
Introduction

초기 LLM은 영어에 중점을 두었지만, 최근 모델들은 다국어 기능을 강화하고 있다.
하지만 비영어권 사용자들은 여전히 높은 지연 시간, 비용 증가, 성능 저하 등으로 인해 불편을 겪을 때가 있다.
LLM은 사용자의 의도를 이해하고 문법, 스타일, 어조와 같은 '형식'과 사실성, 일관성과 같은 '내용' 측면에서 적절한 응답을 제공해야 한다.
Language Confusion은 LLM이 사용자가 원하는 언어나 문맥에 맞는 적절한 언어로 텍스트를 일관되게 생성하지 못하는 형식적 한계를 말한다.
언어 혼란의 다양한 유형 (Figure 1):
- Full-response Confusion : LLM이 아랍어 프롬프트에 대해 완전히 영어로 응답하는 것처럼, 전체 응답이 의도하지 않은 다른 언어로 생성되는 경우
- Line-level Confusion : 응답 내 일부 줄은 요청된 언어로, 다른 줄은 다른 언어로 생성되는 경우
- Word-level Confusion : 응답 내에 단일 단어나 구절이 의도하지 않은 다른 언어로 간헐적으로 삽입되는 경우
이러한 언어 혼란 실패를 체계적으로 평가하기 위해 본 연구에서는 Language Confusion Benchmark (LCB)를 개발했다.
LCB는 유형학적으로 다양한 15개 언어를 포함하며, 기존 및 새롭게 생성된 영어 및 다국어 프롬프트를 활용한다.
해당 벤치마크는 효율적이고 확장 가능한 다국어 평가의 첫 단계 역할을 한다고 주장한다.
연구 결과를 요약하면 다음과 같다.
- Llama Instruct 및 Mistral 모델은 높은 수준의 Language Confusion 을 보이며, SOTA 모델조차도 원하는 언어로 일관되게 응답하지 못한다.
- base 모델과 영어 중심의 instruction-tuned 모델이 언어 혼란에 더 취약하며, 복잡한 프롬프트와 높은 샘플링 temperature는 이러한 혼란을 악화시킨다.
- few-shot prompting, 다국어 SFT, preference tuning을 통해 언어 혼란을 부분적으로 완화할 수 있음을 발견했다.
본 연구의 기여를 요약하면 다음과 같다.
- LLM의 언어 혼동 문제를 식별하고 기술
- LLM의 언어 혼동을 측정하기 위한 새로운 벤치마크와 평가지표를 제시
- 다양한 LLM에 대한 체계적 평가를 수행하여, 실제로 언제 언어 혼동이 발생하는지 조사
- LLM의 언어 혼동을 완화하기 위한 방법을 제안
Language Confusion Benchmark
자연스러운 코드 스위칭 데이터에서 LLM 성능을 평가하는 데이터셋은 몇 가지가 있지만 LLM의 Language Confusion을 평가하도록 설계된 데이터셋은 없다. 본 연구는 계통적으로 다양한 언어들에서 현실적인 사용 사례를 반영한 다양한 프롬프트를 모아 Language Confusion Benchmark(LCB) 를 만들었다.
2.1 Generation settings
두 가지 설정에서 Language Confusion을 측정한다: 단일언어 생성과 교차언어 생성.
단일언어 생성
화자가 언어 l 로 모델에 질의하고, l 로 된 응답을 기대하는 경우다. 사용자가 보통 모국어로 기술과 상호작용하길 선호하기 때문에 가장 흔한 사용 시나리오다.
교차언어 생성
사용자가 언어 l 로 모델에게 지시해, 다른 언어 l′ 로 요청을 수행하게 하는 설정이다. 이 설정에서는 요청된 언어 l′ 가 지시 언어 l 과 다르다. 이 설정은 다국어 출력을 요구하지만 각 입력 언어마다 프롬프트를 최적화하는 게 비효율적인 애플리케이션, 혹은 사용자가 자신이 모르는 언어로 생성을 원할 때에 유용하다. 본 연구는 지시 언어를 영어로 설정한다.
2.2 Language Confusion Metrics
Language Confusion을 탐지하기 위해, 우리는 off-the-shelf 언어 식별(LID) Tool을 사용한다. LLM 기반 평가의 강력한 대안으로 fastText를 채택한다.
