
💻 프로젝트
- 호주의 날짜, 지역별등 10년간 기상 데이터를 통하여 로지스틱 회귀를 통하여 내일 비가 올 지 안 올지 예측을 해보려 한다.
[데이터셋]
https://www.kaggle.com/datasets/jsphyg/weather-dataset-rattle-package?select=weatherAUS.csv
[데이터 구성]
- Date : 날짜
- Location : 지역
- MinTemp: 최저 기온 (단위: °C)
- MaxTemp: 최고 기온 (단위: °C)
- Rainfall: 일일 강수량 (단위: mm)
- Evaporation: 일일 증발량 (단위: mm)
- Sunshine: 일일 일조 시간 (단위: 시간)
- WindGustDir: 바람의 돌풍 방향
- RainToday:해당 날짜에 비가 온지 안 온지 여부
- 그 외에도 시간별 풍속 ,습도, 기압, 구름 양 ,기온 등이 있습니다
[EDA 및 전처리🔍]
- 각 컬럼에 데이터 결측값을 확인 한 결과 상당히 많은 결측치 들이 존재했지만,이를 처리 하기 위해서 연속형 범수와 범주형 변수를 나누어 주었습니다. 연속형 변수는 평균값으로 , 범주형 변수는 최빈값으로 대체해주었습니다.
categorical = [col for col in x_train.columns if x_train[col].dtypes == 'O']
numerical = [col for col in x_train.columns if x_train[col].dtypes != 'O']
print(categorical)
print("")
print(numerical)- 범주형변수: ['Date', 'Location', 'WindGustDir', 'WindDir9am', 'WindDir3pm', 'RainToday']
- 연속형 변수: ['MinTemp', 'MaxTemp', 'Rainfall', 'Evaporation', 'Sunshine', 'WindGustSpeed', 'WindSpeed9am', 'WindSpeed3pm', 'Humidity9am', 'Humidity3pm', 'Pressure9am', 'Pressure3pm', 'Cloud9am', 'Cloud3pm', 'Temp9am', 'Temp3pm']
x_train[numerical] = x_train[numerical].fillna(x_train[numerical].mean())
x_test[numerical] = x_test[numerical].fillna(x_train[numerical].mean())
for df in [x_train, x_test]:
df['WindGustDir'].fillna(x_train['WindGustDir'].mode()[0], inplace=True)
df['WindDir9am'].fillna(x_train['WindDir9am'].mode()[0], inplace=True)
df['WindDir3pm'].fillna(x_train['WindDir3pm'].mode()[0], inplace=True)
df['RainToday'].fillna(x_train['RainToday'].mode()[0], inplace=True)
y_train.fillna(y_train.mode()[0], inplace=True)
y_test.fillna(y_test.mode()[0], inplace=True)- 연속형 변수는 평균값으로 , 범주형 변수는 최빈값으로 대체해주었습니다.y_train과 y_test는 종속변수 RainTomorrow에도 결측치가 있어 최빈값으로 대체해 주었습니다.
| Before | After |
|---|---|
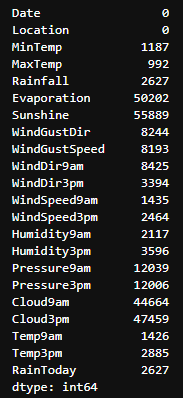 | 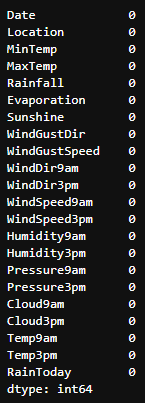 |
- 결측치 처리 전과 후 입니다.
