3D Paintbrush: Local Stylization of 3D Shapes with Cascaded Score Distillation[CVPR 2024]
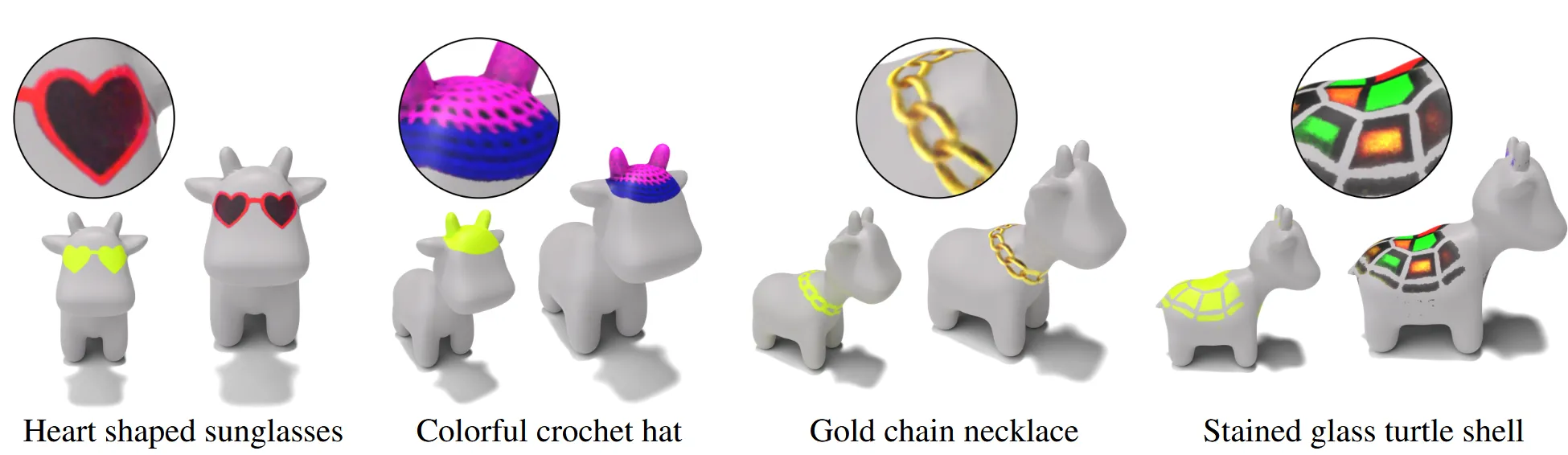

사용자가 Text prompt를 입력하면 3D Mesh의 특정 부분에 원하는 texture를 자동으로 입혀주는 3D Paintbursh를 제안했습니다.
Method
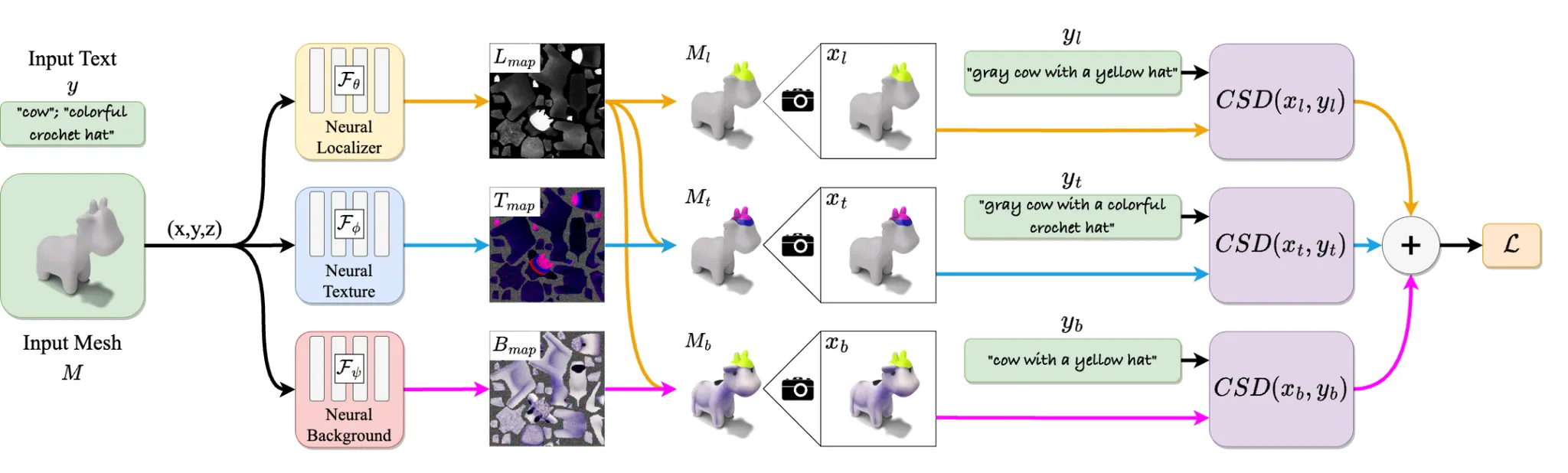
3D Paintbrush는 입력으로 3D 메시(M)와 사용자가 원하는 지역 편집에 대한 텍스트 설명(y)을 받는다. 이 시스템은 텍스트 프롬프트에 맞게 메시의 특정 부분에 정밀하게 텍스처를 수정하는 결과를 출력한다. 텍스트 조건을 3D 메시 편집에 반영하기 위해 학습된 텍스트-이미지 생성 모델에서 얻는 score distillation 기법을 사용한다. 특히, 지역적인 편집은 작은 영역에 대해 더 높은 디테일이 요구되기 때문에, 다양한 해상도의 정보를 동시에 활용하는 Cascaded Score Distillation(CSD) 방식을 도입하여, 세밀하고 자연스러운 텍스처 수정이 가능하도록 한다.
Local Neural Texturing
