
Introduction

인간은 task-oriented actions과 Verbal reasoning을 자연스럽게 결합할 수 있는 능력이 있다. 이 능력은 자기 조절, 전략 수립 그리고 작업 기억 유지에 있어 중요한 역할을 한다고 한다.
또한, 인간은 행동으로 추론을 뒷받침하거나 질문에 대답하기도 한다. 이처럼 인간이 새로운 태스크에 빠르게 적응하고, 예측 불가능한 상황에서 robust한 의사 결정을 낼 수 있도록 하기 위해 acting과 resoning의 시너지는 중요한 역할을 한다.
LLM은 arithmetic, commonsense, 그리고 symbolic reasoning tasks에서 COT를 통해 정답을 도출하는 능력을 보여주었으나, 이는 블랙박스이며 internal representations을 바탕으로 추론을 수행하기 때문에 지식을 확장할 수 없어 할루시가 발생할 수 있다.
추론과 행동을 시너지 있게 결합하는 방법에 대한 연구가 아직 이루어지지 않은 상황에서, reasoning과 Acting을 결합해 diverse language reasoning을 해결하는 ReAct 방법론을 제안하게 된다. ReAct는 LLM이 dynamic reasoning to create, maintain,and adjust high-level plans for acting 하도록 verbal reasoning traces와 actions을 하게 한다. 또한, 외부 환경과 상호작용하여 reasoning에 필요한 추가 정보를 획득할 수 있도록 한다.
REACT: SYNERGIZING REASONING + ACTING
에이전트의 action space를 space of language로 확장하는 것을 핵심 아이디어라고 제안한다.
space of language 에서 발생한 행동 즉, thought or reasoning trace는 환경의 변화가 없다. 대신 현재 문맥에 대해 추론을 수행하고, 유용한 정보를 정리하고 문맥을 갱신하는 데 목적이 있다. 예를 들면, task의 목표를 분해하거나, 계획을 수립하거나, task에 필요한 commonsense 지식을 주입하거나 주요한 부분을 관찰하여 추출하거나, 진행 상황을 추적하고 행동으로 전환하거나, 예외를 처리하는 등 다양한 타입의 thoughts가 존재한다.
하지만, space of language는 무한하기 때문에, 강력한 language priors가 요구 된다. 그래서 본 연구는 frozen한 PaLM-540B에 few shot을 통하여 task solving을 위한 action과 thoghts를 생성하는 데 초점을 맞춘다. 이는 인간이 특정 문제를 해결한 action-thoght -observations의 trajectory로 구성된다.
reasoning이 중요한 task는 thoghts와 actions을 번갈아가며 진행하도록 하고, decision making task에서는 action이 많기 때문에 LLM이 필요하다고 판단할 때만 비동기적으로 thoghts를 생성하도록 진행한다.
ReAct는 LLM에 resoning과 및 decision making 케파를 통합함으로써 유니크한 특징이 있다.
A) 직관적이고 쉬운 설계: 인간 주석자가 자신의 행동과 함께 생각을 언어로 기록하는 방식이라, 프롬프트 설계가 매우 간단하다.
B) 일반적이고 유연함: 유연한 thoght space와 thoght-action 발생 형식 덕분에 QA, 팩트 확인, 텍스트 게임, 웹 탐색 등 다양한 작업에 적용할 수 있다.
C) 뛰어난 성능과 견고함: 단 1~6개의 소수 예시만으로도 새로운 작업에 대한 강력한 일반화 능력을 보이며, resoning or act 만 사용하는 기존 모델들보다 일관되게 우수한 성능을 보인다.