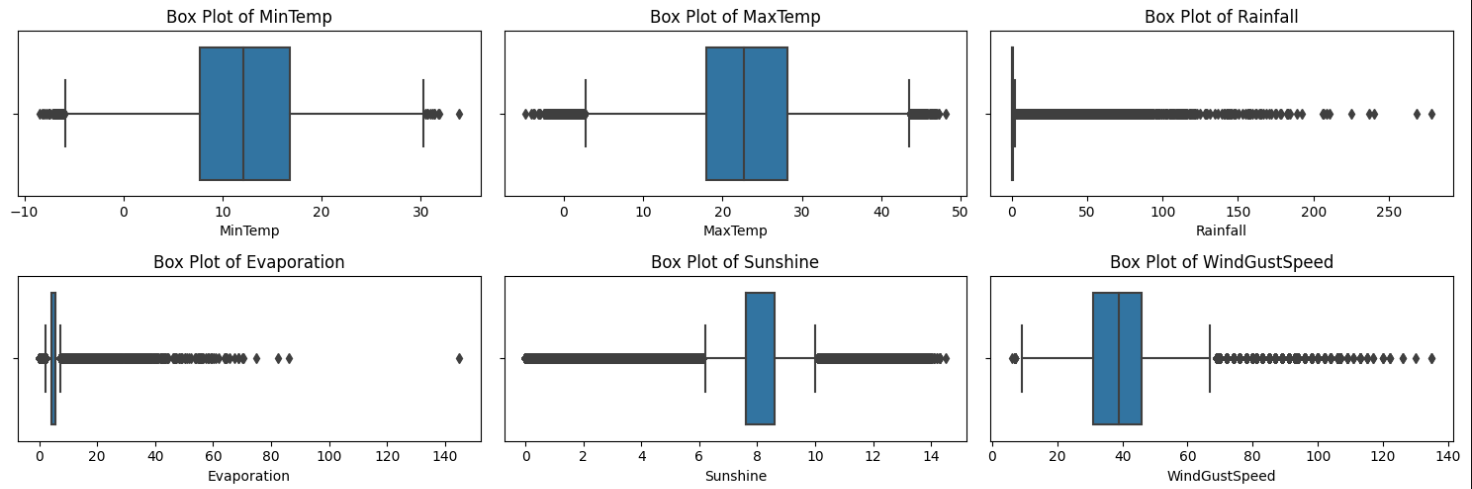
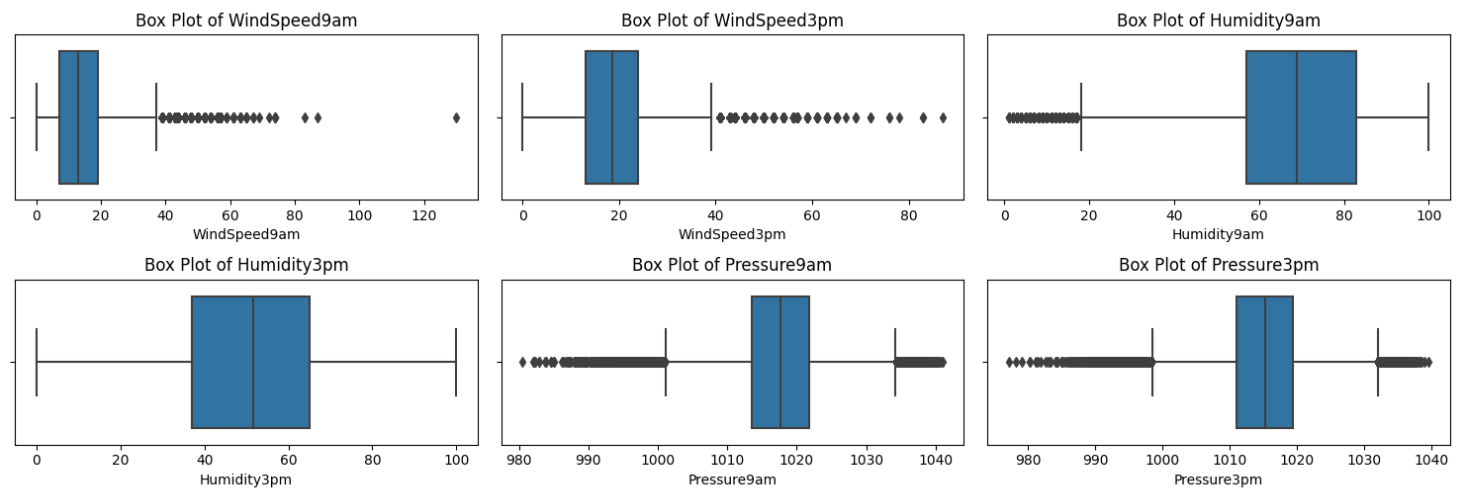
| 이상치 확인 |
|---|
 |
 |
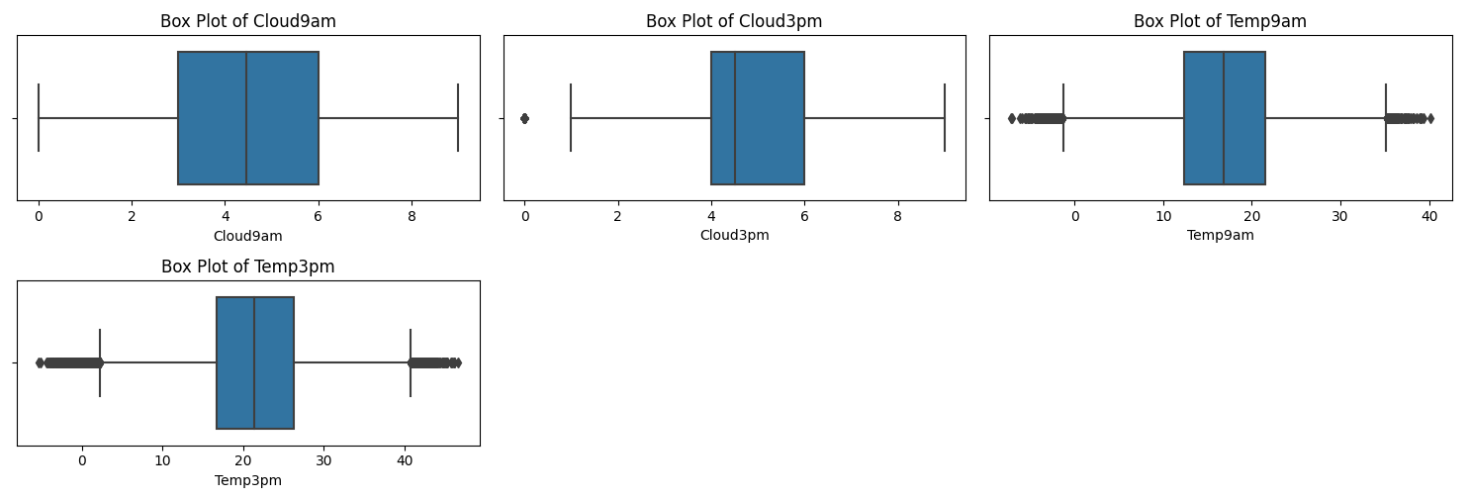 |
- 이상치 확인 결과 이상치 값은 엄청나게 많았지만 , 비가 내린다 안 내린다에는 영향을 미치지 않는다고 판단하여 이상치를 처리하지는 않았습니다.
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
x_train['RainToday'] = label_encoder.fit_transform(x_train['RainToday'])
x_test['RainToday'] = label_encoder.transform(x_test['RainToday'])
y_train = label_encoder.fit_transform(y_train)
y_test = label_encoder.fit_transform(y_test)- 이진 변수 RainToday와 종속 변수 RainTommorow에 라벨 인코딩을 해주었습니다.
import pandas as pd
categorical_variables = ['Location', 'WindGustDir', 'WindDir9am', 'WindDir3pm']
for var in categorical_variables:
dummies = pd.get_dummies(x_train[var], prefix=var)
x_train = pd.concat([x_train, dummies], axis=1)
x_train.drop(var, axis=1, inplace=True)
for var in categorical_variables:
dummies = pd.get_dummies(x_test[var], prefix=var)
x_test = pd.concat([x_test, dummies], axis=1)
x_test.drop(var, axis=1, inplace=True)- Date를 제외한 범주형 변수 원 핫 인코딩을 했습니다.
date_columns = ['Date']
def process_date_columns(data):
data['Date'] = pd.to_datetime(data['Date'])
data['Year'] = data['Date'].dt.year
data['Month'] = data['Date'].dt.month
data['Day'] = data['Date'].dt.day
data.drop(date_columns, axis=1, inplace=True)
return data
x_train = process_date_columns(x_train)
x_test = process_date_columns(x_test)- Date 변수를 년,월,일로 쪼개어 분류하였습니다.
