Absctract
시각적으로 풍부한 문서(VRD)에 대한 질의응답은 고립된 내용뿐만 아니라 문서의 구조적 조직과 페이지 간 의존성에 대한 추론도 필요하다. 그러나 기존의 검색 증강 생성(RAG) 방식은 문서 수집 단계에서 내용을 고립된 청크로 인코딩하여 구조적 및 페이지 간 의존성을 손실한다. 또한, 질의나 문맥의 특정 요구 사항과 관계없이 추론 시 고정된 수의 페이지를 검색하여 다중 페이지 추론 작업에서 불완전한 증거 검색과 저하된 답변 품질을 초래한다. 이러한 한계를 해결하기 위해 본 연구는 새로운 레이아웃 인식 동적 RAG 프레임워크인 LAD-RAG를 제안한다. 수집 단계에서 LAD-RAG는 레이아웃 구조와 페이지 간 의존성을 캡처하는 Symbolic Document Graph를 표준 Neural Embedding과 함께 구축하여 문서의 보다 전체적인 표현을 생성한다. 추론 단계에서 LLM Agent는 질의에 기반하여 필요한 증거를 적응적으로 검색하기 위해 Neural Index 및 Symbolic Index와 동적으로 상호 작용한다. MMLongBench-Doc, LongDocURL, DUDE, MP-DocVQA에 대한 실험 결과, LAD-RAG는 어떤 top-k 튜닝 없이도 평균 90% 이상의 Perfect Recall을 달성하여 검색 성능을 향상시키며, 유사한 노이즈 수준에서 기존 검색기보다 최대 20% 더 높은 Recall을 보이고, 최소한의 지연 시간으로 더 높은 QA 정확도를 제공한다.
Introduction
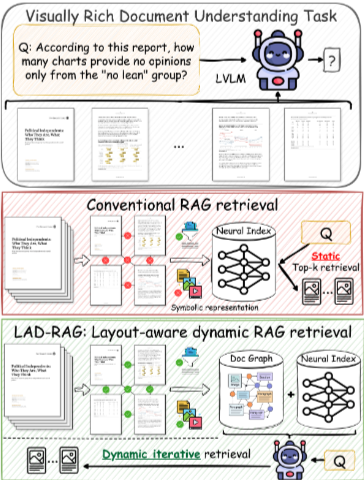
시각적으로 풍부한 문서(VRD)에 대한 질의응답, 요약, 데이터 추출과 같은 자연어 처리(NLP) 작업은 텍스트, 그림, 차트 처리 및 레이아웃(예: 문서 구조, 읽기 순서, 시각적 그룹화)에 대한 추론을 필요로 한다. 최신 멀티모달 모델은 이러한 입력을 처리할 수 있지만, 문서가 모델의 컨텍스트 창을 초과하거나 입력 길이가 길어질수록 성능이 저하되는 한계가 있다. 이는 관련 신호가 노이즈에 의해 희석되어 불완전하거나 부정확한 답변으로 이어진다. 이러한 문제를 극복하기 위해 RAG 프레임워크는 문서 청크를 색인화하고 추론 시 관련 청크의 하위 집합을 검색한다. 그러나 Figure 1에서 보듯이 기존 RAG 접근 방식은 대부분 Dense Text 및 Image Encoder에 의존하며, 문서 세그먼트를 선형적인 고립된 단위의 시퀀스로 취급하여 문서 구조와 페이지 간 관계를 무시한다. 이로 인해 세 가지 주요 한계가 발생한다.
- 레이아웃 및 구조적 컨텍스트 손실 (Loss of layout and structural context): 레이아웃 기반 계층 구조와 페이지 간 연속성을 무시하면 불완전한 증거 검색으로 이어질 수 있다. 예를 들어, "빅데이터로 인한 변혁의 사례로 제시된 기업은 몇 개인가?"와 같은 질문에 대해 기존 검색기는 제목 슬라이드만 반환하고, 문서의 구조와 레이아웃을 통해 제목 슬라이드와 연결된 후속 페이지의 사례들을 놓칠 수 있다.
- 임베딩에 대한 과도한 의존 (Over-reliance on embeddings): 검색은 차트 참조, 페이지 번호 또는 테이블 출처와 같은 Symbolic 또는 Structural Cues에 의존하는 질의에서 어려움을 겪는다. "이 보고서에서 Pew Research Center 설문 데이터의 총 연간 합계에서 가져온 차트와 테이블은 몇 개인가?"와 같은 질문에 답하려면 시맨틱 임베딩에 명시적으로 캡처되지 않은, 연속적이지 않지만 구조적으로 관련된 그림과 캡션을 집계해야 한다.
