
Introduction
정보 접근은 인간의 기본적인 일상적 요구로 원하는 정보를 신속하게 획득하고자 하는 요구를 충족시키기 위해 다양한 정보검색(IR) 시스템이 개발되었다.
- Sequential matching network: A new architecture for multi-turn response selection in retrieval-based chatbots
- From eliza to xiaoice: challenges and opportunities with social chatbots
- Dense passage retrieval for open-domain question answering
- Image retrieval: Ideas, influences, and trends of the new age
IR 시스템의 핵심 기능은 텍스트, 이미지, 음악 등과 같은 다양한 유형의 정보를 포함하여 사용자가 발행한 쿼리와 검색할 콘텐츠 간의 관련성을 결정하는 것을 목표로 하는 검색이다.
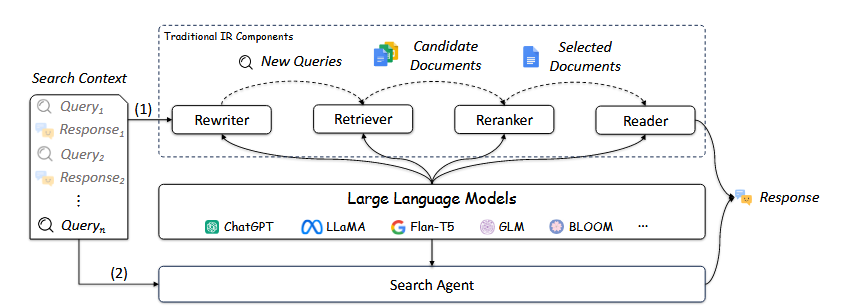
사용자 경험을 개선하기 위해 upstream (query reformulation)과 downstream (reranking and reading) 관점 모두에서 검색 성능이 향상되었다.
upstream
- Query reformulation for dynamic information integration
- Analyzing and evaluating query reformulation strategies in web search logs
downstream
- Multistage Document Ranking with BERT
- Document Ranking with a Pretrained Sequence-to-Sequence Model
- Contrastive Learning of User Behavior Sequence for Context-Aware Document Ranking
upstream 기술인 query reformulation은 관련 문서를 검색하는 데 더 효과적이도록 사용자 쿼리를 개선하도록 설계되었다. 최근 대화형 검색의 인기가 높아짐에 따라 이 기술에 대한 관심이 높아지고 있다.
downstream에서는 문서 순위를 추가로 조정하기 위해 reranking 접근 방식이 개발되었다. 검색 단계와 달리 검색자가 이미 검색한 제한된 관련 문서 집합에 대해서만 reranking이 수행된다. 이러한 상황에서는 더 높은 효율성을 유지하기보다는 더 높은 성과를 달성하는 데 중점을 두어 reranking 프로세스에서 보다 복잡한 접근 방식을 적용할 수 있다.
또한 reranking은 개인화 및 다양화와 같은 기타 특정 요구 사항을 수용할 수 있다. 검색 및 reranking 단계 후에는 검색된 문서를 요약하고 사용자에게 간결한 문서를 전달하기 위해 읽기 구성 요소가 통합된다.
personalization
- Personalizing search via automated analysis of interests and activities
- Modeling the impact of short- and long-term behavior on search personalization
- Personalizing search results using hierarchical RNN with query-aware attention
- PSSL: Self-supervised learning for personalized search with contrastive sampling
diversification
- The use of MMR, diversity-based reranking for reordering documents and producing summaries
- Diversifying search results
- DVGAN: A minimax game for search result diversification combining explicit and implicit features
- Modeling intent graph for search result diversification
reading
- Improving language models by retrieving from trillions of tokens
- WebGPT: Browser-assisted question-answering with human feedback
전통적인 IR 방식은 일반적으로 사용자가 관련 정보를 직접 수집하고 정리하도록 한다. 하지만, Reading Component는 새로운 IR 시스템의 필수적인 모듈로 사용자의 시간을 절약한다.
IR의 발전 방향은 term-based methods에서 integration of neural models로 전환을 거치고 있다.
처음에 IR은 용어 기반 방법과 bool 논리에 고정되어 문서 검색을 위한 키워드 일치에 중점을 두었다.
- Introduction to Modern Information Retrieval
패러다임은 벡터 공간 모델의 도입으로 점차적으로 바뀌었고, 용어 간의 미묘한 의미 관계를 포착할 수 있는 포텐셜이 열렸다.
- A vector space model for automatic indexing
이러한 진행은 통계적 언어 모델을 통해 계속되었으며 상황 및 확률적 고려를 통해 관련성 추정을 개선했다.
- A general language model for information retrieval
- Delta TFIDF: An improved feature space for sentiment analysis
BM25 알고리즘은 이 단계에서 중요한 역할을 수행하여 용어 빈도 및 문서 길이 변화를 고려하여 관련성 순위에 큰 영향을 끼쳤다.
BM25
- Okapi at TREC-3
IR의 가장 최근은 neural models이 주목을 받고 있다. 이러한 모델은 복잡한 상황별 단서와 의미적 뉘앙스를 포착하여 IR 환경을 재구성하는 데 좋은 성능을 보인다.
- Dense Passage Retrieval for Open-Domain Question Answering
- A Deep Relevance Matching Model for Ad-Hoc Retrieval
- Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
- Pretrained Transformers for Text Ranking: BERT and Beyond
그러나 이러한 neural models은 여전히 데이터 부족, 해석 가능성, 그럴듯하지만 부정확한 응답 생성 가능성 등의 문제에 직면해 있다.
따라서 IR의 진화는 전통적인 강점(예: BM25 알고리즘의 높은 효율성)과 neural models 아키텍처가 가져온 기능(예: 의미론적 이해)의 균형을 맞춘다.
한편으로, LLM 또한 다양한 연구 분야에서 성과를 달성하고 있다.LLM을 활용하면 IR 시스템의 성능이 확실히 향상될 수 있고, LLM을 통합함으로써 IR 시스템은 사용자에게 보다 정확한 응답을 제공할 수 있으며 궁극적으로 정보 접근 및 검색 환경을 재구성할 수 있다.
예를 들면, New Bing은 서로 다른 웹 페이지에서 정보를 추출하고 이를 사용자 생성 쿼리에 대한 응답 역할을 하는 간결한 요약으로 압축하여 사용자의 검색 엔진 사용 경험을 향상시키도록 설계되었다. 또한 연구 커뮤니티에서 LLM은 IR 시스템(예: retrievers)의 특정 모듈 내에서 유용한 것으로 입증되어 이러한 시스템의 전반적인 성능을 향상시킨다.
