Make-It-Animatable: An Efficient Framework for Authoring Animation-Ready 3D Characters [CVPR 2025]
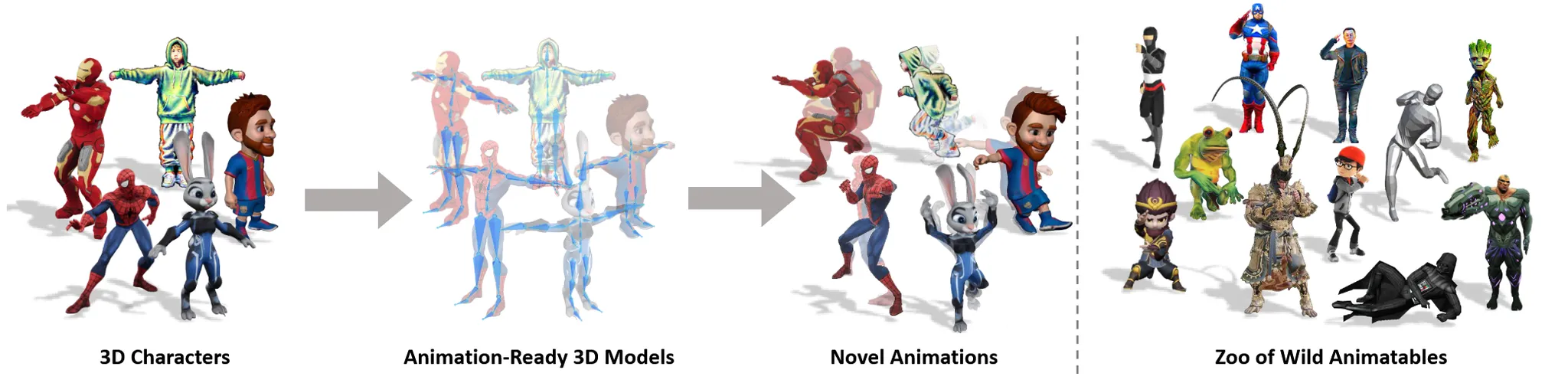
3D 캐릭터를 넣으면 해당 캐릭터가 새로운 동작을 취할 수 있는 애니메이션 기능을 제공해줍니다. 애니메이션에 대해서 많이 읽어보지 않았기 때문에 최대한 쉽게 이해할 수 있도록 설명하겠습니다.
Method
Preliminaries
N: Particle(입자)의 개수
T: animation timestamps
d: degrees of freedom(rigid(강체)의 경우 rotation과 scaling으로 d=6)
위의 3개의 요소를 고려해서 deformation 행렬의 경우 와 같이 표현할 수 있습니다.
하지만 입자들이 중복되는 경우가 많기 때문에 이를 low-rank approximation의 방식을 통해서 으로 나타낼 수 있습니다.
K: desired rank(원하는 차원)
: temporal basis(애니메이션 동안 캐릭터의 관절이나 제어 노드가 어떤 동작(포즈)을 하는지 나타내는 기본적인 움직임 정보)
: spatial weight(각 관절이나 노드가 캐릭터 표면의 어떤 부분에 얼마나 영향을 미치는지를 나타내는 값)
캐릭터의 모양(geometry)이 주어졌을 때, 애니메이션을 위해 필요한 요소
- Bone
- K개의 관절로, 각 관절은 뼈의 시작(헤드)과 끝(테일) 위치로 표현
- 수학적으로는 (6는 각 뼈의 두 위치(시작과 끝)를 나타냄)
- Pose Tranformation
- 입력된 다양한 포즈를 공통의 rest pose로 변환하기 위한 6-DoF 변환
- 수학적으로 로 표현
- Blend Weights
- 각 관절과 각 입자 사이의 영향력을 나타내는 가중치
- 수학적으로 로 표현
Particle-based Shape Autoencoder
Neural field encoding
Encoding 부분은 ‘3DShape2VecSet’ 모델과 유사하게 설계 됐습니다. Point cloud 에서 시작해서 Farthest point sampling(FPS) 방식을 사용해서 다운샘플링 결과 를 얻습니다.
