Table-Critic: A Multi-Agent Framework for Collaborative Criticism and Refinement in Table Reasoning
Paper Review
서론
LLM은 다양한 추론 작업에서 뛰어난 능력을 보이지만, 테이블 추론 작업, 특히 다단계 추론 과정 전반에 걸쳐 일관성을 유지하는 데 어려움을 겪는다. 기존의 분해 전략들은 중간 추론 단계의 오류를 식별하고 수정하는 효과적인 메커니즘이 부족하여 cascading error propagation을 유발한다. 이 문제를 해결하기 위해, Table-Critic이라는 새로운 multi-agent framework를 제안한다. 이는 collaborative criticism과 iterative refinement를 통해 정확한 솔루션으로 수렴할 때까지 추론 과정을 개선한다. 이 framework는 오류 식별을 위한 Judge, 포괄적인 critique를 위한 Critic, 프로세스 개선을 위한 Refiner, 그리고 패턴 추출을 위한 Curator의 네 가지 specialized agent로 구성된다. 다양하고 예측 불가능한 error type에 효과적으로 대응하기 위해, 경험 기반 학습을 통해 critique knowledge를 체계적으로 축적하고 미래의 reflection을 안내하는 self-evolving template tree를 도입한다. Table-Critic은 기존 방법론에 비해 상당한 개선을 보여주며, 우수한 accuracy와 error correction rate를 달성하는 동시에 computational efficiency와 낮은 solution degradation rate를 유지한다.
방법론
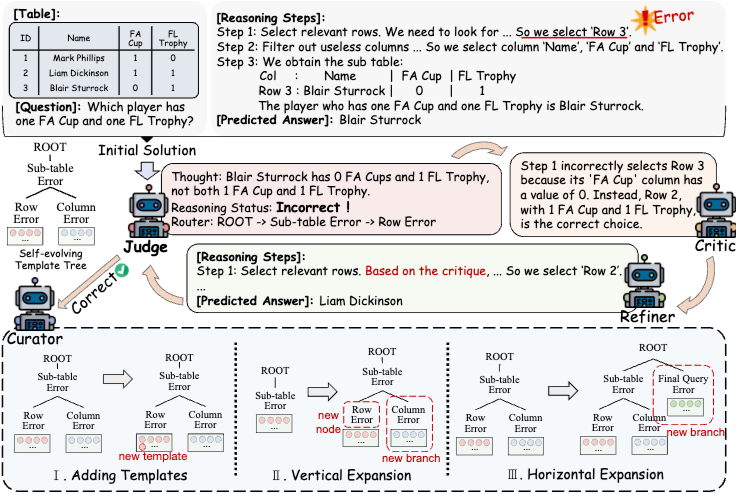
Table-Critic은 인간의 수정 프로세스를 모방하여 multi-step reasoning에서 효과적으로 구현하기 위한 collaborative multi-agent framework이다. 이 framework는 복잡한 reasoning refinement task를 네 가지 specialized function으로 분해한다: error detection (Judge), critique generation (Critic), reasoning refinement (Refiner), experience learning (Curator). 이 agent들은 협력하여 reasoning quality를 점진적으로 향상시키면서 귀중한 correction experience를 축적한다. Table 와 question 가 주어지면, 이 agent들은 초기 reasoning chain 을 만족스러운 솔루션에 도달할 때까지 iterative하게 refine한다. refinement 프로세스는 과거 경험에서 critique pattern을 체계적으로 축적하는 self-evolving template tree 에 의해 안내된다.
3.2 Multiple Agents
인간과 유사한 correction behavior에서 영감을 받아, Judge, Critic, Refiner, Curator의 네 가지 specialized agent를 설계하여 multi-step reasoning에서 criticism 및 refinement를 용이하게 한다. LLM()에 특정 instruction을 prompt하여 해당 operation을 실행한다.
- Judge (Aj): 추론 과정에서 잠재적인 오류를 식별하는 역할을 한다. Table , question , 현재 reasoning chain , 그리고 template tree 가 주어지면, 각 reasoning step을 분석하고 특정 error type을 결정한다(오류가 있는 경우). 식별된 error type을 기반으로 Judge는 template tree 를 통해 routing하여 subsequent critic agent를 안내하는 적절한 template을 찾는다.
