기존 RAG 시스템은 flat data representation에 의존하고 contextual awareness가 부족하여 복잡한 정보 간의 상호 의존성을 파악하지 못하고 fragmented answers를 생성하는 문제가 있었다. 이러한 문제를 해결하기 위해 LightRAG는 text indexing과 retrieval 프로세스에 graph 구조를 통합한다. 이 프레임워크는 low-level과 high-level 지식 발견을 위한 dual-level retrieval 시스템을 활용하여 포괄적인 정보 검색을 강화한다. 또한, graph 구조와 vector representation의 통합은 관련 entity와 그 관계의 효율적인 retrieval을 가능하게 하여 contextual relevance를 유지하면서 응답 시간을 크게 단축시킨다. LightRAG는 incremental update algorithm을 통해 새로운 데이터의 적시 통합을 보장하며, 이는 빠르게 변화하는 데이터 환경에서 시스템의 효율성과 응답성을 유지하는 데 기여한다. 광범위한 실험 검증을 통해 LightRAG는 기존 접근 방식에 비해 retrieval accuracy와 efficiency에서 상당한 개선을 보였다.
서론
chunking은 대규모 외부 텍스트 corpus를 더 작고 관리하기 쉬운 segment로 분할하여 정보 retrieval의 정확성을 높이는 데 중요한 역할을 한다. 그러나 기존 RAG 시스템은 flat data representation에 의존하여 복잡한 entity 관계를 이해하고 검색하는 데 한계가 있으며, contextual awareness가 부족하여 여러 entity와 그 상호 관계에 걸쳐 일관성을 유지하지 못하는 문제가 있다. 예를 들어, 전기차와 도시 대기 질, 대중교통 인프라 간의 복잡한 상호 의존성을 설명하지 못하고 파편화된 답변을 제공할 수 있다. LightRAG는 이러한 한계를 해결하기 위해 graph 구조를 text indexing과 retrieval에 통합한다. graph는 다양한 entity 간의 상호 의존성을 효과적으로 나타내며, 이는 관계에 대한 보다 미묘한 이해를 가능하게 한다. 본 연구의 핵심 목표는 Comprehensive Information Retrieval, Enhanced Retrieval Efficiency, Rapid Adaptation to New Data의 세 가지 주요 과제를 해결하여 효율적인 RAG 시스템을 구축하는 것이다.

LightRAG 아키텍처
LightRAG는 graph-based text indexing paradigm과 dual-level retrieval framework를 원활하게 통합한다. 이 혁신적인 접근 방식은 entity 간의 복잡한 상호 의존성을 포착하는 시스템의 능력을 향상시켜 보다 일관성 있고 contextually rich한 응답을 제공한다. LightRAG는 low-level retrieval과 high-level retrieval이라는 효율적인 dual-level retrieval 전략을 사용한다. low-level retrieval은 특정 entity와 그 관계에 대한 정확한 정보에 초점을 맞추고, high-level retrieval은 더 넓은 topic과 theme를 포함한다. LightRAG는 detail과 conceptual retrieval을 결합하여 다양한 쿼리를 효과적으로 수용한다. 또한, graph 구조와 vector representation의 통합을 통해 관련 entity 및 관계의 효율적인 retrieval을 가능하게 하며, 구축된 knowledge graph에서 관련 structural information을 통해 결과의 comprehensiveness를 향상시킨다.
Graph-Based Text Indexing
LightRAG는 문서를 더 작고 관리하기 쉬운 chunk로 분할하여 retrieval 시스템을 향상시킨다. 이 전략은 전체 문서를 분석하지 않고도 관련 정보를 신속하게 식별하고 접근할 수 있게 한다. 다음으로, LLM을 활용하여 다양한 entity(예: 이름, 날짜, 위치, 이벤트)와 그들 간의 관계를 식별하고 추출한다. 이 프로세스를 통해 수집된 정보는 전체 문서 collection에 걸쳐 연결 및 통찰력을 강조하는 포괄적인 knowledge graph를 생성하는 데 사용된다.
