AR-1-to-3: Single Image to Consistent 3D Object via Next-View Prediction [2025 arXiv]
2025 ICLR 철회?(OpenReview ID: pOcGFvfgjS)
기존 문제점들
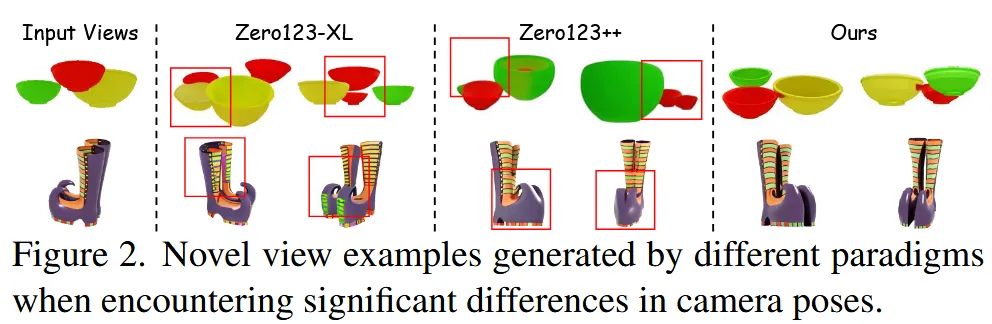
Zeor123, Zero123++처럼 기존 NVS(Novel View Synthesis) 논문들은 새로운 시점의 이미지가 입력 이미지와 gap이 존재하는 것을 확인할 수 있습니다. 예를들어서 ZEro123-XL에서는 그릇 개수가 더 많아지거나, 초록색 문양이 생기고, Zero123++도 마찬가지로 그릇 개수가 달라지고, 신발이 하나로 합쳐지는 것을 확인할 수 있습니다. 이러한 이유는 모든 뷰에 대해서 동일한 우선순위 방식을 적용하기 때문입니다.
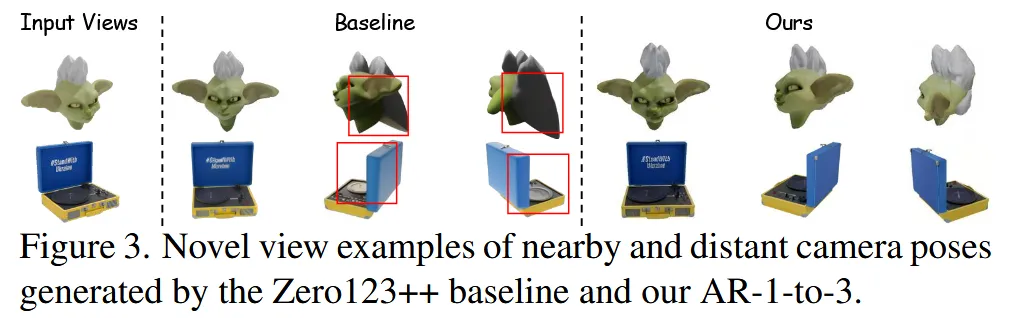
Baseline(Zeor123++)도 입력 이미지와 인접한 시점에서의 generation 성능은 좋지만, 각도가 커질수록 확실히 성능이 급속도로 감소하는 것을 확인할 수 있습니다.
Method
이전에 모든 뷰에 대해서 동일한 우선순위 방식을 사용했기 때문에 consistency가 일치하지 않는다고 언급했고, 이에 따라 논문에서는 netw-view prediction 방식을 활용한다고 했습니다.
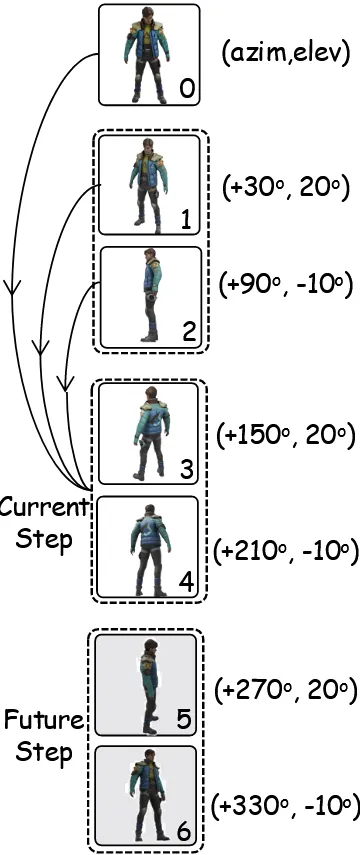
Baseline model이 6개의 이미지를 한번에 생성한다면, AR-1-to-3는 하나씩 순차적으로 이미지를 생성합니다. Zero123++에서 3x2 grid 이미지를 한번에 생성했고 비슷한 방식이지만 AR-1-to-3는 2개씩 총 3번을 순차적으로 생성하게 됩니다. 2개를 생성할 때 이미지들은 방위각 90도, 고도 30도의 차이를 갖고, 다음 단계로 넘어갈 때 방위각만 120도 차이가 생기도록 설정했습니다.
