Language models can learn implicit multi-hop reasoning, but only if they have lots of training data
Paper Review
언어 모델이 implicit multi-hop reasoning을 학습하는 능력과 그에 필요한 자원을 조사한다. 특히 GPT2-style 언어 모델을 제어된 k-hop reasoning 데이터셋(k = 2, 3, 4)으로 학습하여 이 능력을 탐구한다.
서론
implicit reasoning은 언어 모델이 chain-of-thought 없이 단일 forward pass로 multi-hop reasoning task를 해결하는 능력이다. 기존 연구는 주로 2-hop task에 집중하여 LM이 개별 사실을 결합하여 implicit reasoning을 학습할 수 있음을 보여주었다. 이 논문은 이러한 능력이 k > 2인 경우에도 확장될 수 있는지 연구한다.
이 연구는 세 가지 핵심 질문에 답한다:
1. LM이 implicit k-hop reasoning을 학습할 수 있는지, 있다면 어떤 조건에서 가능한가?
2. 모델이 k-hop reasoning을 내부적으로 어떻게 수행하는가?
3. k-hop reasoning에 필요한 막대한 데이터 예산을 어떻게 줄일 수 있는가?
주요 발견은 LM이 k-hop reasoning을 학습할 수 있지만, 학습에 필요한 데이터는 k에 대해 기하급수적으로 증가하고, 필요한 Transformer layer 수는 k에 대해 선형적으로 증가한다는 점이다. 또한, curriculum learning이 데이터 요구 사항을 완화할 수 있지만 완전히 제거하지는 못한다는 점을 보여준다.
관련 연구
implicit reasoning 관련 연구는 크게 knowledge-based reasoning과 mathematical reasoning 두 가지로 나뉜다. 이 논문은 knowledge-based reasoning에 중점을 두며, GPT2-style LM이 training data 요구 사항을 충족하면 multi-hop reasoning이 가능함을 보여준다. 대부분의 이전 연구가 기존 대규모 LM으로 knowledge-based reasoning을 탐구한 것과 달리, 이 연구는 synthetic dataset으로 모델을 훈련하여 데이터 및 모델과 같은 특정 측면에 모델 동작을 정확하게 귀속시킬 수 있다.
Memorization과 generalization 측면에서는 grokking 현상과 관련이 있다. 이전 연구는 학습 과정에서 memorized solution과 generalizable solution이 모두 존재하며, training set 크기를 늘리면 generalizable solution을 장려한다고 시사한다. 이 논문은 training data 크기가 task 난이도에 따라 기하급수적으로 증가해야 한다고 주장하며, 이는 복잡한 implicit reasoning task에서 LLM이 실패하는 가능한 설명이 된다.
데이터셋
이 연구는 k = 2, 3, 4에 대해 생성된 k-hop reasoning dataset을 사용한다.
Task description: knowledge-based multi-hop reasoning은 사실과 쿼리로 구성된다. 사실은 (e, r, e') 형태의 triple이며, 관계 r은 함수 r(e) -> e'로 작용한다. k-hop query는 k개의 함수 합성 에 해당한다. 중간 엔티티를 bridge entity라고 부른다.
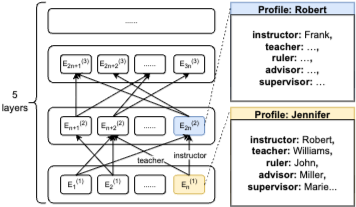
데이터셋 형식은 두 가지 구성 요소를 포함한다:
1. Entity profile: 특정 엔티티에 대한 모든 사실을 인코딩한다.
2. Reasoning questions: 자연어 쿼리로 사실의 합성을 묻는다 (예: "Who is the teacher of the instructor of Jennifer? \n Answer: ").
모델이 모든 entity profile에 접근할 수 있도록 training set에는 모든 profile과 무작위로 선택된 reasoning question이 포함되며, held-out reasoning question은 test set으로 사용된다.
두 가지 데이터셋 변형이 생성되었다: k-hoplarge (|E|=500, |R|=20)와 k-hopsmall (|E|=250, |R|=10).
데이터 생성:
- Profile sampling: 엔티티 이름을 5개의 계층적 layer로 샘플링하여 나눈다. 각 엔티티는 상위 layer의 |R|개 엔티티와 관계를 통해 연결된다. 이 구조는 k ∈ {2, 3, 4} 관계의 합성이 잘 정의된 대상 엔티티로 이어지도록 보장한다.
