LLM 기반 Text-to-SQL 방법론의 현황을 체계적으로 검토하며, 고전적인 벤치마크 및 LLM 시대의 새로운 벤치마크, 평가 메트릭을 제시한다. 주요 방법론인 prompt engineering과 fine-tuning에 대해 상세한 taxonomy를 구축하고, 각 하위 범주에 대한 실용적인 통찰력을 제공한다. 또한, 다양한 모델과 데이터셋에 대한 분석을 통해 특성을 도출하고, 이 분야의 도전 과제와 미래 방향을 논의한다.
1. 서론
빅데이터 시대에 관계형 데이터베이스는 데이터 관리에 핵심적인 역할을 한다. SQL을 사용한 데이터 쿼리는 전문 지식을 요구하며, 비전문 사용자에게는 진입 장벽으로 작용한다. Text-to-SQL parsing은 자연어 쿼리를 SQL 쿼리로 변환하여 이러한 격차를 해소한다. 초기 template-based 및 rule-based 방법론에서 시작하여, 딥러닝 시대에는 Seq2Seq 모델이 주류를 이루었고, PLM(Pre-trained Language Models)의 등장으로 SOTA(State-of-the-Art) 성능을 달성했다. PLM이 LLM(Large Language Models)으로 발전하면서 scaling law와 emergent capabilities 덕분에 Text-to-SQL 분야에 혁신을 가져왔다. LLM 기반 Text-to-SQL 연구는 크게 prompt engineering과 fine-tuning의 두 가지 접근 방식에 집중한다. Prompt engineering은 LLM의 instruction-following 능력을 활용하여 RAG(Retrieval-Augmented Generation), few-shot learning, Chain-of-Thought(CoT)와 같은 추론 기법을 사용한다. Fine-tuning은 "pre-training and fine-tuning" 패러다임을 따르며 Text-to-SQL 데이터셋으로 LLM을 훈련한다. Prompt engineering은 적은 데이터를 요구하지만 최적화되지 않은 결과를 초래할 수 있고, fine-tuning은 성능을 향상시키지만 더 큰 훈련 데이터셋이 필요하다. 이 서베이는 LLM 기반 Text-to-SQL의 전체 파이프라인을 분석하고, 체계적인 taxonomy를 제공하며, 실용적인 "Key Takeaways"를 통해 통찰력을 제공한다.
2. 개요
LLM은 자연어 처리 및 기계 학습의 이정표로, PLM의 파라미터 크기와 훈련 데이터 볼륨을 지속적으로 확장함으로써 등장했다. LLM은 emergent abilities를 통해 few-shot learning 및 instruction following과 같은 놀라운 능력을 보여준다. 이러한 능력과 LLM의 autoregressive한 동작 원리로 인해 prompt engineering은 LLM을 downstream 태스크에 적용하는 주요 흐름 중 하나가 되었다. 다른 흐름은 fine-tuning으로, 특정 도메인에서 성능을 높이고 개인 정보 보호 문제를 해결하는 것을 목표로 한다. Text-to-SQL은 LLM의 등장으로 혁신을 겪었으며, LLM 기반 Text-to-SQL 시스템은 prompt engineering과 fine-tuning 두 가지 범주로 분류된다. Prompt engineering은 태스크 설명, 테이블 스키마, 질문 및 추가 지식을 포함하는 잘 구조화된 프롬프트를 설계하고 in-context learning 및 추론 방법을 활용한다. Fine-tuning은 Text-to-SQL 데이터셋으로 적절한 PLM을 선택하여 LoRA와 같은 fine-tuning 접근 방식을 적용한다.
2.1. 전통적인 Text-to-SQL 접근 방식과의 차이점
LLM 기반 Text-to-SQL은 두 가지 측면에서 전통적인 접근 방식과 다르다. 첫째, LLM은 instruction following 능력 덕분에 훈련 없이도 Text-to-SQL 태스크를 수행할 수 있어 새로운 패러다임을 제시한다. 둘째, 전통적인 접근 방식은 다양한 encoder와 decoder 아키텍처를 사용했지만, LLM은 Transformer 기반의 통일된 아키텍처를 따르므로 확장이 용이하고 구현이 간소화된다.
2.2. LLM 기반 Text-to-SQL을 사용하는 이유
LLM 기반 Text-to-SQL 방법론의 인기는 다음과 같은 이유에서 비롯된다.
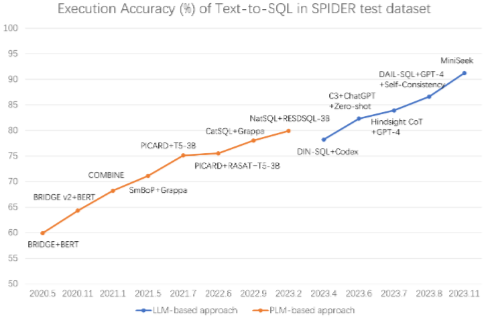
- Enhanced Performance: Spider 테스트 데이터셋에서 LLM 기반 방법론이 SOTA 성능을 크게 향상시켰다.
- Generalization Ability and Adaptability: LLM은 instruction following 능력과 in-context learning을 통해 추가 훈련 없이도 다양한 설정에 쉽게 적용될 수 있다.
- Future Improvements: LLM 커뮤니티의 지속적인 발전(모델 확장, 새로운 prompting 방법, 고품질 데이터셋 생성, fine-tuning)이 Text-to-SQL 방법론을 더욱 발전시킬 잠재력이 크다.
3. 벤치마크 및 평가 메트릭

3.1. 벤치마크
Text-to-SQL 데이터셋은 LLM 등장 이전과 이후의 벤치마크로 나뉜다.
- Benchmarks prior to the rise of LLMs: WikiSQL, Spider 1.0, KaggleDBQA와 같은 고전적인 벤치마크는 여전히 널리 사용되며, Spider 1.0은 Text-to-SQL 성능 평가의 주요 선택지로 남아 있다. Spider-Realistic, Spider-SYN, SPIDER-CG, CSpider, ADVETA와 같은 증강된 벤치마크도 제안되었다.
