본 게시글은 패스트캠퍼스 [혁펜하임의 AI DEEP DIVE] 체험단 활동을 위해 작성되었습니다.
강의 링크 : https://bit.ly/3GV73FN
왜 현재 AI가 가장 핫할까?
이 글을 다 읽고나면 위의 질문에 답하는 시간을 가져보자 !!
AI란?
Artifical Intelligence 영어 해석 그대로 인간의 지능을 인공적으로 설계한 것이다. 즉, 기계가 인간의 사고방식을 따라해 Output을 도출하는 것이다.
AI vs ML vs DL 의 차이점은?
한 문장으로 정리하면 AI >> ML >> DL 순으로 기계가 학습하는 방식이 구체적이다.
가장 기본적인 AI와 ML,DL과의 차이점
AI는 기계가 개발자가 정해준 규칙에 따라 Output(즉, Label)이 나온다. 아래의 예시로, Input에 아침, O, ..(시간대: 아침, 식사여부: O, ...) 값을 넣는다. 그러면, Output으로 개발자가 정한 커피가 나오는 방식이다.
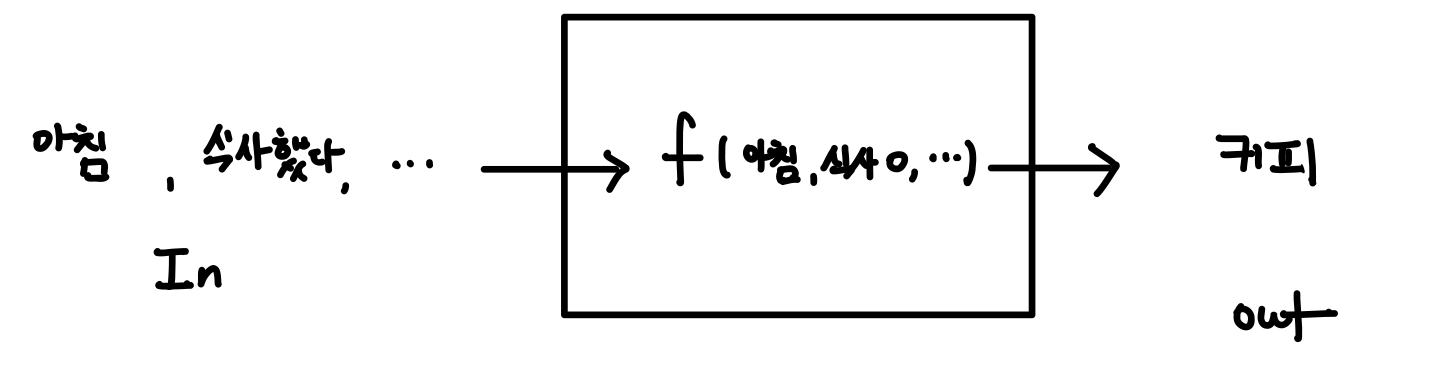
이때, Input으로 아침, 식사 O는 당연하게 숫자로 들어갈 것이다. 그리고 Output 커피도 나올때는 숫자이다. 이해를 돕기위해 글을 써놨다.
여기서, 가장 중요한 것은 f(function)의 작동방식이다. 아래와 같이 If-Then방식으로 규칙이 정해져있다는 것이다.
if 아침:
if 식사 O:
then 커피
else:
then 아침 식사
else if 점심:
if 식사 O:
then 버블티
else:
then 점심 식사
else if 저녁:
...이를 보면 기계가 직접 학습을 하는 것이 아니라 규칙에 따라가지만 규칙 자체가 인간의 행동을 비롯하기 때문에 가장 간단한 AI이다. 문제점으로는 개발자가 모든 규칙을 정의할 수 없기 때문에 규칙 이외의 상황에는 올바르게 작동하지 않는다.
하지만, ML과 DL은 데이터들을 Model에 넣고 각각 특징들의 연관성을 자동으로 분석해 Output을 내는 것이다.
그러면 이제 ML과 DL 차이점을 알아보자
ML vs DL
ML은 데이터를 넘겨줘서 추론 및 결정을 하는 방법을 머신에게 알려준다. 패턴을 파악하고 과거의 데이터를 분석하여 이러한 데이터들의 의미를 추측한다. 이때, DL은 추론 및 결정하는 방식을 인공신경망을 이용해 학습을 시키는 것이다.
각 AI, DL, ML에서 사용되는 대표 알고리즘은?