여기서 는 각 reasoning step에 대한 error analysis를 나타내고, 는 전반적인 reasoning status를 나타내며, 은 template 선택을 안내하는 template tree의 routing path를 나타낸다. routing path를 기반으로, 관련 critique template 를 template tree 에서 sampling하여 Critic agent가 식별된 오류에 대한 high-quality critique를 생성하도록 안내한다. - Critic (Ac): Framework에서 중요한 구성 요소로서, 식별된 오류에 대해 상세하고 건설적인 critique를 생성하는 역할을 한다. Sampling된 critique template 의 안내를 받아 Critic agent는 reasoning chain 에서 첫 번째 오류 step을 찾아 오류 세부 정보를 분석하고 subsequent refinement를 위한 구체적인 suggestion을 제공한다.
여기서 는 생성된 critique를 나타내고 는 에서 첫 번째 오류 step의 index를 나타낸다. - Refiner (Ar): Critic이 제공한 critique를 기반으로 reasoning chain을 수정하는 작업을 수행한다. Critique , table , question , 그리고 첫 번째 오류 step까지의 partial reasoning chain (즉, )이 주어지면, Refiner는 먼저 식별된 오류를 수정하고 나머지 reasoning step을 완료하여 완전한 refined chain을 생성한다.
여기서 는 새로 생성된 complete reasoning chain을 나타낸다. - Curator (Acu): 경험 기반 학습 구성 요소 역할을 하며, 현재 refinement process에서 귀중한 critique template을 추출한다. Judge agent가 최종 reasoning chain이 error-free임을 확인한 후(P = Correct)에만 활성화된다. 각 refinement iteration과 기존 template tree 를 검토하여 Curator는 효과적인 refinement experience에서 의미 있는 critique template을 자율적으로 추출한다. 새로 추출된 이 template은 미래의 critique generation을 향상시키기 위해 에 통합된다.
여기서 는 complete refinement history를 나타내고 는 업데이트된 template tree를 나타낸다.
3.3 Multi-turn Refinement
Multi-turn refinement는 LLM이 reasoning chain에서 첫 번째 오류를 식별하고 수정하는 데 뛰어나지만, subsequent step에서 새로운 오류를 도입할 수 있다는 관찰에서 비롯되었다. 이 문제를 해결하기 위해, 여러 agent가 만족스러운 솔루션에 도달할 때까지 reasoning chain을 협력적으로 모니터링하고 개선하는 iterative refinement process를 구현한다.
초기 reasoning chain 가 주어지면, framework는 각 iteration에서 다음 단계를 통해 작동한다. (1) Judge agent는 먼저 전체 reasoning chain을 분석하여 잠재적인 오류를 식별하고 그 유형을 결정한다. 오류가 감지되지 않으면(P = Correct) 프로세스가 종료된다. 그렇지 않으면 Judge는 template tree를 통해 routing하여 관련 critique template을 찾는다. (2) Sampling된 template 의 안내를 받아 Critic agent는 step 에서 식별된 첫 번째 오류에 초점을 맞춰 detailed critique 를 생성한다. (3) Refiner agent는 critique를 통합하여 새로운 reasoning chain 를 생성한다. Refiner는 오류 step 까지의 partial chain 만 받으므로, critique의 도움으로 나머지 step을 재구성해야 한다. (4) 위 프로세스는 Judge가 현재 reasoning chain이 올바르다고 판단하거나(P = Correct) 최대 iteration 수 에 도달할 때까지 iterative하게 계속된다.
3.4 Self-evolving Template Tree
테이블 추론에서 다양하고 예측 불가능한 error type을 식별하는 문제를 해결하기 위해, critique knowledge를 체계적으로 축적하고 구성하는 self-evolving template tree를 도입한다. 이 dynamic structure는 경험 기반 학습을 통해 common 및 emerging error pattern을 효과적으로 처리할 수 있게 한다.
- Tree Structure: Template tree 는 다른 error type 간의 관계를 포착하는 hierarchical structure를 나타낸다. 각 node는 특정 error type을 나타낸다. Internal node는 더 넓은 error category를 나타내고, Leaf node는 특정 error type을 나타내며 해당 error type과 관련된 critique template의 repository를 유지한다.
- Self-evolving Mechanism: Template tree는 Curator agent를 통해 dynamic하게 진화하며, 두 가지 주요 operation을 관리한다: 기존 leaf node에 template 추가 및 tree branch 확장.
- Template Enhancement: 새로운 효과적인 critique pattern이 식별되면 Curator는 해당 leaf node의 template repository에 추가한다.
- Branch Expansion: Curator는 새로운 error type이 식별될 때 두 가지 방식으로 tree structure를 확장한다.
- Vertical Expansion: 더 fine-grained categorization이 필요한 새로운 error type이 발견되면 Curator는 vertical split을 수행한다. 이 operation은 기존 leaf node를 두 개의 새로운 child node를 가진 internal node로 변환한다.