Farthest point sampling(FPS) 방식은 각각의 점들이 선택된 점들과의 거리 중 최솟값을 계산하고, 이 최솟값들 중에서 가장 큰 값을 선택해서 가장 동 떨어진 점을 선택하는 방식입니다. 이렇게 M번 진행되면 우리가 원하는 다운샘플링 결과를 얻을 수 있습니다.
다운샘플링된 결과에 positional encoding을 취해서 고차원으로 변환해줍니다 .
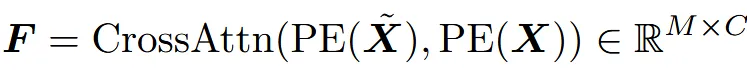
다운샘플링된 결과에 PE를 적용한 값과, 원본값에 PE를 적용한 결과를 Cross attention 취해서, 최종적인 latent feature F를 얻습니다.
Geometry-aware attention
Mesh를 point sampling을 진행했을 때 기하학적인 정보(곡률, 세부적인 형태)가 많이 변형 될 수 있고 이는 blend weight corruption problems(잘못된 블렌드 웨이트가 할당되는 문제)가 발생할 수 있습니다.

이를 해결하기 위해서 각 포인트마다 normal 값을 이용한 attention layer를 이전의 CrossAttn의 branch로 추가합니다. 초기의 영향력은 0이고, 임의의 값을 손상시키는 등의 과정을 통해서 robust하도록 학습시킵니다.
Spatially continuous decoding for blend weights
3D 공간 내의 임의의 좌표에서 blend weight를 예측할 수 있어야 합니다. 즉, blend wieght가 연속적으로 정의되어야 합니다. 임의의 좌표에서 blend weight를 얻는 과정을 간단히 설명하도록 하겠습니다.

임의의 점들 (개의 점)에 대해서 PE(positional encoding)을 진행한 결과와 F의 Selfattn의 결과와 CrossAttn을 진행한 결과가 가 됩니다. blend weight는 간단한 MLP()를 통해서 를 얻습니다.
Learnable discrete decoding for bone attributes
뼈와 같이 집단적인 속성에 대해서 blend weight(모든 점에 대해서 가중치를 나타낸 값)를 사용하면 비효율적이고, 예측 값이 불안정해집니다.
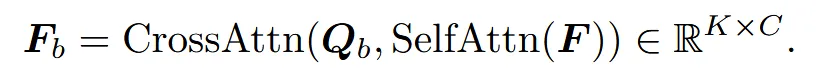
이를 극복하기 위해서 학습 가능한 semantic queries를 사용합니다. K개의 뼈가 있을 때 우리는 학습 가능한 query embedding()를 F와 결합해서 뼈별 임베딩 값 를 얻습니다.
이후 2개의 개별 디코더가 사용되어 각 뼈의 원하는 속성을 예측합니다. 첫번째는 뼈의 시작과 끝의 위치 , 두번째는 pose-to-rest transformation 를 얻습니다. 2개의 내용은 preliminaries에서 설명되었고, 마지막 P의 값은 6차원보다는 8차원이 더 많은 정보를 담고 있으므로 나중에 rigid transformation을 통해서 로 변환합니다.
Coarse-to-Fine Shape Representation

이전에 설명한 방법을 통해서 blend weight 값은 잘 예측되지만, 손처럼 세밀한 부분에서 관절 예측이 어렵습니다. 지금까지의 과정을 Coarse 단계라고 하면 해당 과정에서는 캐릭터의 주요 부위가 어느 위치에 있는지 대략적으로 파악합니다.
이후에 Fine 단계는 Canonical Transformation과 hierarchical sampling 과정으로 진행됩니다. Canonical Transformation은 입력된 캐릭터의 포즈를 공통의 방향으로 정렬합니다. Hierarchical sampling은 손과 같이 세밀한 부분에 더 많은 정보를 얻는 과정입니다.