- Benchmarks in the era of LLMs: LLM의 등장 이후 새로운 도전 과제(도메인 특화 지식, 다양한 perturbation, 크고 노이즈가 많은 데이터베이스, SQL 효율성)에 초점을 맞춘 벤치마크가 등장했다.
- SCIENCEBENCHMARK: 실제 연구 정책 수립, 천체 물리학, 암 연구와 같은 도메인 특화 데이터베이스의 NL 인터페이스 구축 어려움을 반영한다.
- BIRD: 12,751개의 Text-to-SQL 쌍과 95개의 데이터베이스를 포함하며, dirty하고 noisy한 데이터베이스 값, 외부 지식 grounding, SQL 효율성 문제를 다룬다. GPT-4조차 Execution Accuracy 54.89%에 불과하여 여전히 도전 과제가 많다.
- Dr.Spider: Spider 데이터셋 기반으로 17가지 perturbation을 설계하여 Text-to-SQL 모델의 robustness를 측정한다. 가장 robust한 모델도 성능이 14.0% 하락한다.
- Spider 2.0: 실제 엔터프라이즈 수준의 Text-to-SQL workflow 문제를 다루며, BigQuery, Snowflake, PostgreSQL과 같은 클라우드/로컬 데이터베이스 시스템의 복잡성을 포함한다.
- BIRD-Critic 1.0: LLM이 실제 데이터베이스 환경에서 사용자 문제를 진단하고 해결하는 능력을 평가하는 새로운 SQL 평가 프레임워크를 도입한다.
3.2. 평가 메트릭
다음 다섯 가지 메트릭이 주로 사용된다.
- Exact Set Match Accuracy (EM): 생성된 SQL과 ground-truth SQL의 리터럴 내용이 일치하는지 비교한다.
- Execution Accuracy (EX): 생성된 SQL과 ground-truth SQL의 실행 결과가 일치하는지 비교한다.
- Test-suite Accuracy (TS): 정확한 쿼리에 대해 높은 코드 커버리지율을 가진 데이터베이스 테스트 스위트를 생성하여 예측된 쿼리의 annotation 정확도를 측정한다.
- Valid Efficiency Score (VES): SQL 실행 효율성을 평가 범위에 포함한다. 식은 다음과 같다.
여기서 은 ground-truth SQL의 결과, 은 예측 SQL의 결과, 은 ground-truth SQL의 실행 시간, 은 예측 SQL의 실행 시간을 나타낸다. - ESM+: EM 기반으로 LEFT JOIN, RIGHT JOIN, OUTER JOIN, INNER JOIN, JOIN, DISTINCT, LIMIT, IN, foreign keys, schema check 및 alias checks에 새로운 규칙을 적용하여 false positives 및 false negatives를 줄인다.
3.3. 벤치마킹 연구
다양한 벤치마킹 연구가 LLM의 Text-to-SQL 성능을 평가하기 위해 수행되었다. [89]는 Codex 및 GPT-3 모델을 평가했으며, prompt 기반 few-shot learning이 fine-tuning 기반 접근 방식과 경쟁할 수 있음을 보여주었다. [35]는 prompt engineering 전략을 비교하여 DAIL-SQL을 제안했다. [133]은 Text-to-SQL, SQL Debugging, SQL Optimization, Schema Linking, SQL-to-Text의 5가지 태스크를 통해 LLM 능력을 종합적으로 평가했다. DB-GPT-Hub[146]는 오픈 소스 LLM의 fine-tuning에 중점을 두었다. LLM 기반 Text-to-SQL 방법론의 빠른 진화로 인해 벤치마킹 결과는 빠르게 구식이 되므로, 특정 결과보다는 원본 논문을 참조하는 것이 좋다.
4. Prompt Engineering
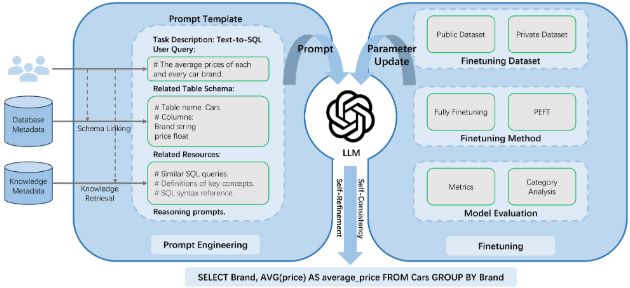
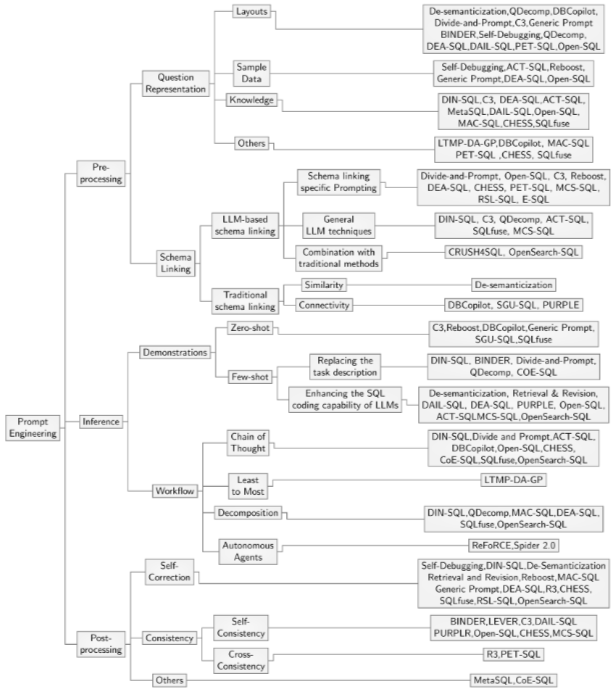
Prompt engineering은 LLM이 이해할 수 있는 지시를 구조화하는 과정이다. 개발자 관점에서는 LLM과의 상호 작용 시 프롬프트 단어를 설계하여 특정 태스크에 대한 LLM의 출력을 사용자 정의하는 것을 의미한다. LLM은 autoregressive decoding 속성으로 인해 이전 텍스트를 기반으로 다음 단어를 예측하며, 프롬프트 단어의 설계는 다음 토큰의 확률 분포에 영향을 미쳐 최종 생성에 영향을 미친다. Text-to-SQL에 대한 prompt engineering 방법은 세 단계로 나뉜다.
