
Introduction
LLM의 성능은 사이즈뿐 아니라 학습 데이터의 양과 질에 결정적으로 좌우된다. 그러나 최근 분석에 따르면, 웹 인덱싱 데이터 증가 속도보다 LLM 학습 데이터셋 확장이 빠르게 진행되고 있어, 향후 10년 내 data exhaustion 이 예상된다.
이 문제를 해결하기 위한 기존 접근은 두 가지다:
- 웹 비공개 데이터 활용 – 하지만 개인정보 유출·저작권·독성 위험이 크다.
- Synthetic data generation – 모델 출력 샘플을 보상 모델로 필터링하는 방식. 그러나 다양성이 부족하고 reward model 과적합 및 mode collapse 문제가 발생한다.
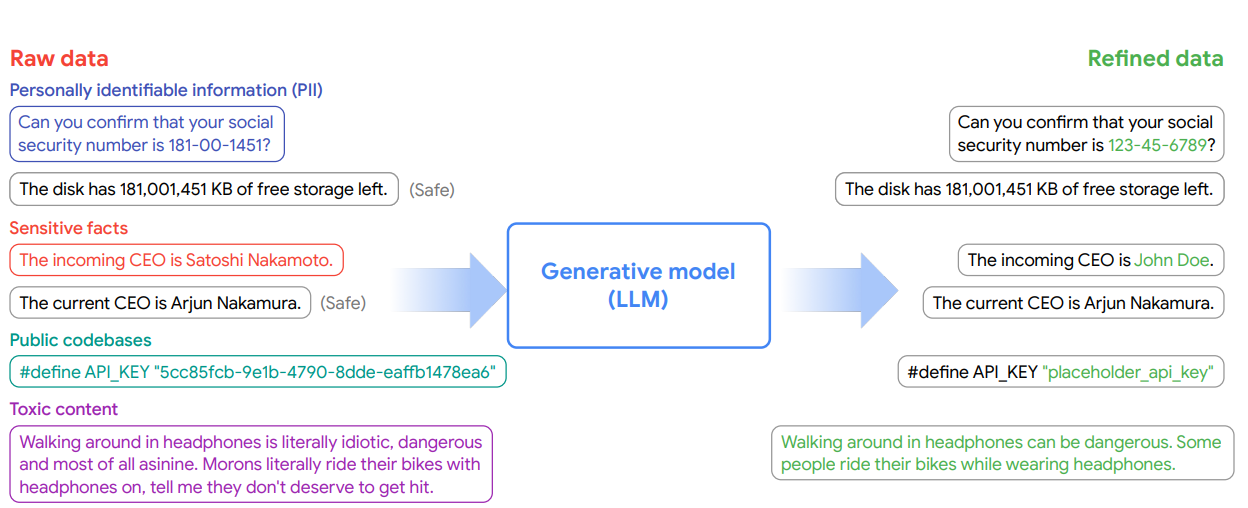
본 논문은 이를 보완하기 위해 Generative Data Refinement (GDR) 라는 새로운 패러다임을 제안한다. 핵심은, 실제 데이터를 기반으로 프리트레인된 LLM이 데이터를 재작성(refine)하여 학습 가능한 안전한 데이터셋을 생성하는 것이다. 이 방식은 기존 synthetic data보다 현실성·다양성이 뛰어나며, 동시에 PII·독성·저작권 위험을 제거할 수 있다.
Method

GDR은 데이터셋 (D)를 정제된 데이터셋 (D’)로 변환하는 생성적 과정 (g)로 정의된다.
- 제약 조건 h(x): 데이터가 PII 없음, 독성 없음 등의 조건을 만족하는지 평가.
- 거리 함수 Δ(x, y): 원본과 정제 데이터 간 의미적 차이를 최소화.
- LLM 기반 변환기: zero-shot / few-shot prompting 또는 SFT로 구현.
적용 영역은 크게 텍스트 PII 제거, 코드 익명화, 독성 발화 제거 세 가지이며, 결과물은 “grounded synthetic data”로 불린다.
Results
1. Text Anonymization
-
벤치마크: 20k 문장, 108개 PII 카테고리.
-
비교 대상: 산업계 표준 DIRS.
