
문서 이미지에 대한 시각 질의 응답(VQA)을 위한 새로운 데이터셋인 DocVQA를 제안한다. DocVQA는 문서 이미지에 대한 높은 수준의 이해를 통해 자연어 질문에 답하는 것을 목표로 하며, 기존의 정보 추출 중심 문서 분석 및 인식(DAR) 연구에 "목적 지향적" 관점을 도입한다. 답변을 위해서는 단순히 텍스트를 읽는 것을 넘어 문서의 레이아웃, 구조, 비텍스트 요소, 스타일 등 다양한 시각적 단서를 해석하는 것이 필수적이다.
서론
기존의 DAR 연구는 문자 인식, 테이블 추출, 키-값 쌍 추출 등 특정 정보 추출 작업에 중점을 두지만, 이러한 모듈식 접근 방식만으로는 문서 이미지에 대한 총체적인 이해를 달성하기 어렵다. DocVQA는 지능형 판독 시스템이 사람이 제기하는 정보 요청에 동적으로 응답하는 고수준 작업으로, 이를 통해 DAR 알고리즘이 문서 이미지를 조건부로 해석하도록 유도한다. 일반적인 VQA나 장면 텍스트 VQA와 달리, 문서 이미지는 암묵적인 통신 규칙과 고밀도의 의미론적 정보를 활용해야 하며, 답변은 미리 정의된 사전에서 나오는 것이 아니라 본질적으로 개방형이다.
관련 데이터셋 및 과제
문서 이미지 VQA는 기계 독해(MRC) 및 VQA 분야와 관련이 있다. MRC는 컴퓨터가 읽을 수 있는 텍스트 문맥에서 질문에 답하는 반면, DocVQA는 문서 이미지에서 답을 찾는다. 장면 텍스트 VQA 데이터셋(ST-VQA, TextVQA)은 실제 장면 텍스트 이해를 다루지만, DocVQA는 다양한 유형의 실제 문서 이미지에 초점을 맞춘다. 또한, 합성 데이터셋(DVQA, FigureQA)이나 특정 도메인(OCR-VQA)에 제한된 기존 VQA 데이터셋과 달리 DocVQA는 테이블, 양식, 그림 등 다양한 요소를 포함하는 광범위한 문서 유형을 포함한다.
DocVQA 데이터셋
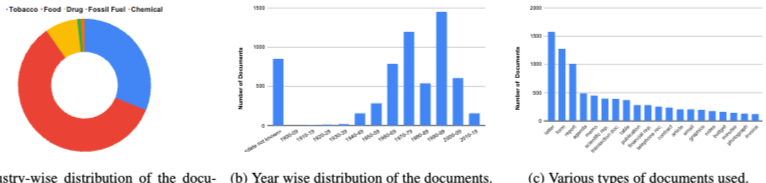
DocVQA는 12,767개의 다양한 문서 이미지에 대해 50,000개의 질문-답변 쌍으로 구성된다. 데이터셋은 훈련, 검증, 테스트 세트로 80-10-10 비율로 분할되며, 각각 39,463개, 5,349개, 5,188개의 질문을 포함한다.
3.1 데이터 수집
- 문서 이미지: UCSF Industry Documents Library에서 6,071개의 산업 문서 페이지를 선별했다. 이미지 품질 저하를 최소화하기 위해 바이너리화된 이미지를 피하고, 테이블, 양식, 목록, 그림이 포함된 페이지를 우선적으로 선택했다. 1900년에서 2018년 사이(주로 1960-2000년대)의 문서들로, 타자, 인쇄, 손글씨, 디지털 원본 텍스트를 포함한다.
- 질문 및 답변: 웹 기반 주석 도구를 사용하여 원격 작업자를 통해 3단계로 수집했다.
- 1단계 (질문-답변 수집): 작업자는 문서 이미지당 최대 10개의 질문-답변 쌍을 정의했다. 이미지에 있는 텍스트로 답할 수 있는 질문이어야 하며, 답변은 문서에서 그대로 추출되어야 한다(추출형 QA).
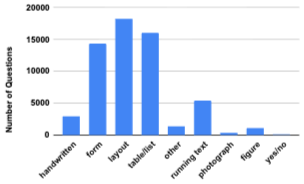
- 2단계 (데이터 검증): 1단계에서 정의된 질문에 대해 작업자가 답변을 입력하고, 하나 이상의 질문 유형을 할당했다(예: handwritten, form, layout, table/list, other, running text, photograph, figure, yes/no). 부적절하거나 모호한 질문은 플래그를 지정할 수 있었다.