Structure-Aware Modeling of Bones
뼈별 학습가능한 임베딩 값을 얻었지만, 뼈들의 연결 구조(topology)를 반영 하지 못하면 예측이 부정확해질 수 있습니다. 실제로 뼈들은 상하위 관계를 갖는데 이러한 정보가 제대로 반영되지 않아서 부정확한 결과가 나타납니다. 이를 해결하기 위해서 뼈들의 계측정 구조를 고려한 네트워크를 설계했습니다.
Next-child-bone prediction via causal attention
현재 설계된 모델은 각 뼈들에 대한 독립적인 결과를 나타냅니다. 하지만 실제로 손의 움직임은 손가락에 영향을 주는 계층적인 구조로 되어있습니다.
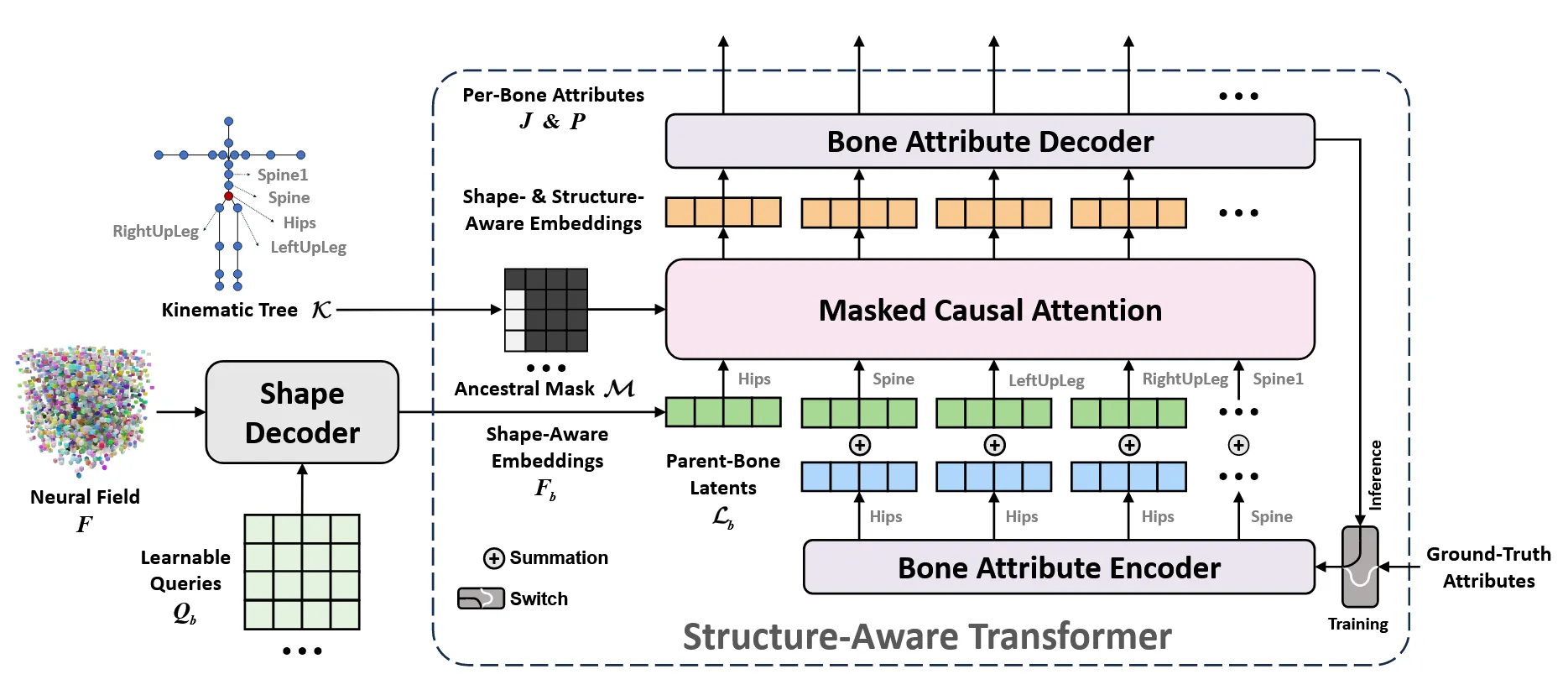
이를 반영하기 위해서 LLM에서 사용한 decoder-only next-token prediction 방식을 사용합니다.