이 graph generation module은 다음과 같이 공식적으로 표현된다:
$$ \hat{D} = (\hat{V}, \hat{E}) = \text{Dedupe} \circ \text{Prof}(V, E) $여기서 $V, E = \cup_{D_i \in D} \text{Recog}(D_i)이며, 는 결과 knowledge graph를 나타낸다. 원시 텍스트 문서 에 세 가지 주요 처리 단계를 적용하여 이 데이터를 생성한다.
- Extracting Entities and Relationships (R(·)): 이 함수는 LLM에 텍스트 데이터 내의 entity(node)와 그 관계(edge)를 식별하도록 프롬프트한다. 효율성을 높이기 위해 원시 텍스트 는 여러 chunk 로 분할된다.
- LLM Profiling for Key-Value Pair Generation (P(·)): 각 entity node와 relation edge에 대한 텍스트 key-value pair (K, V)를 생성하기 위해 LLM 기반 profiling 함수 P(·)를 사용한다. 각 index key는 효율적인 retrieval을 가능하게 하는 단어 또는 짧은 구문이며, 해당 value는 텍스트 생성을 돕기 위해 외부 데이터에서 관련 snippet을 요약한 텍스트 paragraph이다. entity는 이름을 유일한 index key로 사용하고, relation은 연결된 entity의 global theme를 포함하는 LLM 강화로 파생된 여러 index key를 가질 수 있다.
- Deduplication to Optimize Graph Operations (D(·)): 마지막으로, 원시 텍스트 의 다른 segment에서 동일한 entity 및 relation을 식별하고 병합하는 deduplication 함수 D(·)를 구현한다. 이 프로세스는 graph의 크기를 최소화하여 에 대한 graph operation과 관련된 overhead를 효과적으로 줄여 더 효율적인 데이터 처리를 가능하게 한다.
Fast Adaptation to Incremental Knowledge Base
LightRAG는 효율적으로 진화하는 데이터 변화에 적응하면서 정확하고 관련성 높은 응답을 보장하기 위해 전체 외부 데이터베이스의 완전한 재처리 없이 knowledge base를 incremental하게 업데이트한다. 새로운 문서 에 대해 incremental update algorithm은 이전과 동일한 graph-based indexing steps 를 사용하여 처리하며, 결과는 이다. 이후 LightRAG는 node set 와 , 그리고 edge set 와 의 union을 취하여 새로운 graph 데이터를 원본과 결합한다. 이는 기존 연결의 무결성을 보존하고, 중복 없이 그래프를 풍부하게 하며, 전체 index graph를 재구축할 필요성을 없애 컴퓨팅 overhead를 줄인다.
Dual-Level Retrieval Paradigm
특정 문서 chunk와 그들의 복잡한 상호 의존성 모두에서 관련 정보를 검색하기 위해 LightRAG는 상세하고 추상적인 수준에서 query key를 생성한다. Specific Queries는 세부 지향적이며 일반적으로 graph 내의 특정 entity를 참조하고, 특정 node 또는 edge와 관련된 정보의 정확한 retrieval을 요구한다. Abstract Queries는 더 개념적이며, 특정 entity에 직접 연결되지 않은 더 넓은 topic, 요약 또는 전반적인 theme를 포함한다.
- Low-Level Retrieval: 이 수준은 주로 특정 entity와 그 관련 attribute 또는 관계를 검색하는 데 중점을 둔다. 이 수준의 쿼리는 세부 지향적이며 graph 내의 특정 node 또는 edge에 대한 정확한 정보를 추출하는 것을 목표로 한다.
- High-Level Retrieval: 이 수준은 더 넓은 topic과 전반적인 theme를 다룬다. 이 수준의 쿼리는 여러 관련 entity와 관계에 걸쳐 정보를 집계하여 특정 세부 사항보다는 high-level 개념 및 요약에 대한 통찰력을 제공한다.
Integrating Graph and Vectors for Efficient Retrieval
Graph 구조와 vector representation을 결합하여, 모델은 entity 간의 상호 관계에 대한 더 깊은 통찰력을 얻는다.
- (i) Query Keyword Extraction: 주어진 query 에 대해 LightRAG의 retrieval algorithm은 먼저 local query keywords 와 global query keywords 를 추출한다.