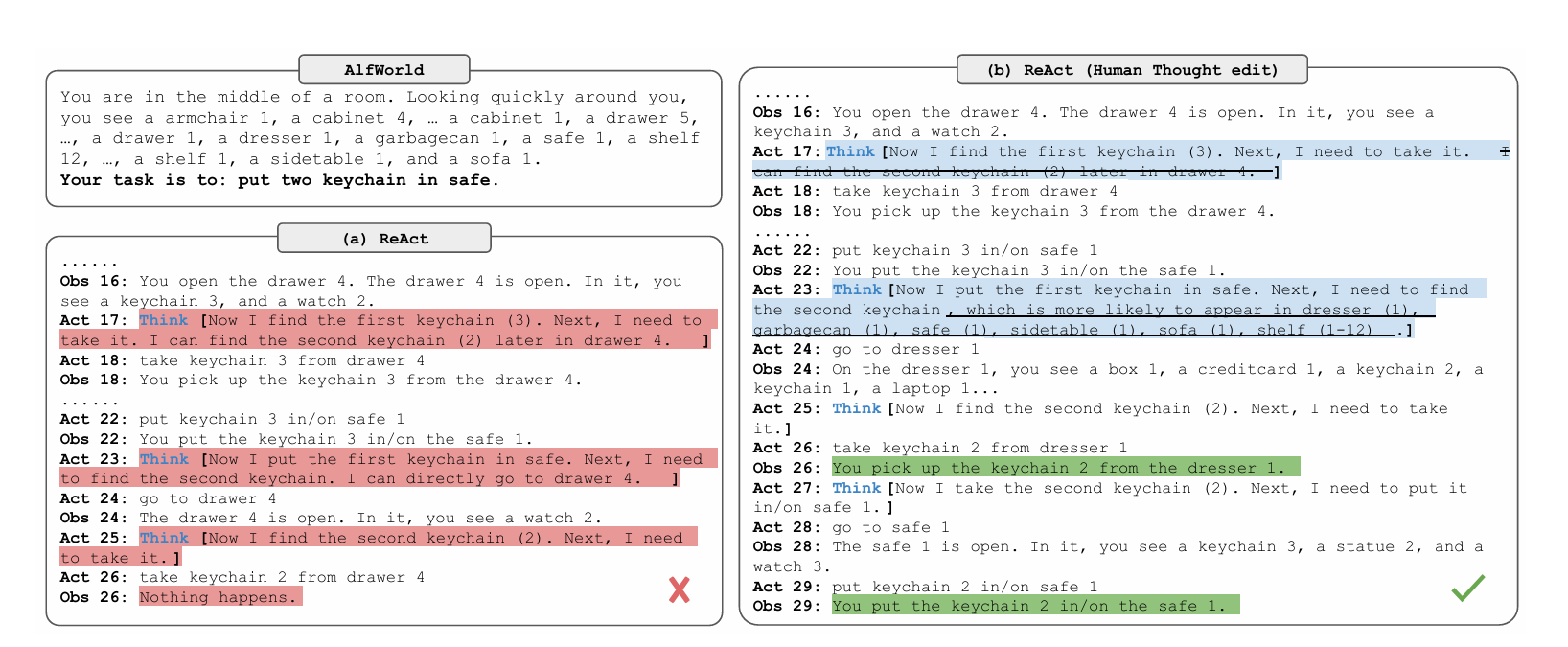
D) 인간 친화적이고 제어 가능함: 에이전트의 추론 과정을 명확하게 보여주므로, 인간이 그 과정을 쉽게 검토하고 이해할 수 있다. 또한, thought editing 통해 에이전트의 행동을 실시간으로 수정하거나 제어할 수 있다.
Experiments
ReAct가 multi-hop question answering task나 fact verification같은 KNOWLEDGE-INTENSIVE REASONING TASKS에서 어떻게 작동하는지 확인한다. 특히 위키피디아 API와 상호작용하며 Reasoning할 정보를 검색함과 동시에, 무엇을 검색할지 추론하는 능력도 함께 사용한다. 이를 통해 synergy of reasoning and acting를 보여준다.
Datasets
- HotPotQA
- FEVER
Action Space
ReAct는 위키피디아 API를 사용해 정보를 검색하기 위해 3type의 Action이 가능하도록 설계했다.
- Search: 검색한 entity 위키피디아 페이지에서 첫 5문장을 반환
- Lookup: 현재 페이지에서 주어진 string을 포함하는 다음 문장을 찾아 반환
- Finish: 작업 완료하고 최종 답변 제출
언어를 통한 명시적인 추론을 통해 정보를 검색하도록 유도한 설계이다.
METHODS
ReAct Prompting을 다음과 같이 진행하였다.

- 예시 구성: HotpotQA의 경우 6개, FEVER의 경우 3개 case를 무작위로 선택했다. 이 shot은 인간이 직접 작성한 ReAct 형식의 궤적(trajectory)으로 구성된다.