뼈별로 학습된 임베딩 을 사용합니다(그림상에서 가운데에 Shape-Aware Embeddings). 실제 뼈 속성을 bone attribute encoder를 사용해서 같은 크기의 임베딩 값으로 만듭니다 . Kinematric tree를 통해서 자신의 부모인 경우 1(흰색) 아닌 경우 0(검정색)을 갖는 Ancestral mask도 생성합니다.
계층적인 학습을 위해서 kinematic tree(K)를 이용해서 i의 parent j(손가락의 parent 손)의 값을 구합니다. Anc(i,k)값은 i번째 뼈의 조상들 값을 나타냅니다. 예를들어서 i가 손가락을 나타내면 Anc(i,k)는 손, 팔, 몸통 이런식으로 최초의 조상까지 나타냅니다. 이때 Anc(1,k)(1)을 사용해서 바로 자신의 윗부모인 손만 가져오도록 합니다.
이렇게 바로위의 조상을 구하고, 의 각 값들의 부모 값의 를 더해줍니다(초록색과 파란색 임베딩의 합). 이후 이전에 구한 Ancestral mask를 통해서 자신의 조상 정보와만 cross-attention을 진행하는 Masked Casual Attention을 진행합니다. 이 과정에서 조상의 정보는 과거, 자식의 정보는 미래의 정보로 간주해서 과거의 정보만 사용해서 미래를 예측하는 decoder-only next-token prediction 방식을 사용했습니다.
Masked Casual Attention을 진행하고 나온 결과는 계층적인 정보와 전체 모양의 정보가 모두 반영된 정보입니다. 최종적으로 이를 Bone Attribute Decoder를 통과시켜 각 뼈마다 J(시작과 끝의 정보), P(pose-to-rest transform) 2가지 정보를 예측합니다.
Body prior loss
Ground-truth 값을 기반으로 각각의 뼈들을 직접 학습하지만, 다양한 정답이 나올 수 있기 때문에 추가적인 제약 조건을 사용했습니다.
- Bone connectivity: 각 뼈의 시작은 조상의 끝과 연결되어 있어야 한다.
- Bone symmetry: Rest pose는 좌우 대칭이어야 한다.
- Bone parallelism: Rest pose에서 같은 limb(부분)은 같은 방향을 나타내야 한다.
Summary

전체 모델의 아키텍처를 보면서 다시한번 정리하겠습니다.
Coarse-to-Fine Shape Representation
Unifrom Sampling: 입력값을 면적에 비례하게 point cloud로 변환하는 과정Coarse Localization: 간단한 모델/ AutoEncoder로 뼈 위치와 전역 정렬을 대략적으로 구함Global Transform: 캐릭터의 힙을 원점으로, 힙을 정의하는 평면이 법선 +z축을 향하도록 회전하면서 모든 캐릭터가 동일한 위치와 방향을 갖도록 설정Hierarchical Sampling: 손과 같은 미리 정해진 세밀한 영역에 더 많은 점을 추가하는 과정
Particle-based Shape Autoencoder
Geometry-Aware Attention: Point sampling으로 인한 기하학적인 정보의 손실을 극복하기 위해서 normal을 이용한 attention layer를 branch로 추가Shape Encoder&Shape Decoder: 기존의 모델을 그대로 가져와서 사용Learnable Quereis: 뼈별 학습가능한 semantic queries
Structure-Aware Modeling
Weight Decoder: 에 대해서 간단한 MLP를 통해서 얻은 최종적인 blend weightsStructure-Aware Transformer: 계층적인 뼈들의 구조를 반영한 방법
논문 자체에서 기본적인 개념들의 경우 설명이 생략된 경우도 있어서 어려웠지만, 애니메이션을 조작하는 방법에 대해서 간단하게 배울 수 있었습니다.