2D Texture map에 대해 바로 MLP를 적용하면 Seam 현상이 발생할 수 있기 때문에, Mesh의 3D 좌표(x,y,z) 자체에 대해 MLP를 적용해서 texture 값을 출력하도록 설계 했습니다.
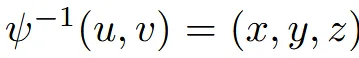
ψ함수가 3D 좌표를 2D Texture mapping 해주는 함수라고 할 때, Texture map의 픽셀값에 대응되는 3D 좌표를 찾고, 이를 MLP에 입력해서 texture 값을 예측하도록 합니다.
MLP는 크게 2가지가 존재합니다.
Localization MLP($F_{\theta}$): 3D 좌표를 입력 받아 그 위치가 편집할 지역인지 아닌지를 확률(p)로 출력
Texture MLP($F_φ$): 3D 좌표를 입력 받아 그 위치의 RGB 값을 출력
실제 구현에서는 3D 좌표를 positional encoding을 거쳐 6-layer MLP에 넣어서 최종적으로 원하는 값을 출력합니다.
Visual Guidance for Localized Textures
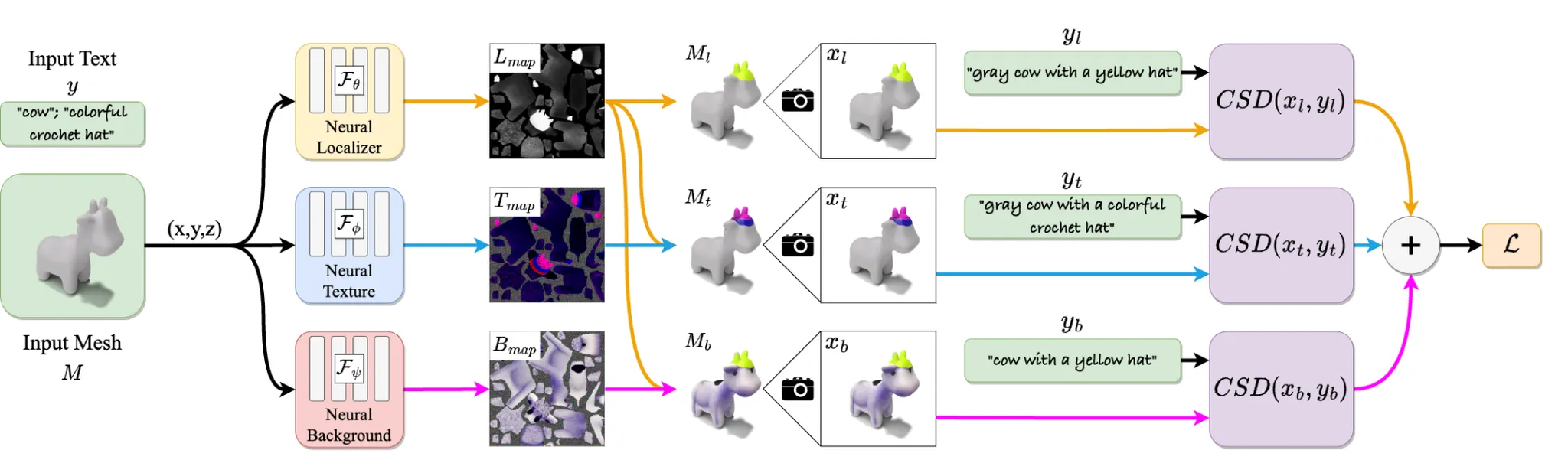
위에 그림에서 보셨던 것처럼 해당 논문에서는 3가지 loss를 사용합니다. 위에서 부터 첫번째 branch는 localization loss, 가운데 branch는 local texture map loss, 마지막 branch는 background loss입니다.