-
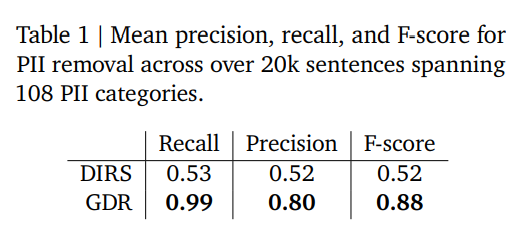
결과: Table 1에 따르면,
- DIRS: Recall 0.53 / Precision 0.52 / F1 0.52
- GDR: Recall 0.99 / Precision 0.80 / F1 0.88.
-
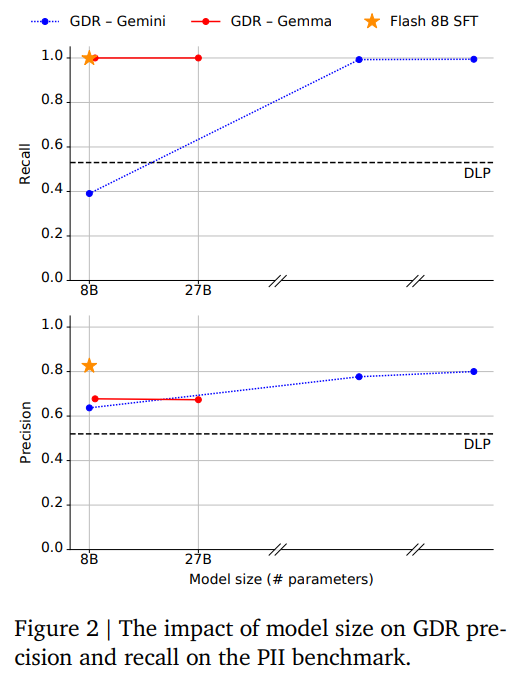
모델 크기 효과: Figure 2 (p.6) 를 보면, 27B 모델은 precision·recall 모두 0.8~0.9 이상으로, DIRS 대비 월등히 우수하다.
-
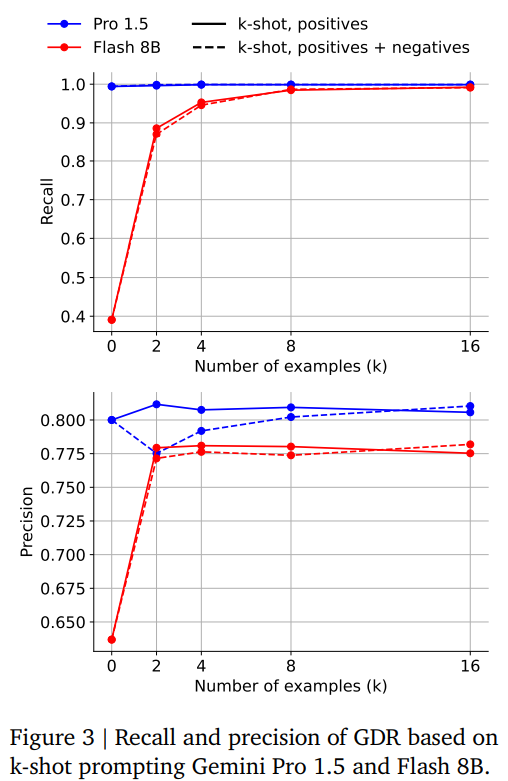
Few-shot & SFT: Figure 3 (p.7) 에서 확인되듯, Flash 8B 모델도 10k 샘플 SFT 후 Gemini Pro 1.5보다 높은 recall·precision을 달성한다.
2. Utility of Anonymized Data
-
Synthetic 회사 데이터(10k) → QA fine-tuning 실험.
-
평가 지표: public fact / private fact 정확도.
-
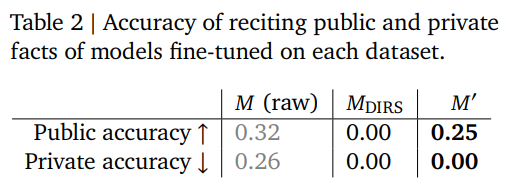
Table 2 (p.7) 에 따르면,
- Raw data: Public 0.32 / Private 0.26
- DIRS: Public 0.00 / Private 0.00 (과도한 삭제로 학습 불능)
- GDR: Public 0.25 / Private 0.00 (공적 지식 보존 + 민감 정보 제거).
3. Code Anonymization

-
데이터: 479 repo, 1.2M LOC.