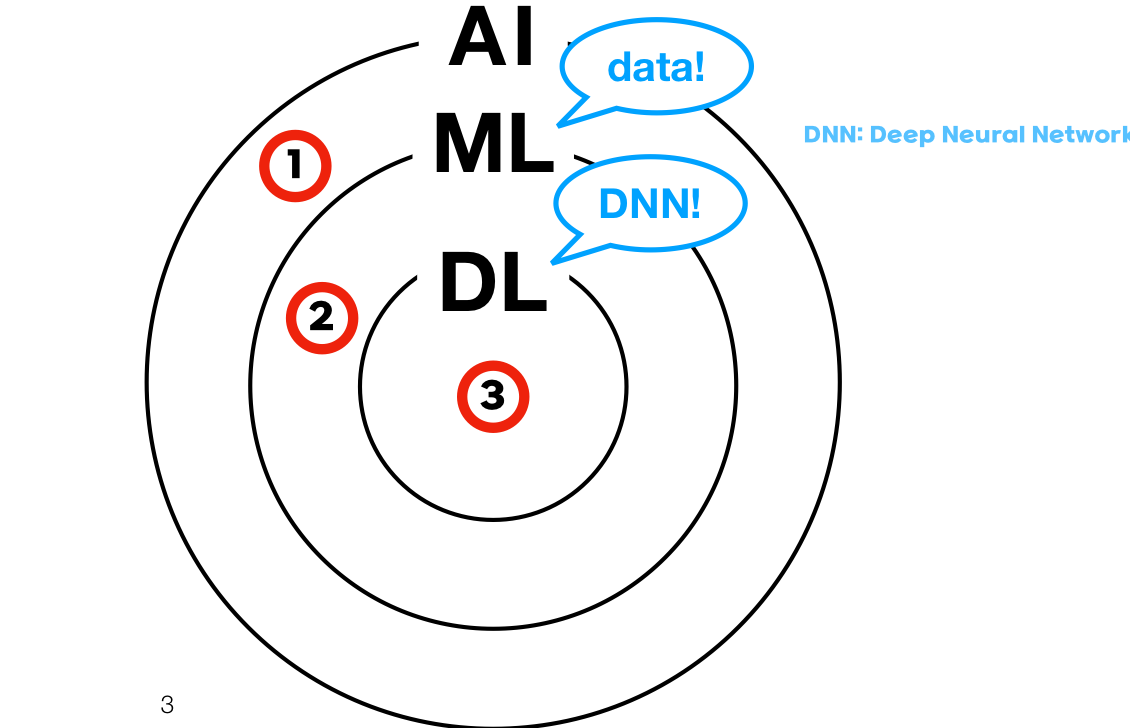
출처: AI Deep Dive 교재
- 규칙기반 알고리즘, 2. 결정트리, 선형회귀, 퍼셉트론, SVM , 3. CNN, RNN, GAN
DL의 모델 간단 소개
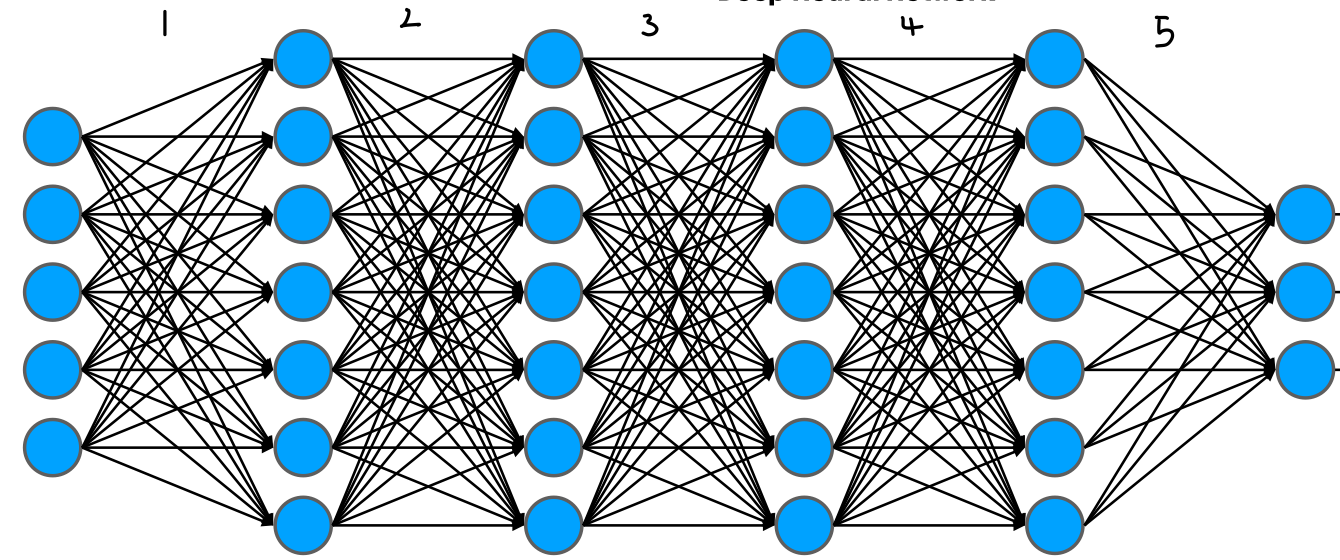
DNN (Deep Neural Network)
아래의 그림에 숫자 1~5까지 있는데 이는, 신경망이 몇개가 연결되어 나타낸 것이다. 이름에서 알 수 있듯이 깊게 인공신경망이 연결된 것이 DNN이다.