- Profile and question generation: 각 사실 (e, r, e')는 자연어 문장 템플릿(예: "{subj}'s {relation} is {obj}")로 매핑된다. Reasoning question은 계층 구조의 최하위 layer에서 엔티티를 샘플링하고 k개의 관계를 재귀적으로 탐색하여 올바른 답을 식별하여 생성된다.
LM은 k-hop reasoning을 학습할 수 있지만, 데이터 비용이 많이 든다
실험 설정:
- 모델: GPT-2 smallest architecture (12 transformer layers, 12 attention heads, 768 embedding dim). 기존 positional embeddings 대신 Rotary Position Embedding (RoPE)를 사용했다. GPT-2 tokenizer를 사용하고 모든 가능한 entity name을 포함하도록 vocabulary를 확장했다. causal language modeling loss로 학습한다.
- 훈련: 20k steps (4-hoplarge는 40k), 1k warm-up steps가 있는 cosine learning rate scheduler를 사용했다. 각 실험은 3번 반복되었다.
- 데이터셋: 섹션 3에서 소개된 k-hopsmall 및 k-hoplarge 데이터셋을 사용한다. 2-hop task의 경우 가능한 모든 reasoning question 중 일부를 샘플링하여 training set으로 사용한다. 3-hop 및 4-hop task의 경우, 2-hop training set의 기본 데이터 예산(bg)을 기준으로 {×1, ×2, ×5, ×10, ×20, ×50, ×100} 비율로 training data를 점진적으로 늘린다. Test set은 3,000개의 무작위 샘플링된 held-out instance로 구성된다.
- 평가: 모델에 answer token("Answer: ")까지의 prompt를 제공하고 생성된 token의 정확도를 gold answer와 비교하여 평가한다. Greedy decoding을 사용한다.
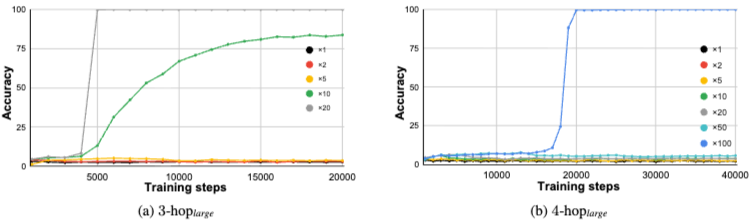
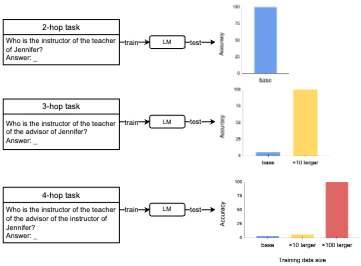
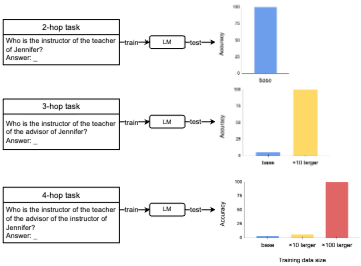
결과:
GPT-2 모델은 충분히 큰 training data budget이 주어지면 2-hop 뿐만 아니라 3-hop 및 4-hop task에서도 100% 정확도를 달성할 수 있다. 이는 모델이 input-output 쌍만으로 underlying reasoning process를 학습할 수 있음을 시사한다.
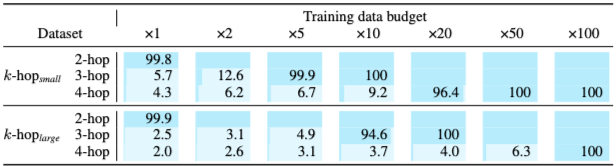
그러나 데이터 요구 사항은 k에 따라 기하급수적으로 증가한다. 모델이 task를 성공적으로 학습했다고 판단하는 기준은 test accuracy가 80%를 초과하는 경우이다. k-hopsmall 데이터셋의 경우 3-hop task에 최소 ×5 budget, 4-hop task에 최소 ×20 budget이 필요하다. k-hoplarge 데이터셋의 경우 3-hop task에 ×10, 4-hop task에 ×100 budget이 필요하다. 이는 training data budget이 k 값 증가에 따라 기하급수적으로 증가함을 시사한다.
더 큰 training budget은 더 높은 정확도를 가져올 뿐만 아니라 모델 수렴을 가속화한다.
