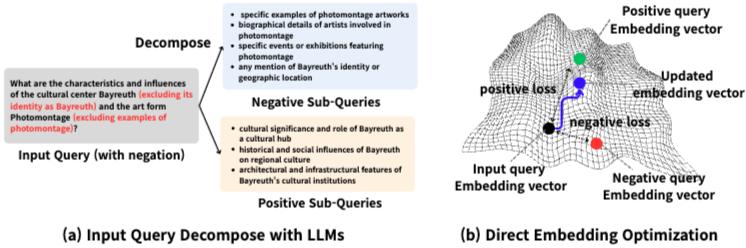
이 논문은 DEO(Direct Embedding Optimization)를 제안하며, DEO는 훈련 과정 없이(training-free) 부정(negation) 및 제외(exclusion) 질의에 대한 검색 성능을 향상시키는 방법론이다. 기존의 검색 방법론들은 대규모 언어 모델(LLM)과 검색 증강 생성(RAG)의 발전에도 불구하고 부정 또는 제외와 관련된 질의 처리에서 한계를 보였다. 이를 해결하기 위한 기존 접근 방식들은 임베딩 모델의 미세 조정(fine-tuning)이나 어댑터 기반(adaptor-based) 접근 방식을 사용했지만, 이는 상당한 컴퓨팅 자원, 대규모 데이터셋, 긴 훈련 시간을 필요로 하여 자원 제약이 있는 환경에서의 적용을 어렵게 했다. 또한, 이러한 방식들은 때때로 검색 성능을 저하시키거나 명확한 제어 가능성을 제공하지 못했다. DEO는 이러한 제약 없이 사용자의 의도를 더 정확하게 포착하는 검색 방법을 제시한다.
1. 서론
최근 LLM과 RAG의 발전으로 사용자 의도에 부합하는 응답을 생성하는 시스템이 가능해졌다. 그러나 실제 질의에는 종종 부정이나 제외의 개념이 포함되어 있어, 사용자의 의도를 정확하게 반영하는 콘텐츠를 검색하는 데 어려움이 있다. 기존 미세 조정 기반 접근 방식은 자원 집약적이고 제어 가능성이 낮으며, 부정 질의 처리에서 성능 저하를 일으킬 수 있다. NUDGE와 같은 임베딩 미세 조정 방법도 여전히 대규모 데이터셋과 GPU 자원이 필요하다. 이에 DEO는 미세 조정 없이도 효과적인 접근 방식을 제안한다. DEO는 사용자 질의를 긍정 및 부정 하위 질의로 분해한 다음, 대비 손실(contrastive loss)을 사용하여 원래 질의 임베딩을 최적화한다. 이를 통해 긍정 임베딩에는 가까워지고 부정 임베딩에서는 멀어지도록 하여 부정 및 제외를 포함하는 사용자 의도를 더 잘 나타내는 임베딩을 생성한다. 실험 결과, NegConstraint 벤치마크에서 MAP를 0.6299에서 0.7327로, nDCG@10을 0.7139에서 0.7877로 향상시켰다. 다중 모달 검색 벤치마크인 COCO-Neg에서는 OpenAI CLIP의 Recall@5를 0.4792에서 0.5392로 높였다. 이러한 결과는 DEO가 실제 환경에서 부정 및 제외 질의에 효과적임을 입증한다.
2. 관련 연구
- Dense Retrieval: 질의와 문서를 저차원 연속 임베딩으로 인코딩하여 의미론적 유사성을 포착하는 방식이다. 훈련 전략, 증류(distillation), 사전 훈련(pre-training)을 통해 성능이 향상되었지만, 부정 및 제외 질의 처리에 대한 연구는 상대적으로 미흡하다.
- Embedding Control and Fine-tuning Alternatives: 전체 모델 미세 조정 외에 임베딩 공간을 직접 제어하거나 정제하는 방법들이 연구되었다. 그러나 이들 역시 상당한 데이터셋과 GPU 자원을 요구하여 자원 제약 환경에서는 적용이 어렵다.
- Negation- and Exclusion-aware Retrieval: 부정 또는 제외 질의는 포함 및 제외 의미론을 명확히 구분해야 하지만, 기존 검색기는 이를 잘 포착하지 못한다. 미세 조정이나 태스크별 정규화(regularization)를 통해 부정에 대한 민감도를 높이려는 시도가 있었으나, 계산 비용이 크고 제어 가능성이 제한적이다. LLM을 활용하여 질의를 의미적으로 일관된 하위 질의로 분해하는 방식이 대안으로 제시되었다.
- Negation Robustness in Multimodal Retrieval: CLIP과 같은 비전-언어 검색기는 강력한 제로샷 성능을 보이지만, 부정 현상(예: 속성 부정, 부재, 관계 부정)에는 취약하다. NegBench는 이러한 한계를 평가하며, 기존 모델들이 긍정 및 부정 문장을 구별하는 데 어려움을 겪음을 확인했다. DEO는 이러한 문제에 대한 강건성을 제공한다.