줄 단위 탐지
응답을 줄바꿈 문자 기준으로 줄로 나눈 뒤, 각 줄이 사용자가 원하는 언어와 일치하는지 fastText로 확인한다.
단어 단위 탐지
기성 도구는 단어 단위 LID를 지원하지 않고, LLM들도 단어 수준 코드 스위칭 탐지에서 F1 79–86에 그쳐 자동 평가자로 쓰기엔 부족하다. 상위권 LLM에서 단어 수준 혼동이 주로 영어에서 발생하는 점을 관찰해, 정밀도가 높은 일부 언어에 한정한 휴리스틱 평가를 택한다. 구체적으로는 비라틴 문자권 언어에 집중해, 라틴 문자(영어) 단어를 쉽게 식별한다. 자연스러운 코드 스위칭을 거짓 양성으로 잡지 않기 위해, 목표 언어 텍스트에 보통 등장하지 않는 영어 단어를 검사한다. 본 연구는 아랍어(ar), 힌디어(hi), 일본어(ja), 한국어(ko), 러시아어(ru), 중국어(간체, zh) 에 대해 단어 수준 혼동을 평가한다.
이진 평가(binary evaluation)
응답이 올바른 언어로 완전히 작성된 경우에만 정답으로 본다. 언어 혼동이 한 번이라도 발생하면 이해 가능성을 해치고 사용자 경험에 큰 위화감을 주기 때문이다. 우리는 다음의 이진 지표를 계산한다. a) 잘못된 언어로 된 줄이 하나라도 있는지, b) 비라틴 문자권 언어들에서 영어 단어/구가 고립되어 삽입됐는지.
-
LPR: 줄 수준 언어 혼동 탐지기를 에러 없이 통과한 모델 응답의 비율. 모든 줄이 사용자가 원하는 언어와 일치하면 “정답”으로 본다.
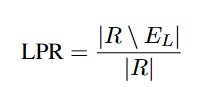
여기서 (R)은 모든 응답의 집합, (E_L)은 줄 수준 오류가 있는 응답의 집합이다.
-
단어 수준 통과율(WPR): 모든 단어가 원하는 언어에 속하는 응답의 비율. 줄 수준 오류가 있으면 대부분 단어 수준 오류에도 해당되어 두 오류 유형을 구분하기 어려우므로, 줄 수준 오류가 없는 응답만 모수에 포함한다. 단어 수준 혼동 탐지는 매우 어렵기 때문에 비라틴 문자권 목표 언어에서 잘못된 영어 단어만 찾는다(가장 흔한 단어 수준 혼동 유형).
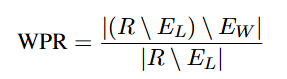
여기서 (R)은 모든 응답의 집합, (E_L)은 줄 수준 오류가 있는 응답 집합, (E_W)는 단어 수준 오류가 있는 응답 집합이다.
-
언어 혼동 통과율(LCPR): LPR과 WPR의 조화평균.
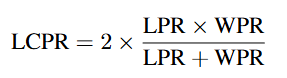
LCPR은 올바른 언어로 출력을 내는 데 심각한 문제가 있을 때 특히 유용한 지표다.
2.3 Data sources
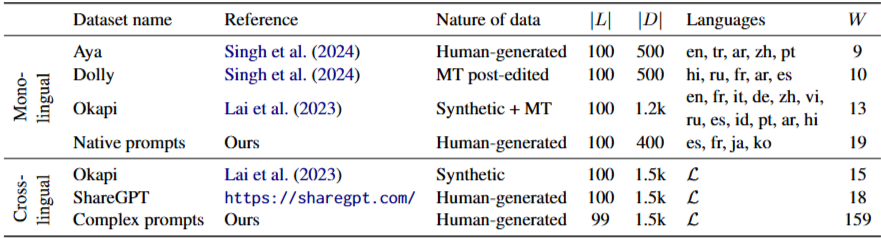
단일언어 과제와 교차언어 과제는 각각 총 2,600개와 4,500개 프롬프트로 구성되며, 영어, 프랑스어, 독일어, 스페인어, 포르투갈어, 이탈리아어, 일본어, 한국어, 중국어, 아랍어, 터키어, 힌디어, 러시아어, 인도네시아어, 베트남어 등 15개의 계통적으로 다양한 언어를 다룬다. 자세한 내용은 표 1에 나와 있다.
