page-fault율에 대한 이전의 논의에서, 각 페이지는 처음 참조될 때, 최대 한 번 fault(폴트, 부재)된다고 가정했다. 하지만, 이 표현은 엄밀히 말하면 정확하지 않다. 10페이지짜리 프로세스가 실제로는 그 중 절반만 사용한다면, demand paging(요구 페이징)은 사용되지 않는 5페이지를 로드하는 데 필요한 I/O를 절약한다. 또한 두 배 더 많은 프로세스를 실행하여 다중 프로그래밍의 정도를 높일 수 있다. 예를 들어, 프레임이 40개일 때,
→ 각 프로세스가 5개의 페이지만 사용한다면 총 8개의 프로세스을 실행할 수 있지만, (40/5=8)
→ 각 프로세스가 10개 프레임이 필요하다면(그 중 5개는 사용되지 않아도), 4개의 프로세스만 실행할 수 있다. (40/10=4)
Page fault란?
- CPU가 요청한 페이지가 메모리에 없을 때 발생
- 이 경우 디스크에서 페이지를 불러와야 하므로 시간이 오래 걸림
Page frame란?
- 운영체제가 메모리를 일정 크기로 나눈 슬롯
- 하나의 프레임에는 하나의 페이지만 들어갈 수 있음
- 프레임 수가 많을수록 동시에 보관할 수 있는 페이지 수가 많아짐
멀티프로그래밍의 정도를 높이면, 메모리를 과도하게 할당한다. 각 프로세스가 10페이지 크기, 실제로는 5페이지만 사용하는 프로세스 6개를 실행하려면, CPU 사용률과 처리량이 높아지고, 10프레임이 남게된다. 그러나, 특정 data set에 대해, 이러한 프로세스들이, 갑자기 10페이지 모두 사용하려고 하는 경우, 사용 가능한 프레임이 40개뿐인데도 60프레임이 필요한 상황이 발생할 수 있다.
또한, 시스템 메모리가 페이지 저장에만 사용되는 것이 아니라는 점을 고려해야 한다. I/O 버퍼 또한 상당한 양의 메모리를 소모한다. 이러한 사용은 memory-placement 알고리즘에 부담이 증가한다. I/O에 얼마나 많은 메모리를 할당하고, 프로그램 페이지에 얼마나 많은 메모리를 할당할지 결정하는 것은 상당한 과제이다. 일부 시스템은 I/O 버퍼에 고정된 비율의 메모리를 할당하는 반면, 다른 시스템은 프로세스와 I/O 하위 시스템이 모든 시스템 메모리를 차지하기 위해 경쟁하도록 허용한다.
메모리 과할당은 다음과 같이 나타난다. 프로세스가 실행되는 동한 페이지 폴트가 발생한다. 운영체제는 원하는 페이지가 보조저장소의 어디에 있는지 확인하지만, free-frame 목록에 free frame이 없다는 것을 발견한다. 즉, 모든 메모리가 사용 중이다. 이러한 상황은 그림 10.9에 설명되는데, free 프레임이 없다는 사실은 물음표로 표시된다.
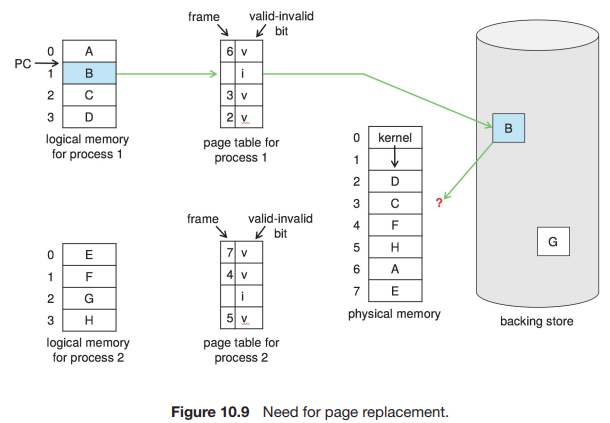
이 포인트에서 운영체제는 여러가지 옵션을 제공한다. 프로세스를 종료할 수도 있다. 하지만, 요구 페이징은 운영체제가 컴퓨터 시스템의 활용도와 처리량을 향상시키기 위한 시도이다. 사용자는 프로세스가 페이징된 시스템에서 실행되고 있다는 사실을 인지해서는 안된다. 페이징은 사용자에게 논리적으로 투명해야 한다. 따라서 이 옵션은 최선의 선택이 아니다.
운영체제는 대신 standard swapping과 프로세스를 swap out하여, 모든 프레임을 해제하고 멀티프로그래밍 수준을 줄일 수 있다. 그러나 섹션 9.5에서 논의했듯이, standard swapping은 메모리와 스왑 공간 간에 전체 프로세스를 복사하는 오버헤드로 인해, 대부분의 운영체제에서 더 이상 사용되지 않는다. 현재 대부분의 운영체제는 페이지 스와핑과 page replacement(교체)를 결합하고 있다.