Local texture map loss
Localization Map()을 Texture Map()에 적용해서 local texture map()을 얻습니다. 해당 Map을 Mesh에 적용한 를 얻고 이를 local-texture text prompt()와 비교해서 loss를 구합니다.
Localization loss
Texture에 대한 loss만 사용한다면 localization map은 우리가 원하는 영역보다 더 큰 결과를 야기할 것입니다. 따라서 localization map에 특정색(노란색)으로 칠해서 얻은 localization-colored mesh ’3D Highlighter’ 논문에서 사용한 동일한 방식으로 생성한 text prompt 와의 비교를 통해서 loss를 계산합니다.
Background loss
편집할 영역을 명확하게 구분짓기 위해서 background loss를 추가합니다.
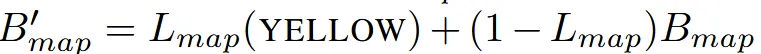
Background Map()을 이용해서 와 비슷하게 수정하고자 하는 영역을 노란색으로 칠합니다. 의 색깔은 원래 3D 모델이 가지고 있던 특징적인 색깔이 들어가게 될 것입니다.
을 Mesh에 적용해서 를 생성하고 text prompt 와 비교해서 loss를 계산합니다. 는 generic object class(cow)와 colored localization region(yellow)가 들어갑니다. Text prompt를 정하는 방법은 supplemental material을 참고하시면 됩니다.

Localization과 Texture를 동시에 학습해야 되는 이유를 설명하는 그림입니다. 맨 왼쪽이 동시 최적화, 가운데 그림이 Localization → Texture를 학습하는데 편집 영역과 텍스처가 모두 디테일이 떨어지는 것을 알 수 있습니다. 맨 오른쪽 그림에서 맨 왼쪽은 Localization만 가운데는 Texture만 오른쪽 그림은 Localization마스크로 texture를 마스킹한 결과입니다.
Score Distillation and Cascaded Diffusion
Score Distillation

이제는 잘 아시겠지만 렌더링된 이미지 x에 t시점의 노이즈를 추가한 뒤, text(y)를 condition으로 주어서 t시점의 노이즈를 예측하는 과정입니다.
Cascaded Diffusion
Text-to-image diffusion 모델중에서 해상도를 높여가면서 이미지를 생성하는 cascaded 방식을 사용하는 논문들이 있습니다. Cascaded diffusion은 크게 base stage와 super-resolution stage로 나뉩니다.
Base stage는 일반적인 diffusion 모델과 동일하게 작동하고, Super-resolution stage는 입력으로 현재 단계 해상도의 노이즈 이미지()와 이전 단계 해상도의 노이즈 이미지()를 생성합니다.
Standard SDS는 super-resolution stage 단계에서는 여러 해상도의 이미지를 동시에 입력받으므로 gradient를 계산한느 것이 직관적으로 명확하지 않아 오직 base stage만을 사용해서 학습했습니다. 해당 논문에서는 SDS 방식을 일반화해서 모든 단계에서 score distillation 신호를 추출하는 방식을 제안(아래 설명)했습니다.