CNN (Convolutional Neural Network)
합성곱 신경망으로 컴퓨터비전에서 주로 이미지를 다룰때 많이 쓰인다. 예시로 Input에 고양이 강아지 사진을 주면 CNN Model을 통과하면 강아지 or 고양이를 분류해준다. 이때, Input과 Output 모두 숫자이다. 즉, Input 사진이미지는 픽셀값 ( 개체(이미지 수) X 채널(RGB) X 행 X 열 ) OutPut은 0(강아지), 1(고양이) or 0(고양이), 1(강아지)로 분류한다.
GAN (Generative Adversarial Network)
현재, 생성모델에 관심이 많아 GAN에 대해 기본적인 개념과 학습이 돌아가는 과정을 다른 Model보다는 자세히 다뤄보고 넘어가고자 한다 :)
GAN은 생성모델로서 무엇인가를 생성할 때 적대적으로(Adversarial) 생성한다는 것을 머리 속에 넣어두자. 이때, 적대적이면 서로 비교 상대가 있고 그것이 적대적이어야 한다. 즉, 우리는 모델 두 개를 비교하며 모델들을 Update시킬 것이다. 아래의 예시를 이해하면 GAN이 어떻게 동작하는지 큰 틀을 알 수 있다.
Ex) 위조 지폐를 만드는 GAN Model (50000원 지폐의 이미지를 만들라!!)
여기서, G(Generate)모델은 이미지를 생성하는 모델이다. D(Descriminator)은 실제 50000권과 G가 생성한 fake 이미지와 비교해 실제 지폐를 잘 구별해내는 모델이다.
두 Model의 목표는 G_Model은 D를 속이고 싶어하고 D_Model은 속임에 당하지 않고 실제 50000권을 잘 구별해내고 싶어한다.
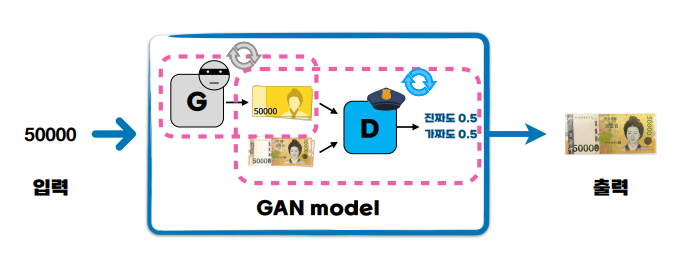
출처: AI Deep Dive 교재
각 모델의 훈련동작은 서로가 고정되어있다는 가정하게 업데이트를 진행하게 되는데, 처음 G가 고정되고 D가 업데이트 된다. 그러면, 아래와 같이 성능도가 나타난다.
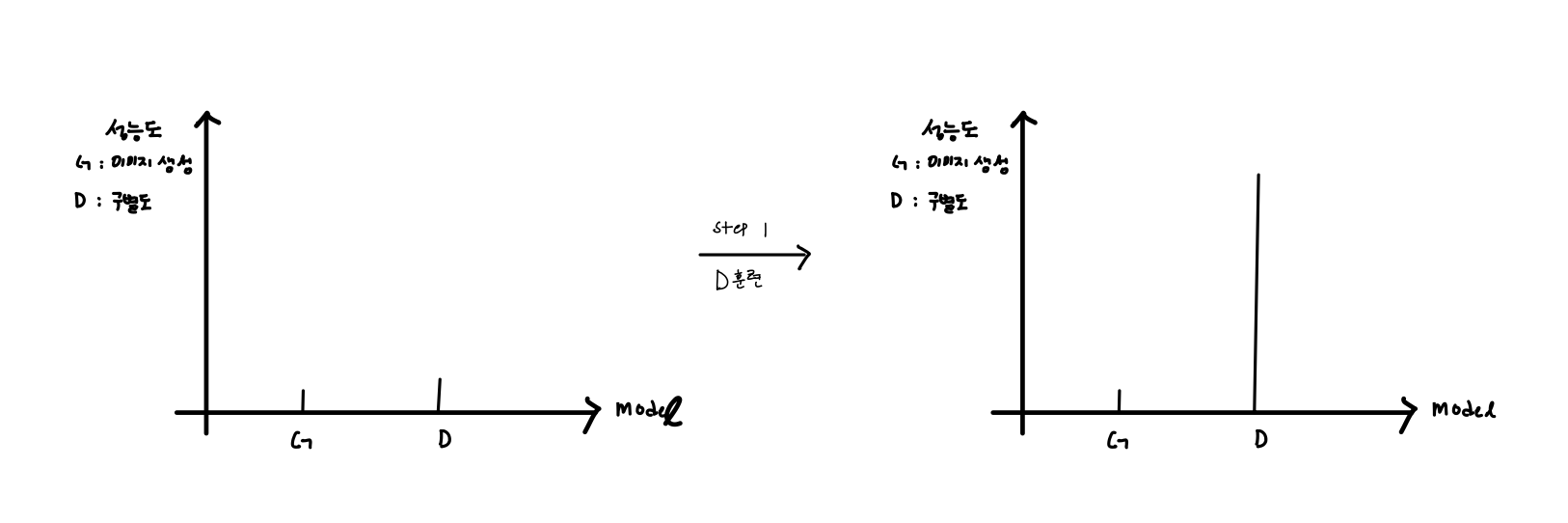
이후, 훈련된 D가 고정이 되고 G를 훈련 시킨다. 그러면, 아래와 같이 성능도가 나타난다.