10.4.1 Basic Page Replacement
페이지 교체는, 사용 가능한 프레임이 없으면 현재 사용되지 않는 프레임을 찾아 해제한다. 프레임의 내용을 작성하여 공간을 스왑하고, 페이지 테이블을 변경하여 페이지가 더 이상 메모리에 없음을 표시하여 프레임을 해제할 수 있다 (그림 10.10).
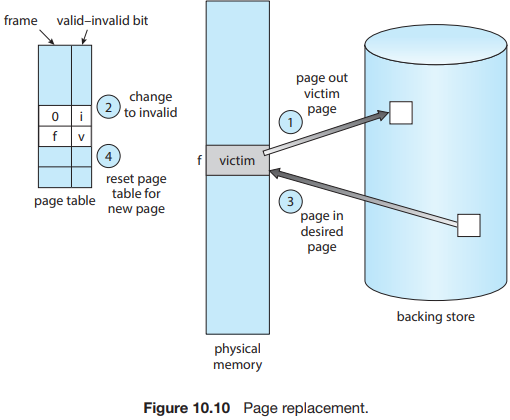
해제된 프레임을 사용하여, 프로세스에서 오류가 발생한 페이지를 보관할 수 있다. 페이지 교체를 포함하도록 page-fault 서비스 루틴을 수정한다:
- 보조 기억장치에서 원하는 페이지 위치 찾기.
- 빈 프레임 찾기.
a. 빈 프레임이 있으면 사용.
b. 빈 프레임이 없는 경우, page-replacement 알고리즘을 사용하여 victim(희생당할) frame 선택.
c. victim 프레임을 보조 기억장치에 쓰고(필요한 경우); 페이지와 프레임 테이블을 적절히 변경. - 새로 해제된 프레임에 원하는 페이지를 읽어 오고, 페이지와 프레임 테이블 변경.
- page fault가 발생한 지점부터 프로세스를 계속 진행.
사용 가능한 프레임이 없는 경우, 두 페이지를 전송해야 한다(하나는 page-out, 하나는 page-in). 이러한 상황은 page-fault 서비스 시간을 두 배로 늘리고, 그에 따라 유효 access 시간도 증가시킨다.
modify bit(or dirty bit)를 사용하면 이러한 오버헤드를 줄일 수 있다. 이 방식을 사용하면, 각 페이지 또는 프레임에 하드웨어에 연결된 modify bit가 있다. 페이지 modify bit는 페이지의 어떤 바이트가 기록될 때마다 하드웨어에 의해 설정되며, 이는 페이지가 수정되었음을 나타낸다. 교체할 페이지를 선택할 때, 해당 페이지의 modify bit를 검사한다. 이 비트가 설정되어 있으면, 페이지가 보조 기억장치에서 읽힌 이후 수정되었음을 알고있다. 이 경우, 해당 페이지를 저장소에 기록해야 한다. 그러나, modify bit가 설정되지 않았다면, 해당 페이지는 메모리에서 읽힌 이후 수정되지 않은 것이다. 이 경우, 페이지를 저장소에 기록할 필요가 없다. 이미 저장소에 존재하기 때문이다. 이 기법은 read-only 페이지에도 적용된다. 이러한 페이지는 수정할 수 없으므로, 원하는 경우 삭제할 수 있다.
페이지 교체는 요구 페이징의 기본이다. 이는 논리 메모리와 물리 메모리를 분리한다. 이 메커니즘을 사용하면 프로그래머가 더 작은 물리 메모리에 거대한 가상 메모리를 제공할 수 있다. 요구 페이징이 없는 경우, 논리 주소는 물리 주소에 매핑되며, 두 주소의 집합은 다를 수 있다. 그러나, 프로세스의 모든 페이지는 여전히 물리 메모리에 있어야 한다. 요구 페이징을 사용하면, 논니 주소 공간의 크기가 더 이상 물리 메모리의 제약을 받지 않는다. 20페이지 프로세스가 있다면, 요구 페이징과 교체 알고리즘 사용이 필요할 때마다 빈 프레임을 찾아 10프레임으로 간단히 실행할 수 있다. 수정된 페이지를 교체해야 하는 경우, 해당 내용은 보조 기억장치에 복사된다. 나중에 해당 페이지를 참조하면 page fault가 발생한다. 이때, 해당 페이지는 메모리에 다시 로드되어, 프로세스 중 다른 페이지를 교체할 수 있다.
요구 페이징을 구현하려면 두 가지 주요 문제를 해결해야 한다: frame-allocation algorithm과 page-replacement algorithm을 개발해야 한다. 즉, 메모리에 여러 프로세스가 있는 경우, 각 프로세스에 할당할 프레임 수를 결정해야 한다. 또한 페이지 교체가 필요한 경우, 교체할 프레임을 선택해야 한다. 이러한 문제를 해결하기 위한 적절한 알고리즘을 설계하는 것은 중요한 작업이다. 보조 기억장치 I/O가 너무 비싸기 때문이다. demand-paging 방식을 조금만 개선해도 시스템 성능이 크게 향상된다.
페이지 교체 알고리즘은 매우 다양하다. 각 운영체제마다 고유한 교체 방식이 있을 것이다. 일반적으로 page-fault율이 가장 낮은 알고리즘을 선택한다.