- (ii) Keyword Matching: algorithm은 효율적인 vector database를 사용하여 local query keywords를 candidate entity와 매칭시키고, global query keywords를 global key에 연결된 relation과 매칭시킨다.
- (iii) Incorporating High-Order Relatedness: 더 높은 order의 관련성으로 쿼리를 향상시키기 위해 LightRAG는 검색된 graph element의 local subgraph 내에서 neighboring node를 추가로 수집한다. 이 프로세스는 set을 포함하며, 여기서 와 는 각각 검색된 node 와 edge 의 one-hop neighboring node를 나타낸다.
Retrieval-Augmented Answer Generation
검색된 정보 를 활용하여 LightRAG는 수집된 데이터를 기반으로 답변을 생성하기 위해 general-purpose LLM을 사용한다. 이 데이터는 profiling 함수 P(·)에 의해 생성된 관련 entity 및 관계의 concatenate된 value V로 구성되며, 이름, entity 및 관계의 description, 원본 텍스트의 발췌본을 포함한다. query와 이 multi-source text를 통합하여 LLM은 사용자의 요구에 맞게 조절된 유익한 답변을 생성하며, query의 의도와 일치하도록 보장한다.
Complexity Analysis
LightRAG 프레임워크의 복잡성 분석은 두 가지 주요 부분으로 나뉜다. 첫 번째는 graph-based Index phase이다. 이 단계에서는 LLM을 사용하여 각 텍스트 chunk에서 entity와 관계를 추출한다. 결과적으로 LLM은 번 호출되어야 한다. 이 과정에는 추가 overhead가 없어 새로운 텍스트 업데이트를 효율적으로 관리한다.
두 번째 부분은 graph-based retrieval phase이다. 각 query에 대해 먼저 LLM을 사용하여 관련 키워드를 생성한다. 기존 RAG 시스템과 유사하게 LightRAG의 retrieval mechanism은 vector-based search에 의존한다. 그러나 기존 RAG와 달리 chunk를 검색하는 대신 entity와 관계를 검색한다. 이 접근 방식은 GraphRAG에서 사용되는 community-based traversal method에 비해 retrieval overhead를 크게 줄인다.
실험
LightRAG 프레임워크의 효과를 평가하기 위해 UltraDomain 벤치마크에서 Agriculture, CS, Legal, Mix 네 가지 데이터셋을 선택하여 실험을 수행했다. 이 데이터셋들은 각각 600,000에서 5,000,000 토큰에 이르는 방대한 양의 텍스트를 포함한다. 평가를 위해 LLM을 사용하여 각 데이터셋의 모든 텍스트 콘텐츠를 context로 사용하고, RAG 시스템의 high-level sensemaking task 평가를 위해 5명의 RAG 사용자(각 사용자별 5개 작업)를 생성했다. 각 (사용자, 작업) 조합에 대해 LLM은 전체 corpus에 대한 이해를 요구하는 5개의 질문을 생성하며, 각 데이터셋당 총 125개의 질문을 도출했다.
LightRAG는 Naive RAG, RQ-RAG, HyDE, GraphRAG와 같은 최신 RAG 모델들과 비교되었다. Naive RAG는 표준 baseline으로, 텍스트를 chunk로 분할하고 vector database에 저장하는 방식이다. RQ-RAG는 LLM을 활용하여 input query를 여러 sub-query로 분해하여 검색 정확도를 높인다. HyDE는 LLM을 사용하여 hypothetical document를 생성하여 관련 텍스트 chunk를 검색한다. GraphRAG는 LLM으로 entity와 관계를 추출하여 graph로 표현하고, community를 생성하여 high-level 쿼리에 대한 정보를 검색하는 graph-enhanced RAG 시스템이다.
평가 지표는 GPT-4o-mini를 LLM evaluator로 사용하여 다음 네 가지 차원에 따라 수행되었다: Comprehensiveness, Diversity, Empowerment, Overall. LLM은 두 답변을 각 차원에서 직접 비교하고 우수한 응답을 선택하며, 답변 제시 순서에 따른 bias를 완화하기 위해 답변의 위치를 교대로 제시했다. Win rate는 이에 따라 계산되었다.