- 정적 top-k 검색 (Static top-k retrieval): 검색 깊이는 질문이나 문서 복잡성에 관계없이 고정되어, 너무 많거나 너무 적은 증거를 검색하는 경우가 많다. 질문의 범위가 "상세하게 소개된 조직은 몇 개인가?"처럼 세 페이지만 필요한 경우와, "네덜란드의 고유한 위치 이미지는 몇 개 사용되었는가?"처럼 12페이지가 필요한 경우가 다르다.
요약하면, 기존 RAG 파이프라인은 수집 시점에 전체적인 문서 표현이 부족하여 관련 내용이 문서 전반에 걸쳐 구조적으로 분산되어 있을 때 완전한 증거 집합을 검색하는 데 방해가 된다. 이를 해결하기 위해 본 연구는 레이아웃 인식 동적 RAG인 LAD-RAG를 도입한다. LAD-RAG는 수집 단계에서 구축된 Symbolic Document Graph로 기존 Neural Indexing을 강화한다. 이 그래프의 노드는 명시적 Symbolic Element (예: 헤더, 그림, 테이블)를 인코딩하고, 엣지는 구조적 및 레이아웃 기반 관계(예: 섹션 경계, 그림-캡션 링크, 페이지 간 의존성)를 캡처한다. 이 설계는 개별 노드에 대한 Fine-grained retrieval과 구조적으로 그룹화된 요소(예: 섹션의 모든 구성 요소)에 대한 Higher-level retrieval을 모두 지원하여 여러 보완적인 검색 경로를 가능하게 한다. 추론 시 질의가 주어지면, 색인화된 정보를 효과적으로 활용하기 위해 언어 모델 에이전트가 Neural Index와 Document Graph 모두에 접근하여 적절한 검색 전략(Neural, Graph-based 또는 Hybrid)을 결정하고, 두 색인과 반복적으로 상호 작용하여 완전한 증거 집합을 검색한다. 특히 Document Graph는 레이아웃 기반의 근접성과 Higher-order 패턴을 포함한 Local 및 Global Structural Relationship을 인코딩하므로, LAD-RAG는 검색된 노드들을 일관되고 완전한 노드 그룹으로 Contextualize할 수 있다. 이는 기존 RAG 시스템의 부분적이고 단편적인 검색과 달리, 완전하고 잘 구조화된 증거 집합의 추출을 지원한다.
2 LAD-RAG Framework
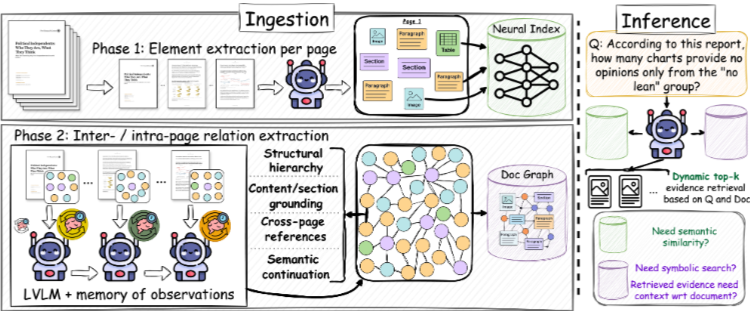
질의 (q)의 대상인 문서 (d)가 주어졌을 때, LAD-RAG 프레임워크의 목표는 수집 시점에 문서 d에 대한 전체적이고 Contextualized된 이해를 구축하여 추론 시 더 완전하고 정확한 검색을 지원하는 것이다. 이를 달성하기 위해 프레임워크는 Figure 2에 설명된 두 가지 해당 단계로 구성된다. (i) 수집 중 Neural 및 Symbolic 형태로 풍부한 문서 정보를 준비하고 저장하며 (Section 2.1), (ii) 추론 중에 해당 정보를 전략적으로 활용한다 (Section 2.2).