특정 메모리 참조 문자열에 대해 알고리즘을 실행하고 페이지 fault 발생 횟수를 계산하여 알고리즘을 평가한다. 이 메모리 참조 문자열을 reference string이라고 한다. 참조 문자열은 인위적으로 생성할 수도 있고, 주어진 시스템을 추적하여 각 메모리 참조 주소를 기록할 수도 있다. 후자는 대량의 데이터를 생성한다. 데이터 수를 줄이기 위해, 두 가지 사실을 사용한다.
- 주어진 페이지의 크기(페이지의 크기는 일반적으로 하드웨어나 시스템에 의해 고정됨)에 대해 전체 주소가 아닌 페이지의 번호만 고려
- 페이지 에 대한 참조가 있는 경우, 바로 뒤에 오는 페이지 에 대한 참조는 page fault를 일으키지 않는다. 페이지 는 첫 번째 참조 이후에 메모리에 저장되기 때문이다.
예를 들어, 특정 프로세스를 추적하는 경우, 다음과 같은 주소 시퀀스를 기록할 수 있다.
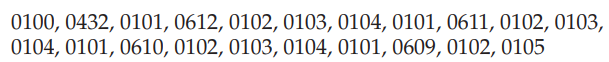
페이지당 100byte인 경우, 이 시퀀스는 다음과 같은 참조 문자열로 축소된다.
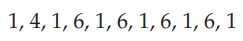
특정 참조 문자열과 페이지 교체 알고리즘에 대한 page fault 수를 확인하려면, 사용 가능한 페이지 프레임 수도 알아야 한다. 당연히 사용 가능한 프레임 수가 증가할 수록 페이지 fault 수는 감소한다. 예를 들어, 앞서 고려한 참조 문자열의 경우, 프레임이 세 개 이상이라면 각 페이지를 처음 참조할 때마다 fault를 하나씩, 총 세 개의 fault만 발생한다. 반대로 사용 가능한 프레임이 하나뿐이라면, 모든 참조에 대해 교체가 발생하여 총 11개의 fault가 발생한다. 일반적으로 그림 10.11과 같은 곡선을 예상할 수 있다.
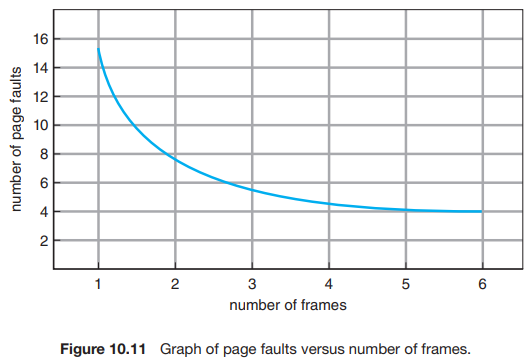
프레임 수가 증가함에 따라 페이지 폴트 수는 최소 수준으로 감소한다. 물론, 물리적 메모리를 추가하면 프레임 수가 증가한다.
다음으로 여러 페이지 교체 알고리즘을 살펴본다. 이 과정에서, 3개의 프레임으로 구성된 메모리에 대해 아래의 참조 문자열을 사용한다.
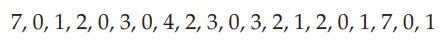
10.4.2 FIFO Page Replacement
가장 간단한 페이지 교체 알고리즘은 선입선출(FIFO) 알고리즘이다. FIFO 교체 알고리즘은 각 페이지가 메모리에 들어온 시간을 해당 페이지와 연관시킨다. 페이지를 교체해아 할 때는 가장 오래된 페이지가 선택된다. 페이지가 들어오는 시간을 반드시 기록할 필요는 없다. 메모리에 있는 모든 페이지를 보관하기 위해 FIFO 큐를 생성할 수 있다. 큐의 맨 앞에 있는 페이지를 교체한다. 페이지가 메모리에 로드되면, 큐의 맨 뒤에 삽입한다.
예시 참조 문자열의 경우, 세 프레임은 처음에 비어있다. 처음 세 참조 7, 0, 1은 페이지 fault를 발생시켜 빈 프레임으로 가져온다. 다음 참조 2는 페이지 7을 대체하는데, 페이지 7이 먼저 들어왔기 때문이다. 0이 다음 참조이고, 0은 이미 메모리에 있으므로 이 참조에는 fault가 없다. 3에 대한 첫 번째 참조는 페이지 0이 줄의 첫 번째에 있으므로 교체된다. 이 교체때문에 다음 참조 0에서 fault가 발생한다. 그런 다음 페이지 1은 페이지 0으로 교체된다. 이 과정은 그림 10.12와 같이 계속 진행된다. fault가 발생할 때마다 세 프레임에 어떤 페이지가 있는지 보여준다. 총 15개의 fault가 있다.
