
Intro
보안 환경에서 Cyber threat intelligence(CTI)는 위협을 이해하고 대응하기 위한 핵심 정보로서 중요한 역할을 함
최근 LLM이 CTI 분야에서 잠재력을 보였으나, hallucination 문제에 대한 우려가 여전히 존재
기존 벤치마크들은 LLM의 일반적 성능을 평가하지만, CTI 특화 과제의 실용적·응용 측면을 다루는 벤치마크는 존재 X
해당 연구에서는 CTI 환경에서 LLM의 성능을 평가하기 위해 CTIBench를 제안
Method
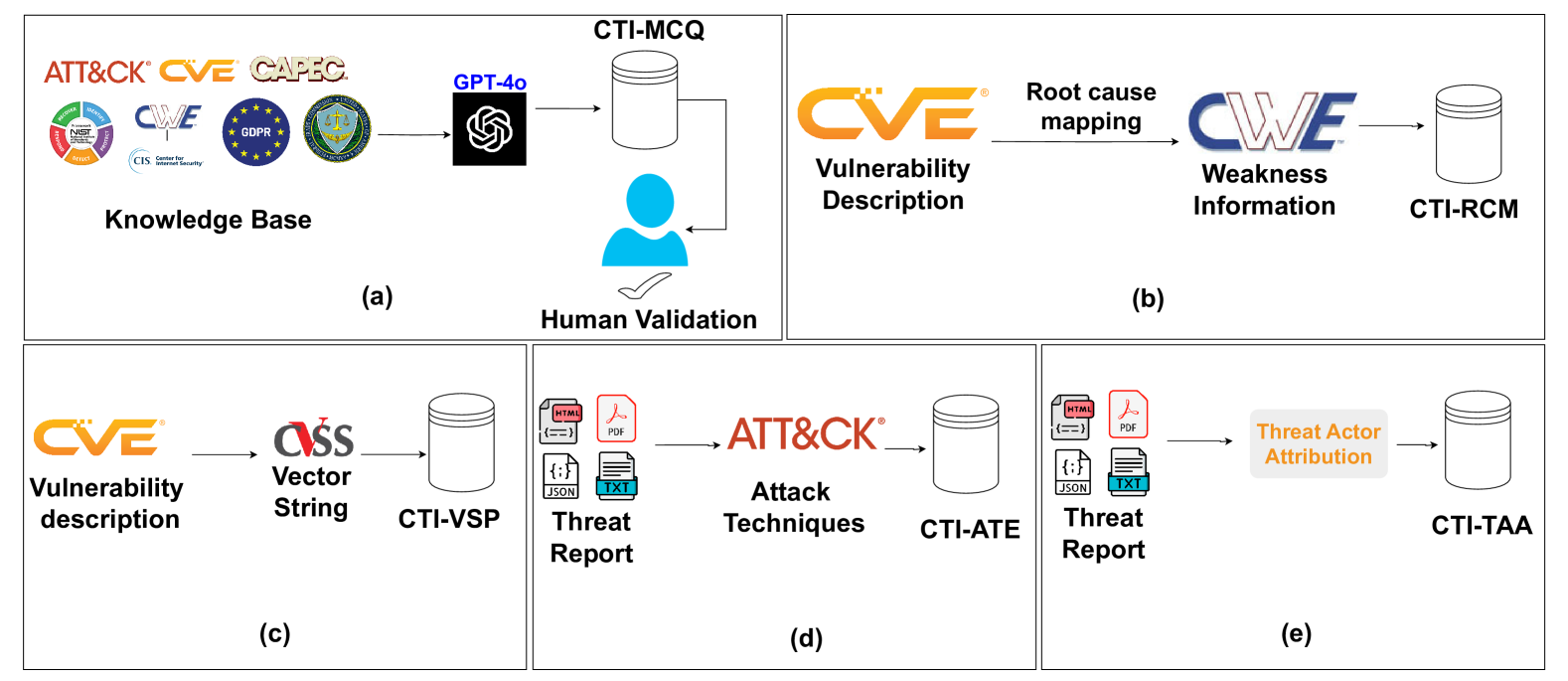
CTIBench는 CTI 특화 LLM 평가 벤치마크로 LLM의 기억력, 이해력, 문제 해결 능력, 추론 능력을 측정하는 다섯 가지 과제로 구성
CTI-MCQ(중요) : NIST, MITRE, CWE, CAPEC 등 권위 있는 자료를 기반으로 객관식 문제를 생성·검증하여 핵심 CTI 지식 평가 (Include standards, threat identification, detection strategies, mitigation techniques, and best practices)
- NIST, GDPR과 같은 규정 포함
- STIX, TAXII와 같은 CTI 공유 표준을 반영해 사이버 보안 기본 지식 문제 구성
- MITRE ATT&CK 프레임워크, CWE 데이터 베이스, VAPEC을 활용해 공격 패턴, 위협 행위, APT 캠페인, 탐지 방법, 완화 전략, 일반 소프트웨어 취약점, 공격 패턴 분류에 관한 문제 개발
- 또한 직접 수집 및 선별하여 데이터를 보강
CTI-RCM: CVE 설명과 CWE 분류를 정확히 매핑하는 루트 원인 분석 과제.