2.1 수집 단계 (Ingestion)
수집 단계에서는 문서 d를 포괄적으로 파싱하고 그 내용을 Neural 및 Symbolic 형태로 저장하는 것을 목표로 한다. 인간 독자가 페이지를 순차적으로 읽으면서 상호 참조 및 상위 개념을 추적하여 Mental Model을 구축하는 과정에서 영감을 받아, Figure 2에서 보여지는 유사한 과정을 시뮬레이션한다. 다양한 문서 레이아웃에 걸친 유연한 이해를 지원하기 위해, GPT-4o와 같은 강력한 Large Vision–Language Model (LVLM)을 사용하여 각 페이지를 순차적으로 처리한다. LVLM이 각 페이지를 파싱하면서, 모든 가시적 요소를 추출하고 각 요소에 대한 Self-contained Description을 생성한다 (이는 나중에 Document Graph의 노드를 형성한다). 페이지 수준 처리를 넘어, 문서에 대한 인간 독자의 지속적인 이해와 유사하게 Running Memory (M)를 유지한다. 이 메모리는 섹션 구조, 개체 언급, 주제 진행과 같은 핵심적인 High-level 정보를 페이지 간에 축적한다. 새 페이지가 처리될 때마다, 해당 요소를 M의 관련 부분과 연결하여 Document Graph의 엣지와 같은 페이지 간 관계를 구축한다. 모델이 문서에 대한 전체 패스를 완료하면, Intra- 및 Inter-page 구조를 모두 포함하는 전체 Document Graph (G)를 구성한다. 이 그래프는 두 가지 보완적인 형태로 저장된다: 전체 Symbolic Document Graph 객체와 해당 노드에 대한 Neural Index. 각 형태는 다운스트림 검색의 다른 모드를 가능하게 한다.
- 문서 그래프 노드 (Document Graph Nodes): 각 노드는 페이지의 로컬화된 요소(예: 단락, 그림, 테이블, 섹션 제목, 각주)에 해당한다. 모든 요소에 대해 다음을 추출한다.
Layout position: 페이지의 위치.Element type: 요소의 종류 (예: figure, paragraph, section header).Displayed content: 추출된 텍스트 또는 시맨틱, 캡션을 포함한 요소의 전체 원시 내용.Self-contained summary: 독립적인 해석을 가능하게 하는 요약.Visual attributes: 글꼴, 색상, 크기 등 시각적 속성.
이 노드 수준 표현은 모든 요소가 필요한 경우 독립적으로 검색되고 해석될 수 있도록 보장하며, 동시에 구조화된 색인화를 가능하게 한다.
- 문서 그래프 엣지 (Document Graph Edges): 엣지는 Symbolic, Layout 또는 Semantic Relationship에 따라 노드를 연결한다. 여기에는 다음이 포함된다.
Reference relationships: 예를 들어, 그림을 참조하는 단락 또는 섹션을 참조하는 각주.
Layout/structural relationships: 예를 들어, 동일한 섹션에 속하는 요소 또는 페이지 간 연속성을 나타내는 요소.
이러한 엣지를 구성하려면 문서 구조에 대한 Higher-level 이해가 필요하다. 이는 현재 섹션 계층, 논의 중인 활성 개체, 미해결 참조(예: 나중에 설명될 요소에 대한 자리 표시자)를 추적하는 Running Memory (M)에 의해 가능해진다. 이러한 Contextual Signal은 현재 페이지만으로는 명확하지 않은 관계를 명확히 하는 데 도움이 된다. - 신경-기호 색인화 (Neural-symbolic indexing): 수집의 최종 출력은 두 가지 보완적인 표현으로 저장된다.
1. Symbolic (graph) index (G): 구조화된 노드/엣지 속성(예: content type, location, visual attributes) 및 그래프 구조에 의해 캡처된 커뮤니티의 일부인 노드 집합을 캡처하는 그래프 기반 검색을 위한 명시적 Local 및 Global Relationship을 가진 Document Graph이다.
2. Neural index (E): 모든 노드의 Self-contained summary에 대한 Vector-based index로, Semantic Similarity Search를 가능하게 한다.
이 이중 표현은 Neural Model의 시맨틱 풍부함과 문서 레이아웃에 캡처된 명시적 구조를 모두 보존하여, 임베딩 기반 접근 방식만으로는 접근할 수 없는 검색 메커니즘을 가능하게 한다.