3. 방법론
DEO는 크게 두 단계로 구성된다. 첫째, LLM을 사용하여 사용자 질의를 긍정 및 부정 하위 질의로 분해한다. 둘째, 대비 손실을 사용하여 입력 질의의 임베딩 공간을 직접 최적화한다.
3.1 질의 분해 (Query Decomposition)
DEO는 LLM을 프롬프트 기반 설정(prompt-based setting)에서 사용하여 입력 질의를 의미적으로 분석하고 부정 또는 제외 의도를 명시적으로 포착한다. LLM은 원래 질의를 구조화된 긍정 하위 질의 ()와 부정 하위 질의 ()로 분해한다. 예를 들어, "What are the characteristics and influences of the cultural center Bayreuth (excluding its identity as Bayreuth) and the art form Photomontage (excluding examples of photomontage)?"와 같은 질의는 긍정 하위 질의(예: "cultural significance and role of Bayreuth as a cultural hub")와 부정 하위 질의(예: "specific examples of photomontage artworks", "any mention of Bayreuth's identity or geographic location")로 분해된다. 이러한 분해는 검색에 필요한 요소와 제외되어야 할 제약 조건을 명확히 구분하여 사용자의 의도를 보다 정확하게 반영한다.
3.2 직접 임베딩 최적화 (Direct Embedding Optimization)
DEO는 추론 시(inference time) 인코더를 고정한 상태에서 입력 질의의 임베딩을 직접 최적화한다.
주어진 질의 에 대한 원래 임베딩은 이다.
분해된 긍정 하위 질의 와 부정 하위 질의 의 임베딩은 각각 와 이다.
학습 가능한 질의 임베딩 는 원래 임베딩 로 초기화된다: .
최적화 목표는 세 가지 구성 요소로 이루어진 손실 함수를 최소화하는 것이다.
- 긍정 하위 질의에 대한 매력 항(attraction term): 를 긍정 임베딩 에 가깝게 당긴다.
- 부정 하위 질의에 대한 반발 항(repulsion term): 를 부정 임베딩 에서 멀리 밀어낸다.
- 원래 질의에 대한 일관성 항(consistency term): 가 원래 임베딩 의 의미를 보존하도록 한다.
손실 함수는 다음과 같이 정의된다:
여기서 , , 는 각각 긍정 매력, 부정 반발, 일관성 정규화의 강도를 제어하는 하이퍼파라미터이다.
이 손실 함수는 고정된 수의 단계 동안 경사 기반 최적화기(Adam)를 사용하여 최소화되며, 인코더 파라미터는 변경되지 않는다. 최적화된 임베딩 는 최종 검색 표현으로 사용된다.
3.3 최적화된 임베딩을 이용한 검색 (Retrieval with Optimized Embeddings)
최적화된 임베딩 를 사용하여 검색을 수행한다. 와 값을 조정하여 검색 동작을 제어할 수 있다. DEO는 모델에 구애받지 않으며(model-agnostic), CLIP과 같은 다중 모달 인코더에도 적용 가능하여 추가 미세 조정 없이도 효과적인 다중 모달 검색을 가능하게 한다.
4. 실험
4.1 실험 설정
- 데이터셋 및 측정 지표: 부정 인식 검색을 위해 NegConstraint 및 NevIR 데이터셋을 사용한다. NegConstraint는 nDCG@10과 MAP@100으로, NevIR는 Pairwise 지표로 평가한다. 텍스트-이미지 부정 인식 검색을 위해 COCO-Neg (NegBench)를 사용하며 Recall@5로 평가한다.
- 기준 모델 (Baselines): 텍스트 검색에는 BGE-M3, BGE-large-en-v1.5, BGE-small-en-v1.5를, 텍스트-이미지 검색에는 OpenAI CLIP, CLIP-laion400m, CLIP-datacomp, NegCLIP을 사용한다.
- 구현 세부 사항: 모든 임베딩 모델에 대해 [CLS] 토큰 표현을 사용하고, FAISS 라이브러리를 사용하며, 검색을 위해 코사인 유사도(cosine similarity)를 계산한다. 질의 분해에는 OpenAI의 GPT-4.1-nano를 사용한다 (온도 0.1). 텍스트 전용 데이터셋에서는 로 설정하고 20단계 최적화를 수행한다. 다중 모달 데이터셋에서는 로 설정한다.