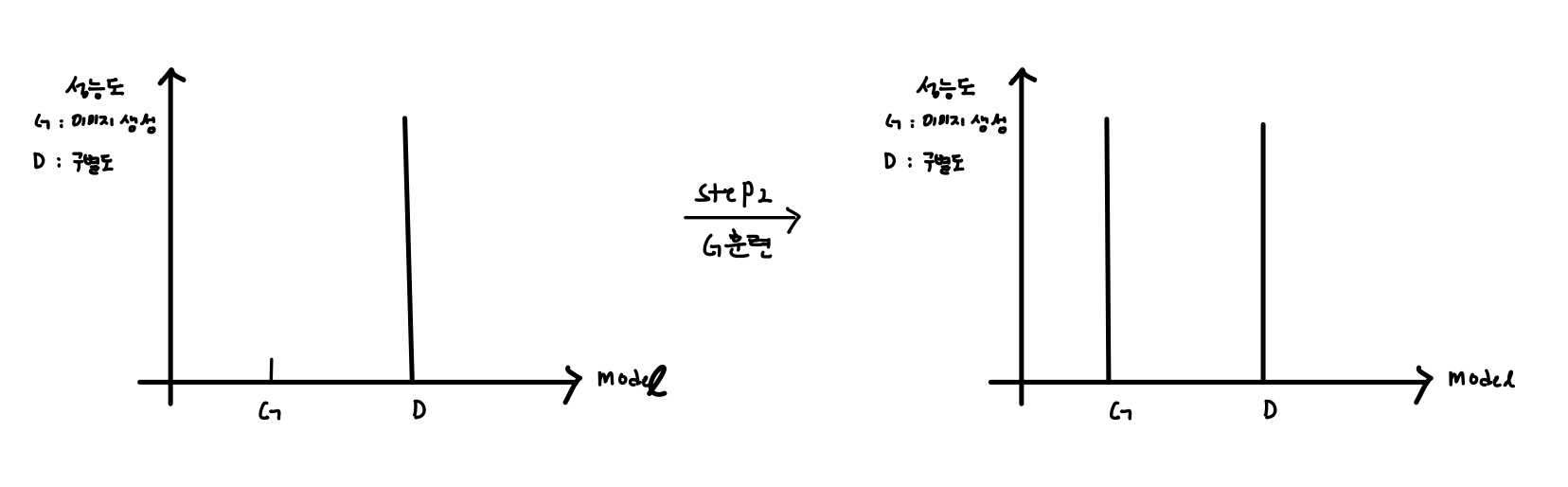
위의 Step1,2를 반복하면 성능을 향상시켜나간다. 여기서, Loss Function이 어떻게 정의되어있고 서로 연관하여 어떻게 훈련하는지 궁금했다. 아래의 설명이 첨부된 판서를 보고 이해해보자!! (수식이 이상할 수도 있으니 있다면 댓글 부탁드립니다 ㅎㅎ)

-
D를 훈련할 때 G는 상수화(이때, G는 전혀 updata를 하지 않는다.) 그리고 D는 실제 데이터는 1로 잘 분류해야하고 가짜 데이터는 0으로 분류해야 성능이 좋은 것이라 V(D,G)가 Max가 되는 걸 찾아야한다.
-
G를 훈련할 때 D가 실제 데이터를 잘 예측하는지는 G성능에 아무런 영향이 없다. 따라서, 제외하고 생각하자. 그리고 G는 가짜 데이터를 D로 분류했을때 1로 나오게 해야 성능이 좋은 것이라 V(D,G)가 Min이 되는 걸 찾아야한다.
GAN 모델은 유용하게 사용된다. 딥페이크, 가짜뉴스(전 오바마 미국 대통령 가짜연설), 등등
하지만, 문제점으로 GAN을 통해 생성된 미디어의 지식재산권 이슈, 가짜 이미지를 이용한 사기 등 여러가지 법적, 윤리적인 범주의 이슈가 존재하는데 이는 GAN의 기술적 발전에 따른 제도적 대안이 필요합니다.
