fine-tuning에 대해 상세한 taxonomy를 구축하고, 각 하위 범주에 대한 실용적인 통찰력을 제공한다. 또한, 다양한 모델과 데이터셋에 대한 분석을...
38.Table-Critic: A Multi-Agent Framework for Collaborative Criticism and Refinement in Table Reasoning
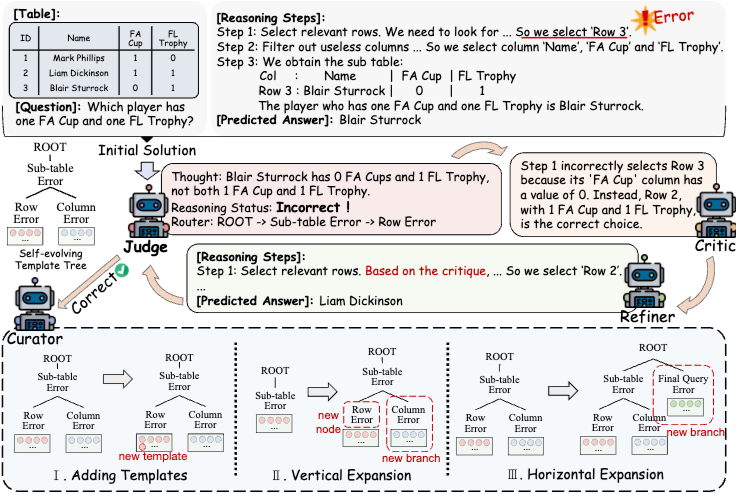
서론 LLM은 다양한 추론 작업에서 뛰어난 능력을 보이지만, 테이블 추론 작업, 특히 다단계 추론 과정 전반에 걸쳐 일관성을 유지하는 데 어려움을 겪는다. 기존의 분해 전략들은 중간 추론 단계의 오류를 식별하고 수정하는 효과적인 메커니즘이 부족하여 cascading error propagation을 유발한다. 이 문제를 해결하기 위해, Table-Cr...
39.MultiDocFusion: Hierarchical and Multimodal Chunking Pipeline for Enhanced RAG on Long Industrial Documents
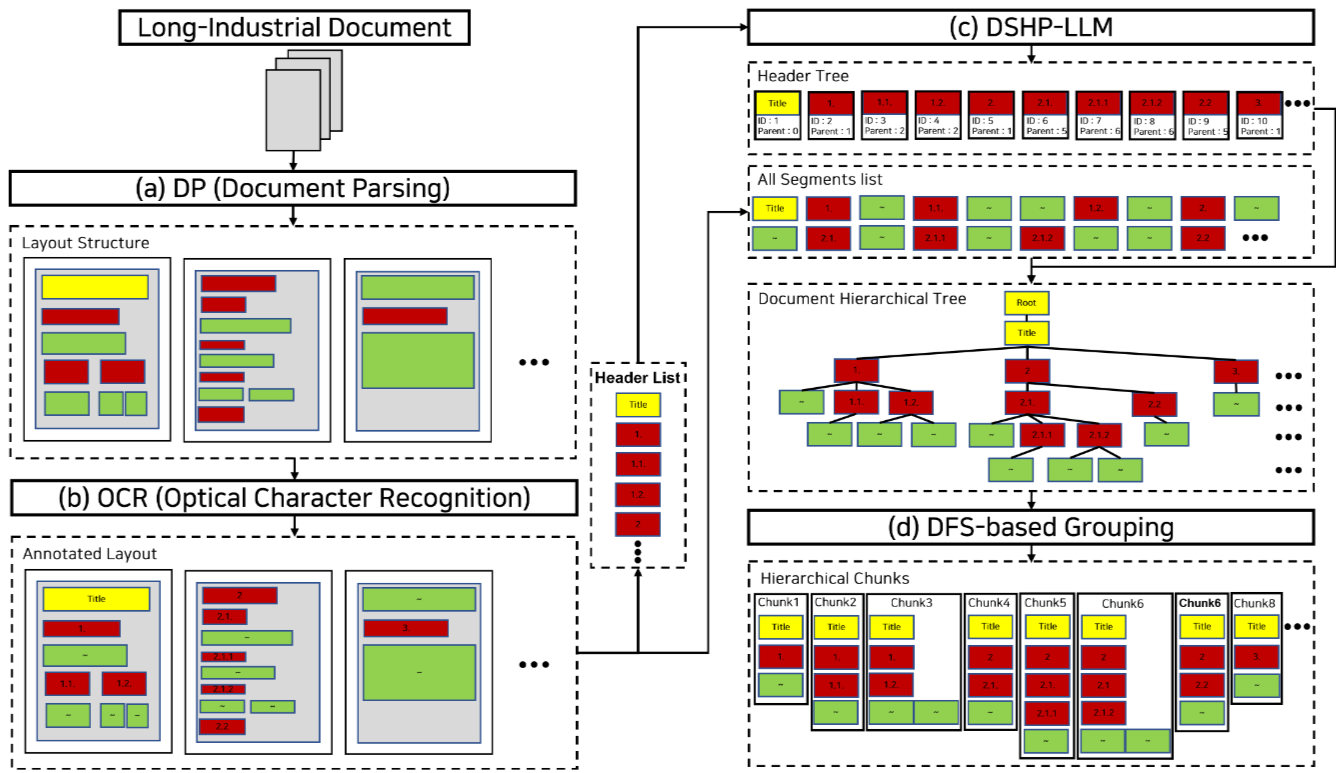
긴 인더스트리 문서에 대한 RAG 시스템의 성능을 향상시키기 위한 MultiDocFusion이라는 다중 모드 chunking 파이프라인을 제안한다. 기존의 텍스트 중심 청킹 방식은 복잡한 인더스트리 문서의 구조(시각적 레이아웃, 계층적 섹션)를 무시하여 정보 손실과 답변 품질 저하를 야기하는 문제를 해결하고자 한다. MultiDocFusion은 시각적 레이...
