3D-FREE MEETS 3D PRIORS: NOVEL VIEW SYNTHESIS FROM A SINGLE IMAGE WITH PRETRAINED DIFFUSION GUIDANCE [2025 ICLR]
Baseline Model Hawkl 논문리뷰: https://velog.io/@guts4/HawkI-Homography-Mutual-Information-Guidance-for-3D-free-Single-Image-to-Aerial-View-2024-arXiv

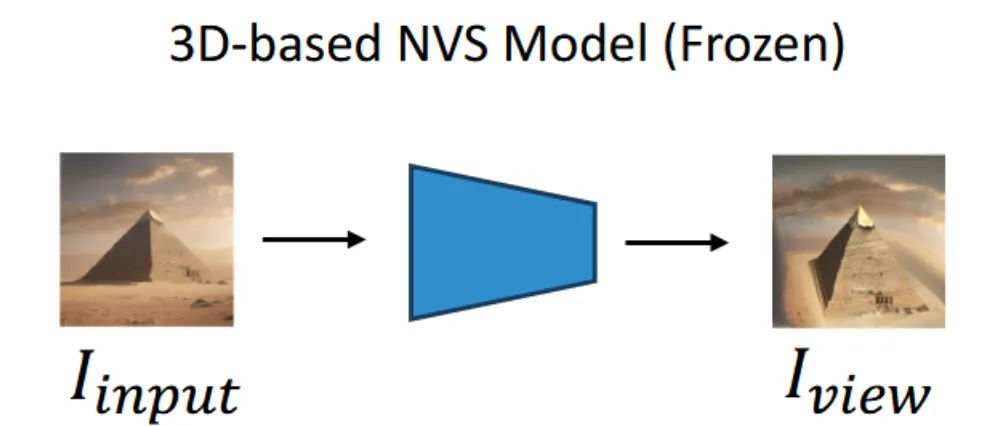
새로운 방위각과 고도의 정보를 입력하면, 해당 시점에서의 새로운 이미지를 생성하는 모델입니다.
UNDERSTANDING 2D MODELS AND THE 3D SPACE
HOW WELL DO CLIP MODELS UNDERSTAND THE 3D-SPACE

입력 이미지를 넣고, text prompt로 카메라 정보를 넣었을 때 결과입니다. 결과를 봤을 때 원본 이미지의 스타일을 잘 유지 하지 못하고, 카메라 정보를 잘 반영하지 못했습니다. 결론적으로 CLIP 모델은 카메라 정보를 잘 이해하지 못 합니다.
IMPORTANCE OF GUIDANCE IMAGE IN 3D-FREE METHODS