나중에, GAN을 보완한 WGAN에 대해서도 공부하고 포스팅 해야겠다!
Machine의 학습방식
지도학습
데이터의 Label을 알고있는 상태에서 기계를 학습시키는 방법이다. ML 회귀 분류의 대표적인 방법이고 학습데이터가 많으면 많을수록 기계의 성능은 높아진다. 반대로 데이터 양이 적다면 좋은 성능을 기대하기 힘들다.
비지도학습
지도학습과 반대로 Label없이 기계를 학습시키는 방법이다. 이는, 군집 차원축소 GAN에 주로 쓰이는데 특히, 군집에서 Group화 시킬 때 각 group이 뭔 특징을 갖는지 알지는 못하지만 기계가 각 데이터의 특징들의 distance measure을 구해 비슷한 특징값을 갖는 데이터끼리 묶어놓는 것이다.
(분류: 지도학습, 군집화: 비지도학습)
자기지도학습
위 지도학습에서 데이터가 많으면 좋은 성능을 내지만 데이터를 모으는데 비용과 시간이 많이 들어 대용량의 데이터를 가지기 힘든 문제점이 있다.
그래서, 등장한 것이 자기지도학습이다. 자기지도학습은 결과로 내고자하는 문제를 설계하는 대신에 다른 관련 문제를 학습한 후에 본 문제로 들어가는 것이다. 이는, 게임 시작 전 튜토리얼을 한다고 생각하면 좋을 것 같다.
Step 1) Pretext task 학습으로 pre-training (예제 문제)
Step 2) downstream task(분류)를 풀기 위해 transfer learning을 한다. (본 문제)
- Step 1의 Pretext task에서 Contrastive Learning 방법
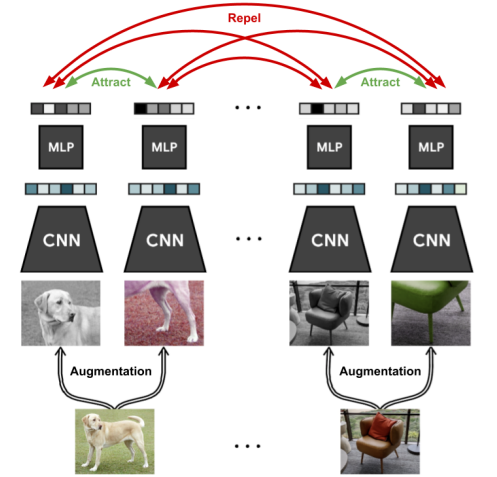
출처: AI Deep Dive 교재
여기서, 주의해서 볼 부분이 한 장에 사진을 여러 부분으로 쪼갠다. 이후 딥러닝 모델을 통과시킨 후에 나온 결과로 같은 사진의 부분끼리는 Attract(끌어댕기기)하고 다른 사진끼리는 Repel(밀어낸다.)한다.
그러면, 본 문제인 분류전에 한 장의 사진으로 여러 개의 데이터를 만들어내 선행학습을 진행하면서 모델의 성능을 향상시킨다.
강화학습
강화학습은 알파고와 이세돌 바둑기사 대국으로 전 세계의 이목을 집중시킨 것으로 유명하다. 방식은 매우 Greedy하다. 이기는 수에 가중치를 높게 주고 지는 수에는 가중치를 낮게 준다.
미로찾기 방식으로 강화학습을 이해하면 편할 것이다.
- 말이 형광펜을 따라 지옥으로 갔다고 가정하자.