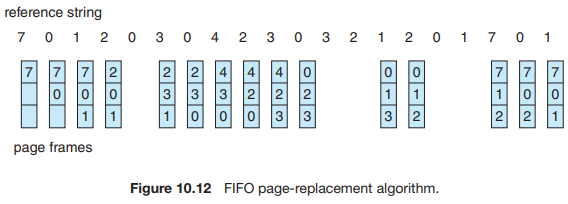
FIFO 페이지 교체 알고리즘은 이해하고 프로그래밍하기 쉽다. 하지만 성능이 항상 좋은 것은 아니다. 한 편으로는, 교체된 페이지가 오래전에 사용되어 더 이상 필요하지 않은 초기화 모듈일 수 있다. 다른 한편으로는, 일찍 초기화되어 지속적으로 자주 사용되는 변수를 포함할 수 있다.
활성 상태인 페이지를 교체 대상으로 선택하더라도 모든 것은 여전히 정상적으로 작동한다. 활성 페이지를 새 페이지로 교체한 후에는, 활성 페이지는 가져오는 데 거의 즉시 fault가 발생한다. 활성 페이지를 다시 메모리로 가져오려면 다른 페이지를 교체해야 한다. 따라서 잘못된 교체 선택은 페이지 fault 발생률을 높이고 프로세스 실행 속도를 저하시킨다. 하지만, 이로 인해 잘못된 실행이 발생하지는 않는다.
FIFO 페이지 교체 알고리즘에서 발생할 수 있는 문제를 설명하려면 , 다음 참조 문자열을 고려한다.
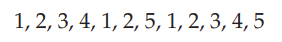
그림 10.13은 이 참조 문자열에 대한 페이지 fault 발생률 곡선과 사용 가능한 프레임의 수를 보여준다.
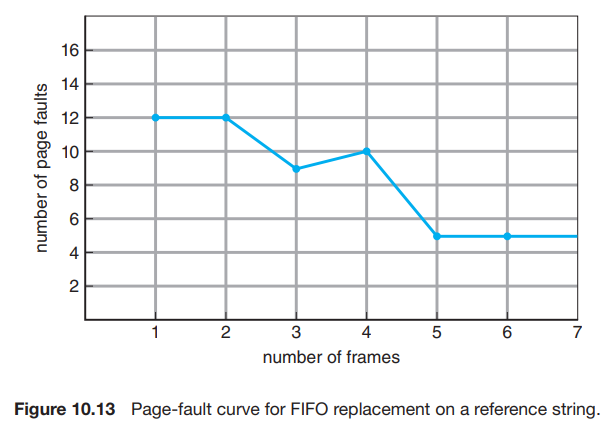
4 프레임(10개)에 대한 fault 발생률이 3 프레임(9개)에 대한 fault 발생률보다 크다. 이 예상치 못한 결과는 Belady's anomaly(벨라디의 이상현상, 역설, 모순..)으로 알려져 있다. 일부 페이지 교체 알고리즘의 경우, 할당된 프레임 수가 증가함에 따라 페이지 fault 발생률이 증가할 수 있다. {프로세스에 더 많은 메모리를 할당하면 성능이 향상될 것으로 예상되지만, 초기 연구에서 연구자들은 이러한 가정이 항상 맞는 다는 것은 아니라는 사실을 발견했다. 벨라지 현상은 이러한 결과로 발견되었다.}
10.4.3 Optimal Pgae Replacement
벨라디 이상현상 발견의 한 가지 결과는 optimal page-replacement algorithm, 즉 모든 알고리즘 중 페이지 부재율이 가장 낮고 벨라디 이상현상이 발생하지 않는 알고리즘을 찾는 것이었다. 그러한 알고리즘은 실제로 존재하며 OPT 또는 MIN이라고 불린다. 그 원리는 다음과 같다:
가장 오랫동안 사용되지 않을 페이지 교체
이 페이지 교체 알고리즘을 사용하면 고정된 수의 프레임에 대해 가장 낮은 페이지 부재율이 보장된다.
예를 들어, 샘플 참조 문자열에서 최적의 페이지 교체 알고리즘은 그림 10.4와 같이 9개의 페이지 fault를 발생시킨다.
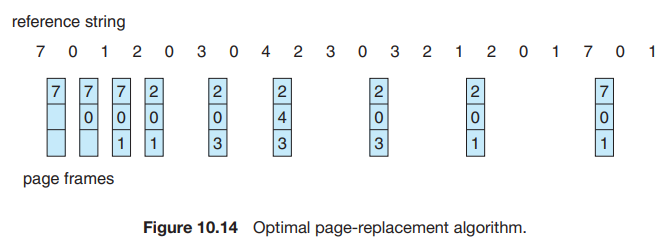
처음 세 개의 참조는 세 개의 빈 프레임을 채우는 fault를 발생시킨다. 페이지 2에 대한 참는 페이지 7을 교체하는데, 이는 페이지 7이 참조 18이 될 때까지 사용되지 않기 때문이다. 반면에, 페이지 0은 5에서, 페이지 1은 14에서 사용된다. 페이지 3에 대한 참조는 페이지 1을 대체하는데, 이는 페이지 1이 메모리에 있는 세 페이지 중 마지막으로 참조되기 때문이다. 페이지 fault가 9개에불과하므로 최적 교체는 15개의 fault를 발생시키는 FIFO 알고리즘보다 훨씬 우수하다. (모든 알고리즘이 겪어야 하는 처음 세 개의 fault를 무시하면 최적 교체는 FIFO 교체보다 두 배 더 좋다.)