- 궤적의 특징: 각 궤적은 여러 단계의 'Thought-Action-Observation'로 이루어져 있다. 즉, 추론 과정이 촘촘하게 포함되어 있다.
이 자유 형식의 'thoughts'들은 다양한 목적으로 활용된다.
- 질문 분해: "나는 x를 검색하고, y를 찾은 다음, z를 찾아야 해"와 같이 질문을 단계별로 나눈다다.
- 정보 추출: 위키피디아에서 "x는 1844년에 시작되었다"와 같은 정보를 추출하거나, "이 문단에는 x에 대한 정보가 없어"와 같이 정보의 부재를 파악한다.
- 상식 또는 산술 추론: "x는 y가 아니므로 z여야 한다"와 같은 상식적인 판단이나, "1844 < 1989"와 같은 산술 계산을 수행한다.
- 검색 전략 재구성: "대신 x를 검색/조회해 볼까"와 같이 검색 전략을 수정한다.
- 답변 종합: "...따라서 답은 x이다"와 같이 최종 답변을 도출한다.
ReAct 성능 평가를 위해 Baseline을 다음과 같이 설정하였다.
- Standard
- CoT
- Acting-only Prompt
또한 Combining Internal and External Knowledge를 위해 다음과 같은 방법을 제안한다.
ReAct → CoT-SC 전환: ReAct가 주어진 단계(HotpotQA는 7단계, FEVER는 5단계) 내에 답변을 찾지 못하면, CoT-SC로 전환한다. 이는 ReAct의 무한정한 탐색을 방지하기 위함이다.
CoT-SC → ReAct 전환: CoT-SC 샘플 중 다수결 답변의 일치율이 낮을 경우(즉, 모델의 내부 지식이 확신을 주지 못할 때), ReAct로 전환하여 외부 지식을 활용하게 한다.
마지막으로 수동으로 추론 과정을 주석 달기는 매우 어렵기 때문에 bootstrpaing 방식을 사용했다.
- ReAct가 정답을 도출한 3,000개의 trajectories로 SFT
- SFT된 SLM을 통해 입력에 따라 모든 trajectories를 생성하도록 유도
Results

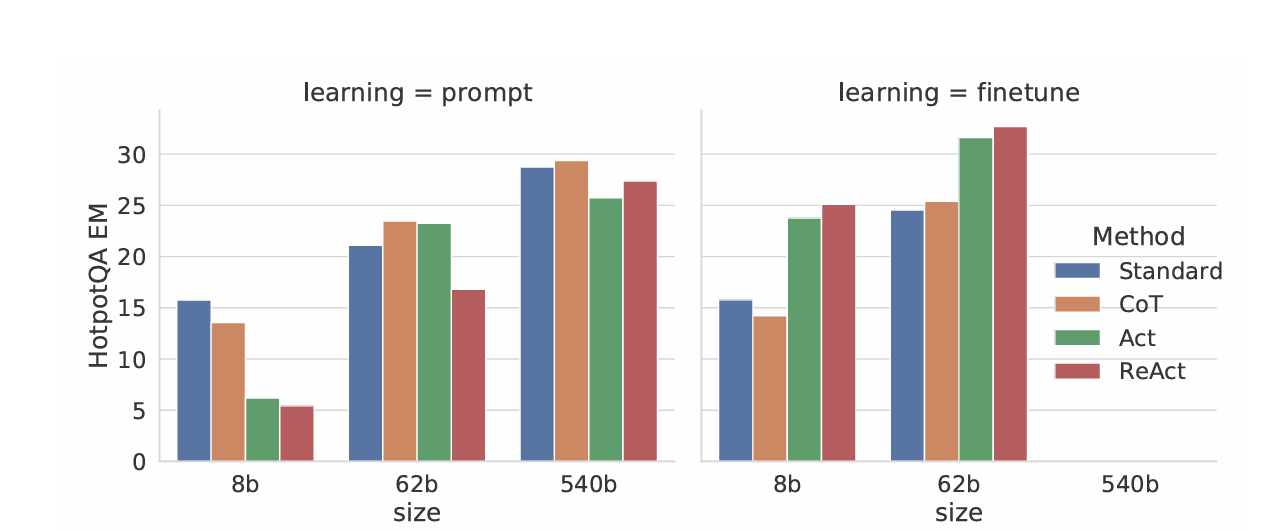
ReAct와 Acting-only (Act) 모델 비교
- ReAct의 우위
ReAct와 Chain-of-Thought (CoT) 모델 비교
- FEVER에서의 ReAct 우위: 60.9% vs 56.3%
- HotpotQA에서의 CoT 우위: 27.4% vs 29.4%
분석
- 할루시: CoT의 주요 실패 원인. ReAct는 사실에 기반한 문제 해결 과정으로 할루시로 인한 오류가 낮았다.