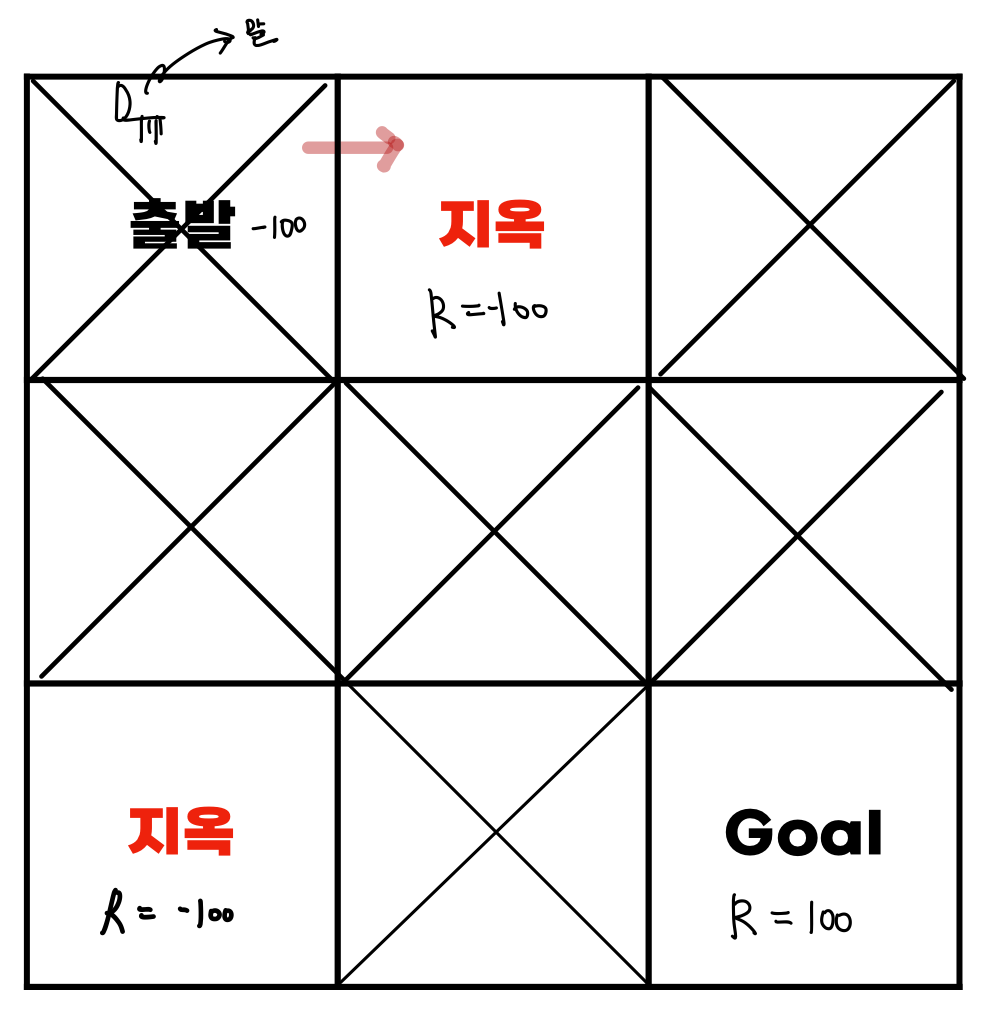
Then, 해당 경로에 -100의 가중치가 부여된다.
- 말이 운이 좋아서 아래에 표시된 형광펜을 따라가 Goal에 갔다고 가정하자.
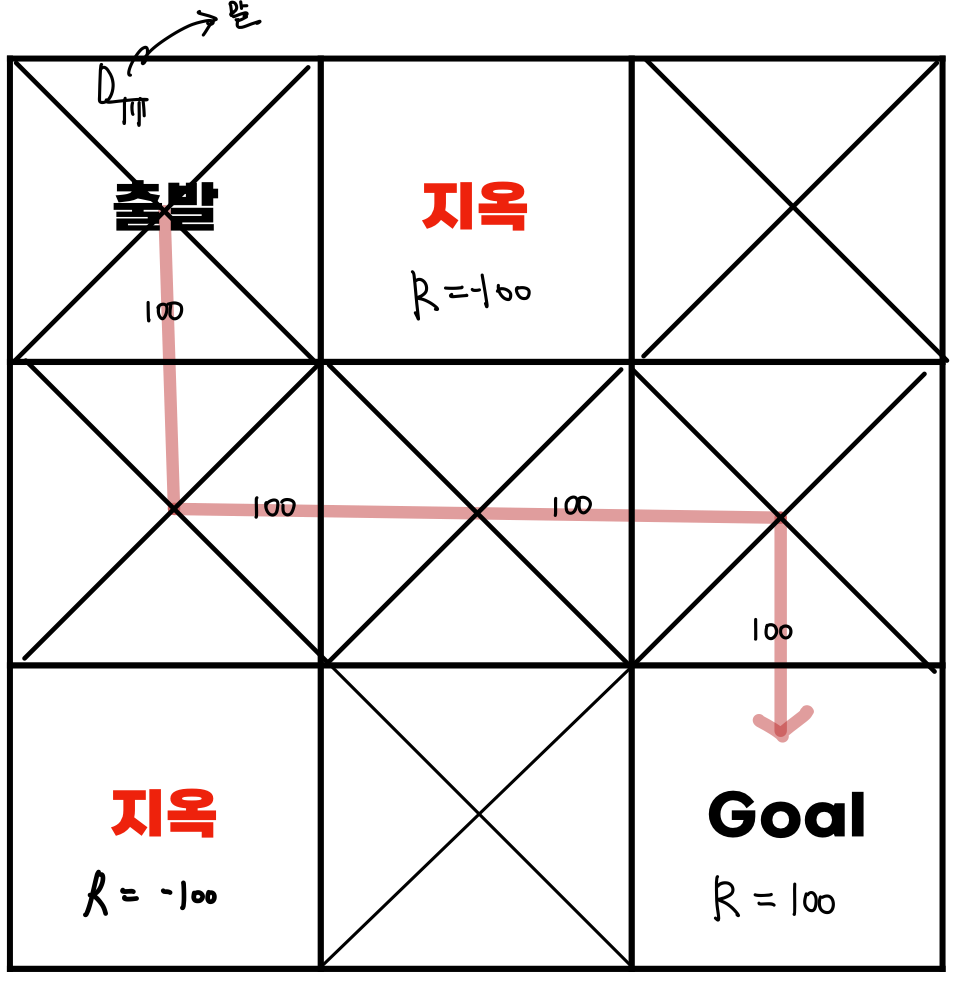
Then, 해당 경로에 100의 가중치가 부여된다.