\text{pred_SQL} = \text{Post_process} (\text{LLM} (\text{QuestionRepresentation}, \text{Demonstration}, \text{Reasoning}))
4.1. Pre-processing
Text-to-SQL 태스크의 초기 단계에서 프롬프트에 문제 해결에 필요한 모든 정보를 명확하고 포괄적으로 기술해야 한다. 이는 주로 질문 설명의 표현 형식, 데이터베이스 스키마, 그리고 태스크 관련 지식을 포함한다.
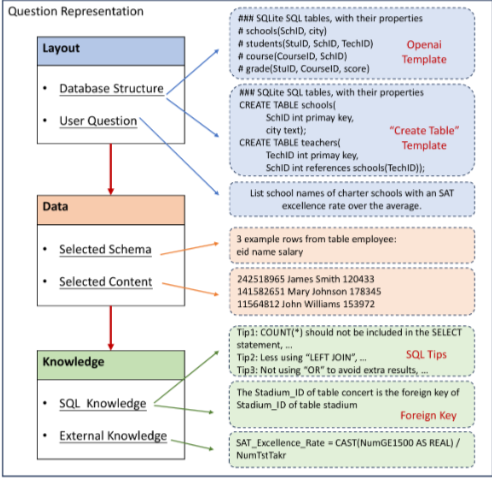
4.1.1. Question Representation
Question Representation은 자연어 문제 진술과 관련 데이터베이스의 필수 정보를 포함한다.
- Layouts: OpenAI template layout(SQLite의 주석 기호로 시작하고 Table(Column1,...) 형식), "Create Table" layout(CREATE TABLE 문으로 데이터베이스 구조를 표현하며, 각 열의 데이터 타입과 primary/foreign key 관계를 포함).
- Sample Data: 실제 데이터베이스 내용의 샘플 데이터를 프롬프트에 포함하여 LLM이 데이터 형식을 이해하고 준수하도록 돕는다.
SELECT * From Table LIMIT X문이나 열별 데이터 목록을 사용할 수 있다. - Knowledge: SQL 관련 지식(SQL 키워드, 구문, 일반적인 작성 습관) 및 외부 지식(전문 용어, 도메인 특화 단어)을 프롬프트에 추가하여 LLM의 SQL 생성 능력을 보정한다. C3[25]는
COUNT(*)사용,LEFT JOIN피하기 등 SQL 스타일 편향을 보정하는 지시를 추가했다. DIN-SQL[85]은 SQL 쿼리의 난이도에 따라 다른 사양과 힌트를 설계했다.
Key Takeaways:
- 구조화된 layout(OpenAI template, 'Create Table' template)이 unstructured layout보다 우수하며, 서로 다른 구조화된 layout은 비슷한 성능을 보인다.
- Sample data는 효과적이고 추가 가능하며, context length가 충분하다면 고려할 가치가 있다.
- Primary 및 foreign key는 복잡한 시나리오에서 중요한 영향을 미치고 필수적이다.
- 지식 부분은 LLM이 SQL 증거와 질문 속 숨겨진 개념을 이해하고 상식과 일치하도록 돕는 데 중요하다.
4.1.2. Schema Linking
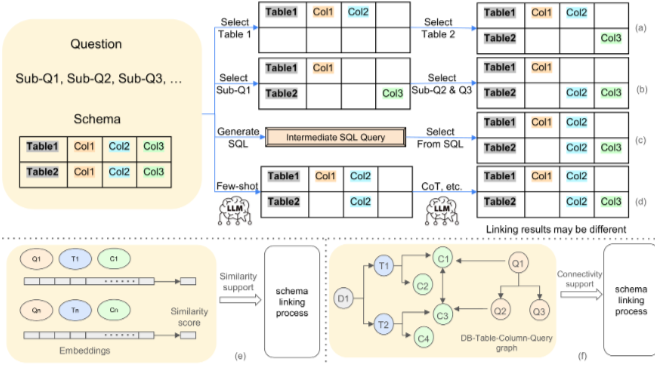
Schema linking은 주어진 쿼리에서 데이터베이스의 테이블과 열을 식별하는 Text-to-SQL 프로세스의 하위 태스크이다.
- LLM 기반 schema linking methods: LLM을 활용하여 schema linking을 수행한다.
- Prompting LLMs in specific steps: LLM에 직접 schema linking을 요청하거나(Divide-and-Prompt[69]), 더 복잡한 경로를 설계하여(C3[25]는 테이블 먼저, 그 다음 열을 검색) 수행한다. PET-SQL[61]은 먼저 SQL 쿼리를 구성하고 그 쿼리에서 테이블과 열을 추출하는 방식을 제안한다.
- Enhancing LLM-based schema linking performance by utilizing general LLM techniques: few-shot learning[7], CoT reasoning[115], self-consistency voting[112], fine-tuning과 같은 일반적인 LLM 기술을 활용하여 성능을 향상시킨다. DIN-SQL[85]은
Let’s think step by step을 사용하여 성능을 개선한다. - Integrating LLMs into traditional schema linking methods: LLM을 전통적인 schema linking 접근 방식과 통합한다. CRUSH4SQL[52]은 LLM의 hallucination 능력을 활용하여 DB 스키마를 생성하고, OpenSearch-SQL[119]은 LLM으로 schema item을 선택한 후 vector retrieval을 사용한다.
- Traditional schema linking methods: LLM에 의존하지 않는 schema linking 기술이다.