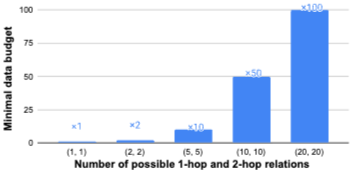
데이터가 많이 필요한 이유:
4-hoplarge 데이터셋에 대한 case study를 수행하여 1-hop 및 2-hop 관계의 수를 변화시키고 3-hop 및 4-hop 위치의 관계 수는 고정했다. 1-hop 및 2-hop 관계의 수가 단일 관계로 제한될 때 모델은 기본 데이터 예산으로 4-hop task를 성공적으로 학습할 수 있었다. 그러나 관계 수가 증가함에 따라 필요한 데이터 예산은 빠르게 증가했다. 이는 k-hop reasoning task에서 데이터 비효율성의 주요 원인이 개별 사실의 수가 아니라 관계 조합의 기하급수적인 증가임을 시사한다.
LM은 layer-wise lookup을 통해 추론하며, 깊이 비용이 발생한다
이 섹션에서는 모델의 내부 추론 프로세스를 조사하기 위해 probing과 causal intervention 두 가지 실험을 설계했다. 강력한 성능을 보이는 4-hoplarge ×100 budget으로 학습된 모델을 선택했다.
실험 설정:
- Probing: hidden representation에 중간 bridge entity에 대한 정보가 인코딩되어 있는지 평가하기 위해 probing task를 사용한다. 모델 파라미터는 고정하고 hidden state 위에 선형 probe classifier를 훈련하여 해당 bridge entity를 예측한다. Probe는 모든 Transformer layer와 prompt의 모든 token에 대해 훈련된다.
- Causal intervention: activation patching (Vig et al., 2020; Meng et al., 2022)을 사용하여 모델이 최종 답을 생성하기 위해 실제로 이 정보에 의존하는지 조사한다. residual stream (Transformer block의 residual layer 출력)을 특정 layer 와 prompt token 에서 교체하고, 정답의 출력 확률 변화를 측정한다. causal effect는 로 정의된다. 1-hop, 2-hop, 3-hop, 4-hop의 4가지 유형의 corrupted run을 정의하여 특정 i-hop entity를 방해하는 효과를 측정한다.
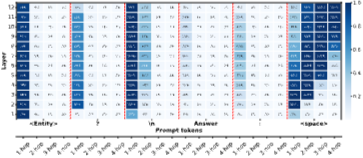
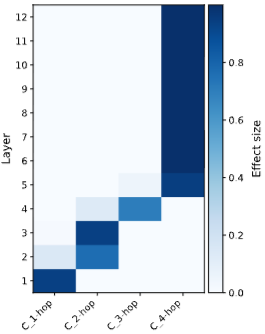
결과:
- Bridge entity는 마지막 token 위치에 인코딩된다: Figure 6의 probing 결과는 마지막 input token의 hidden representation이 최종 답을 예측하는 데 필요한 모든 bridge entity에 대한 정보를 인코딩함을 보여준다. 다른 token 위치에서는 probe classifier의 정확도가 낮아 추론 과정이 최종 답 생성 직전의 위치에서 집중적으로 발생함을 시사한다.
- 출력 예측은 bridge entity 정보에 의존한다: Figure 7의 causal effect 결과는 모델이 layer-wise lookup 방식으로 추론 과정을 구성하며, 얕은 layer는 low-hop entity를, 깊은 layer는 high-hop entity를 처리함을 보여준다. 이는 모델이 multi-hop reasoning을 수행하기 위해 bridge entity 정보를 활용함을 확인시켜 준다.
이론적 분석:
LM이 k-hop task를 layer-wise lookup 방식으로 해결한다는 점은 Transformer가 추론 단계 수에 비례하는 깊이를 필요로 할 수 있음을 시사한다.
Theorem 5.1: 인과 Transformer가 k-hop reasoning을 수행할 때, attention pattern이 쿼리 e에 의존하지 않는 경우, layer 수 L은 k에 선형적으로 비례한다:
여기서 p는 정밀도(bits of precision), d는 hidden units, H는 heads, L은 layers이다.
이 정리는 너비-깊이 tradeoff를 표현하며, 모델 내에서 k가 증가함에 따라 더 많은 layer가 hop-by-hop 검색에 관여해야 함을 예측한다. 이는 실험 결과와 일치한다.
Curriculum learning은 데이터 요구 사항을 완화하지만 해결하지는 못한다
실험 설정:
데이터 예산 문제를 개선하기 위한 훈련 전략을 연구한다.