하지만, 위에 방식은 매우 이상적이다. 우리는 Worst를 고려안할 수가 없다. 아래의 방식을 확인해보자.
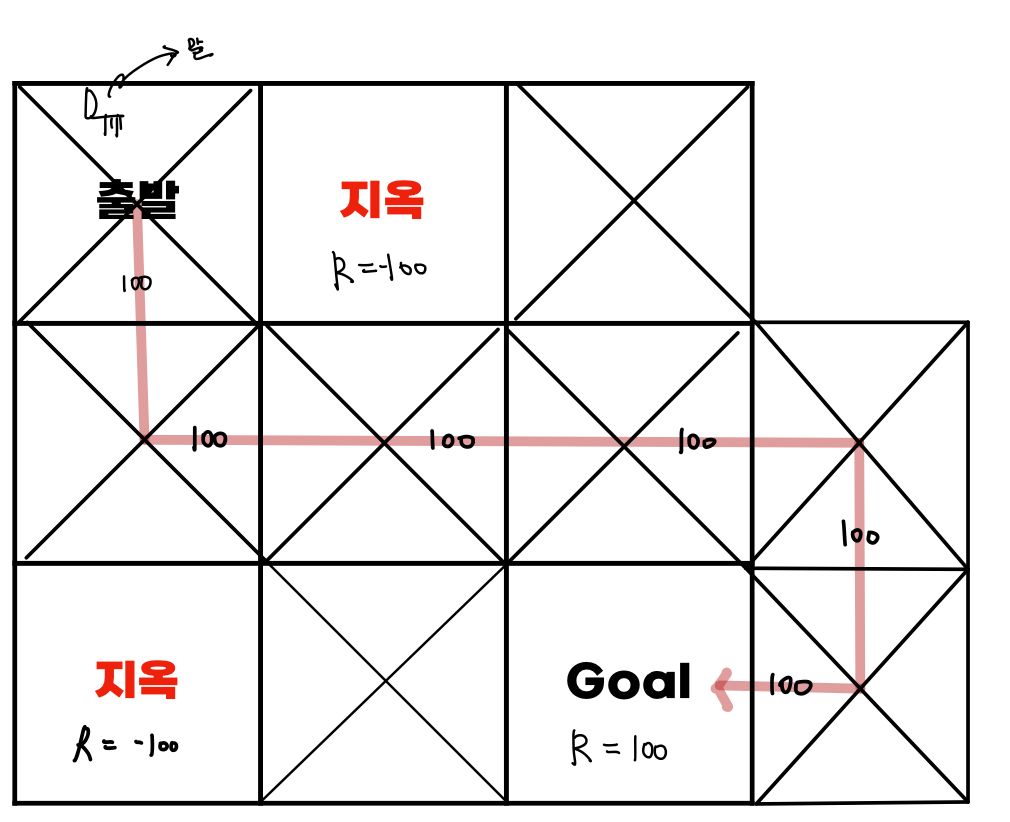
이는, Goal에 도착은 했지만 최적의 경로라고 말할 수 없다. 이를 해결하는 방법으로 Q-Learning exporation의 -greedy 방식을 살펴보자.
이 방법에는 파라미터가 2개가 있다. 과 이다.
: 의 확률로 greedy하게 좋은 것만 택하는 것이 아니라 다양한 경로를 위해 다른 길로 가는 것이다. (여러 경로를 가보기 위해 사용된다.)
: 는 0-1사이의 값을 가지는데 reward에서 값을 가져올 때 가 곱해진다. (최적화 된 해를 구하는데 사용된다.)