- Horizontal Expansion: 기존 category와 병렬인 완전히 새로운 error type이 식별되면 Curator는 같은 level에 새로운 branch를 추가한다. 이 operation은 기존 구조를 보존하면서 새로운 error type을 수용한다.
실험
4.1 Experimental Setup
- Datasets: WikiTableQuestions (WikiTQ), TabFact.
- Baselines:
- Standard Reasoning: End-to-End QA, Few-Shot QA.
- Decomposition-Based Reasoning: Binder, Dater, Chain-of-Table.
- Critic-Based Reasoning: Critic-CoT.
- Implementation Details: Qwen2.5-72B-Instruct, LLaMA3.3-70B-Instruct, GPT-4o-mini LLM을 사용한다. Critic-CoT와 Table-Critic framework는 Chain-of-Table을 기반으로 구현되었다. Template tree는 초기 2개의 template으로 시작하여 자율적으로 진화한다. 최대 refinement iteration 는 5로 설정하고, temperature 0.0을 사용하여 greedy decoding을 한다.
4.2 Main Results
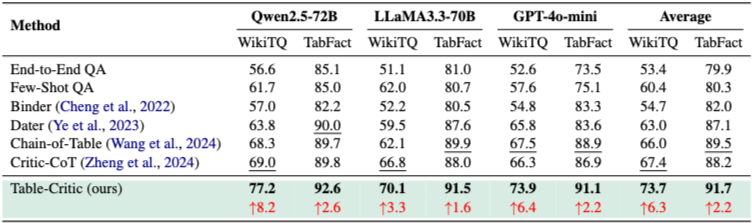
Table 1은 WikiTQ와 TabFact에서 다양한 LLM에 대한 Table-Critic의 성능을 보여준다.
- Table-Critic은 모든 데이터셋과 세 가지 LLM에서 모든 baseline 방법을 일관되게 능가한다. 평균적으로 WikiTQ에서 73.7%, TabFact에서 91.7%의 accuracy를 달성하며, 가장 강력한 baseline보다 각각 6.3%, 2.2%의 상당한 개선을 보인다.
- 개선 사항은 다른 model architecture 전반에 걸쳐 강력하다. Qwen2.5-72B-Instruct를 사용하여 WikiTQ에서 77.2%, TabFact에서 92.6%의 가장 높은 절대 성능을 달성하며, 각각 8.2%, 2.6%의 상당한 gains를 보인다. LLaMA3.3-70B-Instruct 및 GPT-4o-mini에서도 유사한 패턴이 관찰되며 framework의 일반화 가능성을 보여준다.
- WikiTQ와 TabFact 간의 성능 차이는 방법론의 강점을 시사한다. Table-Critic은 TabFact(+2.2%)에 비해 WikiTQ(평균 +6.3%)에서 더 큰 개선을 보이는데, 이는 복잡한 multi-step reasoning task를 처리하는 데 특히 효과적임을 나타낸다. 이는 WikiTQ의 compositional question이 TabFact의 binary verification task보다 multi-turn refinement 및 self-evolving template tree 메커니즘의 이점을 더 많이 얻기 때문으로 해석된다.
4.3 Analysis of Critic Effectiveness
Table 2는 Table-Critic, Chain-of-Table, Critic-CoT의 critic mechanism을 비교 분석한다. 주요 지표는 Overall Accuracy (Acc), Error Correction Rate (), Solution Degradation Rate (), Net Performance Gain ()이다.
- Error Correction vs. Solution Degradation: Table-Critic은 superior error correction capability를 보여주면서 solution degradation을 최소화한다. WikiTQ에서 Chain-of-Table의 오류 중 9.6%를 성공적으로 수정하고 올바른 솔루션의 0.7%만 저하시켜 상당한 net performance gain(+8.9%)을 얻는다. Critic-CoT는 5.6%의 correction rate를 보이지만 높은 degradation rate(-4.9%)로 인해 미미한 개선(+0.7%)만을 보인다.
- Task-Specific Performance: WikiTQ에서 Table-Critic은 Critic-CoT보다 높은 error correction rate(+9.6% vs +5.6%)를 달성하고 현저히 낮은 degradation(-0.7% vs -4.9%)을 유지한다. TabFact에서는 개선이 미미하지만, Table-Critic은 여전히 낮은 degradation rate(-0.5% vs -2.8%)로 더 나은 stability를 유지한다.
- Critic Stability: Table-Critic의 핵심 강점은 올바른 솔루션을 유지하는 안정성이다. 일관되게 낮은 degradation rate는 self-evolving template tree가 유효한 reasoning pattern을 효과적으로 보존하면서 오류를 식별하고 수정함을 시사한다.