- 모든 전처리를 마치고 난 후 컬럼이 엄청나게 많아졌습니다.
[🧑💻회귀 모델 학습]
- 로지스틱 회귀 분석을 돌려보았다.
import statsmodels.api as sm
x_constant_train = sm.add_constant(x_train)
model = sm.Logit(y_train,x_constant_train)
result = model.fit()-
회귀분석 결과 요약표
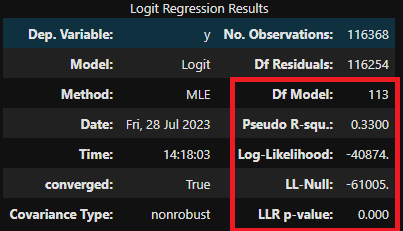
-
로지스틱 회귀 모델의 결과를 통해, 예측 성능은 Pseudo R-squared가 0.33으로 중간 수준이며, 주어진 데이터에 대한 적합도는 높은 편입니다. 로그우도 값은 -40874로, 상수항만으로 이루어진 기본 모델보다 훨씬 더 높은 예측 성능을 보여주고 있습니다. 이로써 모델이 데이터를 더 잘 설명하고 있음을 확인할 수 있습니다.
-
Confusion Matrix
from sklearn.metrics import accuracy_score
x_constant_test = sm.add_constant(x_test)
threshold = 0.5
y_train_pred = result.predict(x_constant_train) > threshold
y_test_pred = result.predict(x_constant_test) > threshold
from sklearn.metrics import confusion_matrix
import seaborn as sns
matrix = confusion_matrix(y_test,y_test_pred)
sns.heatmap(
matrix,
annot = True,
fmt="d"
)| Before | After |
|---|---|
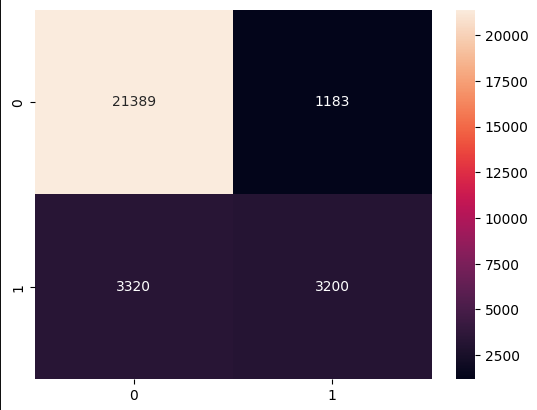 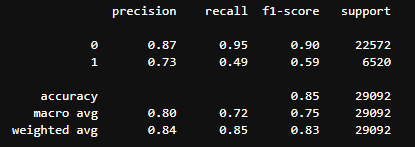 | 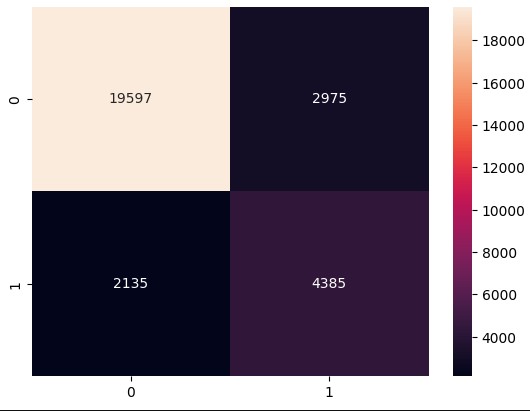 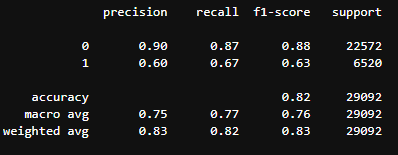 |
- 시각화를 시킨 후 결과를 보니 f1_score와 recall_score가 낮음을 확인했습니다.그래서 임계값을 0.3으로 재조정하여 확인해보니 f1_score와 recall_score가 조금은 상승한 모습을 보였습니다.하지만 정밀도가 가 떨어졌음을 보았습니다. 그러므로 thresh 값을 알맞게 조정하여 재현율과 정밀도의 균형을 잘 맞춰야 할 것 같다.