두번째 실험으로 guidance로 homogeneous image(특정 시점의 이미지)와 text prompt로 다른 시점의 이미지를 넣었습니다.
예를들어서 3번째 열에서 text prompt는 방위각 30, 고도30을 넣었고 guidance로는 방위각 30, 고도 270인 이미지를 넣었습니다. 결과적으로 사진은 guidance와 유사하게 나왔습니다. 따라서 Diffusion 모델은 이미지를 생성할 때 guidance를 통해서 3D 정보를 많이 얻는 것을 확인할 수 있습니다.
Method
전반적인 내용은 HawkI와 비슷합니다. HawkI에서는 Inverse perspective mapping (IPM)를 사용해서 항공뷰 이미지를 얻고, 이를 guidance로 사용했습니다. 이와달리 해당 논문에서는 Zero123++를 사용해서 얻은 결과를 guidance 이미지로 사용했습니다.
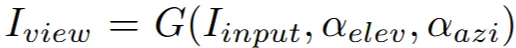
Zero123++에 입력이미지와 방위각(elev), 고도(azi)를 넣으면 해당 시점의 대략적인 이미지를 얻을 수 있습니다.
STEP 1 ~ STEP4
step1 ~ step4는 HawkI 방식과 동일해서 해당 설명을 그대로 가져오도록 하겠습니다.
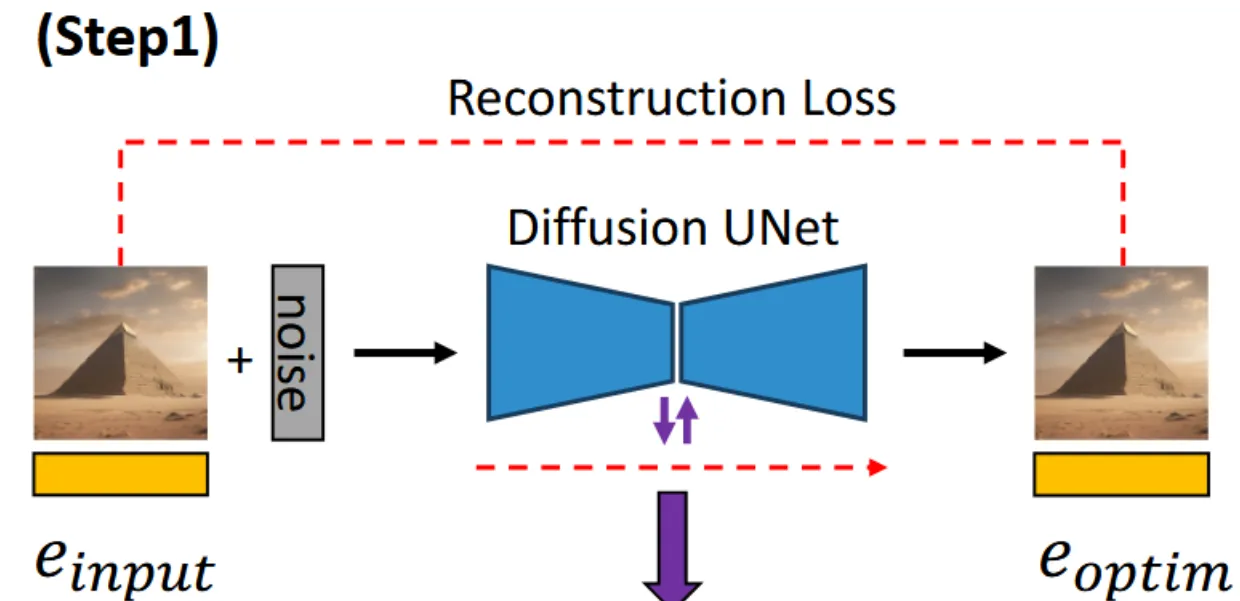
첫번째 단계에서는 CLIP을 통해서 얻은 text embedding값 를 이미지를 잘 생성하는 라는 임베딩 값으로 변환하는 과정입니다. 이때 Diffusion model은 frozen 됩니다.