- NVD에서 데이터를 수집
- NVD: CVE로 식별된 과거 취약점의 설명과, 이에 매핑된 CWE 항목을 제공
CTI-VSP: 취약점 설명을 기반으로 CVSS v3 점수 벡터를 예측하는 심각도 예측 과제.
- 기본(Base), 시간적(Temporal), 환경(Environmental) 세 가지 메트릭 그룹으로 구성
- CTI-RCM과 동일한 데이터 소스를 사용
CTI-ATE: 위협 행위 설명에서 MITRE ATT&CK 기법 ID를 추출·매핑하는 공격 기법 식별 과제.
- ID는 공격 수명 주기의 여러 단계에서 사용되는 상대방(공격자)의 고유한 기법을 나타냄

CTI-TAA: 위협 보고서를 분석해 알려진 위협 행위자에게 귀속하는 고난도 추론 과제.
- 사이버 공격 활동을 한 개인, 그룹, 조직을 찾아내는 과제
- 매우 고난이도
각 과제는 NVD, MITRE ATT&CK, APT 보고서 등 신뢰성 있는 출처에서 데이터를 수집하고, 일부는 LLM 생성 질문과 수작업 검증을 병행해 품질을 확보
CTIBench는 CTI 도메인 전반에서 LLM의 실무 적용 가능성을 정량적으로 평가할 수 있는 구조를 제공
Experiment
평가 모델
-
ChatGPT-3.5 (gpt-3.5-turbo)
-
ChatGPT-4 (gpt-4-turbo)
-
Gemini-1.5
-
LLAMA3-70B
-
LLAMA3-8B
설정
-
Temperature = 0 (응답의 일관성 및 결정적 출력 확보)
-
top_p = 1
-
모든 과제는 zero-shot 프롬프트를 사용
-
LLM에게 사이버 위협 인텔리전스 전문가 역할을 지시
You are a cybersecurity expert specializing in cyber threat intelligence.
Analyze the following CVE description and map it to the appropriate CWE.
Provide a brief justification for your choice.
Ensure the last line of your response contains only the CWE ID.
CVE Description:
{description}
평가 지표
CTI-MCQ / CTI-RCM
- 다중 클래스 분류이므로 Accuracy 사용
CTI-VSP
- 예측한 CVSS v3.1 벡터 문자열에서 점수를 계산한 뒤, 실제 점수와의 평균 절대 편차(MAD) 계산
- Python 라이브러리:
cvss사용 - 점수 범위: 0 ~ 10
- LLM이 직접 점수를 계산하는 오류를 방지하기 위해 자동 계산
- 순수히 추론 능력만 평가
CTI-ATE
- 멀티라벨 분류 성능을 평가하기 위해 Micro-F1 Score 사용
- 정확도(Precision)와 재현율(Recall)을 동시에 반영
CTI-TAA
-
예측을 세 가지로 분류:
- 정답 (Correct): 위협 행위자나 그 별칭을 정확히 식별
- 그럴듯한 답 (Plausible): 보고서가 세부 정보가 부족하지만, 같은 그룹 내 관련 위협 행위자를 제시
- 오답 (Incorrect): 잘못된 행위자 식별 (오판, 환각, 잘못된 상관관계)
-
두 가지 정확도 산출:
- Correct Accuracy = 정답 비율
- Plausible Accuracy = (정답 + 그럴듯한 답) 비율