ROC Curve, AUROC
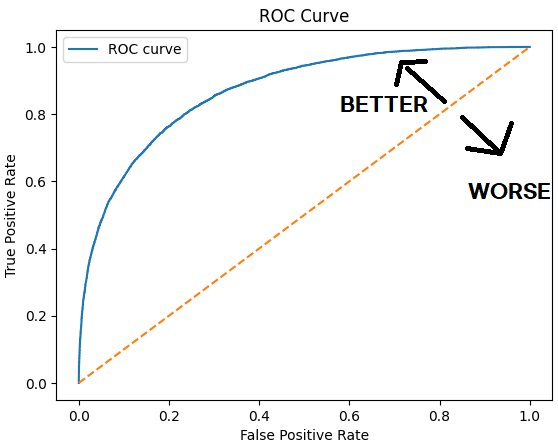
- ROC 곡선은 다양한 임계값(threshold)을 변화시키면서, 모델의 민감도와 특이도를 시각적으로 나타낸 것입니다.곡선이 왼쪽 위로 향할수록 모델의 분류 능력이 높아집니다. 반대로 곡선이 대각선에 가까울수록 모델의 성능은 랜덤한 수준에 머물게 됩니다.
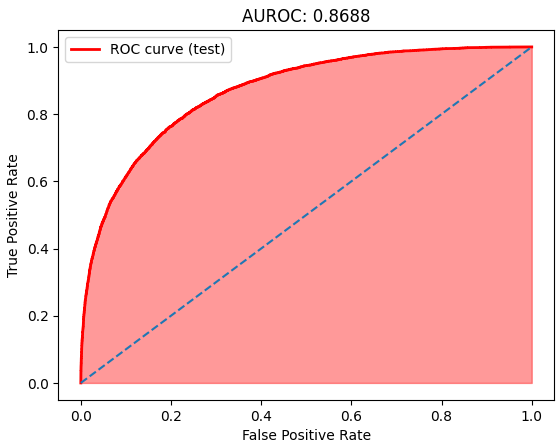
- AUROC는 모델의 분류 성능을 평가하는 지표 중 하나로, 0부터 1까지의 값을 가집니다. 이 값이 1에 가까울수록 모델의 성능이 뛰어나다는 것을 의미합니다. AUROC 값이 0.5에 가까울 경우 모델이 랜덤하게 예측하는 것과 비슷하며, 1에 가까울 경우 모델이 완벽하게 예측하는 것입니다.
분석을 토대로 한 AUROC는 0.8688이 나왔으므로,비가 올지 안 올지 예측하는데에 높은 성능을 보여줍니다.
++
가장 영향을 주는 변수는 뭐가 있을까?
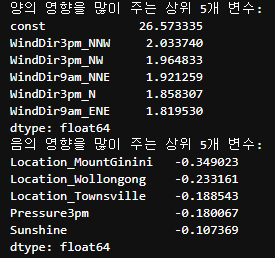
대체적으로 바람이 북쪽으로 많이 불때 비가 오는 경향이 있고
Mount Ginini ,Wollongong ,Townsville지역은 비가 적게온다고 예측할 수 있다. 또한 오후 3시에 기압이 높을경우, 햇빛이 강할경우도 비가 적게오는 요소라고 볼 수 있다.
인사이트
전처리 과정에서 너무 많은 변수를 가지다 보니 과적합 상태가 일어난 것 같다.
그러므로 유의미한 변수를 내버려 두고 필요한 변수만 내버려 두어서 과적합을 방지하는 것이 좋을것 같다고 생각한다. 또한 더 많은 도메인 지식이 있었다면, Date 변수를 통해 시계열분석을 하는 등,월별 강수량을 통하여 새로운 컬럼을 만드는 식으로도 봤어도 괜찮았을 것같다.
하지만 임계값을 조정하면서 재현율등을 올리는 결과를 도출하기도 했다.