- 3단계 (리뷰): 1단계와 2단계 답변이 일치하지 않는 질문은 저자들이 직접 검토하고 필요시 수정했다.
3.2 통계 및 분석
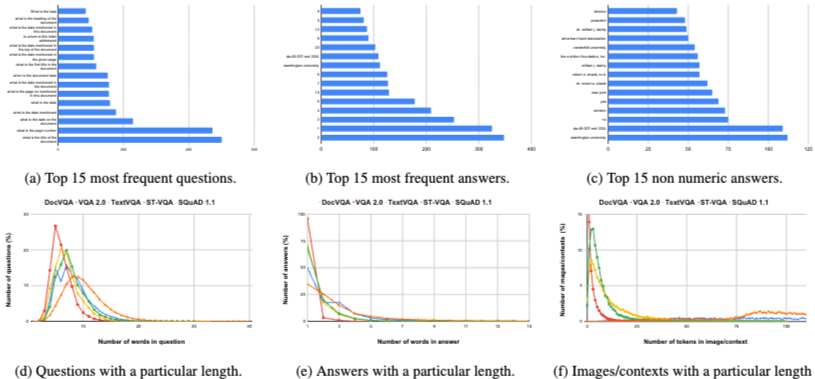
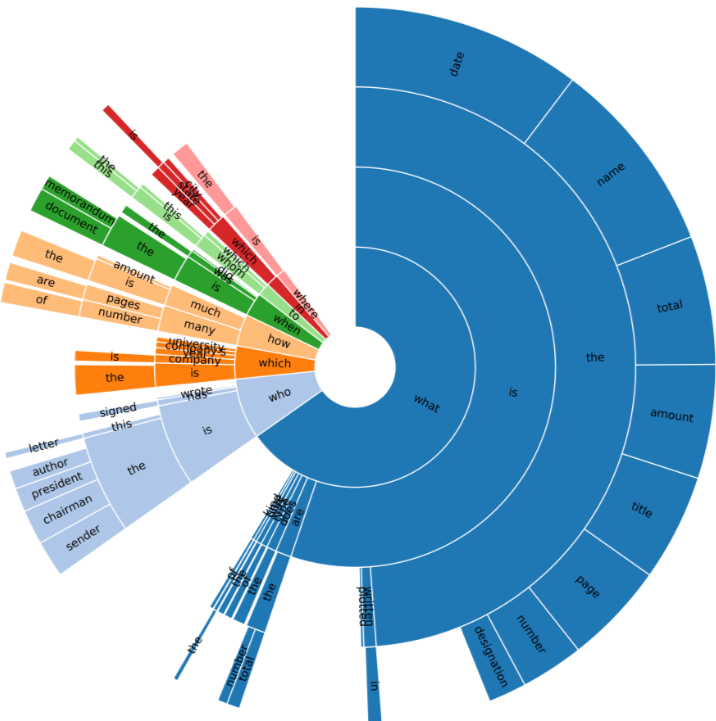
- DocVQA의 평균 질문 길이는 8.12단어로, 다른 VQA 데이터셋보다 길다. 70.72%의 질문이 고유하다.
- 평균 답변 길이는 2.17단어로, SQuAD 1.1과 유사하게 긴 답변의 비율이 높다. 63.2%의 답변이 고유하다. 가장 흔한 답변은 숫자 값이며, 그 다음으로는 사람, 기관, 장소의 고유 명사가 많다.
- 이미지당 OCR 토큰 수는 평균 182.75개로, SQuAD 1.1(117.23개)이나 다른 VQA 데이터셋(평균 13개 이하)보다 현저히 높다. 이는 문서 이미지의 높은 정보 밀도를 반영한다.
- 질문 유형은 답변이 근거하는 데이터 유형을 나타내며, 하나의 질문에 여러 유형이 할당될 수 있다.
4. 기준선 모델
DocVQA 데이터셋에 대한 성능 평가를 위해 휴리스틱 방법과 기존 VQA 및 독해 모델을 활용했다. 모든 실험에서 상용 OCR 애플리케이션으로 추출된 OCR 토큰을 사용한다.
4.1 휴리스틱 및 상한선
- 휴리스틱:
- Random answer: 훈련 세트의 답변 중 무작위 선택.
- Random OCR token: 주어진 문서 이미지의 OCR 토큰 중 무작위 선택.