수식은 위와 같습니다. L은 DDPM의 loss function이므로 쉽게 말해서 원본 이미지 를 잘 설명하는 임베딩 를 생성하는 과정입니다.
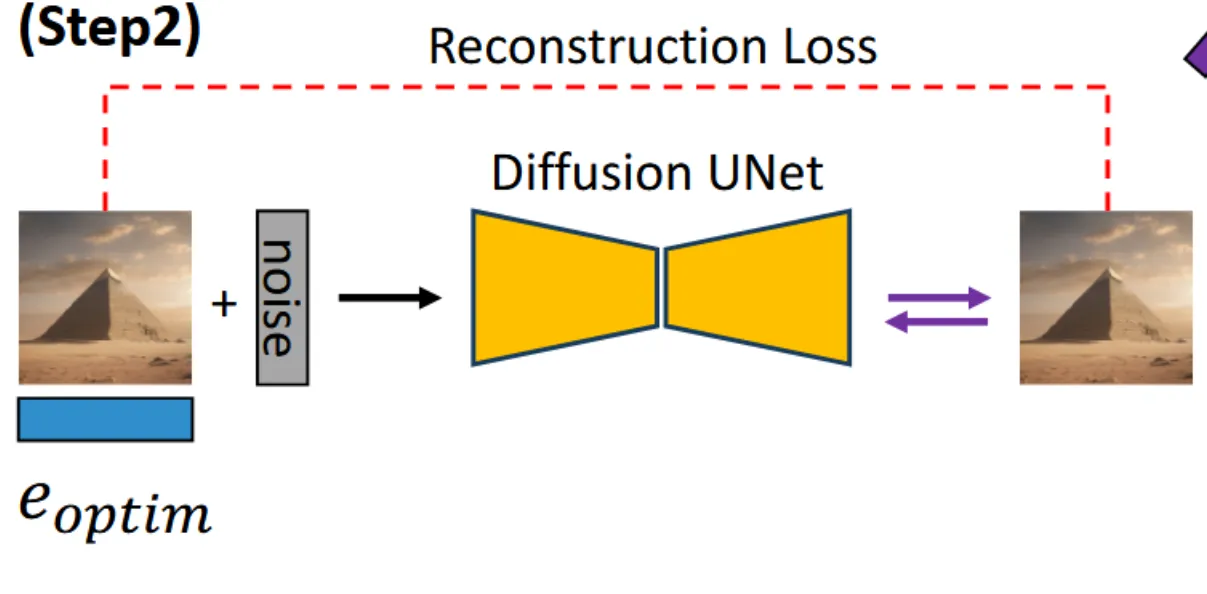
두번째 단계는 방금 생성한 를 이용해서 원본 이미지를 reconstruction을 잘하게 하는 과정입니다. 이때 사용하는 Diffusion UNet에 LoRA layer를 추가해서 파라미터만 학습하도록 합니다.
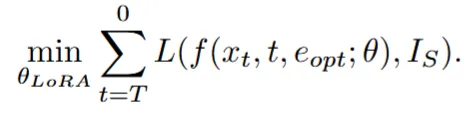
수식을 보면 이전 수식과 비슷한데 이전에는 업데이트 하는 값이 단순히 값 였다면 이번에는 Diffusion Unet에 추가한 LoRA layer의 가중치입니다.