40.OG-RAG: Ontology-grounded retrieval-augmeÎnted generation for large language models
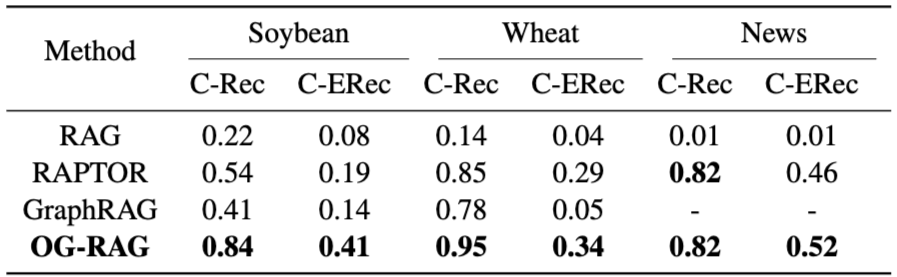
OG-RAG는 LLM이 헬스케어, 법률, 농업 등 전문 지식 영역에서 일반적인 RAG 방식으로는 한계가 있다는 문제의식에서 출발한 Ontology-Grounded Retrieval Augmented Generation 방법론을 제안하는 논문이다. 기존 RAG 모델은 구조화된 도메인 지식을 활용하지 못해 Suboptimal한 Context 생성으로 이어지...
41.LIGHTRAG: SIMPLE AND FAST RETRIEVAL-AUGMENTED GENERATION

기존 RAG 시스템은 flat data representation에 의존하고 contextual awareness가 부족하여 복잡한 정보 간의 상호 의존성을 파악하지 못하고 fragmented answers를 생성하는 문제가 있었다. 이러한 문제를 해결하기 위해 LightRAG는 text indexing과 retrieval 프로세스에 graph 구조를 통합...
42.From Local to Global: A GraphRAG Approach to Query-Focused Summarization
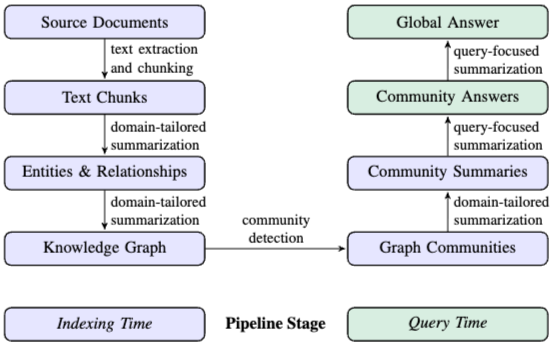
1. 서론 현재의 RAG 시스템은 대규모 데이터셋에서 특정 정보를 검색하는 데 최적화된 Vector RAG 방식에 의존한다. 그러나 "데이터셋의 주요 테마는 무엇인가?"와 같은 전체 말뭉치에 대한 Global sensemaking 질문에는 대응하지 못하는 한계가 있다. 기존의 QFS 방식은 RAG 시스템이 다루는 방대한 텍스트 규모를 처리하기 어렵다. 이...
43.From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
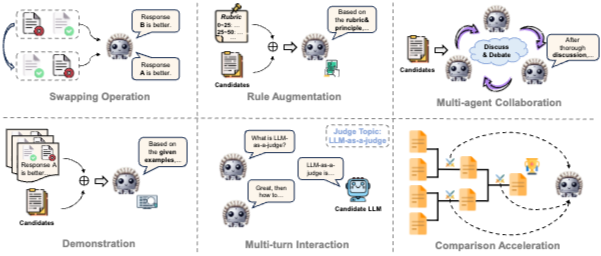
최근 LLM 연구에서 중요한 변화 중 하나는 LLM을 단순히 답변을 생성하는 모델로만 보지 않는다는 점이다. 이제 LLM은 다른 모델의 답변을 평가하고, 여러 후보 중 더 나은 결과를 고르고, 때로는 학습 데이터나 reasoning path까지 선별하는 “judge” 역할을 맡고 있다. 이 흐름을 정리한 논문이 From Generation to Judg...