1. 서론
현재의 RAG 시스템은 대규모 데이터셋에서 특정 정보를 검색하는 데 최적화된 Vector RAG 방식에 의존한다. 그러나 "데이터셋의 주요 테마는 무엇인가?"와 같은 전체 말뭉치에 대한 Global sensemaking 질문에는 대응하지 못하는 한계가 있다. 기존의 QFS 방식은 RAG 시스템이 다루는 방대한 텍스트 규모를 처리하기 어렵다. 이 논문은 GraphRAG를 제안하여, 지식 그래프 구축과 커뮤니티 요약 기술을 결합함으로써 대규모 텍스트 데이터셋에 대한 질문 대응 능력을 확장하고 Global sensemaking 질문에 효과적인 답변을 제공한다.
2. 방법론
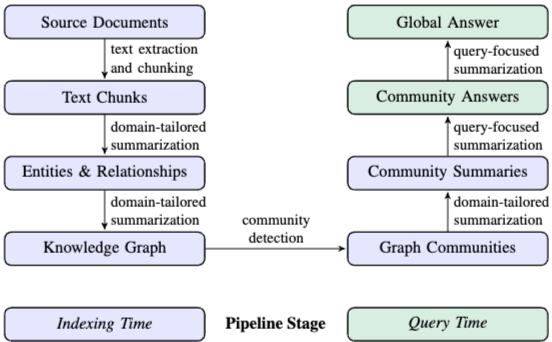
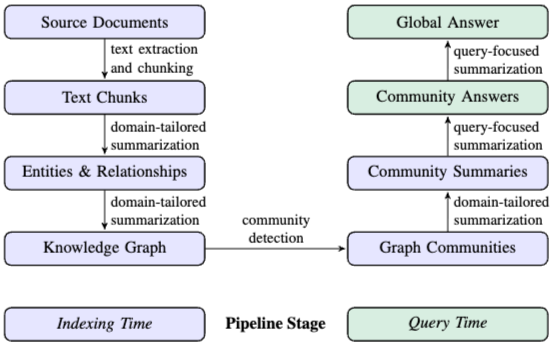
GraphRAG의 파이프라인은 크게 Indexing Time과 Query Time 두 단계로 구성된다.
-
Graph Index 구축 (Indexing Time):
- Text Chunking & Entity/Relationship Extraction: 소스 문서를 텍스트 단위로 분할하고 LLM을 사용하여 주요 Entity, Relationship, Claim을 추출한다. 추출 과정에서 self-reflection 기법을 통해 정보 누락을 방지한다.
- Knowledge Graph Construction: 추출된 인스턴스들을 노드와 엣지로 구성된 그래프로 구축하고, 중복 Entity를 병합한다.
- Community Detection: Leiden algorithm을 사용하여 그래프를 계층적인 커뮤니티 구조로 분할한다.
- Community Summarization: 계층 구조의 각 커뮤니티에 대해 LLM이 요약문을 생성한다. 하위 커뮤니티 요약은 상위 커뮤니티 요약 시 재귀적으로 반영되어 전체 말뭉치에 대한 Global 요약을 형성한다.
-
질문 대응 (Query Time):
- Map Step: 주어진 질문에 대해 각 커뮤니티 요약문이 독립적이고 병렬적으로 부분적인 답변과 helpfulness score를 생성한다.
- Reduce Step: 생성된 중간 답변들을 helpfulness score 순으로 정렬하여, 컨텍스트 제한 내에서 최종 Global 답변을 도출한다.
3. 실험
연구진은 약 100만 토큰 규모의 Podcast transcripts와 News articles 데이터셋을 활용하여 실험을 진행했다.
- 비교 대상: GraphRAG (4개 계층 수준: C0-C3), 원본 텍스트를 Map-Reduce 방식으로 요약하는 방법 (TS), 그리고 일반적인 Vector RAG (SS).
- 평가 방식: LLM-as-a-judge 기법을 적용하여 125개의 Global sensemaking 질문에 대해 Comprehensiveness, Diversity, Empowerment, Directness 항목을 비교 평가했다. 또한, Claimify를 사용해 추출된 factual claim의 수와 클러스터링을 통해 정량적 지표를 산출했다.
4. 결과
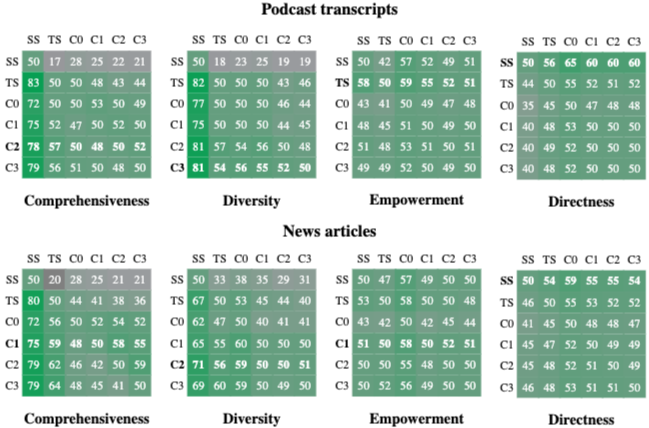

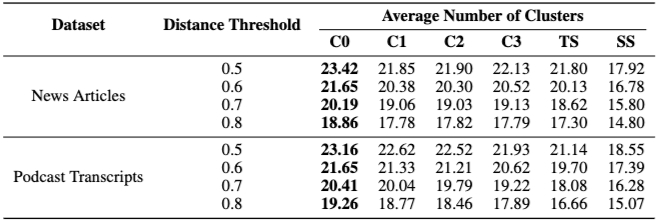
- 성능 우위: GraphRAG는 모든 데이터셋에서 Vector RAG (SS) 대비 Comprehensiveness 및 Diversity 항목에서 압도적으로 높은 승률을 기록했다.
- 효율성: Root-level (C0) 커뮤니티 요약을 사용할 경우, Vector RAG와 비교하여 훨씬 적은 컨텍스트 토큰을 사용하면서도 더 높은 품질의 답변을 제공한다. 구체적으로, C0 요약은 TS 방식보다 9배에서 43배 적은 토큰 비용으로 효율적인 Global 요약을 수행한다.
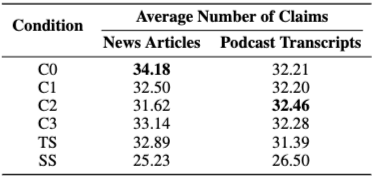
- 정량적 검증: Claim-based 측정 결과, 모든 GraphRAG 조건이 Vector RAG보다 더 많은 factual claim을 도출했으며, 정보의 다양성 측면에서도 우수한 결과를 보여주었다.
5. 결론
GraphRAG는 지식 그래프의 모듈성(modularity)을 활용하여 대규모 데이터셋에 대한 Global sensemaking 기능을 성공적으로 구현했다. 이 방식은 기존의 Vector RAG가 놓치기 쉬운 전체적인 테마와 연결성을 포착하는 데 탁월하며, 대규모 텍스트 말뭉치에 대한 효율적인 질문-답변 시스템 구축을 위한 새로운 표준을 제시한다. 향후 연구에서는 하이브리드 RAG 기법 결합 및 데이터 도메인 확장 등을 통해 모델의 정밀도를 지속적으로 향상시킬 예정이다.