Cascaded Score Distillation
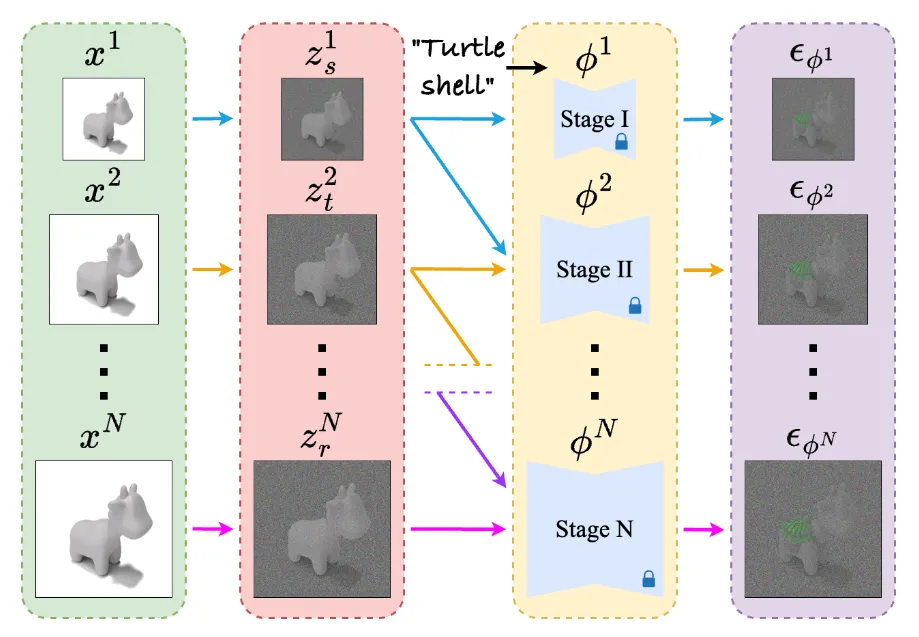
해당 논문에서 처음으로 Cascaded diffusion을 위의 그림처럼 score distillation 가능하도록 설계 했습니다. 모든 과정은 동시에 진행됩니다.
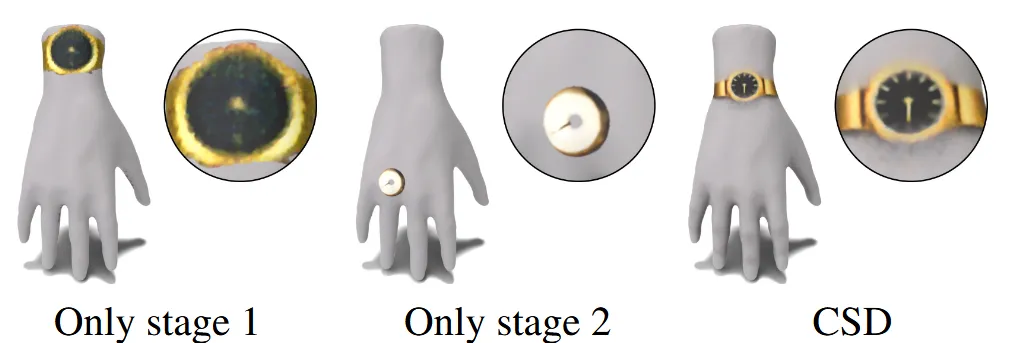
위 그림을 통해서 각각의 Stage가 다른 결과를 학습하는 것을 확인했습니다.

Stage1과 Stage2의 Weight를 얼마나 크게 하느냐에 따른 interpolation의 결과인데 이를 통해서 적절한 값을 선택해 좋은 결과를 유도할 수 있습니다.
CSD Formalization
우리가 Diffusion 모델을 통해서 학습하고자 하는 값은 결론적으로 MLP의 하이퍼파라미터 입니다. 우선 Mesh 로부터 N개의 서로다른 해상도 이미지를 렌더링합니다. 이 해상도는 각 Stage에서 사용할 이미지의 해상도와 동일합니다.
Base stage는 일반적인 SDS와 동일하게 작동합니다.
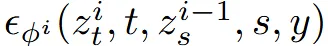
이후 Super-resolution stage에서는 현재시점의 랜더링 이미지에 timestep t에서의 노이즈를 추가한 와 이전시점의 렌더링 이미지에 timestep i를 추가한 을 입력으로 사용해서 time step(t,s)에서의 노이즈를 예측합니다.
