메인 메모리는 운영체제와 다양한 사용자 프로세스를 모두 수용해야 한다. 따라서 가능한 가장 효율적인 방식으로 메인 메모리를 할당해야 한다. 이 섹션에서는 초기 방법 중 하나인, 연속 메모리 할당에 대해 설명한다.
메모리는 일반적으로 두 개의 파티션으로 나뉜다: 하나는 운영체제용, 다른 하나는 사용자 프로세스용이다. 운영체제를 낮은 메모리 주소나 높은 메모리 주소에 배치할 수 있다. 이 결정은 인터럽트 벡터의 위치와 같은 여러 요인에 따라 달라진다. 그러나, 많은 운영체제(Linux 및 Windows 포함)는 운영체제를 높은 메모리에 배치하므로, 해당 상황만 논의한다.
우리는 일반적으로 여러 사용자 프로세스가 동시에 메모리에 존재하기를 원한다. 따라서 메모리로 가져오기를 기다리는 프로세스에 사용 가능한 메모리를 할당하는 방법을 고려해야 한다. contiguous memory allocation(연속 메모리 할당)에서, 각 프로세스는 다음 프로세스를 포함하는 섹션과 연속된 단일 메모리 섹션에 포함된다. 그러나, 이 메모리 할당을 더 논의하기 전에, 메모리 보호 문제를 해결해야 한다.
9.2.1 Memory Protection
이전에 논의한 두 가지 아이디어를 결합하여 프로세스가 소유하지 않은 메모리에 액세스하는 것을 방지할 수 있다. relocation register (Section 9.1.3)가 있는 시스템이 있다면, 목표를 달성할 수 있다. relocation register(재배치 레지스터)는 가장 작은 물리적 주소 값을 포함하고, limit register는 논리적 주소 범위를 포함한다(예: relocation=100040 및 limit=74600). 각 논리적 주소는 limit 레지스터에서 지정한 범위 내에 있어야 한다. MMU는 relocation 레지스터의 값을 추가하여 논리적 주소를 동적으로 매핑한다. 이 매핑된 주소는 메모리로 전송된다(그림 9.6)
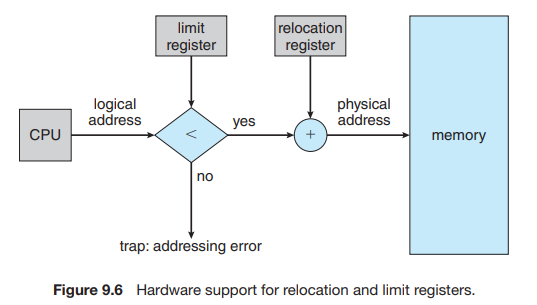
그림 설명 참고
- CPU: 프로그램이 사용하는 논리적 주소 생성
- limit register: 프로그램이 사용할 수 있는 최대 주소 범위 저장
- relocation register: 프로그램이 실제 물리적 메모리 어디에 로드되었는지를 나타내는 base address
- logical address < limit 확인: CPU가 생성한 논리 주소가 limit보다 작으면 ok, 아니면 trap 발생
- 논리 주소 + relocation = 물리주소: ok인 경우, 논리 주소에 relocation 값을 더해서 물리 주소를 계산하고 메모리에 접근
CPU 스케줄러가 실행할 프로세스를 선택하면, 디스패처는 context switch의 일부로 relocation 및 limit 레지스터의 올바른 값을 로드한다. CPU에서 생성된 모든 주소는 이러한 레지스터와 비교되기 때문에, 운영체제와 다른 사용자의 프로그램과 데이터가 이 실행 중인 프로세스에 의해 수정되는 것을 보호할 수 있다.
relocation-register 방식은 운영체제의 크기를 동적으로 변경할 수 있는 효과적인 방법을 제공한다. 이러한 유연성은 많은 상황에서 바람직하다. 예를 들어, 운영체제에는 장치 드라이버에 대한 코드와 버퍼 공간이 포함되어 있다. 장치 드라이버가 현재 사용 중이 아니라면, 메모리에 보관하는 것은 별로 의미가 없다. 대신, 필요할 때만 메모리에 로드할 수 있다. 마찬가지로, 장치 드라이버가 더 이상 필요하지 않으면, 제거하고 다른 필요에 따라 메모리를 할당할 수 있다.