2.2 추론 단계 (Inference)
추론 시, 질의 q, 해당 Symbolic Graph G, 및 Neural Index E가 주어졌을 때, 목표는 G 및/또는 E에서 완전하고 문맥적으로 적절한 증거 집합을 검색하는 것이다. 이 과정은 질의에 따라 달라지며 (일부 질문은 임베딩 유사성을 통해 답변될 수 있지만, 다른 질문은 레이아웃 또는 구조에 대한 Symbolic Reasoning을 필요로 함) 상호적이다. 질의의 범위와 난이도에 따라 다양한 양의 증거가 필요할 수 있기 때문이다. 이러한 요구 사항을 수용하기 위해, LAD-RAG는 LLM Agent (GPT-4o)를 사용하여 두 색인과 반복적으로 상호 작용하며 질문에 답하는 데 필요한 모든 증거를 검색한다 (Figure 2 참조). LLM Agent는 색인에 접근하고 작동하기 위한 명시적 함수 시그니처를 가진 Tool Interface를 갖추고 있다. 질의가 주어지면, 에이전트는 High-level 계획을 생성하고 (예: Semantic, Symbolic 또는 Hybrid 검색 모드 선택), 그에 따라 도구 호출을 발행하고, 대화 루프를 통해 증거 집합을 반복적으로 정제한다. 이 루프는 다음 조건 중 하나가 충족될 때 종료된다. (i) 모델의 컨텍스트 창에 가까워지거나, (ii) 최대 단계 수에 도달하거나, (iii) 에이전트가 충분한 증거가 수집되었다고 판단하는 경우이다.
에이전트에 노출되는 도구는 다음과 같다.
1. NeuroSemanticSearch(query): 에이전트가 주어진 질문 q에 기반하여 구성한 질의를 사용하여 Neural Index에서 임베딩 유사성 기반으로 증거를 검색한다.
2. SymbolicGraphQuery(query_statement): Symbolic Document Graph에 대한 구조화된 질의를 수행한다 (예: 요소 유형, 섹션 또는 페이지별 필터링). 에이전트는 그래프 표현에 대한 지시를 받고, 문서 그래프 객체와 상호 작용하고 해당 속성 또는 구조적 위치에 기반하여 관련 노드를 추출하기 위한 질의 문장을 생성해야 한다.
3. Contextualize(node): 주어진 노드를 그래프 내의 구조적 근접성에 기반하여 더 넓은 증거 집합으로 확장한다. 이 확장은 Local Neighborhoods와 Higher-order Relationships를 모두 활용하며, Louvain Community Detection (Blondel et al., 2008)을 사용하여 문맥적으로 관련된 노드의 일관된 클러스터를 표면화한다.
이러한 도구들은 시스템이 특정 질의, 문서 및 추론 복잡성에 맞춰 증거를 유연하게 검색할 수 있도록 하여, 고정된 top-k 검색을 넘어 완전히 Contextualized되고 적응적인 증거 선택을 지원한다.
3 Experiments
3.1 Datasets
LAD-RAG를 평가하기 위해, MMLongBench-Doc, LongDocURL, DUDE, MP-DocVQA의 네 가지 다양한 VRD 벤치마크에서 실험을 수행한다. 이 데이터셋들은 High-level 문서 내용에 기반한 질문과 그림, 참조, 섹션, 테이블과 같은 보다 로컬화된 시각적 요소에 의존하는 질문을 포함하여 광범위한 도메인과 질문 유형을 다룬다. 또한 질문에 답하는 데 필요한 페이지 수가 다양하여, LAD-RAG의 검색 완전성뿐만 아니라 다운스트림 질의응답 성능을 평가하는 데 적합하다.
- MMLongBench-Doc: Long-context 문서 이해를 목표로 한다. 135개의 긴 PDF 문서(평균 47.5페이지, 약 21k 토큰)에 대한 1,082개의 전문가 주석 질문을 포함한다. 증거는 텍스트, 이미지, 차트, 테이블 및 레이아웃 구조를 포함한 멀티모달 소스에서 나온다. 특히 질문의 33%는 Cross-page evidence를 필요로 한다.
- LongDocURL: 33k 페이지에 걸쳐 396개 문서를 포함하며 이해, 추론, 위치 파악의 세 가지 작업 범주를 통합한다. 2,325개의 고품질 QA 쌍을 제공하며, 문서당 평균 86페이지, 약 43k 토큰이다. 다중 페이지(52.9%) 및 Cross-element(37.1%) 질문의 비율이 가장 높다.
- DUDE (Document Understanding Dataset and Evaluation): 약 5천 개의 다중 페이지 문서로 구축된 대규모, 다중 도메인 벤치마크이다. 평균 문서 길이는 5.7페이지, 약 1,831 토큰이다.