결과
LightRAG와 기존 RAG 방법의 비교 (RQ1)
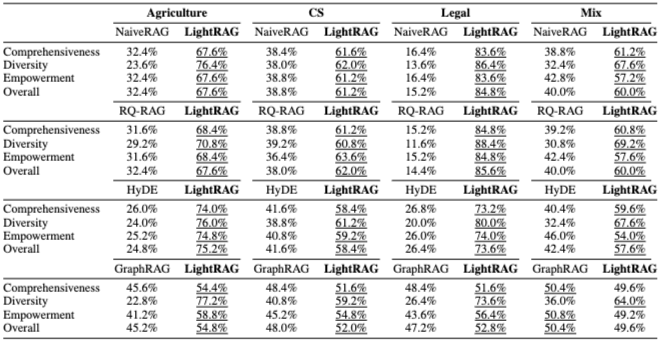
Table 1은 LightRAG와 각 baseline 간의 win rate를 보여준다. 대규모 corpus에서 LightRAG와 GraphRAG와 같은 graph-based RAG 시스템은 NaiveRAG, HyDE, RQRAG와 같은 chunk-based retrieval 방법을 consistently하게 능가한다. 특히 Legal 데이터셋과 같이 데이터셋 규모가 증가할수록 이러한 성능 차이는 더욱 두드러진다. LightRAG는 특히 Diversity metrics에서 상당한 이점을 보여주며, 이는 dual-level retrieval paradigm이 low-level과 high-level 정보의 포괄적인 검색을 용이하게 하기 때문이다. LightRAG는 GraphRAG도 능가하며, 특히 대규모 데이터셋에서 complex language context를 처리하는 데 강점을 보인다. LightRAG는 specific entity의 low-level retrieval과 broader topic의 high-level retrieval을 결합하여 응답 다양성을 높이고 복잡한 쿼리 처리에 효과적이다.
Ablation Studies (RQ2)
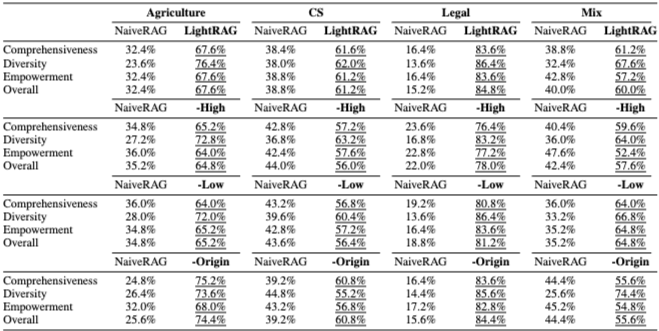
Table 2는 LightRAG의 ablated version의 성능을 보여준다.
- Dual-level Retrieval Paradigm의 효과:
LightRAG -High(high-order retrieval 제거) 변형은 거의 모든 데이터셋과 지표에서 성능이 크게 감소했다. 이는 특정 정보에만 중점을 두어 복잡한 쿼리에 필요한 포괄적인 통찰력을 얻는 데 어려움을 겪기 때문이다.LightRAG -Low(high-level-only retrieval) 변형은 broader content를 포착하는 데 이점을 보이지만, 특정 entity에 대한 깊이 있는 탐색이 부족하여 정밀한 답변을 제공하는 데 어려움이 있다. LightRAG의 Hybrid Mode (full version)는 low-level과 high-level retrieval의 강점을 결합하여 retrieval 프로세스의 breadth와 analysis의 depth를 모두 보장하며, 여러 차원에서 균형 잡힌 성능을 달성한다. - Semantic Graph의 우수성: retrieval 프로세스에서 원본 텍스트의 사용을 제거한
LightRAG -Origin변형은 성능 저하를 보이지 않았고, 일부 경우(Agriculture, Mix)에는 오히려 개선되었다. 이는 graph-based indexing 프로세스 동안 key information의 효과적인 추출이 쿼리 응답에 충분한 context를 제공하며, 원본 텍스트에 포함될 수 있는 irrelevant information이 노이즈를 유발할 수 있기 때문으로 분석된다.