프롬프트는 아래 데이터셋에서 가져오되, 사람이 주석/편집한 프롬프트에 중점을 둔다. 각 데이터셋은 언어 혼동 평가에 가장 적합하도록 필터링한다.
-
Aya
Aya Evaluation Suite의 aya-human-annotated 서브셋에서 7개 언어별로 각 250개의 사람이 직접 작성한 원문 프롬프트. -
Dolly
Dolly 프롬프트를 6개 언어로 기계 번역 후 유창한 화자가 후편집한 자료에서 200개. -
Okapi
Okapi의 multilingual-alpaca-52k 서브셋 사용. Alpaca의 영어 지시문 52k개를 ChatGPT가 번역 생성한 26개 언어 자료. -
ShareGPT
ShareGPT API가 종료되기 이전에 크롤링된, 대부분 영어인 ChatGPT 사용자 대화 9만 건의 첫 턴에서 프롬프트를 사용. -
자체 수집 Native prompts (Ours)
위 데이터셋에서 상대적으로 덜 대표된 일본어와 한국어, 그리고 스페인어, 프랑스어에 대해, 원어민 주석자를 고용해 프롬프트를 추가로 수집. -
자체 수집 Complex prompts (Ours)
위 출처의 프롬프트가 비교적 단순하므로, 사람 주석자들이 작성한 복잡한 영어 프롬프트도 수집.
2.4 Data Filtering and Processing

LID 적합성
LID 도구는 짧은 시퀀스나 비표준 텍스트에서 성능이 낮기 때문에, 우리는 다음을 수동으로 걸러낸다:
a) 단어/구 한 개로 답할 수 있는 예시, b) 객관식 질문이나 목록을 요구하는 프롬프트, c) 코드 생성·수식·HTML 같은 데이터 포맷을 요구하는 프롬프트. 또한 완료본(completion)이 제공되는 데이터셋의 경우, 가장 긴 완료본(예: 4단어 초과)을 우선한다.
서구 중심 응답
번역으로 만들어진 데이터셋에는 미국 국립공원, 대통령, 미국 브랜드처럼 서구 중심 개념에 관한 질문이 많아, 우리의 단어 수준 탐지기에서 거짓 양성이 날 수 있다. 이런 질문들은 수동으로 제거한다.
프롬프트 형식
교차언어 생성의 경우, 목표 언어로 생성하라는 지시를 프롬프트에 반자동으로 덧붙여 수정한다. 단일언어 생성에는 프롬프트를 원형 그대로 사용한다. 몇 가지 예시는 표 2에 제시한다.
요청한 대로 각주·연도 표기 등을 제거하고, ~이다 / ~다 체로 이어서 정리한다.
3 Experiments
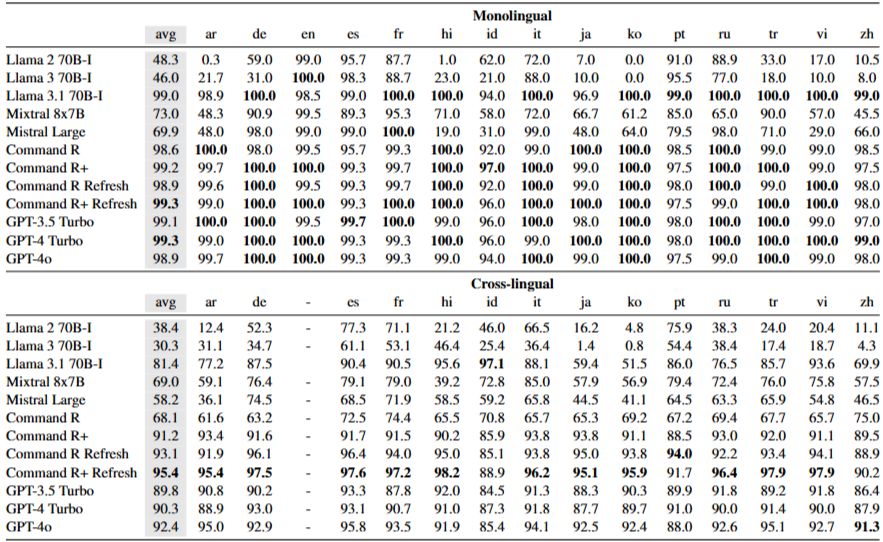
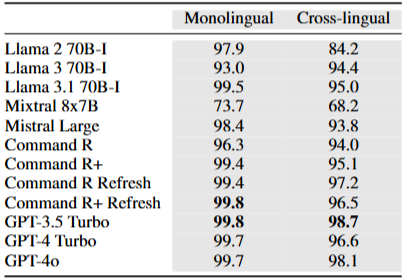
Models
Llama 2 70B Instruct, Llama 3 70B Instruct, Command R(35B), Command R+(104B), Mixtral 8x7B, Mistral Large, GPT-3.5 Turbo, GPT-4 Turbo. Llama와 Command는 베이스 버전도 함께 평가한다. 프롬프트당 최대 100토큰을 생성하며, nucleus 샘플링 p=0.75, T=0.3으로 설정한다.