- MP-DocVQA: DocVQA 데이터셋을 다중 페이지 문서로 확장한다. 5,928개 문서에 걸쳐 46k 질문을 포함하며 총 47,952페이지로, 문서당 약 8페이지이다. 각 질문은 Supporting Evidence가 단일 페이지에 국한되도록 설계되었다.
3.2 Baselines
- 검색 (Retrieval): LAD-RAG의 증거 검색 성능을 텍스트 기반 및 이미지 기반 검색기와 비교한다.
텍스트 기반: E5-large-v2, BGE-large-en, BM25.
이미지 기반: ColPali.
이러한 기준선은 추출된 모든 페이지 요소의 요약에 대해 작동하며, 추론 시 질의와의 유사성을 기반으로 top-k 요소를 검색하는 표준 RAG 설정을 따른다. 성능은 Perfect Recall 지점까지의 k 값에 따라 평가한다. - 질의응답 (Question Answering): 검색된 증거를 다음 네 가지 LVLM과 페어링하여 시스템의 다운스트림 QA 성능을 평가한다.
Phi-3.5-Vision-4B, Pixtral-12B-2409, InternVL2-8B, GPT-4o.
각 모델에 대해 결정론적 Greedy Decoding을 사용하여 답변을 생성하고, 다음 검색 설정에서 QA 정확도를 비교한다.
LAD-RAG에 의해 검색된 증거 사용.
고정된 검색 크기(k=5, k=10)에서 가장 성능이 좋은 기준 검색기 사용.
LAD-RAG와 동일한 수의 검색된 항목(검색 예산 통제)을 매칭하는 동일한 기준 검색기 사용.
* Ground-truth evidence pages (Oracle retrieval)를 상한선으로 사용.
VRD에서의 QA를 위한 검색의 가치를 설명하기 위해, 전체 문서를 입력으로 받는 모델(예: mPLUG-DocOwl v1.5-8B, Idefics2-8B, MiniCPM-Llama3-V2.5-8B)과도 비교한다.
3.3 Evaluations & Metrics
-
검색 (Retrieval): 질의 q가 문서 d와 연관되어 있고, Ground-truth 증거 페이지 집합이 이라고 할 때, 검색기가 반환하는 페이지 집합 이 P와 얼마나 잘 일치하는지(완전성과 정확성 측면에서) 평가한다.
-
Perfect Recall (PR): 이진 지표로, 로 정의한다. 검색기가 모든 Ground-truth 페이지를 검색했는지 여부를 나타낸다. 다중 페이지 질문의 경우, 단 하나의 증거 페이지를 놓쳐도 부정확한 답변이 나올 수 있으므로 이 지표는 중요하다.
-
Irrelevant Pages Ratio (IPR): 검색된 페이지 중 골드 집합에 없는 페이지의 비율이다. 로 정의하며, 검색기가 도입하는 노이즈를 캡처한다. 값이 낮을수록 더 목표 지향적인 검색을 나타낸다. 이상적인 검색기는 높은 Perfect Recall을 달성하면서 불필요한 내용의 과도한 포함 없이 모든 필요한 증거를 검색하여 Irrelevant Pages Ratio를 최소화한다.
-
-
질의응답 (Question Answering): MMLongBench 및 LongDocURL의 평가 설정에 따라, GPT-4o를 사용하여 검색된 내용에서 간결한 답변을 추출하고 Rule-based 비교를 적용하여 이진 정답 여부를 할당한다. 이를 기반으로 정확도를 보고한다.

4 Results
4.1 Retrieval Effectiveness of LAD-RAG
LAD-RAG의 검색 성능을 Figure 3에서 네 가지 VRD 벤치마크와 기준 방법들에 대해 평가한다. 특히, LAD-RAG는 어떤 top-k 튜닝 없이도 데이터셋 전반에 걸쳐 평균 90% 이상의 Perfect Recall을 달성한다. 그럼에도 불구하고, 기존 기준선에 비해 상당히 적은 불필요한 페이지를 검색한다. 동일한 Irrelevance Rate에서, LAD-RAG는 Perfect Recall Rate에서 MMLongBench-Doc에서 약 20%, LongDocURL에서 15%, DUDE와 MP-DocVQA 모두에서 10% 더 높은 성능을 보인다. 반대로, 기준 검색기들은 우리의 Recall Rate를 맞추기 위해 큰 top-k 값을 필요로 한다. 평균적으로 MMLongBench-Doc의 경우 k=25, LongDocURL의 경우 k=29, DUDE의 경우 k=10, MP-DocVQA의 경우 k=5이다. 이러한 결과는 일반적인 검색 관행(k가 일반적으로 낮은 숫자로 제한됨)과 다중 페이지 질문에 답하는 데 필요한 실제 증거량 사이에 중요한 불일치가 있음을 보여준다. LAD-RAG의 이점은 여러 페이지에서 증거를 필요로 하는 질문에서 더욱 두드러진다. LAD-RAG는 모든 기준선보다 더 완전한 다중 페이지 증거 집합을 일관되게 검색한다. 이는 구조화된 레이아웃 모델링과 Symbolic 및 Neural Index와의 동적 상호 작용을 통해 분산된 정보를 캡처하는 능력을 반영한다.