4.4 Analysis of Multi-Turn Mechanism

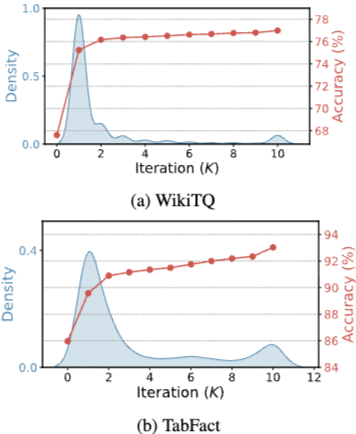
Figure 2는 iteration 수 에 따른 모델 성능 변화와 필요한 iteration 수의 분포를 보여준다.
- Performance Evolution: 두 데이터셋 모두에서 빠른 초기 개선 후 점진적인 convergence 패턴을 관찰한다. WikiTQ의 경우, 첫 세 iteration 내에 accuracy가 67.6%에서 76.5%로 급격히 증가하고 6 iteration 후 약 77%에서 안정화된다. TabFact도 초기 iteration에서 성능이 크게 향상되고 5 iteration 후 약 92%에서 안정된다.
- Iteration Distribution: WikiTQ는 여러 peak가 있는 더 넓은 분포를 보여주는데, 이는 질문 해결에 필요한 iteration 수가 다양함을 나타낸다. TabFact는 1-2 iteration의 primary peak와 10 iteration 근처의 secondary peak를 가진 집중된 분포를 보여준다. 이 bimodal pattern은 TabFact가 두 가지 범주로 나뉘는 경향이 있음을 시사한다: 1-2 iteration 내에 빠르게 검증될 수 있는 간단한 경우와 철저한 refinement가 필요한 복잡한 경우.
4.5 Analysis of Computational Cost

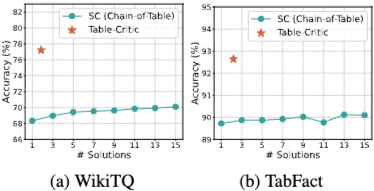
Figure 3은 Chain-of-Table과의 computational cost-effectiveness trade-off를 분석한다.
- Efficiency Comparison: Table-Critic은 기본 Chain-of-Table에 비해 약 1.8-2.2배의 computational cost를 요구한다. 하지만 Table-Critic은 Chain-of-Table이 15번의 solution attempt에도 불구하고 달성하는 성능보다 상당히 높은 accuracy를 달성한다(WikiTQ에서 77.2%, TabFact에서 92.6%).
- Cost-Effectiveness Analysis: Chain-of-Table에서 단순히 solution attempt 수를 늘리는 것은 Table-Critic과 비교할 만한 성능을 달성하지 못한다. 이는 multi-agent refinement mechanism이 traditional majority voting 전략보다 reasoning accuracy를 향상시키는 데 더 효과적인 접근 방식임을 시사한다.
4.6 Analysis of Self-evolving Template Tree
Table 3은 self-evolving mechanism의 효과를 조사하기 위한 ablation study 결과를 보여준다.
- Performance Impact: template evolution 없이 (w/o Self-evolving) 성능은 WikiTQ에서 1.1%, TabFact에서 1.8% 하락한다. TabFact에서 더 큰 성능 차이는 template evolution이 fact verification task에 특히 유익하다는 것을 시사한다.
- Mechanism Analysis: 이 결과는 framework에서 dynamic adaptation의 중요성을 강조한다. self-evolving mechanism은 template tree가 초기 상태를 넘어 확장되어 critique process 중에 마주치는 다양한 reasoning pattern을 수용할 수 있게 한다.
결론
이 논문에서는 collaborative criticism 및 refinement를 통해 테이블 추론을 향상시키는 novel multi-agent framework인 Table-Critic을 제안한다. 이 접근 방식은 self-evolving template tree와 협력하여 작동하는 네 가지 specialized agent를 도입하여 복잡한 테이블 추론 작업에서 오류 식별 및 수정의 어려움을 효과적으로 해결한다. 광범위한 실험을 통해 이 방법론이 기존 접근 방식을 크게 능가하며, 다른 데이터셋에서 상당한 개선을 달성하는 동시에 강력한 성능 안정성을 유지함을 입증했다. 현재 구현은 주로 textual table reasoning에 중점을 두지만, 제안된 multi-agent critique framework는 본질적으로 유연하며 다양한 다른 시나리오로 확장될 수 있다.