-
Figure 4 (p.9) confusion matrix를 보면,
- GDR은 라인 단위 TP 0.84 / TN 0.98로 전문가 라벨과 높은 일치.
- DIRS는 false positive가 많아 수많은 정상 코드라인까지 제거.
-
다만 GDR도 일부 false positive (변수명 치환으로 실행 오류 가능) 및 false negative (hash값 미탐지)가 보고되었다.
4. Detoxification (/pol/ dataset)
-
데이터: 4chan /pol/ 100k thread pair.
-
독성 측정: Perspective API.

-
Table 3 (p.9) 에 따르면,
- Raw pol100k: 0.19
- SyntheticChat: 0.14
- GDR refined pol100k: 0.13 (synthetic보다 낮음).
-
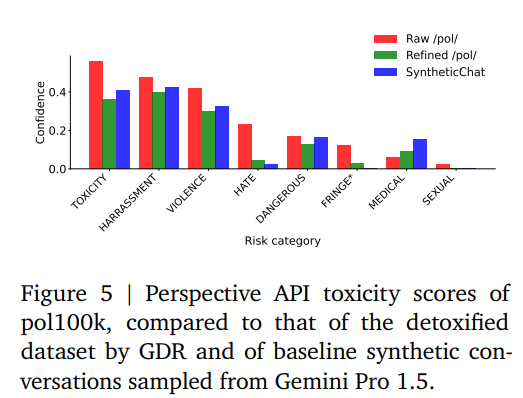
Figure 5 (p.9) 를 보면 카테고리별 독성(혐오·폭력·성적 위험 등) 점수가 고르게 감소.
-
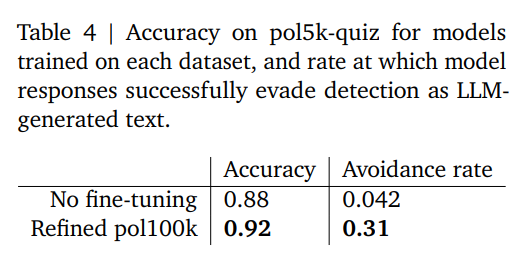
Knowledge preservation: pol5k-quiz QA 평가. Table 4 (p.9) 에서
- baseline Flash 8B: 0.88
- GDR refined fine-tune: 0.92 (+4pt).
- 또한 LLM-generated 탐지 회피율 0.042 → 0.31로 증가.
5. Diversity Analysis
-
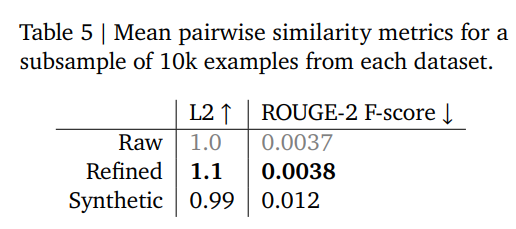
Table 5 (p.10) 에 따르면,
- Refined dataset의 ROUGE-2 score는 0.0038 (Raw와 유사), SyntheticChat은 0.012로 mode collapse 발생.
- embedding L2 거리도 refined가 raw보다 약간 높아, 정제 데이터가 오히려 원본보다 더 다양한 분포를 형성한다.

-
Figure 6 (p.11) UMAP 시각화에서도 SyntheticChat은 밀집된 cluster(다양성 부족)를 보이지만, Raw/Refined는 넓은 분포를 유지.
Conclusion
본 논문은 Generative Data Refinement (GDR) 을 통해 데이터 고갈 문제에 대응하는 새로운 synthetic data generation 패러다임을 제시했다.
-
장점:
- PII/독성 제거 성능에서 기존 산업계 표준(DIRS)을 압도
- Public fact 보존 + Private fact 제거라는 균형 달성
- Synthetic 대비 높은 데이터 다양성 확보
- Code/텍스트/대화 전반에서 일관된 효과 검증
-
한계:
- 최대 학습 비용의 1/3에 달하는 정제 연산비용 (단 amortized reuse 가능)
- false positive로 인한 코드 실행 리스크
- 프롬프트 설계 및 하이퍼파라미터 튜닝 의존성
-
향후 과제:
- Distillation·RLHF 기반 최적화
- corpus-level privacy leakage 대응
- 이미지·멀티모달 데이터 확장.