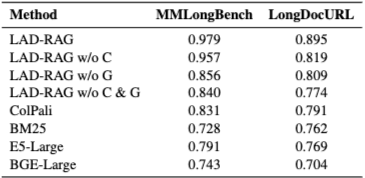
4.2 Ablation Study of Retrieval Components
LAD-RAG의 개별 구성 요소의 기여를 이해하기 위해, 가장 어려운 벤치마크인 MMLongBench와 LongDocURL에서 LAD-RAG 변형들 간의 전반적인 검색 성능(Perfect Recall과 Irrelevant Page Retrieval의 비율로 측정, 높을수록 더 나은 Recall과 낮은 노이즈를 의미)을 비교하는 제거 연구를 수행한다. 완전한 LAD-RAG (Contextualize 및 GraphQuery 모두 포함)를 한두 구성 요소를 비활성화한 버전과 비교한다. Table 1에서 보듯이, Contextualization (C) 또는 Symbolic Graph Querying (G) 중 하나를 제거하면 성능이 눈에 띄게 저하된다. 유사한 노이즈 수준에서 Recall은 Contextualization이 없으면 평균 4%, Graph Querying이 없으면 10% 감소한다. 주목할 점은 Graph 또는 Contextualization이 없는 변형(LAD-RAG w/o C & G)도 기존 기준선보다 우수하다는 점이다. 이러한 결과는 Symbolic 및 Graph 기반 메커니즘이 필수적이지만, 검색기의 상호 작용적 특성 또한 완전한 증거 집합을 구성하는 데 기여함을 보여준다.
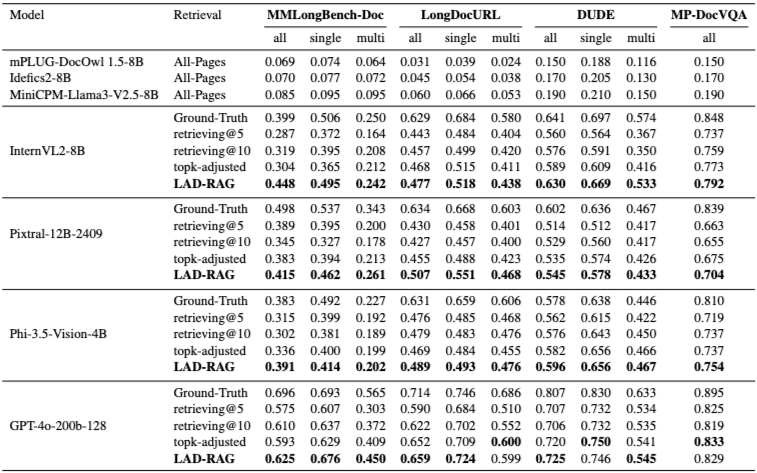
4.3 LAD-RAG’s End-to-End QA Gains
주요 기여는 검색이지만, LAD-RAG를 사용할 때 모든 모델과 벤치마크에서 다운스트림 QA 정확도에서 일관된 향상을 관찰한다. 결과는 Table 2에 나와 있다. InternVL2-8B, Phi-3.5-Vision과 같은 소형 모델과 GPT-4o-200B와 같은 대형 모델 모두에서, LAD-RAG는 모든 검색 기준선 및 검색 없이 전체 문서에 접근하는 모델보다 QA 정확도를 일관되게 향상시킨다. 이는 고정된 top-k 검색(k=5, 10) 및 topk-adjusted 설정(기준선이 우리 시스템과 동일한 수의 페이지를 검색)을 모두 능가한다. 이는 우리의 검색기가 더 관련성 높은 증거를 제공할 뿐만 아니라, 훨씬 적은 노이즈를 도입하여 더 높은 다운스트림 정확도로 직접 이어진다는 것을 보여준다. 더 어려운 예제 하위 집합을 구성하는 다중 페이지 질문에 초점을 맞추면, LAD-RAG는 네 가지 벤치마크 모두에서 일관된 이득을 보인다. top-k 기준선에 비해 평균 4점, 최대 18점까지 향상되며, top-k-adjusted 검색에 비해 평균 3점, 최대 11점 향상된다. 이는 LAD-RAG의 개선이 단순히 더 많은 페이지를 검색하는 것뿐만 아니라, 더 집중적이고 완전한 증거를 검색하는 데서 비롯됨을 나타낸다. 특히, 우리의 검색 성능은 모든 데이터셋에서 Ground-truth 증거를 사용하는 것에 접근하여, 특히 MMLongBench 및 LongDocURL과 같은 도전적인 벤치마크에서 5-8점 이내로 격차를 좁힌다.