- Similarity-based Retrieval Methods: 쿼리와 스키마 정보 간의 유사성을 측정하여 관련 스키마를 검색한다. BERT, RoBERTa와 같은 PLM을 사용하여 embedding vector를 생성하고 유사성을 비교한다.
- Connectivity methods: 테이블과 열 간의 관계나 연결을 고려한다. DBCopilot[111], PURPLE[90], SGU-SQL[137]은 그래프 기반 접근 방식을 사용하여 테이블 간의 관계를 모델링한다.
Key Takeaways:
- 대부분의 연구는 CoT 또는 decomposition reasoning을 기본적인 workflow로 선호한다.
- 주류 LLM 기반 schema linking 방법은 특정 단계에서 LLM을 prompting하거나 일반 LLM 기술(few-shot learning, CoT reasoning, self-consistency voting, fine-tuning)을 활용하여 성능을 향상시킨다.
- 유사성(similarity)과 연결성(connectivity) 모두 중요한 고려 사항이다.
4.2. Inference
주어진 질문과 스키마를 바탕으로 잠재적인 답을 생성하는 단계이다. Text-to-SQL 태스크의 복잡성과 높은 정확도 요구 사항을 고려할 때, 단순히 LLM이 직접 SQL 응답을 생성하도록 하는 것은 만족스러운 결과를 얻기 어렵다. 다음 두 가지 기술이 정확하고 고품질의 SQL을 생성하는 데 도움이 된다.
4.2.1. Workflow
LLM과의 한 번의 상호 작용만으로 SQL을 직접 생성하는 것은 LLM의 전문 분야 능력을 과대평가하는 것이다. 사람처럼 복잡한 태스크를 여러 간단한 하위 태스크로 나누듯이, prompt-engineering 기반 방법론은 LLM을 사용하여 쿼리에 대한 응답을 생성하기 위한 특정 추론 workflow를 설계한다.
- Chain-of-Thought(CoT): 일련의 중간 추론 단계를 포함하며
Let’s think step by step과 같은 구문으로 시작한다. SQL의 절별, 키워드별로 단계를 출력한다. DIN-SQL[85]은 복잡한 질문에 대해 CoT의 휴먼 디자인 단계를 사용한다. - Least-to-Most: 하위 문제가 구문적으로나 의미적으로 원래 문제로 환원될 수 있다는 원칙을 따른다. LTMP-DA-GP[4]는 자연어 쿼리를 분해하고 NatSQL에 매핑하여 SQL을 생성하는 데 Least-to-Most를 적용한다.
- Decomposition: 생성 태스크를 LLM과의 맞춤형 상호 작용으로 분해한다. SQL 생성 태스크의 분해는 병렬적이거나 순차적일 수 있다. DIN-SQL[85]은 SQL을 Easy, Nested Complex, Non-Nested Complex의 세 가지 복잡성 수준으로 분류하는 병렬 분해를 사용한다. MAC-SQL[107]은 selector, decomposer, refiner로 구성된 프레임워크를 도입하는 순차적 분해를 사용한다.
- Autonomous Agents: ReAct 프레임워크[127]에서 영감을 받아 LLM을 두뇌로 취급하고 환경, 인간 및 다른 LLM 기반 에이전트와의 상호 작용을 제어한다. Spider 2.0[55]은 데이터베이스 관련 코딩 태스크에 중점을 둔 Spider-Agent를 제안한다. REFORCE[22]도 self-refinement workflow를 가진 agent-based 프레임워크를 제안한다.
Key Takeaways:
- 대부분의 연구는 CoT 또는 decomposition reasoning을 기본적인 workflow로 선호한다.
- 원래 CoT보다 CoT의 맞춤형 변형을 설계하는 것이 권장된다.
- Decomposition은 순차적 또는 병렬 방식으로 SQL 생성에 도움이 된다.
- 대체 패턴은 탐색의 여지가 있다.
4.2.2. Demonstrations
Workflow에서 demonstrations는 SQL 생성 성능을 향상시키는 데 자주 사용된다.
- Replacing the task description: 복잡한 Text-to-SQL 태스크를 처리하기 위해, 연구들은 특정 단계를 포함하거나 이전에 존재하지 않던 새로운 하위 태스크를 포함하는 다양한 workflow를 탐색한다. DIN-SQL[85]은 NatSQL을 중간 표현으로 생성하고 이를 기반으로 최종 결과를 생성하는 CoT 스타일의 workflow를 따른다. BINDER[18]는 SQL과 같은 프로그래밍 언어를 언어 모델 API 호출 함수로 증강하고, 자연어 쿼리를 확장된 SQL 언어로 번역한다.
- Enhancing the SQL coding capability of LLMs: 적절한 demonstrations는 LLM의 성능을 크게 향상시킬 수 있지만, 샘플 선택에 매우 민감하다. 유사한 의미를 가진 질문의 예를 검색하는 것이 일반적이다. 도메인 특화 단어를 마스킹하여 쿼리 골격(skeletons)을 얻고, 이를 기반으로 유사한 질문 골격을 가진 예를 검색하는 방법이 사용된다.
Key Takeaways:
- 프롬프트에서 태스크 설명을 위한 간단한 방법 중 하나는 demonstrations를 활용하는 것이다. workflow가 복잡할수록 이 방법의 장점이 커진다.
- 질문 골격은 원래 질문보다 질문 의도를 더 효과적으로 포착할 수 있다.
- 정확성과 토큰 비용 간의 trade-off를 고려해야 한다.
4.3. Post-processing
생성된 SQL의 성능과 안정성을 더욱 향상시키기 위해 후처리(post-processing)를 적용한다.
4.3.1. Self-Correction
LLM이 답을 생성한 후, Self-Correction 방법은 특정 질문과 태스크에 대한 규칙을 사용하여 LLM이 답의 정확성을 확인하도록 한다. Text-to-SQL 시나리오에서는 SQL 관련 규칙이나 SQL 문 실행 결과 또는 오류 로그를 LLM에 제공하여 검사를 수행한다. [3]은 테이블 값의 미묘한 공백 차이를 LLM이 재확인하도록 했다. [37–39]는 LLM이 생성한 SQL이 실행되지 않으면 원래 프롬프트에 있는 소수의 스키마를 전체 스키마로 변경하고 SQL을 다시 생성한다.