불행히도, 최적의 페이지 교체 알고리즘은 구현하기 어렵다. 참조 문자열에 대한 미래의 지식이 필요하기 때문이다. 따라서, 최적 알고리즘은 주로 비교 연구에 사용된다.
10.4.4 LRU Page Replacement
최적의 알고리즘이 실현 가능하지 않다면, 최적의 알고리즘의 근사값을 구할 수는 있을 것이다. FIFO와 OTP 알고리즘의 주요 차이점은 FIFO 알고리즘은 페이지가 메모리에 로드된 시간을 사용하는 반면, OPT 알고리즘은 페이지가 사용될 시간을 사용한다는 것이다. 최근 과거를 가까운 미래의 값의 근사값으로 사용하면, 가장 오랫동안 사용되지 않은 페이지를 교체할 수 있다. 이러한 접근 방식이 least recently used (LRU) algorithm이다.
LRU 교체는 각 페이지와 해당 페이지의 마지막 사용 시간을 연관시킨다. 페이지를 교체해야 할 때, LRU는 가장 오랫동안 사용되지 않은 페이지를 선택한다. 이 전략은 과거를 돌아보는 최적의 페이지 교체 알고리즘이라고 할 수 있다.
그림 10.15는 예시 참조 문자열에 LRU 교체를 적용한 결과를 보여준다.
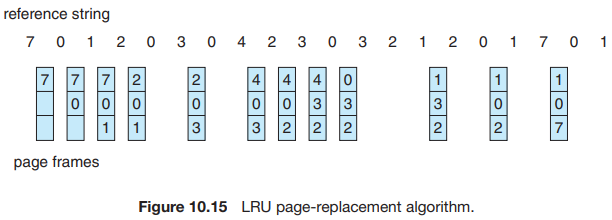
LRU 알고리즘은 12개의 fault를 생성한다. 처음 5개의 fault는 최적 교체의 오류의 동일하다. 그러나, 페이지 4에 대한 참조가 발생하면 LRU 교체는 메모리에 있는 세 프레임 중 페이지 2가 가장 최근에 사용되지 않은 것으로 간주한다. 따라서 LRU 알고리즘은 페이지 2가 곧 사용될 것이라는 사실을 모른 채 페이지 2를 교체한다. 그런 다음 페이지 2에 fault가 발생하면, LRU 알고리즘은 메모리에 있는 세 페이지 중 가장 최근에 사용되지 않은 페이지 3을 교체한다. 이러한 문제에도 불구하고, 12개의 fault이 있는 LRU는 15개의 fault가 있는 FIFO보다 훨씬 우수하다.
LRU는 페이지 교체 알고리즘으로 자주사용되며 좋은 것으로 평가된다. 가장 큰 문제는 LRU를 어떻게 구현할 것인가 이다. LRU 페이지 교체 알고리즘은 상당한 하드웨어 지원을 필요로 할 수 있다. 문제는 마지막 사용 시점을 기준으로 정의된 프레임 순서를 결정하는 것이다. 다음의 두 가지 구현이 가능하다:
- Counters. 가장 간단한 경우, 각 페이지 테이블 항목에 사용 시간 필드를 연결하고 CPU에 논리 clock 또는 counter를 추가한다. colck은 메모리 참조가 발생할 때마다 증가한다. 페이지를 참조할 때마다 클럭 레지스터의 내용이 해당 페이지의 페이지 테이블 항목에 있는 사용 시간 필드에 복사된다. 이렇게 하면 각 페이지에 대한 마지막 참조의 "time" 향상을 얻을 수 있다. 시간 값이 가장 작은 페이지를 교체한다. 이 방식은 페이지 테이블을 검색하여 LRU 페이지를 찾고, 각 메모리 액세스 시 메모리에 쓰기를 요구한다. CPU 스케줄링으로 인해 페이지 테이블이 변경될 때도 이 시간이 유지되어야 한다. 클럭 오버플로우도 고려해야 한다.
- Stack. LRU 교체를 구현하는 또 다른 방법은 페이지 번호 스택을 유지하는 것이다. 이렇게 하면 가장 최근에 사용된 페이지가 항상 스택 맨 위에, 가장 최근에 사용되지 않은 페이지가 항상 맨 아래에 위치 한다(그림 10.6).