Zero123++을 적용한 이미지에 대해서 이전과 같이 적절한 임베딩 를 생성하고, 이를 이용해서 reconstrucion 과정을 진행하면서 LoRA를 업데이트 합니다.
이때 최적화 과정은 이전 와 이전에 학습한 LoRA를 기반으로 진행됩니다. 가 아닌 를 기반으로 진행했기 때문에 저자는 embedding space를 유지하면서 이미지의 결과가 왜곡돼지 않는다고 했습니다.
VIEWPOINT REGULARIZATION
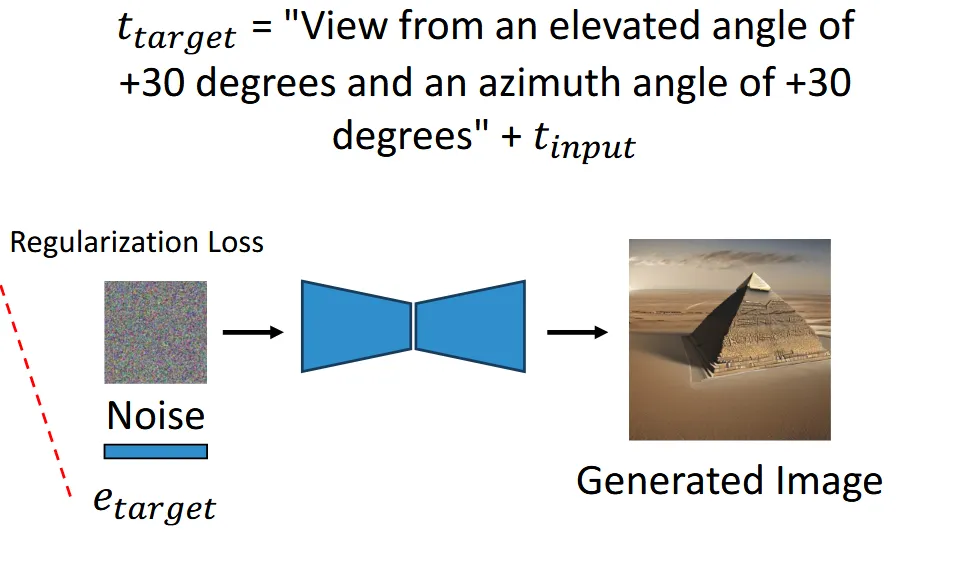
우리가 바꾸고 싶은 시점의 카메라 정보와 text prompt()을 함께 사용해서 을 생성하고, 값과 파인 튜닝된 값의 차이를 L2 Loss를 이용해서 유사하게 만듭니다.
Inference 부분에서 HawkI에서는 Mutual Information 방식을 동일하게 사용했다고 말했습니다. 이는 원본 이미지의 denoising 과정의 특정 timestep denoising값과 위의 denoising 과정에서 얻은 값을 유사하게 사용하는 방식입니다. Mutual Infromation 설명은 Hawkl와 동일하므로 그대로 가져오도록 하겠습니다.
L1 loss나 코사인 유사도를 사용해서도 두 사진을 유사하게 학습시킬 수 있지만, 이는 픽셀값이 비슷해지도록 학습할 뿐 두 이미지의 특성 자체를 비슷해지게 학습할 수 없습니다.
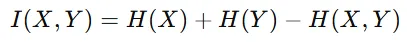
따라서 Mutual intromation을 통해서 새로운뷰 이미지가 원본 이미지의 특성과 유사하게 변하면서 항공뷰라는 특징은 변하지 않게 합니다. Mutual information은 위의 수식과 같은데 두 이미지의 엔트로피에서 공통된 엔트로피를 뺀 결과입니다.
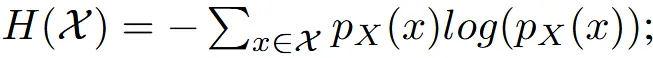
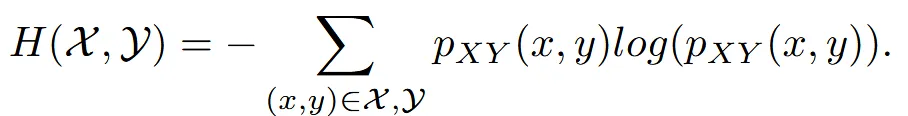
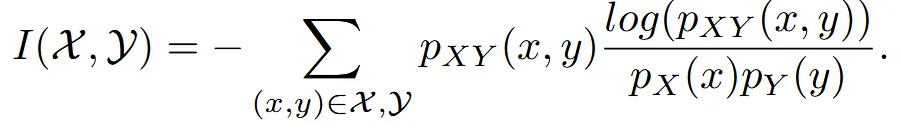
수식은 위와 같은데 그냥 쉽게 말해서 2개의 데이터의 분포를 비슷하게 학습시키는 과정입니다.
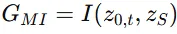
Mutual infomation 값이 커질수록 두 이미지의 분포가 비슷해지기때문에 위의 guidance function을 이용해서 값을 최대화 합니다. 그리고 의 gradient를 이용해서 매 timestep마다 latent를 수정합니다.

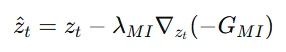
결론적으로 샘플링 과정이 왼쪽에서 오른쪽으로 Mutual information을 사용한 수식으로 변경됩니다.
Experiments

개인적으로 Zero123++의 결과가 더 좋아보이긴 합니다.. 설명으로는 첫번째 피라미드는 그림자가 없고, 두번째 폭포는 부자연스럽고, 세번째 집은 배경이 부자연스럽다고 했습니다.

바로 아래 사진은 Ours가 조금 더 좋아보이긴 합니다.
Limitation
- Inference-time optimization을 수행해야 해서 시간이 오래걸린다.
- Object Editing, Object Insertion, Composition같은 작업에서 실제 접촉 지점(contact points)과 상대적 크기(relative sizes)를 유지하는 것이 어려움
- 현재 방법은 CLIP 텍스트 임베딩을 중심으로 최적화되었지만, 보다 높은 수준의 (view consistency을 달성하려면 이미지 기반 조건을 추가해야 할 필요가 있음