- Longest OCR token: 문서에서 가장 긴 OCR 토큰 선택.
- Majority answer: 훈련 세트에서 가장 빈번한 답변 선택.
- 상한선:
- Vocab UB (Vocabulary Upper Bound): 훈련 세트에서 두 번 이상 나타나는 모든 답변으로 구성된 어휘집 내에서 정답을 예측할 수 있을 때의 성능.
- OCR substring UB: OCR 토큰 시퀀스에서 답변을 부분 문자열로 찾을 수 있을 때의 성능. OCR 토큰은 좌상단에서 우하단 순서로 직렬화된다.
- OCR subsequence UB: OCR 토큰 시퀀스에서 답변을 부분 시퀀스로 찾을 수 있을 때의 성능.
4.2 VQA 모델
이미지의 텍스트를 고려하는 기존 VQA 모델인 LoRRA [35]와 M4C [16]를 사용했다.
- LoRRA (Look, Read, Reason & Answer): 하향식/상향식 주의 메커니즘을 사용하며, OCR 토큰에 대한 추가 상향식 주의를 포함한다. 질문 토큰은 GloVe 임베딩 후 LSTM으로 인코딩된다. 시각적 특징은 ResNet-152 그리드 특징과 Faster R-CNN 바운딩 박스 제안에서 추출된다. OCR 토큰은 FastText 임베딩을 사용한다. 모델은 고정된 어휘집 또는 이미지 내 OCR 토큰 목록에서 답변을 선택하는 포인터 메커니즘을 사용한다. 단, 두 개 이상의 OCR 토큰 조합은 출력할 수 없다.
- M4C (Multimodal Multi-Copy Mesh): 멀티모달 트랜스포머와 반복적인 답변 예측 모듈을 사용한다. 질문 토큰은 BERT 모델로 임베딩된다. 이미지는 Faster R-CNN으로 감지된 객체의 외형 특징과 바운딩 박스 좌표로 표현된다. OCR 토큰은 FastText, 외형 특징, PHOC 표현, 바운딩 박스 좌표로 표현된다. 이러한 특징들은 공통 임베딩 공간으로 투영된 후 트랜스포머 레이어를 거쳐 다중-헤드 자기-주의 메커니즘으로 처리된다. 답변은 자율회귀 방식으로 반복적으로 디코딩되며, 이미지 내 OCR 토큰 또는 가장 흔한 답변 단어로 구성된 고정 어휘집에서 선택된다.
DocVQA 문서 이미지의 텍스트 토큰 수가 많다는 점을 고려하여 LoRRA와 M4C 모두 더 큰 동적 어휘집(더 많은 OCR 토큰 고려)을 시도했으며, 고정 어휘집을 사용하지 않는 변형도 평가했다. 또한, 문서 이미지에 시각적 객체 개념이 직접 적용되지 않으므로, 객체 특징을 생략한 LoRRA 및 M4C 변형도 실험했다.
4.3 독해 모델
추출형 질의 응답/독해 모델로서 BERT [9]를 사용했다. BERT는 트랜스포머 기반의 사전 훈련된 언어 표현 모델로, 질문-답변을 위해 시작 및 종료 인덱스를 예측하는 출력 레이어를 추가하여 미세 조정한다. DocVQA의 경우, 문서 이미지에서 인식된 OCR 토큰들을 좌상단에서 우하단 순서로 하나의 문자열로 직렬화하여 SQuAD 스타일의 컨텍스트로 구성하고, 답변은 이 직렬화된 문자열 내의 첫 번째 일치하는 부분 문자열로 근사했다.
bert-base-uncased, bert-large-uncased-whole-word-masking, bert-large-uncased-whole-word-masking-finetuned-squad (각각 bert-base, bert-large, bert-large-squad로 약칭) 모델을 사용했다. bert-large-squad는 SQuAD 1.1에서 추가 미세 조정된 모델이다.
5. 실험
5.1 평가 지표
- ANLS (Average Normalized Levenshtein Similarity): ST-VQA 평가를 위해 제안된 지표로, 예측된 답변과 정답 간의 Levenshtein 거리를 기반으로 유사도를 측정한다. OCR 오류로 인한 사소한 불일치에 대한 페널티를 줄인다.
- Accuracy: 예측된 답변이 질문의 정답 중 하나와 정확히 일치하는 질문의 비율이다.
5.2 실험 설정
- 인간 성능: 기관의 자원봉사자들의 도움을 받아 테스트 세트의 모든 질문에 대한 답변을 수집했다.