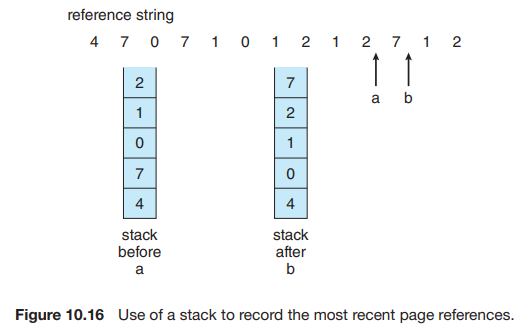
스택 중간에서 항목을 제거해야 하므로, head 포인터와 tail 포인터를 사용하는 이중 linked list를 사용하여 이 방법을 구현하는 것이 가장 좋다. 페이지를 제거하여 스택 맨 위에 배치하려면 최악의 경우 포인터 6개를 변경해야 한다. 각 업데이트는 약간 더 비용이 많이 들지만, 교체 페이지를 검색할 필요가 없다. tail 포인터는 스택 맨 아래, 즉 LRU 페이지를 가리킨다.
최적 교체와 마찬가지로, LRU 교체는 벨라디 이상현상이 발생하지 않는다. 두 알고리즘 모두 stack 알고리즘이라는 페이지 교체 알고리즘의 한 종류에 속하며, 벨라디 이상현상이 발생할 수 없다. 스택 알고리즘이란, n개의 프레임을 사용할 때 메모리에 존재하는 페이지 집합이, n+1개의 프레임을 사용할 때의 페이지 집합의 하위집합이 된다는 것을 보여줄 수 있는 알고리즘이다. LRU의 경우, 메모리에 있는 페이지 집합은 가장 최근에 참조된 n개의 페이지가 된다. 프레임 수가 증가하더라도, 이 n개의 페이지는 여전히 가장 최근에 참조된 페이지이므로 메모리에 계속 남아 있게 된다.
표준 TLB(Translation Lookaside Buffer) 레지스터를 넘어서는 하드웨어 지원 없이는 LRU 구현이 불가능하다.
TLB register란?
메모리 관리 유닛(MMU)에 의해 관리되는, 가상 주소를 물리적 주소로 변환하는 과정에서 사용되는 주소 매핑 정보를 저장하는 작은 메모리 캐시. 가상 주소를 물리적 주소로 변환하는 과정을 빠르게 처리하기 위해 사용.
클록 필드나 스택의 업데이트는 모든 메모리 참조에 대해 수행되어야 한다. 소프트웨어가 이러한 데이터 구조를 업데이트할 수 있도록 모든 참조에 인터럽트를 사용한다면, 모든 메모리 참조 속도가 최소 10배 느려지고, 따라서 모든 프로세스 속도가 10배 느려질 것이다. 메모리 관리에 있어 이 정도 수준의 오버헤드를 허용할 수 있는 시스템은 거의 없다.
10.4.5 LRU-Approximation Page Replacement
LRU 페이지 교체를 위한 충분한 하드웨어 지원을 제공하는 컴퓨터 시스템은 많지 않다. 실제로 일부 시스템은 하드웨어 지원을 전혀 제공하지 않아 다른 페이지 교체 알고리즘을 사용해야 한다. 하지만, 많은 시스템은 reference bit 형태로 어느 정도 도움을 제공한다. 페이지 참조 비트는 해당 페이지가 참조될 때마다 하드웨어에 의해 설정된다. 참조 비트는 페이지 테이블의 각 항목과 연관된다.
처음에는, 운영체제에 의해 모든 비트가 0으로 초기화된다. 프로세스가 실행되면 참조되는 각 페이지와 관련된 비트가 하드웨어에 의해 1로 설정된다. 시간이 지나면 참조 비트를 검사하여 어떤 페이지가 사용되었고 어떤 페이지가 사용되지 않았는지 확인할 수 없지만, 사용 순서는 알 수 없다. 이 정보는 LRU를 근사하는 많은 페이지 교체 알고리즘의 기반이 된다.
10.4.5.1 Additional-Reference-Bits Algorithm
참조 비트를 정기적으로 기록함으로써 추가적인 순서 정보를 얻을 수 있따. 메모리에 테이블의 각 페이지마다 8-bit byte를 보관할 수 있다. 일정한 간격으로 타이머 인터럽트가 운영 체제로 제어권을 넘긴다. 운영체제는 각 페이지의 참조 비트를 8-bit byte의 상위 비트로 이동시키고, 다른 비트는 1bit씩 오른쪽으로 이동시키고 하위 비트는 버린다. 이 8-bit shift register에는 최근 8시간 동안의 페이지 사용 내역이 저장된다. 예를 들어, shift 레지스터에 00000000이 저장되어 있다면 해당 페이지는 8시간 동안 사용되지 않았음을 으미한다. 각 주기에서 최소 한 번 이상 사용되는 페이지의 shift 레지스터 값은 11111111이다. 히스토리 레지스터 값이 11000100인 페이지는 값이 01110111인 페이지보다 최근에 사용된 것이다. 이 8-bit byte를 부호없는 정수로 해석하면, 가장 낮은 번호를 가진 페이지가 LRU 페이지이며, 이 페이지는 교체될 수 있다. 그러나 번호가 고유하다는 보장은 없다. 가장 작은 값을 갖는 모든 페이지를 교체할 수도 있고, FIFO 방법을 사용하여 그 중에서 선택할 수도 있다.
shift 레지스터에 포함되는 히스토리 비트 수는 가변적이며, 업데이트 속도를 최대한 높이기 위해 선택된다. 극단적인 경우에는 이 비트 수를 0으로 줄여 참조 비트만 남길 수 있다. 이 알고리즘은 second-chance page-replacement 알고리즘이라고 한다.