4.2 주요 결과
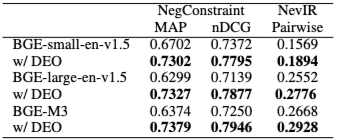
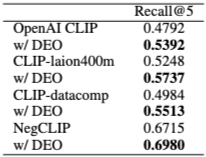
4.2.1 부정 벤치마크 (텍스트)
DEO는 NegConstraint와 NevIR 벤치마크에서 모든 BGE 변형 모델의 성능을 일관되게 향상시킨다. NegConstraint에서 BGE-large-en-v1.5는 DEO 적용 후 MAP가 +0.1028 (16.32%), nDCG@10이 +0.0738 (10.34%) 증가한다. NevIR의 Pairwise 점수도 BGE-small-en-v1.5에서 0.1569에서 0.1894로, BGE-large-en-v1.5에서 0.2552에서 0.2776으로, BGE-M3에서 0.2668에서 0.2928로 향상된다. 이는 DEO가 부정 제약 조건 하에서 더 나은 검색을 가능하게 함을 보여준다.
4.2.2 텍스트-이미지 검색을 위한 부정 벤치마크 (다중 모달)
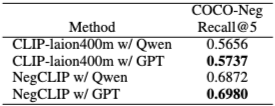
DEO는 COCO-Neg 데이터셋에서 모든 CLIP 기반 모델의 Recall@5를 일관되게 향상시킨다. OpenAI CLIP은 가장 큰 폭으로 6.00% 증가하고, CLIP-Datacomp과 CLIP-laion400m도 각각 5.29%와 4.89% 향상된다. 부정 인식 모델인 NegCLIP도 0.6715에서 0.6980으로 향상되어, DEO가 기존 부정 인식 모델에도 추가적인 이점을 제공함을 확인한다. 이는 DEO가 다중 모달 검색 설정에도 효과적으로 일반화됨을 증명한다.
4.3 어블레이션 연구 (Ablation Study)
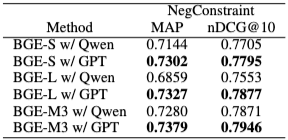
4.3.1 다른 LLM의 효과
질의 분해 능력에 따른 성능 변화를 분석하기 위해 GPT-4.1-nano와 Qwen2.5-1.5B-Instruct를 비교했다. GPT-4.1-nano가 모든 임베딩 모델과 데이터셋에서 Qwen2.5-1.5B-Instruct보다 consistently 우수한 성능을 보였다. 이는 더 큰 LLM이 더 정밀한 질의 분해를 수행하기 때문으로 추정된다. 그러나 Qwen2.5-1.5B-Instruct를 사용하더라도 DEO는 기준 모델 대비 눈에 띄는 성능 향상을 달성한다.
4.3.2 가중치 균형 (Weight Balancing)의 효과
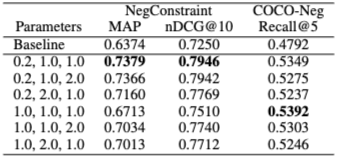
(원래 일관성), (긍정), (부정) 하이퍼파라미터의 영향을 분석했다. DEO는 테스트된 모든 설정에서 기준 모델보다 일관되게 우수한 성능을 보이며, 하이퍼파라미터 변화에 대한 강건성(robustness)을 입증한다. 텍스트 전용 NegConstraint 데이터셋에서는 일 때 MAP 0.7379, nDCG@10 0.7946으로 최고 성능을 보였다. 반면 COCO-Neg에서는 일 때 Recall@5 0.5392로 최고치를 기록했는데, 이는 CLIP과 같은 공유 비전-언어 공간에서 원래 의미론적 맥락을 유지하는 것이 중요하기 때문이다.
4.3.3 질의 분해 (Query Decomposition)의 효과
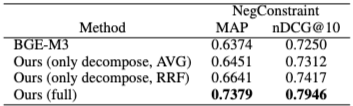
질의 분해 단계의 역할을 분석하기 위해 'Only Decompose' 변형을 실험했다. 이는 분해된 긍정 및 부정 하위 질의의 평균 임베딩을 사용하거나, 각 하위 질의별로 검색한 후 Reciprocal Rank Fusion (RRF)으로 결과를 병합하는 방식이다. 질의 분해만으로는 기준선 대비 제한적인 개선만을 보였다. RRF 기반 집계(aggregation)는 추가적인 이점을 제공하지만, 전체 DEO 방법론의 성능에는 훨씬 못 미친다. 이는 성능 향상이 질의 분해 자체보다는 후속 임베딩 최적화에서 비롯됨을 시사한다.