4.3.2. Consistency Method
- Self-Consistency: 주로 majority voting 전략을 채택하여 동일한 LLM이 특정 temperature 설정으로 여러 답변을 생성하게 한 후, 가장 자주 나타나는 답변을 최종 답변으로 선택한다. [17, 18, 25, 35] 등은 Self-Consistency를 직접 사용하여 성능 향상을 달성했다.
- Cross-Consistency: 여러 다른 LLM이나 에이전트가 각각 답변을 생성하거나 SQL의 유효성을 확인하는 방법이다. PET-SQL[61]은 여러 LLM에 낮은 temperature로 SQL을 생성하도록 지시하고 SQL 실행 결과를 기반으로 투표를 수행한다.
4.3.3. Others
DEA-SQL[120]은 특정 문제 유형(예: 극단값 문제)에서 모델이 오류를 더 많이 일으킨다는 것을 발견하고 active learning을 활용하여 생성된 SQL이 수정되어야 하는지 여부를 식별한다. OpenSearch-SQL[119]은 SQL 생성 과정의 consistency alignment에 중점을 두어 프레임워크의 각 모듈이 특정 요구 사항과 일치하는지 확인하는 alignment module을 추가한다.
Key Takeaways:
- Text-to-SQL 태스크에서 Self-Correction을 갖춘 대부분의 연구는 수작업으로 스키마를 수정하는 규칙 및 실행 로그와 같은 'refine' 부분에 중점을 둔다.
- Self-Consistency는 적응성, 편리성, 좋은 성능의 장점을 가지지만, LLM과의 상호 작용이 많고 비용이 더 많이 든다.
- Cross-Consistency는 여러 LLM이 참여하여 단일 LLM의 편견 단점을 줄인다.
- Post-processing 단계에서 Self-Correction과 consistency method를 모두 사용하는 것이 유망하다.
5. Fine-tuning
Prompting 방법론은 GPT-4와 같은 강력한 폐쇄형 LLM에 크게 의존하지만, 이러한 모델은 데이터 전송으로 인한 개인 정보 보호 문제를 야기할 수 있다. 따라서 오픈 소스 LLM의 활용에 주목해야 한다. 오픈 소스 LLM은 모델 크기, 훈련 코퍼스, pretraining 노력의 부족으로 인해 제한된 추론 및 instruction-following 능력을 보인다. 또한, SQL 관련 콘텐츠가 pretraining 코퍼스의 극히 일부를 차지하여 Text-to-SQL 태스크에서 저조한 성능을 보일 수 있다. 따라서 오픈 소스 LLM의 주류 적용 방식은 fine-tuning이다.
LLM 기반 Text-to-SQL의 fine-tuning은 base LLM(예: Code Llama)을 가져와 특정 시나리오의 Text-to-SQL 데이터셋을 사용하여 SQL 생성 태스크와 같은 Text-to-SQL 관련 태스크에 대해 추가 훈련을 수행하는 것을 포함한다.
여기서 은 base model, 는 fine-tuning 데이터셋, 는 사용자 쿼리, 는 해당 데이터베이스 정보, 는 ground truth SQL 쿼리이다.
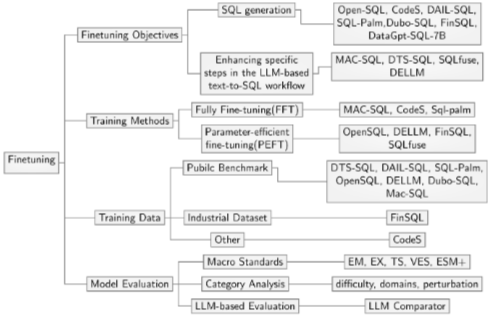
5.1. Finetuning Objectives
일반적으로 fine-tuning의 목표는 SQL 생성이다. 특정 형식으로 설계된 질문 표현과 데이터베이스 정보가 주어지면, 모델은 올바른 SQL 쿼리를 추론한다. Open-SQL[17], CodeS[59] 등이 이에 해당한다.
또한, MAC-SQL[107]과 같이 LLM 기반 Text-to-SQL workflow의 다른 단계(schema linking, question decomposition, SQL correction)의 성능을 향상시키기 위해 fine-tuning을 활용하는 연구도 있다. DELLM[42]은 LLM을 fine-tuning하여 주어진 질문과 데이터베이스 정보에 기반한 도메인 지식을 생성한다.
5.2. Training Methods
LLM fine-tuning에는 Fully Fine-tuning(FFT)과 Parameter-Efficient Fine-tuning(PEFT)의 두 가지 훈련 방법이 있다. FFT는 LLM의 모든 파라미터를 훈련 가능하게 처리하는 반면, PEFT는 소수의 파라미터만 조정하여 훈련 효율성을 높이고 비용을 절감한다. PEFT 중 LoRA[45]와 QLoRA[24]가 가장 인기 있는 방법이다. LoRA는 pre-trained model의 가중치를 고정하고 trainable rank decomposition matrix를 Transformer 아키텍처의 각 레이어에 주입하여 downstream 태스크의 trainable 파라미터 수를 크게 줄인다. QLoRA는 LoRA를 더욱 개선하여 4-bit NormalFloat, double quantization, Paged Optimizers와 같은 혁신적인 노력을 통해 메모리 사용량을 줄이면서 성능을 유지한다.
5.3. Training Data
대부분의 Text-to-SQL fine-tuning 연구는 오픈 소스 Text-to-SQL 벤치마크의 훈련 세트를 직접 활용한다. Spider[129] 훈련 세트를 사용한 연구(DTS-SQL[86], DAIL-SQL[35]), BIRD[60] 훈련 세트를 사용한 연구(OpenSQL[17], DELLM[42])가 있다. 산업 논문의 예시로, FinSQL[134]은 금융 애플리케이션 데이터베이스의 고유한 특성을 고려하여 BULL 벤치마크를 구축했다.