10.4.5.2 Second-Chance Algorithm
second-chance 교체의 기본 알고리즘은 FIFO 알고리즘이다. 페이지가 선택되면 해당 페이지의 참조 비트를 검사한다. 참조 비트 값이 0이면 해당 페이지를 교체한다. 참조 비트가 1이면 해당 페이지에 두 번째 기회를 주고 다음 FIFO 페이지를 선택한다. 페이지에 두 번째 기회가 주어지면 참조 비트는 초기화되고 도착 시간이 현재 시간으로 재설정된다. 따라서 두 번째 기회가 주어진 페이지는 다른 모든 페이지가 교체되거나 두 번째 기회가 주어질 때까지 교체되지 않는다. 또한, 페이지가 참조 비트를 설정할 정도로 자주 사용되면 교체되지 않는다.
second-chance 알고리즘(clock 알고리즘이라고도 함)을 구현하는 한 가지 방법은 순환 큐(circular queue)이다. 포인터는 다음에 교체될 페이지를 나타낸다. 프레임이 필요할 때, 포인터는 참조 비트가 0인 페이지를 찾을 때까지 이동한다. 이동하면서 참조 비트를 지운다(그림 10.17).
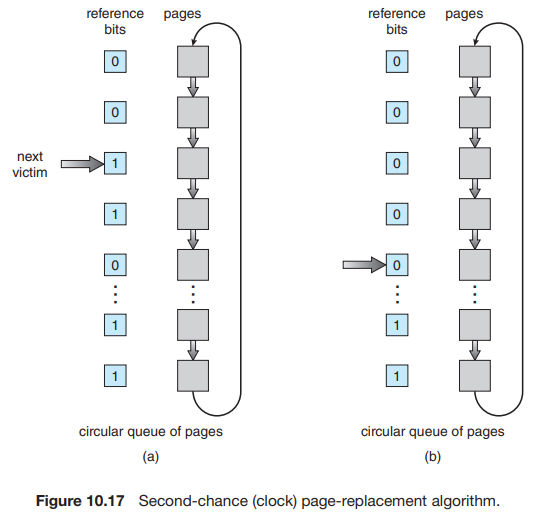
희생 페이지가 발견되면 해당 페이지는 교체되고, 새 페이지는 순환 큐의 해당 위치에 삽입된다. 최악의 경우, 모든 비트가 설정되면(=참조 비트가 1) 포인터는 전체 큐를 순환하며 각 페이지에 두 번째 기회를 제공한다. 포인터는 다음 교체할 페이지를 선택하기 전에 모든 참조 비트를 지운다. 모든 비트가 설정되면 second-chance는 FIFO로 변질된다.
10.4.5.3 Enhanced Second-Chance Algorithm
reference 비트와 modify 비트를 순서쌍으로 간주하여 second-chance 알고리즘을 향상시킬 수 있다. 이 두 비트를 사용하여 다음과 같은 네 가지 클래스를 만들 수 있다:
- (0, 0) 최근 사용X, 수정X - 교체하기 가장 좋은 페이지
- (0, 1) 최근 사용X, 수정O - 교체하기 전에 페이지를 다시 작성해야 하므로 그다지 좋지 않음.
- (1, 0) 최근 사용O 수정X - 아마도 곧 다시 사용될 것임.
- (1, 1) 최근 사용O, 수정O - 아마도 곧 다시 사용될 것이며, 페이지는 교체되기 전에 보조 기억장치에 기록되어야 함.
각 페이지는 이 네 가지 클래스 중 하나에 속한다. 페이지 교체가 필요할 때, clock 알고리즘과 동일한 방식을 사용한다. but 가리키는 페이지의 참조 비트가 1로 설정되어 있는지 확인하는 대신, 해당 페이지가 속한 클래스를 확인한다. 비어 있지 않은 최하위 클래스에서 발견된 첫 번째 페이지를 교체한다. 교체할 페이지를 찾기 전에 순환 큐를 여러 번 스캔해야 할 수도 있다. 이 알고리즘과 더 간단한 clock 알고리즘의 주요 차이점은, 필요한 I/O 횟수를 줄이기 위해 수정된 페이지를 우선적으로 처리한다는 것이다.
10.4.6 Counting-Based Page Replacement
페이지 교체에 사용할 수 있는 다른 알고리즘도 많이 있다. 예를 들어, 각 페이지에 대한 참조 횟수를 기록하고 다음 두 가지 방법을 개발할 수 있다.
- least frequently used (LFU) 페이지 교체 알고리즘은, 참조 횟수가 적은 페이지를 교체해야 한다. 이렇게 선택하는 이유는 활발하게 사용되는 페이지는 참조 횟수가 많아야 하기 때문이다. 그러나, 프로세스의 초기 단계에서 페이지가 많이 사용되다가 다시는 사용되지 않는 경우 문제가 발생한다. 많이 사용되었기 때문에, 개수가 많고, 더 이상 필요하지 않더라도 메모리에 남아있다. 한 가지 해결책은 카운트를 일정한 간격으로 오른쪽으로 1비트씩 이동시켜, 평균 사용 횟수를 기하급수적으로 감소시키는 것이다.