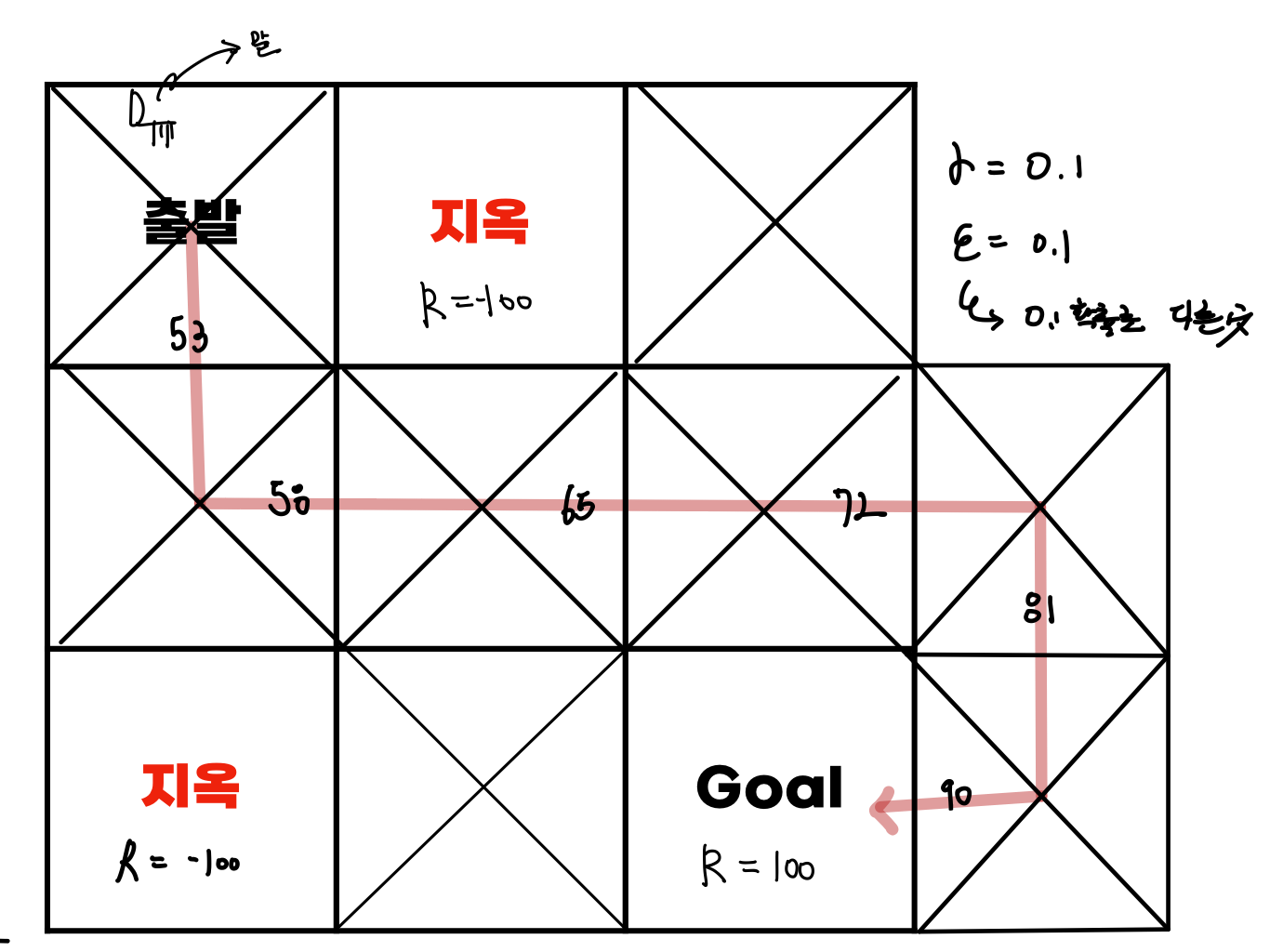
다양한 강화학습 방법이 있는데 기본적인 ML지식을 공부한 후에 추가적인 심화지식을 공부해보자!
강의 후기
패스트 캠퍼스의 혁펜하임 AI DEEP DIVE의 Ch2 "왜 현재 AI가 가장 핫할까?"를 수강 후에 강의에서 알려주신 내용을 정리해보았습니다.
DL부분을 본격적으로 시작하기 전 ML DL의 용어들에 관한 설명과 동작 방식을 비전공자도 이해하기 쉽게 실 예시와 함께 이론적 배경을 알려주셔서 이해하는데 부담없이 들어왔습니다.
이번 강의 중에서 인상 깊었던 부분을 고르자면 GAN과 강화학습 파트이다. 요즘 생성모델에 관심이 많았는데, 큰 틀을 제대로 이해하지 못한 기분을 느겼다.
이 강의를 듣고 예시와 함께 GAN의 동작과정을 살펴보니 내가 놓쳤던 부분인 "G,D Model이 훈련될 때는 개별적으로 하나씩 훈련되는 것"을 알게 되면서 정확히 틀을 잡을 수 있었다.
그리고 강화학습 파트에서는 이론적배경만 소개하는 글은 많이 봤지만, 한 층 더 나아가서 Q-learning이 나온 배경과 -greedy exporation이 나온 배경을 흐름따라 설명하면서 부담없이 이론을 이해할 수 있었다.
아직, 강의들이 ch3 - ch9까지 많이 남았는데 코드리뷰와 함께 이론적 내용을 차근차근 정리하면서 지식을 넓혀가고싶다.
#패스트캠퍼스혁펜하임 #혁펜하임 #혁펜하임AI #패스트캠퍼스 #혁펜하임강의 #AIDEEPDIVE #ai강의 #혁펜하임강의후기