Monolingual generation
Command와 GPT 계열은 줄 수준에서 평균적으로 우수하다(LPR 98.6–99.3%). 반면 Llama와 Mistral은 올바른 언어를 일관되게 생성하는 데 어려움을 보인다(LPR 48.3–73.0%). Mistral Large는 일부 유럽어에서 더 낫지만, Llama는 독일어 같은 고자원 언어에서도 언어 혼동이 나타난다. 대부분의 모델은 WPR이 유사한 범위지만 Mixtral 8x7B는 눈에 띄게 낮다. LCPR은 GPT-4 Turbo가 가장 높고, GPT-3.5 Turbo와 Command R+가 공동 2위이다. Llama의 영어 응답 선호가 매우 낮은 LCPR로 이어진다.
Cross-lingual generation
보다 어려운 교차언어 설정에서는 최상위 모델들의 LPR이 90% 초반대이다. 전반적으로 Command와 OpenAI 계열이 가장 우수하며, 그중 Command R+가 종합 최상위이다. Llama는 영어로 응답하는 경향 때문에 두 모델 모두 30%대 LPR로 성능이 낮다. Mistral Large는 유럽어에서도 Mixtral보다 뒤처진다. 비라틴 문자권 언어에서도 Command R+와 OpenAI 계열이 다시 최상위이다. LCPR 추세는 단일언어와 비슷하지만 절대 점수는 더 낮다. GPT-3.5 Turbo가 가장 높고, Command R+와 GPT-4 Turbo가 그 뒤를 잇는다. 단일언어와 달리 교차언어에서는 Command R이 R+보다 현저히 낮다.
4 Analyses
4.1 Impact of dataset
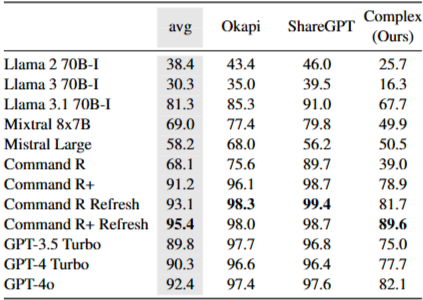
언어 혼동 테스트셋은 다양한 사용 사례와 도메인을 포괄하도록 구성한다. 단일언어에서는 데이터셋 간 LPR 차이가 작다. 교차언어에서는 차이가 더 뚜렷하다. Okapi와 ShareGPT에서는 비교적 성능이 양호하지만, 자체 수집한 Complex 프롬프트에서는 성능이 크게 낮아지며 난도가 높음을 시사한다. WPR과 LCPR도 유사한 경향을 보인다.
4.2 Impact of prompt length
Complex 프롬프트의 어려움이 길이 때문인지 확인하기 위해 프롬프트를 짧음/중간/김의 세 구간으로 나누어 LPR을 비교한다. 뚜렷한 패턴은 관찰되지 않는다. 즉, 혼동 증가는 길이보다 프롬프트 복잡도의 영향일 가능성이 크다.
4.3 Impact of instruction position
교차언어 프롬프트의 출력 언어 지시는 시작, 끝, 또는 문장 내부에 통합하는 방식으로 제시된다(예: “한국어로 에세이를 작성하라”). 모든 모델에서 분리된 지시문은 줄 수준 혼동이 낮고, 시작이든 끝이든 성능이 비슷하다. 통합 지시문은 혼동을 더 많이 유발한다. 예를 들어 Command R은 통합형에서 LPR 69%, 분리형에서 약 85%이다. 원샷 프롬프트를 추가하면 이 어려움이 크게 줄어 LPR 약 80.6%까지 개선된다.