Case Study (RQ3)
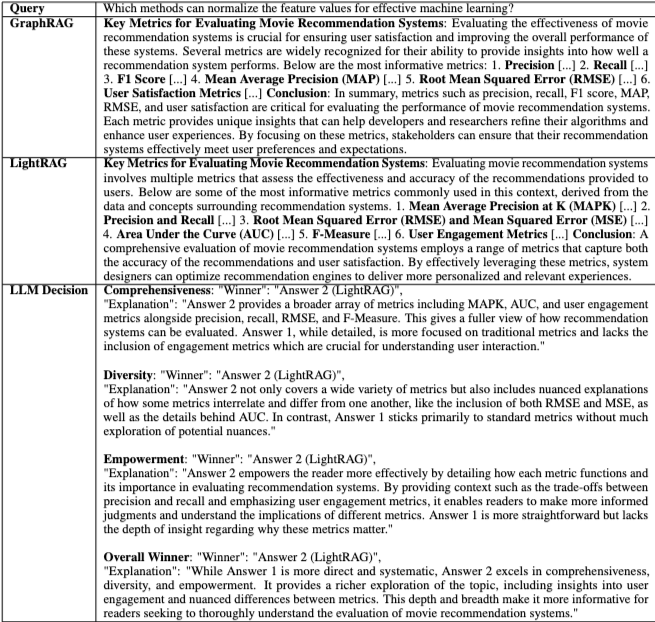
Table 3은 LightRAG와 GraphRAG 간의 machine learning 질문에 대한 답변 비교 사례를 보여준다. LightRAG는 Comprehensiveness, Diversity, Empowerment, Overall 품질 측면에서 GraphRAG를 능가한다. LightRAG는 더 넓은 범위의 machine learning metrics를 포괄하며, 이는 graph-based indexing paradigm의 강점과 LLM profiling의 우수성을 보여준다. 또한 LightRAG는 dual-level retrieval paradigm을 통해 더 다양한 정보를 제공하고 독자에게 더 큰 Empowerment를 제공하며, 이는 low-level retrieval을 통한 관련 entity의 in-depth exploration과 high-level retrieval을 통한 broader exploration의 결합 덕분이다.
모델 비용 및 적응성 분석 (RQ4)
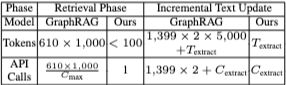
Figure 2는 LightRAG와 GraphRAG의 비용을 토큰 및 API 호출 측면에서 비교한다. Retrieval phase에서 GraphRAG는 610,000 토큰(610 community × 1,000 tokens/community)과 수백 번의 API 호출을 요구하는 반면, LightRAG는 키워드 생성 및 retrieval에 100 토큰 미만과 단일 API 호출만 필요하여 훨씬 효율적이다.
Incremental data update phase에서 두 모델은 entity 및 관계 추출에서 유사한 overhead를 보이지만, GraphRAG는 새로 추가된 데이터를 관리하는 데 상당한 비효율성을 보인다. GraphRAG는 기존 community 구조를 해체하고 완전히 재생성해야 하므로, 1,399개 community의 경우 약 1,399 × 2 × 5,000 토큰의 비용이 발생한다. LightRAG는 새로 추출된 entity와 관계를 기존 graph에 원활하게 통합하여 전체 재구축이 필요 없으므로 incremental update 시 overhead가 훨씬 낮다.
결론
본 연구는 Retrieval-Augmented Generation (RAG) 분야에서 LightRAG를 통해 graph-based indexing 접근 방식을 통합함으로써 효율성과 정보 검색의 Comprehension을 향상시킨다. LightRAG는 포괄적인 knowledge graph를 활용하여 빠르고 관련성 있는 문서 retrieval을 촉진하고 복잡한 쿼리에 대한 더 깊은 이해를 가능하게 한다. dual-level retrieval paradigm은 특정 정보와 추상적인 정보를 모두 추출하여 다양한 사용자 요구를 충족시킨다. 또한 LightRAG의 seamless incremental update capability는 시스템이 새로운 정보에 대해 현재 상태를 유지하고 응답성을 유지하며 시간 경과에 따른 효율성을 유지하도록 보장한다. 전반적으로 LightRAG는 효율성과 효과성 모두에서 뛰어나며, 정보 retrieval 및 생성의 속도와 품질을 크게 향상시키는 동시에 LLM inference 비용을 절감한다.