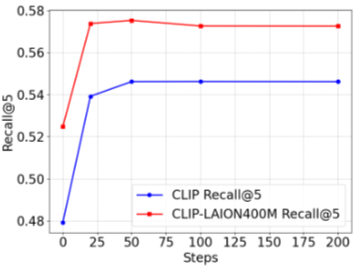
4.3.4 최적화 단계 (Optimization Steps)의 효과
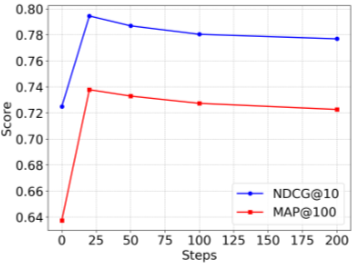
최적화 단계 수에 따른 검색 성능을 분석했다. NegConstraint와 COCO-Neg 모두에서 0단계에서 20단계로 증가할 때 성능이 급격히 향상되며, 20단계에서 50단계 사이에서 안정적으로 유지된다. 100단계 이상에서는 점진적으로 감소하는 경향을 보인다. 20-50단계가 강력한 성능을 달성하기에 충분하며, 모든 실험에서 20단계를 기본 설정으로 사용한다.
5. 분석

5.1 질의 분해의 품질 (Quality of Query Decomposition)
LLM이 질의를 긍정 및 부정 하위 질의로 얼마나 잘 분해하는지 분석했다. GPT-4.1-mini를 사용하여 NegConstraint 데이터셋에서 질의 분해의 정확도를 평가한 결과, 91.76%의 정확도를 달성하여 생성된 하위 질의가 사용자 의도와 대부분 일치함을 보여준다.
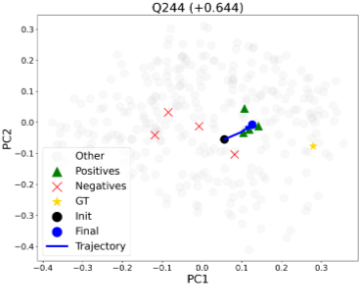
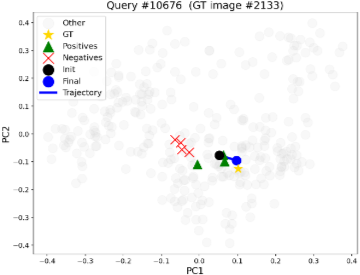
5.2 임베딩 공간 분석 (Embedding Space Analysis)
최적화된 질의 임베딩 가 긍정 임베딩 , 부정 임베딩 , 그리고 문서 임베딩에 대해 어떻게 변화하는지 시각화했다. PCA를 사용하여 BGE-M3의 전체 문서 임베딩에 투영된 질의 궤적, 분해된 하위 질의, 그리고 정답 문서를 2D 공간에 나타냈다. 초기 임베딩(검은색 점)은 긍정 하위 질의(녹색 삼각형)와 정답 문서(노란색 별)에 이끌리면서, 부정 하위 질의(빨간색 X)로부터 멀어지며 최적화된 지점(파란색 점)으로 점진적으로 이동한다. 이는 대비 최적화가 관련 영역으로 를 효과적으로 재구성하고 부정적인 요소를 억제함을 확인한다. 이 분석은 CLIP의 비전-언어 공간에서도 동일한 패턴을 보이며, DEO가 텍스트 검색과 교차 모달 이미지 검색 모두에 일반화됨을 보여준다.
5.3 계산 효율성 (Computational Efficiency)
DEO는 CPU와 GPU 환경 모두에서 높은 효율성을 보인다. CPU에서 20단계 최적화는 0.016초, 50단계는 0.035초가 소요된다. GPU에서 20단계 최적화는 0.033초, 50단계는 0.095초가 소요된다. 이는 DEO가 실제 응용 환경에서 실용적임을 보여준다.
6. 결론
이 논문은 미세 조정이나 추가 데이터셋 없이 부정 및 제외를 인식하는 검색을 위한 간단하면서도 효과적인 방법인 DEO를 제안한다. DEO는 사용자 질의를 긍정 및 부정 하위 질의로 분해하고, 대비 손실을 통해 임베딩 공간을 직접 최적화하여 사용자 의도에 더 정확하게 부합하는 질의 임베딩을 생성한다. 실험 결과, DEO는 텍스트 및 다중 모달 검색 태스크 모두에서 기준 모델보다 일관되게 우수한 성능을 보였다. 이러한 결과는 사용자 질의에 부정과 제외가 빈번하게 포함되는 실제 시나리오에서 DEO 접근 방식의 강건성과 실용성을 강조한다.
7. 한계점
DEO는 미세 조정 없이 효과적이지만, LLM이 사용자 질의를 긍정 및 부정 하위 질의로 정확하게 분해하는 능력에 의존한다. LLM의 분해 품질에 따라 최종 검색 성능이 달라질 수 있다. DEO는 경량화되고 제어 가능한 검색 시스템 구축에 유망한 방향을 제시한다. 향후 연구에서는 더 강력한 LLM으로 질의 분해를 강화하고, 질의별로 손실 균형 파라미터를 자동으로 선택하는 적응형 최적화 전략을 통합하며, 오디오와 같이 이미지 외의 다양한 다중 모달 데이터셋으로 DEO를 확장하는 것을 고려할 수 있다.