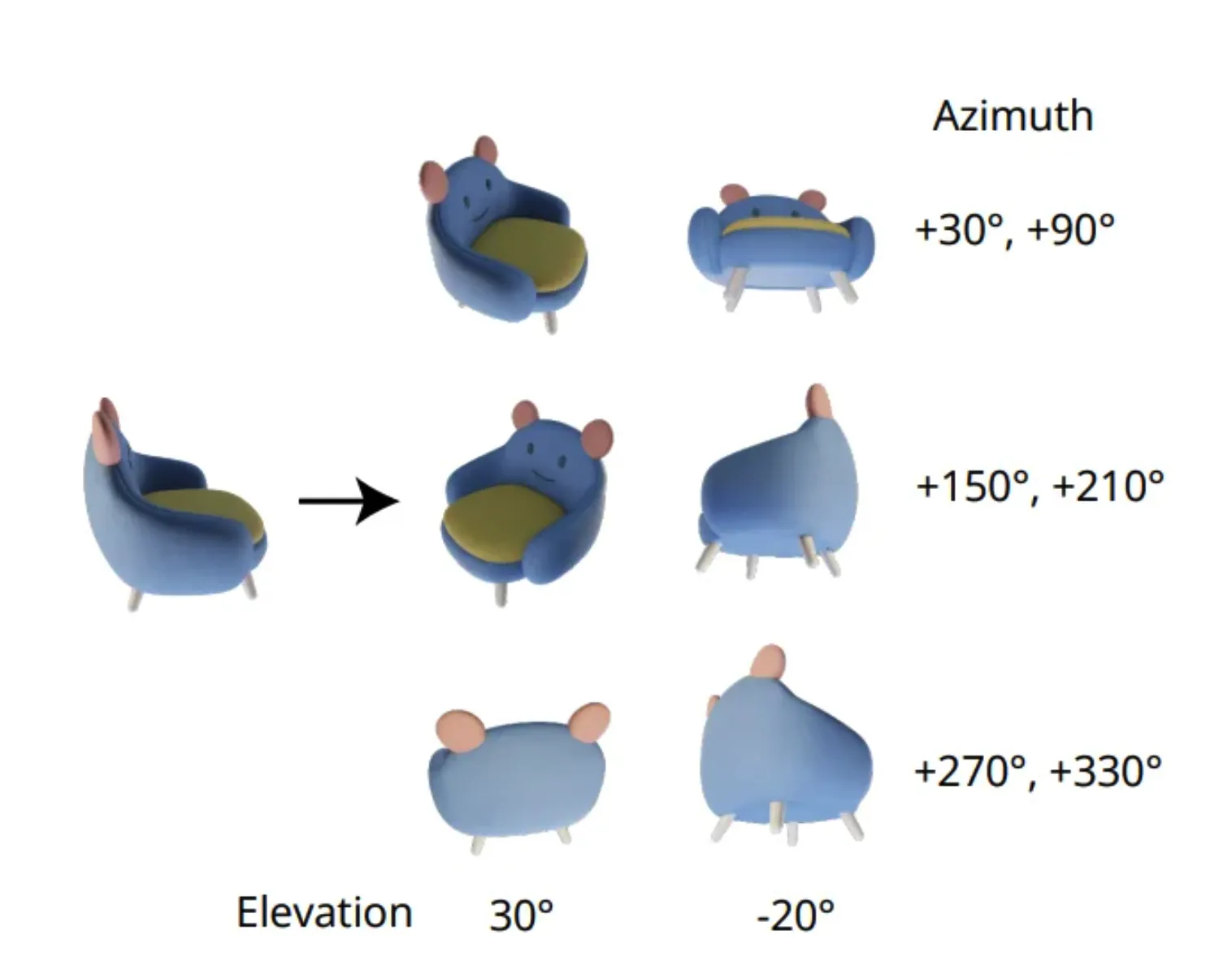
Zero123++의 카메라 방향인데 비교해보면 방위각은 그대로이지만 고도가 30,-20이 아닌 20,-10만 바뀐 것을 확인할 수 있습니다.
지금까지 Zero123++와 큰 차이가 없고 이렇게 6개의 뷰를 얻고 InstantMesh를 이용해서 3D를 생성합니다. 이제 2가지 큰 차이점인 Stacked Local Feature Encoding와 Long Short-Term Global Feature Encoding를 설명하겠습니다.