- OCR 토큰: 모든 휴리스틱 및 훈련된 기준선 모델에 상용 OCR 애플리케이션으로 추출된 OCR 토큰을 사용했다.
- LoRRA 및 M4C: MMF 프레임워크 [34]의 공식 구현을 사용했으며, 훈련 설정 및 하이퍼파라미터는 원본 논문과 동일하게 적용했다.
- BERT:
bert-base는 2개의 Nvidia GeForce 1080 Ti GPU에서 2 에포크, 배치 크기 32, 학습률 로 미세 조정했다.bert-large및bert-large-squad는 4개의 GPU에서 6 에포크, 배치 크기 8, 학습률 로 미세 조정했다.
5.3 결과
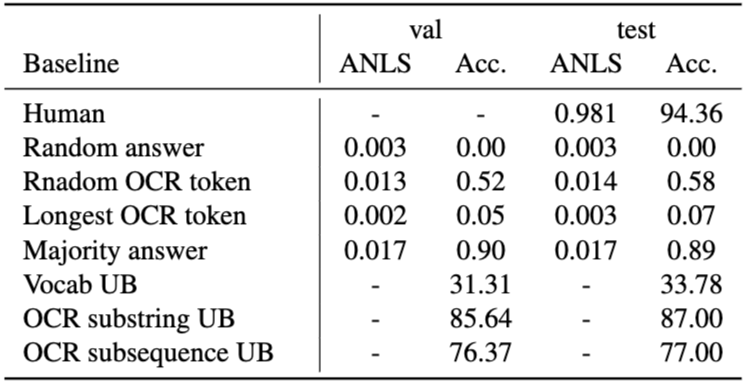
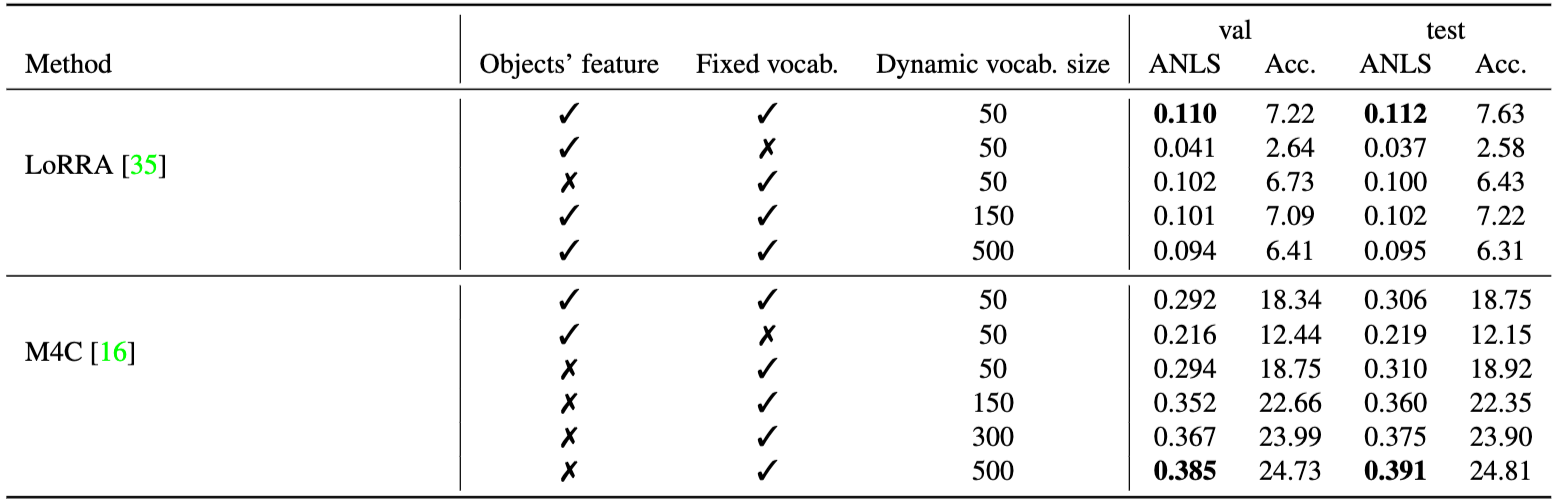
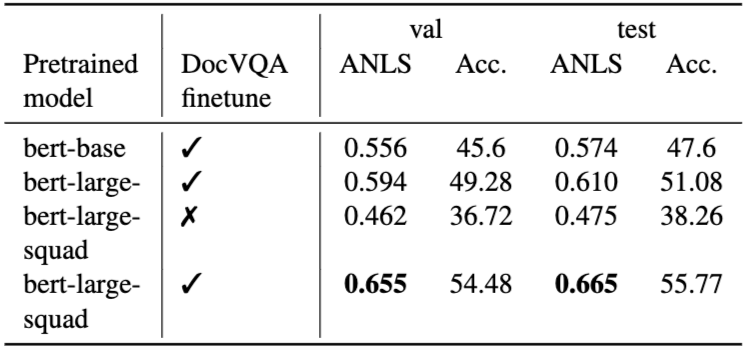
- 휴리스틱 및 상한선:
- 휴리스틱 모델들은 1% 미만의 정확도를 보이며 성능이 매우 낮았다.