9.2.2 Memory Allocation
메모리를 할당하는 가장 간단한 방법 중 하나는 메모리에 가변 크기의 파티션을 프로세스에 할당하는 것이다. variable-partition 방식에서, 운영체제가 메모리의 어떤 부분을 사용할 수 있고 어떤 부분을 차지하고 있는지 나타내는 table을 유지한다. 처음에는, 모든 메모리가 사용자 프로세스에 사용이 가능하며, 하나의 큰 사용 가능한 메모리 블록인 hole로 간주된다. 결국, 메모리에는 다양한 크기의 홀 세트가 포함된다.
그림 9.7은 이 방식을 보여준다.
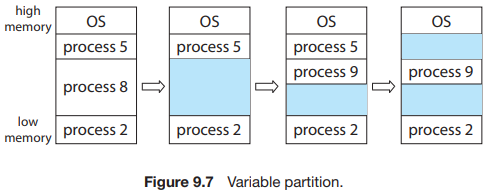
처음에는, 프로세스 5, 8, 2를 포함하여 메모리가 완전히 활용된다. 프로세스 8이 떠난 후에는, 계속 하나의 연속된 홀이 있다. 나중에 프로세스 9가 도착하여 메모리가 할당된다. 그런 다음 프로세스 5가 떠나면, 두 개의 비연속적인 홀이 생긴다.
프로세스가 시스템에 진입하면, 운영체제는 각 프로세스의 메모리 요구 사항과 사용 가능한 메모리 공간의 양을 고려하여 어떤 프로세스에 메모리를 할당할지 결정한다. 프로세스에 공간이 할당되면, 메모리에 로드되고, CPU 시간에 대해 경쟁할 수 있다. 프로세스가 종료되면, 메모리를 해제하고, 운영체제는 이를 다른 프로세스에 제공할 수 있다.
도착하는 프로세스의 요구를 충족시킬 만큼 충분한 메모리가 없을 때, 한 가지 옵션은 단순히 프로세스를 거부하고 적절한 오류 메시지를 제공하는 것이다. 또는, 이러한 프로세스를 wait queue에 넣을 수 있다. 나중에 메모리가 해제되면, 운영 체제는 대기 큐를 확인하여 대기 프로세스의 메모리 요구사항을 충족시킬지 여부를 확인한다.
일반적으로, 언급했듯이, 사용 가능한 메모리 블록은 메모리 전체에 분산된 다양한 크기의 홀 set로 구성된다. 프로세스가 도착하여 메모리가 필요할 때, 이 프로세스에 충분히 큰 홀 세트를 검색한다. 홀이 너무 크면, 두 부분으로 나뉜다. 한 부분은 도착한 프로세스에 할당되고, 다른 부분은 홀 세트로 반환된다. 프로세스가 종료되면, 메모리 블록을 해제한 다음, 다시 홀 세트에 배치된다. 새 홀이 다른 홀과 인접해 있으면, 이러한 인접한 홀이 병합되어 하나의 더 큰 홀을 형성한다.
이 프로시저(procedure: 순서, 진행, 처리 등을 뜻함)는 일반적인 dynamin storage allocation 문제의 특정 사례로, 빈 홀 목록에서 크기 n의 요청을 충족하는 방법과 관련 있다. 이 문제에 대한 솔루션은 여러 가지가 있다. first-fit, best-fit, worst-fit 전략은 사용 가능한 홀 세트에서 빈 홀을 선택하는 데 가장 일반적으로 사용된다.
-
First fit. 충분히 큰 첫 번째 구멍을 할당한다. 검색은 홀 세트의 시작 부분 또는 이전 first-fit 검색이 끝난 위치에서 시작할 수 있다. 충분히 큰 빈 홀을 찾으면 검색을 멈출 수 있다.
-
Best fit. 충분히 가장 작은(=요청 크기에 가까운) 홀을 할당한다. 목록이 크기순으로 정렬되어 있지 않으면, 전체 목록을 검색해야 한다. 이 전략은 가장 작은 남은 홀을 생성한다.
-
Worst fit. 가장 큰 홀을 할당한다. 크기에 따라 정렬되지 않은 한, 전체 목록을 검색해야 한다. 이 전략은 가장 큰 남은 홀을 생성하는데, 이는 best-fit 접근 방식에서 남은 작은 홀보다 더 유용할 수 있다.
시뮬레이션 결과, first fit과 best fit은 모두 시간과 스토리지 활용도 감소 측면에서 worst fit보다 더 나은 것으로 나타났다. first fit이나 best fit은 스토리지 활용도 측면에서 다른 것보다 분명히 더 나은 것은 아니지만, 일반적으로 first fit이 더 빠르다.