CodeS[59]는 일반 Text-to-SQL 능력을 향상시키기 위해 SQL 관련 데이터, NL-to-code 데이터, NL 관련 데이터를 수집하여 fine-tuning 데이터셋을 구성하고, 새로운 도메인의 데이터베이스에 적응적으로 전이하기 위해 GPT-3.5를 활용하여 (질문, SQL) 쌍을 생성한다.
5.4. Model Evaluation
모델 fine-tuning 후에는 테스트 세트에서 EM, EX와 같은 정확도 지표를 계산하여 모델 성능 변화를 비교하는 것이 일반적이다. 난이도, 도메인, perturbation 유형별로 쿼리를 분류하여 분석하거나, 출력 결과의 오류 유형을 분류할 수도 있다. LLM Comparator[48]와 같은 시스템은 두 모델 간의 차이를 시각화하고 평가하여 "when, why, how" 차원에서 분석할 수 있다.
5.5. Current Situation
기업의 개인 정보 및 데이터 보안을 고려할 때, 산업 Text-to-SQL에는 fine-tuning 방법이 더 적합하다. 그러나 프롬프팅 방식에 비해 fine-tuning 연구는 상대적으로 덜 탐색되었다. 이는 GPT 시리즈와 같은 폐쇄형 모델의 우수한 성능과 낮은 API 호출 비용으로 인해 오픈 소스 모델의 fine-tuning 연구가 상대적으로 주목받지 못했기 때문이다. 또한, prompt engineering 방법이 알고리즘 수준에서 더 많은 혁신 포인트를 가지는 반면, fine-tuning 방법은 훈련 기술, base model 및 훈련 데이터 품질에 더 의존한다.
Key Takeaways:
- Fine-tuning은 LLM 기반 Text-to-SQL workflow의 다양한 단계의 성능을 향상시키는 데 사용될 수 있다.
- 대부분의 연구는 PEFT가 FFT보다 훈련 효율성이 우수하고 훈련 비용이 낮기 때문에 PEFT를 선호한다.
- 오픈 벤치마크는 산업 애플리케이션 데이터베이스의 특성을 반영하지 못한다.
- LLM을 활용한 데이터셋 생성은 큰 잠재력을 가진다.
6. Model
Prompt engineering이든 fine-tuning이든, base LLM의 선택은 Text-to-SQL 태스크 구현의 기반이므로 중요하다. Text-to-SQL 태스크에 사용되는 LLM은 주로 Transformer 아키텍처를 기반으로 하며 decoder-only 패턴을 채택한다. 모델은 크게 오픈 소스와 폐쇄형으로 분류된다.
6.1. Base Model
기존 LLM 기반 Text-to-SQL 연구는 주로 12개의 폐쇄형 LLM과 16개의 오픈 소스 LLM을 base model로 사용한다.
6.1.1. Closed-source Models
폐쇄형 모델의 주요 장점은 대규모 pre-trained 코퍼스와 거대한 파라미터 크기이다. GPT-4[1]는 Text-to-SQL 연구에서 가장 일반적인 base model이며, GPT-3.5 시리즈도 강력한 baseline 모델 역할을 한다. 코드 생성에 특화된 CodeX 시리즈[14]는 Python과 같은 프로그래밍 언어에서 전문성을 보여 많은 Text-to-SQL 접근 방식에서 사용되었다. text-davinci-003 모델과 PaLM-2[2]도 일부 방법론에서 사용되었다. 폐쇄형 대규모 모델은 파라미터가 크고 독립적으로 배포하기 어렵기 때문에, 대부분의 연구에서는 API 호출을 통해 모델에 접근한다. 현재 SQL 코드 생성만을 위한 폐쇄형 LLM은 없는데, 이는 SQL의 개인 정보 보호 문제와 특정 언어 모델의 일반화 능력 때문이다.
6.1.2. Open-source Models
오픈 소스 모델은 적절한 파라미터 규모 덕분에 특정 하드웨어 지원을 통해 개인 도메인에 배포되거나 fine-tuning되는 경우가 많다. Llama 3 시리즈[26]는 8B와 70B 파라미터 크기로 나뉘며, Code Llama 시리즈[91]는 7B, 13B, 34B, 70B 파라미터 크기로 제공된다. Deepseek[21]과 QWen[124]도 다양한 파라미터 크기의 모델 유형을 나타내기 위해 버전 번호를 사용한다. 오픈 소스 대규모 모델 중 SQLCoder[98]는 Text-to-SQL 태스크에 특화된 모델 제품군이다. Fine-tuning 방식을 사용하는 연구에서는 LEVER[78]가 InCoder[30]와 CodeGen[79]을 fine-tuning했으며, Open-SQL[17]은 Llama 2와 Code Llama를 Text-to-SQL 도메인에서 fine-tuning했다.
6.2. Trend
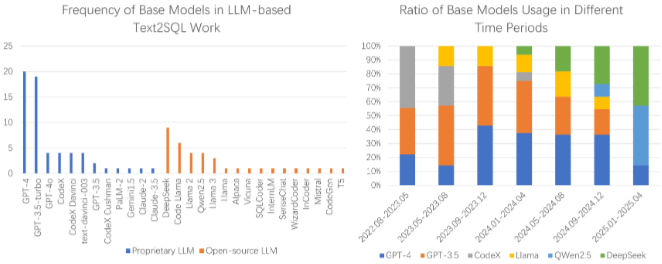
GPT-4[1]의 등장 이후 폐쇄형 LLM 중 GPT 시리즈 모델의 사용이 CodeX 시리즈보다 선호되었다. 오픈 소스 LLM 중에서는 Deepseek, Llama, Code Llama, QWen 시리즈가 주로 선택된다. 2023년에는 폐쇄형 모델의 사용 빈도가 증가했지만 2024년에는 감소한 반면, 오픈 소스 모델은 반대 경향을 보였다. 이는 오픈 소스 모델의 파라미터 크기 증가로 인해 개인 정보 보호 및 fine-tuning 능력을 유지하면서 태스크 성능을 향상시킬 수 있기 때문일 수 있다.