OCR substring UB는 85% 이상의 정확도를 보였지만, 부정확한 부분 문자열 매치 가능성이 있다.OCR subsequence UB는 76% 내외의 정확도를 보였다.
- VQA 모델 (LoRRA, M4C):
- LoRRA: 원본 설정이 가장 좋은 결과를 보였다. 고정 어휘집을 사용하지 않거나 동적 어휘집 크기를 늘려도 성능이 급격히 저하되었다.
- M4C: 동적 어휘집 크기를 늘리면(50에서 500으로) ANLS가 약 50% 향상되었다. 객체 특징을 생략한 설정이 원본 설정보다 약간 더 나은 성능을 보였다.
- BERT 모델:
- 모든 BERT 모델이 M4C를 사용한 VQA 기준선보다 우수한 성능을 보였다.
- DocVQA에서 미세 조정된
bert-large-squad모델이 모든 기준선 중에서 가장 좋은 성능을 보였으며, 55% 이상의 질문에 대해 정답과 정확히 일치했다.
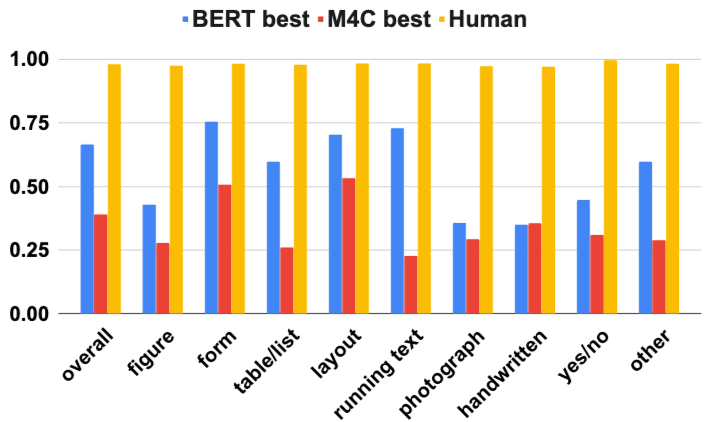
- 질문 유형별 성능:
- 인간 성능은 질문 유형에 관계없이 균일했지만, 모델 성능은 유형별로 달랐다. 특히, 그림(figure)이나 사진(photograph)에 있는 텍스트를 이해하는 데 모델 성능 개선이 필요하며, 손글씨 인식에도 더 나은 모델이 요구된다.
- 정성적 분석 결과, M4C는
layout유형 질문(그림의 로고/팩에 있는 텍스트 읽기)에서 BERT보다 뛰어났지만, BERT는 테이블이나 일반 독해 영역을 넘어서는 질문에서도 좋은 성능을 보였다. 모델들은 특정 질문에서 일관성 없는 결과를 보이기도 했는데, 이는 답변 뒤에 적절한 추론이 부족함을 시사한다. OCR 오류는 모델의 정답 능력을 저해하는 요인으로 작용했다.
6. 결론
이 논문은 문서 이미지 분석 및 인식 연구에 "목적 지향적" 접근 방식을 고취하기 위해 새로운 DocVQA 데이터셋과 관련 VQA 과제를 소개한다. 제시된 기준선과 초기 결과는 문서 이미지에 대한 질문에 답하기 위해 시각적 단서와 텍스트 단서의 동시 사용이 중요함을 보여준다. 이는 하위 수준의 단서(텍스트, 레이아웃, 배열)와 상위 수준의 목표(목적, 관계, 도메인 지식)를 활용하여 실제 문제 해결을 위한 방법을 개발하는 데 기여할 수 있다.