4.4 Impact of quantization
양자화는 고정밀 가중치와 활성화를 저정밀로 매핑하여 저장 공간과 추론 비용을 줄이는 대신 성능 저하를 초래할 수 있다. 단일언어 설정에서 Command R+를 대상으로 FP16과 W8, W8A8, W4 변형을 비교한다. W4에서 부정적 효과가 나타난다.
4.5 Impact of instruction tuning
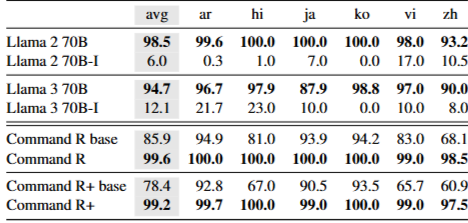
단일언어 설정에서 Llama와 Command의 베이스와 인스트럭션 튜닝 변형을 비교한다. Command R는 튜닝 버전이 베이스보다 언어 혼동이 적다. 반대로 Llama는 튜닝 버전에서 혼동이 훨씬 심해지며, 영어 중심 인스트럭션 튜닝의 영향을 시사한다. 이는 이후 제안하는 완화 실험으로도 확인된다.
5. When does language confusion occur?

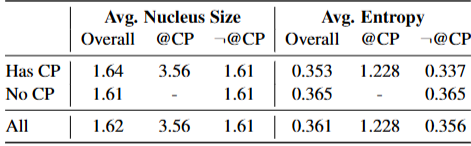
프롬프트 표본을 분석해 language confusion이 어디서 발생하는지 살핀다. 원하지 않는 언어의 token에 충분한 확률이 부여되면 샘플될 수 있다. 다음 token 분포가 납작하고(flat), nucleus가 큰 상황에서 language confusion이 주로 발생하는 경향이 있다.
Okapi의 중국어 프롬프트 15개에 대해 Command R로 응답을 생성한다. 15개 중 5개에서 영어 혼입이 관찰된다. 최초로 영어 token이 끼어든 위치를 confusion point (CP) 라 부른다. 총 9개의 CP가 확인된다.
각 스텝에서 Shannon entropy와 nucleus size를 계산한다. 한 예시에서 CP 시점의 후보 중 “called”가 세 번째로 가능성이 높았으나(정규화 확률 0.221) 샘플될 만큼 확률이 컸다. 프롬프트당 100 tokens를 생성하므로 전체 1,500 스텝 중 9개가 CP이며, 나머지는 비 CP이다.
6. Mitigating language confusion
6.1 Reducing temperature and nucleus size
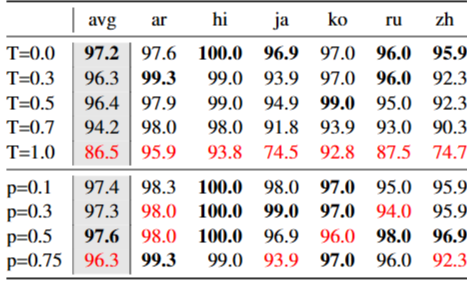
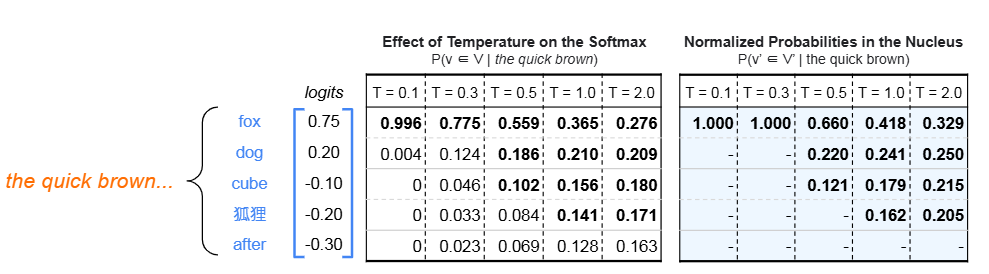
샘플링 하이퍼파라미터를 조정하면 추론 시 선택되는 tokens가 달라진다. language confusion을 샘플링의 바람직하지 않은 부작용으로 보고, 분포를 더 sharp하게 만들면 혼동을 줄일 수 있다.
temperature (T) 와 nucleus (p) 를 조절해 오답 언어 token이 선택될 확률을 낮춘다. 단일언어 설정에서 Command R의 WPR을 보면 T가 높을수록 혼동이 커진다. T=1에서 평균 WPR이 83.5%이며, 일본어 72.0%, 중국어 69.5%까지 하락한다. p 조정의 효과는 상대적으로 작다.