Key Takeaways:
- 현재 Text-to-SQL 태스크에서 폐쇄형 base model의 장점은 바로 사용 가능하며 강력한 코드 생성 능력을 가지고 있다는 점이다. 폐쇄형 모델과 prompt engineering 방법의 조합은 하드웨어 지원이 부족한 사용자에게 적합하다.
- 오픈 소스 base model의 장점은 독립적인 배포, 개인 정보 보호, 도메인 fine-tuning 능력이다. 하드웨어 지원이 있는 사용자는 오픈 소스 모델과 fine-tuning을 결합하여 in-domain Text-to-SQL 태스크를 수행할 수 있다.
- 기존 LLM 기반 Text-to-SQL 연구는 폐쇄형 모델 중 GPT 시리즈를, 오픈 소스 모델 중 DeepSeek, Llama, Code Llama, Qwen 시리즈를 선호한다.
- 현재 오픈 소스 모델은 점점 더 자주 사용되며 연구 측면에서 폐쇄형 모델과 동등한 사용률을 보인다.
7. 분석
각 방법론의 실질적인 가치와 적용 가능성을 알아보기 위해 기존 연구의 실험 결과를 비교 분석한다.
7.1. 벤치마크 선택
Spider 1.0[129], BIRD[60], Spider 2.0[55] 세 가지 벤치마크를 사용하여 성능을 평가한다. 각 벤치마크는 분야의 주요 도전 과제를 대표한다.
- Spider 1.0: Text-to-SQL 모델 성능 평가의 기본 데이터셋으로, 표준화된 스키마와 잘 정의된 복잡성 수준을 가진다.
- BIRD: noisy하고 불완전한 데이터베이스 값 처리, 외부 지식 통합과 같은 실제 문제를 다룬다.
- Spider 2.0: 복잡한 multi-database 환경, 다양한 SQL dialect, 데이터 변환에서 분석 쿼리에 이르는 광범위한 작업을 특징으로 하는 엔터프라이즈 수준 workflow로 범위를 확장한다.
전반적으로 이러한 데이터셋은 SQL 쿼리가 더욱 복잡하고 도전적으로 변하며 산업적 사용 사례를 밀접하게 반영하는 방향으로 발전하고 있음을 보여준다.
7.2. 평가 방법론
공정한 비교를 위해 Spider 1.0, BIRD, Spider 2.0의 공식 리더보드에서 EX 메트릭을 사용하여 결과를 추출한다. LLM을 활용한 접근 방식만 고려하고, 각 방법당 최대 두 개의 최고 성능 LLM을 포함하며, 2022년 이전에 출시된 모델 기반 방법은 제외한다. 문서화되지 않거나 재현 불가능한 방법도 제외한다.
7.3. 결과
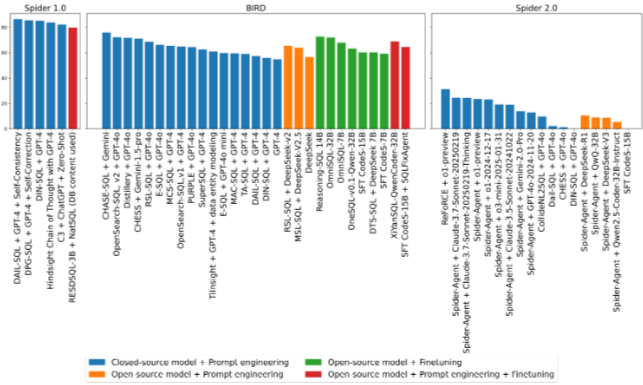
- Spider 1.0: 대부분의 LLM 기반 Text-to-SQL 접근 방식은 80% 이상의 통과율을 달성하며, LLM이 Spider 벤치마크에서 기본적인 Text-to-SQL 태스크를 효과적으로 해결했음을 보여준다.
- BIRD: 강력한 폐쇄형 및 오픈 소스 LLM이 prompting 전략과 결합되거나, fine-tuning을 통해 향상된 소규모 오픈 소스 LLM이 경쟁력 있는 SOTA 성능을 보인다. 이는 폐쇄형 및 오픈 소스 모델 간의 성능 격차가 크게 줄었음을 시사한다. OpenSearch-SQL[119], Distillery[74], MCS-SQL[54]과 같은 최고 성능 방법은 다음 두 가지 특징을 가진다.
- Inference-time Scaling: multi-SQL 생성, 수정 메커니즘, self-consistency 검사를 통합한다.
- Enhanced Schema Linking: irrelevant한 열에 대한 LLM의 내성이 높아짐에 따라 context length가 허용하는 한 많은 열을 포함하도록 권장하거나, schema linking을 통해 탐색 공간을 넓힌다.
- Spider 2.0: Spider-Agent[55]의 성능은 오픈 소스 모델이 상당한 진전을 이루었음에도 불구하고 여전히 독점 모델에 뒤처진다는 것을 보여준다. Reasoning이 강화된 모델은 지속적으로 더 강력한 성능을 보인다. 비-agent 접근 방식은 agent 기반 방법론에 비해 성능이 크게 떨어진다. REFORCE[22]와 같은 최근의 agent 기반 방법은 테이블 압축, structured output formatting, iterative column exploration, self-refinement pipeline과 같은 고급 기술을 통합하여 표준 Spider agent보다 뛰어난 성능을 보인다. 그러나 현재 SOTA 방법도 31.26%의 실행 정확도만을 달성하여 실제 배포와의 상당한 격차를 보여준다.
Key Takeaways:
- LLM은 Spider 1.0에서 뛰어난 성능을 보여주며, 기본적인 Text-to-SQL 태스크는 현대 모델에 의해 대부분 해결된다.