- 추론 오류: ReAct는 사고, 행동, 관찰을 번갈아 진행하기 때문에 추론 유연성이 떨어져 오류율이 CoT 대비 높다. 특히 이전 사고와 행동을 반복하는 오류 패턴이 자주 관찰되었다.
- 정보 부족: ReAct의 오류 사례중 23%는 정보 이슈 였다. 잘못된 검색 결과로 인해 모델의 추론을 방해하였고 다시 회복하기 어려웠다.
ReAct + CoT-SC 결합 모델의 우수성
-
최고의 성능: HotpotQA에서는 ReAct → CoT-SC 방식이, FEVER에서는 CoT-SC → ReAct 방식이 가장 좋은 성능을 보였다.
-
강력한 성능 향상: 두 결합 방법 모두 CoT-SC 단독 사용보다 훨씬 뛰어나며, CoT-SC가 21개 샘플을 사용했을 때의 성능을 단 3~5개 샘플로 달성했다. 이는 내부 지식과 외부 지식을 적절히 결합하는 것의 중요함을 시사한다
.
DECISION MAKING TASKS
ALFWorld
- 과제: 가상 가정 환경에서 텍스트 기반 행동을 통해 "책상 램프 아래의 종이를 살펴봐라"와 같은 상위 목표를 달성해야 하는 텍스트 게임이다.
- 어려움: 목표 달성까지 50단계 이상이 소요될 수 있어, 하위 목표를 계획하고 추적하며 체계적으로 탐색하는 능력이 필요하다. 특히, 특정 물건이 있을 법한 위치(예: 책상 램프는 책상 위에 있을 가능성이 높음)에 대한 상식적 지식이 중요하다.
- ReAct 프롬프트: ReAct는 훈련 데이터에서 가져온 몇 개의 궤적 예시를 사용하며, 이 예시에는 목표 분해, 하위 목표 추적, 다음 하위 목표 결정, 그리고 상식적 추론을 포함하는 사고가 포함되어 있다.
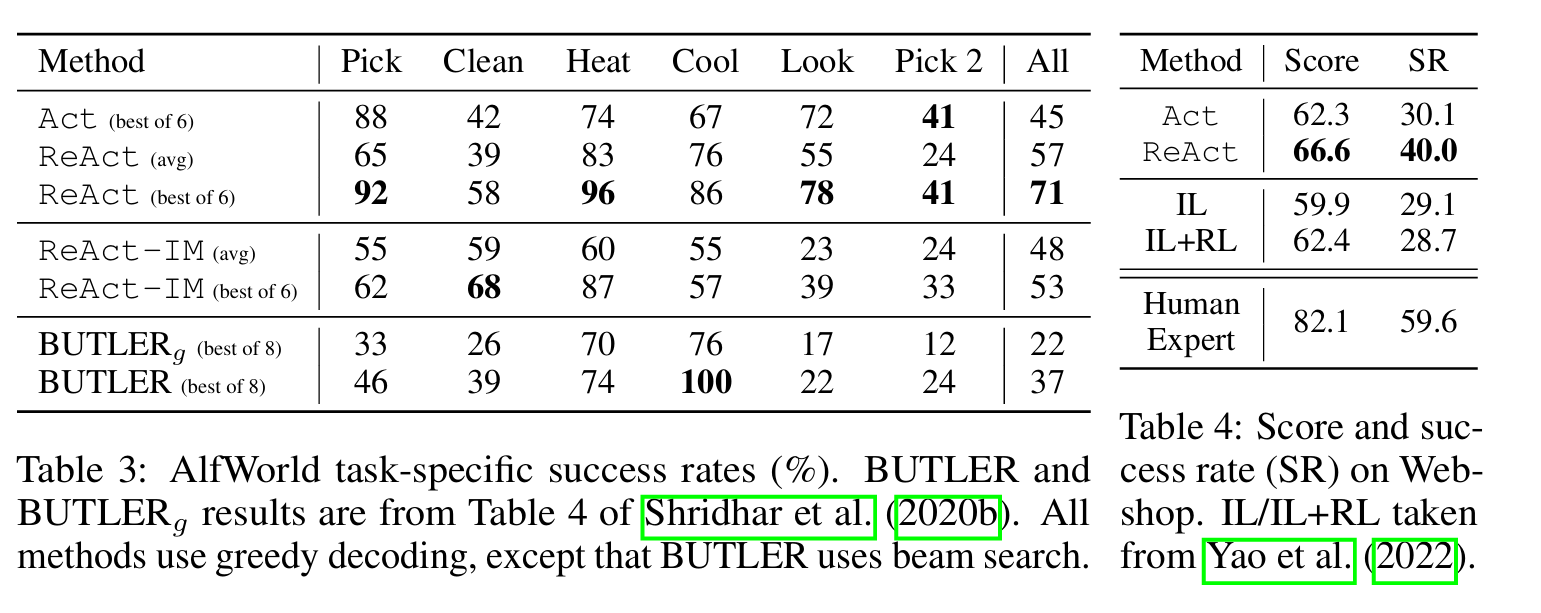
- 결과: ALFWorld에서 ReAct는 최고 성공률 71%를 달성하며, Acting-only 모델(최고 45%)과 BUTLER(37%)를 크게 앞섰다. 심지어 가장 성능이 낮은 ReAct 시도(48%)조차 다른 두 모델의 최고 성능을 능가했다. 분석에 따르면, 사고가 없는 Acting-only 모델은 목표를 제대로 분해하지 못하거나 현재 환경 상태를 추적하지 못하는 경향을 보였다.
WebShop