6.2 Few-shot prompting
instruction tuning이 되지 않은 모델은 지시를 기대대로 따르지 못하는 경우가 있다. 비영어 지시에서 Command R Base는 답변 대신 번역하는 경향이 있다. 이에 영어 prompt/answer 예시 5쌍을 선별해 번역한 few-shot 예시로 가이드한다. 교차언어 생성에서는 테스트셋과 유사한 템플릿을 사용하고, 비교를 위해 one-shot도 적용한다.
few-shot prompting은 Command R Base의 language confusion을 크게 줄이며 단일언어에서는 거의 제거한다. 반면 Command R에 one-shot을 넣으면 단일언어 성능은 악화되지만, 교차언어 지시 준수에는 도움이 된다.
6.3 Multilingual instruction tuning
영어 중심과 다국어 중심 instruction tuning의 영향을 비교한다.
- English-only tuning: 영어 전용 SFT 이후 영어 전용 preference tuning을 적용한다.
- Multilingual tuning: 영어 데이터에 다국어 데이터를 보강한다(다국어 비중은 제한적).
결론적으로 English-only tuning은 단일언어 환경에서 language confusion을 악화한다. 특히 영어 전용 preference tuning은 word-level 혼동에 부정적이다. 반면 다국어 비중이 10% 수준이어도 SFT만으로 line-level 혼동은 단일언어에서 거의 제거된다. 교차언어에서는 multilingual tuning이 line-level 성능을 영어 전용 대비 확실히 높이지는 못한다. 교차언어 데이터가 영어 지시문 기반이어서, 모델이 “Reply in French” 같은 영어 지시를 따르는 능력이 더 중요하게 작용하기 때문일 수 있다.
7. Discussion
Behavior of base models
base 모델의 language confusion은 downstream 성능과 강하게 상관하지 않는다. 더 강한 base(예: Command R+, Llama 3 70B)가 오히려 더 혼동되는 경우가 있다. 사전학습에서 번역·타언어 tokens 노출이 존재하므로 일정 수준의 언어 전환이 나타나며, 이후 instruction tuning이 원하는 거동을 강화하는 것으로 보인다.
English-centricity
LLM의 다국어 생성 능력이 인상적임에도, 문장·단어 수준에서 English로 전환될 가능성이 가장 높다는 점은 영어 중심성을 다시 보여준다. 과도하게 영어 중심인 instruction tuning이 부정적 영향을 준다는 사실은 실험으로 확인된다. Llama Instruct 계열의 높은 language confusion이 이를 방증한다.
Preference tuning
일부 설정에서 preference tuning 이후 WPR이 감소한다. DPO 등 방법이 진행되며 일부 분포에서 선호·비선호 예시 모두의 우도가 낮아지는 현상과, out-of-distribution 응답을 편향적으로 선호하는 정책이 생길 수 있다는 보고가 있다. 학습 중 자주 본 tokens(예: 흔한 English 단어)의 우도가 낮아지면 상대적으로 희소 tokens의 상대우도가 올라가 word-level 혼동(WPR 하락)으로 이어질 수 있다. preference 학습이 language confusion 같은 바람직하지 않은 거동을 유발하는지 추가 검증이 필요하다.
Other factors
word-level 혼동은 under-training과도 관련될 수 있다. 사전학습에서 드물게 등장하는 비영어 tokens(저밀도 영역)이 충분히 보정되지 못하면, 동일 언어의 더 높은 우도 token이 부족해 상대적으로 English token이 샘플될 수 있다. 후속 연구가 이 가설을 검증할 필요가 있다.
9. Conclusion
본 연구는 LLM의 language confusion을 평가하는 Language Confusion Benchmark를 제안한다. 일부 LLM은 여러 언어에서 심각한 language confusion을 보이며, 가장 강력한 모델도 교차언어 설정에서 완전한 성능에 도달하지 못한다. base와 영어 중심 instruction 모델이 특히 취약하며, complex prompts가 혼동을 악화한다. 추론 단계에서는 temperature/nucleus 축소, few-shot prompting을, 학습 단계에서는 multilingual instruction tuning을 제안한다. 제안한 벤치마크는 평가가 효율적이고 확장이 용이하며, 모델이 언어 간 equal utility를 달성하는 데 기여할 수 있다.