- 효과적인 inference-time 전략과 schema linking은 성능을 크게 향상시킬 수 있다.
- Spider 2.0은 실제 세계와의 격차를 드러내며, agent 기반 방법이 다른 방법보다 우수하지만 전반적인 실행 정확도는 여전히 낮다.
8. 미래 방향
LLM 기술이 Text-to-SQL 태스크를 크게 개선했음에도 불구하고, 고품질 Text-to-SQL parser를 개발하는 데에는 여전히 많은 어려움이 있다.
8.1. 오류 분석 개요
기존 연구[17, 25, 85, 137]는 SPIDER 및 BIRD 데이터셋에 대해 오류 분석을 수행했다. 오류 분류는 생성된 SQL에서 오류가 발생하는 구성 요소(schema-linking, join, nested, group by, others)를 기반으로 한다. schema-linking의 평균 오류율이 29%-49%로 가장 높으며, join은 21%-26%, GROUP BY 및 nested는 20% 미만이다. 이는 schema-linking이 Text-to-SQL 태스크에서 가장 개선이 필요한 모듈임을 보여준다.
8.2. 실제 도전 과제 및 방향
8.2.1. Privacy Concern
ChatGPT 및 GPT-4와 같은 API 호출 모델은 프롬프트 전송 시 개인 정보 유출 가능성으로 인해 개인 정보 보호 문제가 발생한다. 오픈 소스 LLM의 개인 배포 및 fine-tuning은 이 문제에 대한 해결책이 될 수 있지만, dirty data, LLM의 다른 능력 저하, catastrophic forgetting과 같은 문제가 발생할 수 있다. 고품질 훈련 데이터 추출이 이러한 fine-tuning 문제를 해결하는 데 도움이 될 수 있다.
8.2.2. Complex Schema and Insufficient Benchmark
실제 Text-to-SQL 태스크의 테이블 스키마는 현재 연구 벤치마크보다 훨씬 복잡하다. Microsoft의 내부 금융 데이터 웨어하우스는 632개의 테이블과 4000개 이상의 열을 포함한다. 이러한 데이터베이스에서의 Text-to-SQL 태스크는 schema linking의 어려움, 많은 토큰으로 인한 LLM의 주의 산만, 긴 추론 시간과 같은 두드러진 문제를 보인다. 현재 표준 데이터셋은 이러한 복잡성을 모델링하지 못한다. 동적 그래프 어텐션 메커니즘과 같은 신흥 개발은 테이블, 열 및 쿼리 간의 관계를 모델링하는 유망한 기회를 제공한다.
8.2.3. Domain Knowledge
LLM은 광범위한 일반 지식을 갖추고 있지만, 데이터 분석 및 배치 처리와 같은 실제 응용 프로그램은 산업 용어, 약어 및 전문 용어를 포함하는 도메인 특화 지식을 요구한다. 이러한 지식 없이는 LLM이 쿼리를 잘못 해석하거나 부정확하게 응답하는 경우가 많다. 도메인 적응은 prompt engineering(RAG 활용)과 fine-tuning을 통해 이루어질 수 있지만, 둘 다 상당한 도전 과제에 직면한다. RAG는 고품질의 구조화된 지식 베이스를 요구하며, fine-tuning은 catastrophic forgetting의 위험이 있고 미래 적응성을 제한한다.
8.2.4. Autonomous Agents
ReAct 프레임워크를 기반으로 LLM이 주도하는 자율 에이전트를 개발하는 것이 가능해졌다. LLM은 에이전트의 핵심으로서 환경, 인간 및 다른 에이전트와의 상호 작용을 조율하고, 단기 및 장기 기억을 활용하여 태스크 실행을 반복적으로 개선한다. 인간의 SQL 구성이 실행 및 수정의 시행착오 주기를 포함한다는 점에서 에이전트를 Text-to-SQL에 적용하는 것이 적합하다. REFORCE[22]와 Spider 2.0[55]은 Text-to-SQL 태스크에 자율 에이전트를 명시적으로 채택한 첫 번째 프레임워크이다. Spider 2.0 리더보드의 결과는 전통적인 비-agent 방법이 agent 기반 접근 방식에 비해 성능이 떨어진다는 것을 보여준다.
8.2.5. Data Governance
현재 Text-to-SQL 데이터셋의 두 가지 주요 한계는 ambiguity와 semantic mismatch이다. Ambiguity는 여러 의미론적으로 다른 SQL 쿼리가 동일한 자연어 질문에 유효한 답변을 산출할 때 발생하며, 모델 정확성 평가를 복잡하게 만든다. Semantic mismatch는 사용자 쿼리가 기본 데이터베이스에서 답변될 수 없는 의도를 반영할 때 발생한다. LLM 기반 Text-to-SQL 시스템에서 데이터 거버넌스는 세 가지 주요 이점을 제공한다: (1) 도메인 지식 구조화는 RAG 효율성을 높이고 자연어 쿼리와 실행 가능한 논리 간의 정렬을 개선하여 ambiguity를 줄인다; (2) 훈련 데이터 품질 향상은 fine-tuning 동안 LLM의 도메인 특화 능력을 강화한다; (3) semantic mismatch를 해결하기 위한 벤치마크 데이터셋 개선은 실제 시스템 성능의 보다 robust한 평가를 가능하게 한다.
9. 결론
이 논문은 LLM을 Text-to-SQL 태스크에 활용하는 것에 대한 포괄적인 검토를 제공한다. 고전적인 벤치마크와 평가 메트릭을 열거한다. prompt engineering과 fine-tuning이라는 두 가지 주요 방법론에 대한 포괄적인 taxonomy를 제시하고, 각 하위 범주에 대한 실용적인 통찰력을 제공한다. 잘 알려진 데이터셋에서 평가된 다양한 방법과 모델에 대한 전반적인 분석을 제시하고 몇 가지 통찰력을 추출한다. 마지막으로 이 분야의 도전 과제와 미래 방향을 논의한다.