- 과제: 실제 온라인 쇼핑몰 환경에서 사용자의 지시에 따라 제품을 구매해야 한다. 예를 들어, "서랍이 있는 협탁을 찾고 있어. 니켈 마감에 가격은 140달러 미만이어야 해"와 같은 지시를 따른다.
- 어려움: 제품 제목, 설명 등 다양한 비정형 및 정형 텍스트를 처리해야 하며, 웹 검색, 제품 선택, 옵션 선택과 같은 복잡한 상호작용이 필요하다.
- ReAct 프롬프트: Acting-only 모델은 단순한 행동(검색, 제품 선택 등)만 수행하지만, ReAct 프롬프트는 탐색할 내용, 구매 시점, 지시와 관련된 제품 옵션 등을 추론하는 과정을 추가한다.
- 결과: ReAct는 기존 모방 학습 및 강화 학습 방법(IL, IL+RL)을 뛰어넘는 성능을 보여주었다. 이전 최고 성공률보다 10%p 향상된 결과를 기록했다. 질적 분석에 따르면, ReAct는 소음이 많은 관찰 내용과 행동 사이의 간극을 추론으로 메워 사용자의 지시와 관련된 제품과 옵션을 더 잘 식별했다. 그러나 인간 전문가의 성능에는 아직 미치지 못하며, 이는 프롬프트 기반 방법이 더 많은 제품 탐색 및 질의 재구성에는 여전히 어려움을 겪고 있음을 시사한다.
On the value of internal reasoning vs. external feedback
실험 결과, ReAct-IM은 전체 성공률 53%를 기록하며 ReAct(71%)에 비해 크게 뒤처졌다. 6개 과제 중 5개에서 ReAct는 일관된 우위를 보였다.분석에 따르면, ReAct-IM이 고수준 목표 분해 능력 부족으로 인해 하위 목표 완료 시점이나 다음 하위 목표를 식별하는 데 종종 실수를 저지른다는 것을 관찰하였다. 또한, 많은 ReAct-IM 궤적이 상식 추론 부족으로 인해 ALFWorld 환경 내에서 특정 물건이 어디에 있을지 결정하는 데 어려움을 겪었다.
Conclusion
- 다단계 질문 응답, 사실 확인, 상호작용 의사결정 등 다양한 실험을 통해 ReAct가 뛰어난 성능을 보였으며, 그 과정이 해석 가능한 의사결정 궤적(interpretable decision traces)을 통해 추적 가능함을 입증하였다.
Future works
- 더 많은 고품질의 인간 주석이 성능 향상에 중요