4.4 Latency Analysis
LAD-RAG의 지연 시간을 분석한 결과, 추론 시 최소한의 오버헤드를 도입한다는 것을 발견한다. 그래프 구성은 수집 중 오프라인에서 한 번만 수행되며, 추론 시간 지연에 영향을 미치지 않는다. 추론 중, 우리의 에이전트 기반 검색기는 일반적으로 2-5회의 LLM 호출을 발행하며 (Figure 4), 이 중 97% 이상은 평균 100개 미만의 토큰을 생성한다 (Appendix F). 이러한 토큰은 미리 구축된 Symbolic Graph 및 Semantic Index에 대해 실행되는 검색 질의 역할을 하며, 둘 다 무시할 수 있는 런타임 비용을 발생시킨다. 전체적으로, 이는 LAD-RAG가 최소한의 추가 지연 시간으로 상당한 QA 이득을 달성함을 보여준다.
5 Related Work
5.1 Visually-rich Document Understanding
LVLM의 등장과 함께, 이러한 모델들은 특히 풍부한 시각적 콘텐츠를 포함하거나 여러 페이지에 걸쳐 있는 문서에 대한 문서 이해 작업에 점점 더 많이 적용되어 왔다. LLM의 추론 부담을 줄이고 응답 정확도를 향상시키기 위해 RAG가 지배적인 전략이 되어, 문맥을 문서의 가장 관련성 높은 부분으로 좁힌다. 최근 몇몇 연구들은 시각적으로 풍부한 문서에서 멀티모달, Cross-page evidence를 검색하는 문제를 다루었다. M3DocRAG와 MDocAgent는 텍스트 기반 및 이미지 기반 검색기를 특수 추론 에이전트와 결합하여 이러한 작업의 멀티모달 특성을 캡처한다. MM-RAG 및 RAPTOR는 수집 시점에 색인을 풍부하게 하여 Cross-page relationship을 모델링하기 위해 Semantic적으로 관련된 내용의 계층적 집계를 구성하여 검색 세분성을 향상시킨다. MoLoRAG는 추론 시점에 Semantic적으로 유사한 페이지를 탐색하여 증거를 확장한다. SimpleDoc은 LLM 피드백을 사용하여 증거를 반복적으로 정제하며, FRAG는 전체 문서를 통과하여 관련 페이지나 이미지를 선택하여 고정된 top-k 검색의 한계를 해결한다.
이러한 방법들은 멀티모달 검색을 발전시켰지만, Cross-page dependency 처리는 여전히 페이지 간에 Semantic적으로 유사한 내용을 캡처하는 데 크게 의존한다. 수집 파이프라인은 주로 임베딩 기반 표현에 의존하여 문서 구조의 Symbolic View를 잃으며, 그 결과 특정 질의의 검색 요구에 대한 적응성이 없다. LAD-RAG는 Local Content와 Global Layout Structure를 모두 캡처하는 Symbolic Document Graph를 도입하고, Neural 및 Symbolic Index 모두에 대해 동적으로 추론하는 질의 적응형 검색기를 결합하여 이러한 격차를 해소한다.