- Mixed learning: lower-hop과 k-hop task의 reasoning question을 결합하여 training set을 구성한다. 예를 들어, 4-hop training set에는 2-hop, 3-hop, 4-hop question이 혼합된다. lower-hop 데이터 양은 고정하고 k-hop training budget만 조절한다.
- Curriculum learning: 훈련은 여러 단계로 나뉘며, 각 단계에서 점진적으로 더 어려운 reasoning task가 도입된다. k-hop task의 경우 k-1단계로 진행된다 (예: 2-hop 질문, 그 다음 2-hop+3-hop, 등). 총 훈련 스텝은 두 전략 간에 동일하게 유지된다.
- Test set: shortcut solution을 피하기 위해 rejection sampling을 사용하여 겹치는 부분이 없도록 test set을 생성한다.
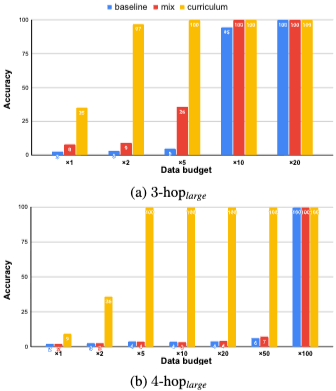
결과:
Figure 8은 k-hoplarge에 대한 결과를 보여준다.
Curriculum learning은 필요한 데이터 예산을 크게 줄인다. 예를 들어, 4-hop task에서 baseline은 ×100 budget이 필요했지만, curriculum learning은 ×5 budget으로 완벽한 정확도를 달성했다. 반면, 단순히 모든 가용한 데이터를 혼합하는 mixed learning은 미미한 개선만을 제공했다. 이는 쉬운 reasoning task를 어려운 task 이전에 제시하는 것이 데이터 효율성을 향상시키는 매우 효과적인 전략임을 보여준다.
Curriculum learning은 회로를 점진적으로 구축한다. 이는 훈련 초기에 lower-hop entity를 검색하는 메커니즘이 나타나고, 이후 단계에서 이러한 확립된 회로를 기반으로 더 복잡한 reasoning task를 학습한다는 점에서 기인한다. Baseline 모델이 k-hop reasoning을 위한 전체 회로를 한 번에 구축해야 하는 반면, curriculum learning은 1-hop 회로가 얕은 layer에 먼저 나타나고, 이후 단계에서 2-hop 및 3-hop entity에 대한 회로가 그 위에 개발되도록 한다.
그러나 curriculum learning도 데이터 증가 문제를 완전히 해결하지는 못한다. 예를 들어, 3-hop task에 ×2 budget, 4-hop task에 ×5 budget이 필요하며, 이는 LM의 implicit reasoning에 대한 k-hop의 어려움을 나타낸다.
결론
이 연구는 언어 모델이 implicit multi-hop reasoning을 학습할 수 있는지에 대해 통제된 k-hop reasoning 데이터셋과 GPT2-style 언어 모델을 사용하여 깊이 있는 분석을 제공한다. LM은 intermediate bridge entity를 layer-by-layer로 순차적으로 검색함으로써 k-hop reasoning을 학습할 수 있음을 입증했다. 그러나 이 능력은 k가 증가함에 따라 training data budget이 기하급수적으로 증가하고, 모델 깊이가 선형적으로 증가해야 하는 비용을 수반한다. 또한, curriculum learning이 데이터 예산 증가를 완화하지만, 증가 추세를 완전히 제거하지는 못한다. 이는 implicit reasoning에서 LM의 잠재력과 한계, 그리고 task 복잡성, 데이터 요구 사항, 모델 깊이 간의 내재된 trade-off를 포괄적으로 보여준다.
제한 사항
이 연구는 미리 정의된 템플릿을 기반으로 생성된 synthetic dataset을 사용한 implicit reasoning task에 국한된다. 현실적인 데이터셋에 동일한 분석을 적용하는 것은 복잡한 multi-hop 질문(예: 4-hop 질문)과 해당 사실을 수집하는 어려움 때문에 도전적이다. 또한 계산 예산 제약으로 인해 k < 5인 k-hop task로 실험을 제한했다.
주로 무작위로 초기화된 소규모 LM (GPT-2 small)에 의존하지만, pretrained 모델 (예: pretrained GPT-2)과 더 큰 모델 (GPT-2 medium 및 large)에서도 데이터 예산 문제가 지속됨을 관찰했다. 그러나 더 큰 파라미터 크기의 모델로는 분석을 확장하지 않았다.