- most frequently used (MFU) 페이지 교체 알고리즘은 페이지 수가 가장 적은 페이지가 방금 가져와서 아직 사용되지 않았을 가능성이 높다는 논리를 기반으로 한다.
MFU와 LFU는 일반적이지 않다. 이러한 알고리즘 구현에는 비용이 많이 들고, OPT를 잘 근사하지 못한다.
10.4.7 Page-Buffering Algofithms
특정 페이지 교체 알고리즘 외에도 다른 절차들이 종종 사용된다. 예를 들어, 시스템은 일반적으로 free 프레임 pool을 유지한다. 페이지 fault가 발생하면, 이전과 마찬가지로 victim 프레임이 선택된다. 하지만 victim 프레임이 기록되지 전에 원하는 페이지가 pool의 free 프레임에 읽혀진다. 이 절차를 통해 victim 페이지가 기록될 때까지 기다리지 않고 프로세스를 가능한 빨리 재시작할 수 있다. 나중에 victim 프레임이 기록되면 해당 프레임이 free-frame pool에 추가된다.
이 아이디어를 확장하면 수정된 페이지 목록을 유지하는 것이 가능하다. 페이징 장치가 유휴 상태일 때마다, 수정된 페이지가 선택되어 보조 기억장치에 기록된다. 그런 다음 modify 비트가 reset된다. 이 방식은 페이지가 선택될 때, 페이지가 클린 상태일 가능성을 높여주며, 기록될 필요가 없게 한다.
"write out" = 메모리에서 디스크로 데이터를 기록하다
또 다른 수정 사항은 free frame pool을 유지하되 각 프레임에 어떤 페이지가 있덨는지 기억하는 것이다. 프레임이 보조 기억장치에 기록될 때 프레임 내용은 변경되지 않으므로, 플요한 경우 해당 프레임을 재사용하기 전에 free-freame pool에서 이전 페이지를 직접 재사용할 수 있다. 이 경우 I/O가 필요하지 않다. 페이지 fault가 발생하면, 먼저 원하는 페이지가 ree-freame pool에 있는지 확인한다. 없으면, free 프레임을 선택하여 읽어들여야 한다.
일부 UNIX 시스템 버전은 second-chance 알고리즘을 함께 사용한다. 이는 잘못된 victim 페이지가 선택되었을 때 발생하는 페널티를 줄이기 위해 모든 페이지 교체 알고리즘을 보완하는 유용한 방법이 될 수 있다. 이러한 기타 수정 사항은 섹션 10.5.3에서 설명한다.
10.4.8 Applications and Page Replacement
경우에 따라, 운영체제의 가상 메모리를 통해 데이터에 액세스하는 애플리테이션은 운영 체제가 버퍼링을 전혀 제공하지 않는 경우보다 성능이 저하된다. 대표적인 예로, 자체 메모리 관리 및 I/O버퍼링을 제공하는 데이터베이스가 있다. 이러한 애플리케이션은 범용 알고리즘을 구현하는 운영체제보다 메모리 사용량과 저장 공간 사용량을 더 잘 이해한다. 더 나아가, 운영체제가 I/O를 버퍼링하고 애플리케이션도 버퍼링 하는 경우(⇒ 이중버퍼링), 일련의 I/O에 두 배의 메모리가 사용되는 것이다.
I/O 버퍼링이란?
데이터를 한 번에 처리하지 않고 임시로 저장해두는 것
또 다른 예로, 데이터 warehouse(저장소)는 대량의 순차적 스토리지 읽기를 수행한 후 계산과 쓰기를 수행하는 경우가 많다. LRU 알고리즘은 이전 페이지를 제거하고 새 페이지를 보존하는 반면, 애플리케이션은 순차 읽기를 다시 시작하면서 새 페이지보다 이전 페이지를 읽을 가능성이 더 높다. 이 경우, MFU가 실제로 LRU보다 더 효율적이다.
이러한 문제 때문에, 일부 운영체제는 특정 프로그램이 보조 저장 파티션을 파일 시스템 데이터 구조 없이도 논리 블록의 큰 순차 배열로 사용할 수 있도록 한다. 이 배열은 raw disk라고 하며, 이 배열에 대한 I/O를 raw I/O라고 한다. raw I/O는 파일 I/O 요구 페이징, 파일 잠금, prefetching, 공간 할당, 파일 이름 및 디렉터리와같은 모든 파일 시스템 서비스를 우회한다. 특정 애플리캐이션은 raw 파티션에 자체 특수 용도 저장 서비스를 구현할 때 더 효율적이지만, 대부분의 애플리케이션은 일반 시스템 서비스를 사용할 때 더 나은 성능을 보인다.
row I/O란?
운영체제의 파일 시스템을 우회하고, 디스크(또는 저장장치)에 직접 접근하는 방식 (⇒ 버퍼링 없음)