예측 결과
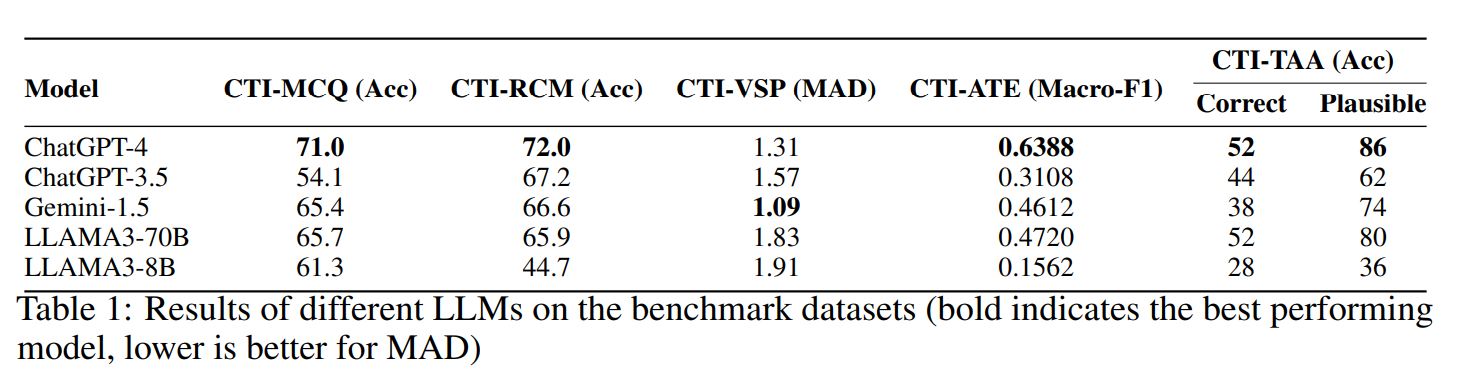
- GPT-4: 모든 과제에서 가장 높은 성능 (단, CTI-VSP는 예외)
- Gemini-1.5: CTI-VSP에서 최고 성능
- LLAMA3-70B: 오픈소스 모델이지만 Gemini-1.5와 비슷한 성능, 일부 3개 과제에서는 더 우수
- 그러나 CTI-VSP에서는 성능 저하
- ChatGPT-3.5: LLAMA3-8B보다 성능이 좋지만, 대부분 다른 모델에 밀림
- LLAMA3-8B: 소형 모델이라 복잡한 추론 과제에서는 한계
- 하지만 CTI-MCQ에서는 준수한 성능
Analysis(focusing MCQ)
CTI-MCQ
오류 상관관계 분석
- 모델 규모가 클수록 오류 상관관계가 높음
- ChatGPT-4, Gemini-1.5, LLAMA3-70B 같은 대형 모델은 CTI-MCQ 문제에서 비슷한 실수를 하는 경향이 있음
- 예시 상관계수:
- ChatGPT-4 & Gemini-1.5: 0.52
- ChatGPT-4 & LLAMA3-70B: 0.55
- Gemini-1.5 & LLAMA3-70B: 0.54
오답 빈도 분석
- 전체 모델(5개)이 공통으로 틀린 문제: 293문항
- 주요 오답 유형:
- 대응 계획(Mitigation plans) 관련
- 공격자 도구 및 기법(Tools & Techniques) 관련
출처별 정확도 비교
- MCQ 출처: MITRE ATT&CK vs CWE
- CWE: 정보 변동성이 적어 모델 성능이 더 높음
- MITRE ATT&CK: 정보 변동성이 커서 상대적으로 어려움
- 최고 성능 모델인 ChatGPT-4도 정확도 75.65%로 여전히 개선 여지 존재
추가 실험: 명시적 추론 프롬프트 사용
- MCQ 결과는 명시적 추론 단계 없이 측정
- 명시적 추론 프롬프트를 추가한 별도 평가도 수행
- 그러나 성능 향상이 일관되게 나타나지 않음
- 추측: MCQ 과제는 추론보다는 기억력에 더 의존하기 때문
Limitations
-
평가 범위 제한
- CTI 활동 범위가 매우 넓지만, 본 연구는 일부 과제만 평가
- 전체 CTI 기능을 포괄하지 못함
- 향후 계획: 평가 과제를 확대해 보다 포괄적인 LLM 성능 분석
-
언어 제한
- 평가가 영어 기반 CTI 기법에만 국한
- 글로벌 사이버 위협은 다국어, 다지역 특성을 가짐
- 향후 계획: 다국어 CTI 평가 포함해 국제적 활용성 개선
-
악용 가능성
- LLM이 CTI 지식을 악의적으로 활용할 위험 존재
- 예: 허위 위협 인텔리전스 보고서 생성 → 의사결정 혼란, 자원 오배분, 잘못된 대응 유발
- 향후 연구 필요: LLM 악용 가능성에 대한 벤치마킹
Conclusion
- LLM의 등장은 사이버 위협 인텔리전스(CTI) 분야에서 새로운 가능성 제시
- 그러나 CTI 분야에서의 능력과 한계는 여전히 명확히 규명되지 않음
- 본 연구는 CTIBench라는 벤치마크를 제안해 다양한 CTI 과제에서 LLM 성능 평가
- 평가 결과:
- LLM의 지식과 역량에 대한 인사이트 제공
- 한계점도 명확히 확인
- 목표:
- 연구자들이 LLM의 CTI 실무 적용 가능성을 이해하도록 지원
- LLM의 신뢰성 있는 활용 및 사이버 위협 탐지·대응 능력 향상에 기여