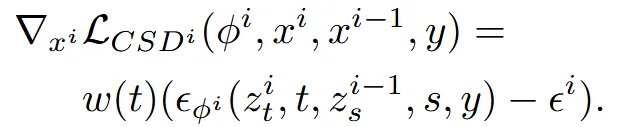
각각의 stage마다 w(t)로 가중치를 주어서 얼마나 영향을 미칠지 정할 수 있습니다.
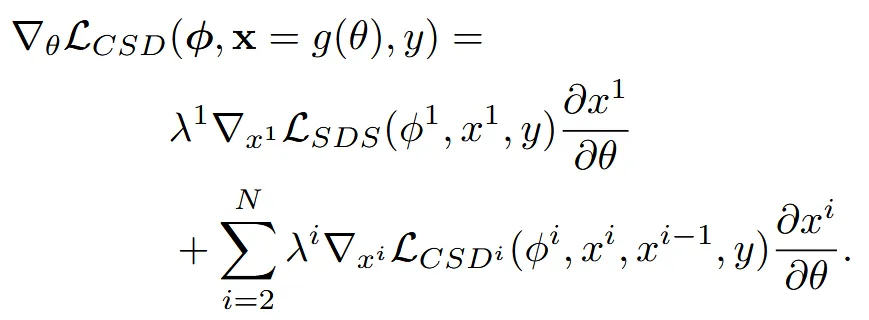
Base stage의 loss까지 추가한 최종적인 CSD의 수식은 위와 같습니다.
Experiments
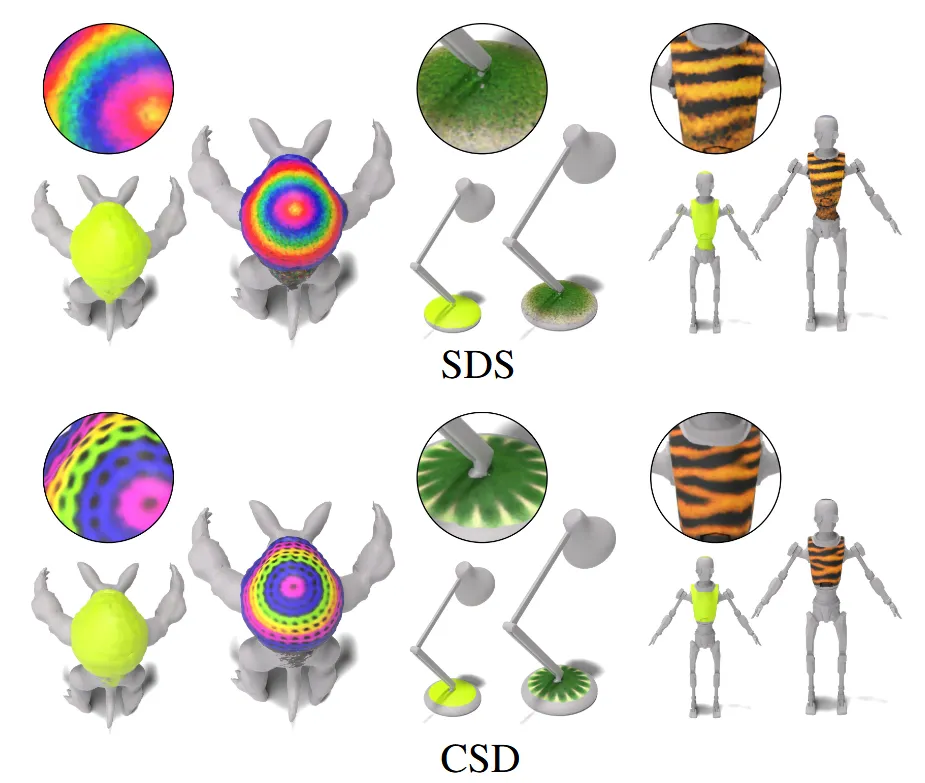
SDS와 비교한 결과인데 디테일한 결과가 확실히 Super-resolution stage를 진행한 CSD가 더 좋은 것을 알 수 있습니다.
Limitations

Text prompt가 ‘Pharaoh head-dress”라고 입력하면 머리 장식만을 생성하는게 아니라 세트로 목걸이 장식까지 생성해버립니다. 즉 text prompt가 다른 부위와 의미적으로 강하게 연결되어 있을 때 보다 넓은 영역이 편집될 수 있습니다. 위의 그림이 이에 대한 설명입니다.
또한 Janus effect도 발생합니다.