5.2 RAG Frameworks with Graph Integration
최근 RAG 프레임워크는 그래프를 통해 검색을 향상시켰다. 수집 시점에 여러 방법은 다중 세분성 검색을 지원하기 위해 주로 Semantic 유사성 또는 문서 섹션과 같은 High-level Layout Cues를 기반으로 계층적 그룹화를 구성한다. 그러나 이러한 구조는 미리 정의된 경계와 일치하지 않는 Ad hoc Query에 대한 유연성이 부족한 경우가 많다. 다른 접근 방식은 Entity-based Traversal을 사용하여 추론 시점에 그래프를 통합한다. 반복적인 그래프 기반 검색도 탐구되어 왔으며, 다중 문서 QA에서의 지식 그래프 프롬프트도 마찬가지이다. LAD-RAG는 Semantic 및 Layout 기반 관계를 모두 캡처하는 General-purpose Symbolic Graph를 구축함으로써 시각적으로 풍부한 문서의 고유한 도전을 해결한다. 추론 시점에 Costly Inference-time Traversal 없이 이 구조에 대한 동적, 질의 중심 검색을 수행한다. LAD-RAG는 문서 구조를 활용하여 Rigid top-k 제약 이상으로 관련 노드 그룹을 유연하게 검색함으로써, 페이지 간의 포괄적인 증거 수집을 가능하게 하고 QA 정확도에서 상당한 이득을 가져온다.
6 Conclusion
본 연구는 시각적으로 풍부한 문서 이해를 위한 레이아웃 인식 동적 RAG 프레임워크인 LAD-RAG를 소개한다. 문서 청크를 개별적으로 수집하고 Neural Index에만 의존하는 기존 RAG 파이프라인과 달리, LAD-RAG는 수집 단계에서 Symbolic Document Graph를 구축하여 Local Semantic과 Global Layout-driven Structure를 모두 캡처한다. 이 Symbolic Graph는 문서 요소에 대한 Neural Index와 함께 저장되며, 추론 시 LLM Agent가 각 질의의 특정 요구 사항에 따라 증거를 동적으로 추론하고 검색할 수 있도록 한다. MMLongBench-Doc, LongDocURL, DUDE, MP-DocVQA의 네 가지 도전적인 VRD 벤치마크에서 LAD-RAG는 검색 완전성을 향상시켜 어떤 top-k 튜닝 없이도 평균 90% 이상의 Perfect Recall을 달성하며, 강력한 텍스트 기반 및 이미지 기반 기준 검색기보다 유사한 노이즈 수준에서 Recall에서 최대 20%까지 우수한 성능을 보인다. 이러한 이득은 최소한의 추가 지연 시간으로 더 높은 다운스트림 QA 정확도로 이어진다. 우리의 결과는 레이아웃과 페이지 간 구조에 대한 추론의 중요성을 강조한다. LAD-RAG는 컨텍스트적, 멀티모달 이해를 요구하는 작업에서 검색을 위한 일반화 가능한 기반을 제공하며, 기업, 법률, 금융 및 과학 분야 전반에 걸쳐 광범위하게 적용 가능하다.
7 Limitations
LAD-RAG는 시각적으로 풍부한 문서 이해를 위한 RAG 파이프라인에서 검색 완전성과 정확성을 향상시키도록 설계되었다. 우리의 결과는 검색 품질과 다운스트림 QA 정확도 모두에서 일관된 이득을 보여주지만, 거의 완벽한 증거에도 불구하고 현재 LVLM은 검색된 콘텐츠를 완전히 활용하는 데 여전히 한계를 보인다. 본 연구는 QA 모델 자체의 추론 능력을 향상시키는 것을 목표로 하지 않는다. 대신, 우리의 기여는 수집 중 문서 모델링을 개선하고 해당 구조를 추론 시 활용하여 더 관련성 높고 완전한 증거를 검색하는 데 중점을 둔다. 따라서 이 논문의 범위는 검색 개선에 국한되며, 생성적 추론이나 답변 합성은 아니다. 본 프레임워크는 수집 중 문서 요소(예: 텍스트, 테이블, 그림)를 추출하고 구조화하기 위해 강력한 General-purpose LVLM에 의존한다. 수동 검사 결과, 이미지에서 텍스트 읽기 또는 테이블 및 그림 내용 요약과 같은 추출 작업이 대부분의 경우 올바르게 처리되었지만, 이러한 모델은 여전히 노이즈가 많은 입력, 복잡한 레이아웃 또는 저품질 시각 자료에 어려움을 겪을 수 있다. 이는 시스템 복잡성을 최소화하는 통합 모델 사용과 견고성을 높일 수 있지만 엔지니어링 오버헤드를 증가시키는 여러 전문 도구 통합 사이의 광범위한 Trade-off를 반영한다. 향후 연구에서는 필요한 경우 특정 문서 양식에 맞춰진 모듈형 대안을 탐색할 수 있다.