Stacked Local Feature Encoding
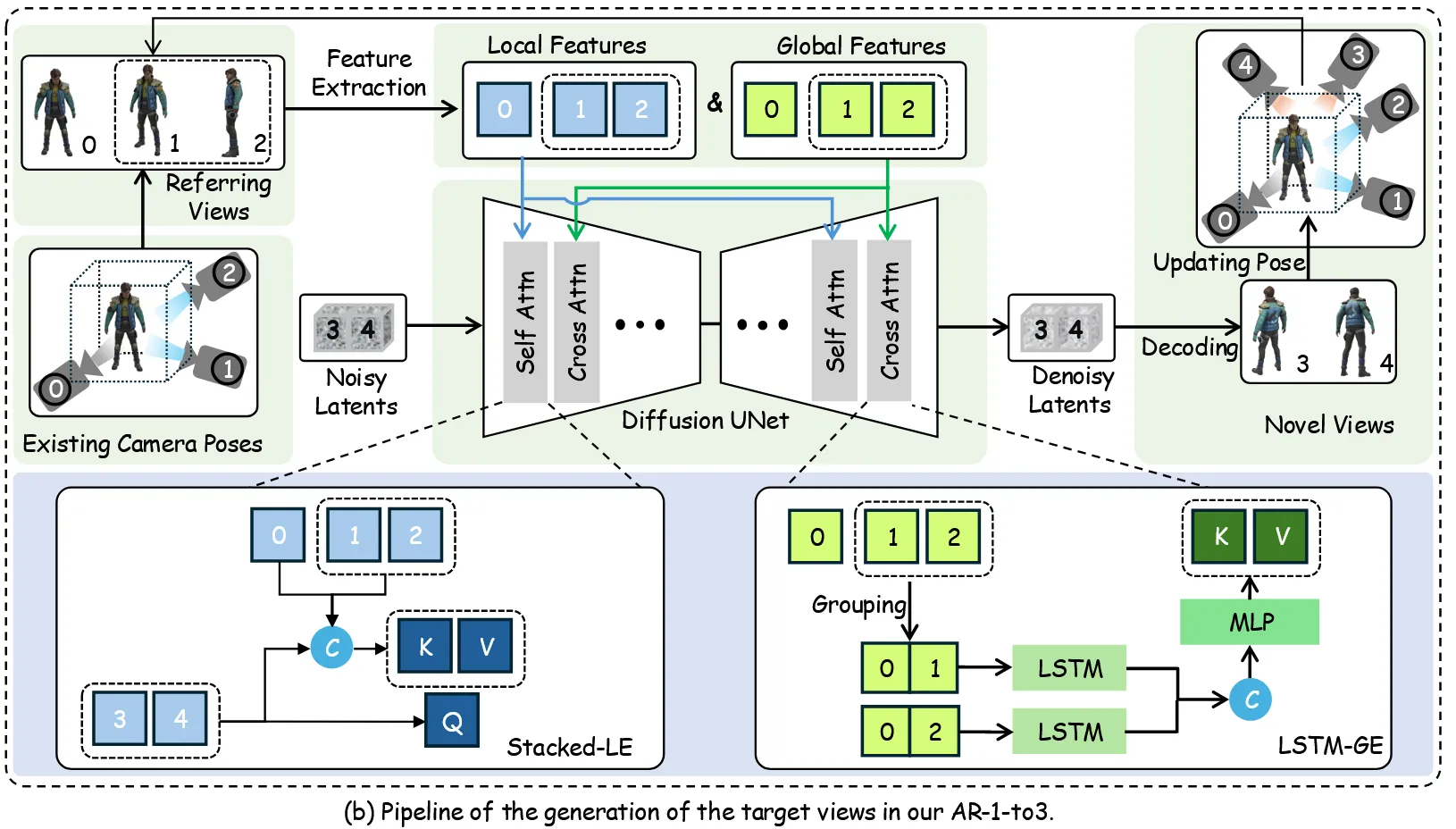
이전에 말했듯이 Autoregressive하게 다음 시점의 이미지를 생성하는데, 이때 이전 시점의 이미지를 어떻게 guidance로 사용하는지 설명하는 부분입니다. 우선 그림은 3,4번 이미지를 생성할 때의 pipeline입니다. 3,4번 이미지를 생성할 때 입력 이미지 0과 이전 시점에서 생성한 1,2번 이미지가 존재합니다. 이에 대해서 U-Net의 downsampling을 진행해서 local feature를 생성합니다(Global feature와 초록색 부분은 이후에 설명이 있으니 일단 넘어가시면 됩니다). 이렇게 생성된 local feature와 현재 시점 3,4번의 이미지 feature까지 concat한 뒤 3,4번만을 local feature로 사용하는 Query로 사용해서 Self-attention을 진행합니다.
이렇게 될경우 몇개의 local feature를 concat하든 token의 차원만 늘어나기 때문에 계속 연산을 진행할 수 있고, 기존의 self-attention weight를 그대로 가져와서 사용할 수 있습니다.
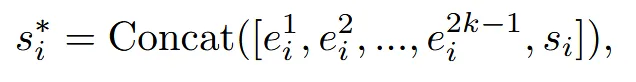
수식적으로 살펴보면 위의 수식은 이전의 reference(0,1,2)를 concat하는 과정 + 현재 시점(3,4)의 이미지를 concat하는 과정입니다. 이전시점은 2k-1개가 존재하고, 현재 시점의 feature는 로 표현합니다.
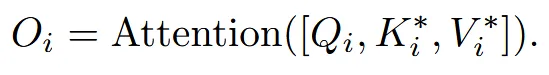
결과적으로 Attention은 3,4번의 Query와 방금 생성한 Key&Value를 통해서 진행합니다.
Long Short-Term Global Feature Encoding
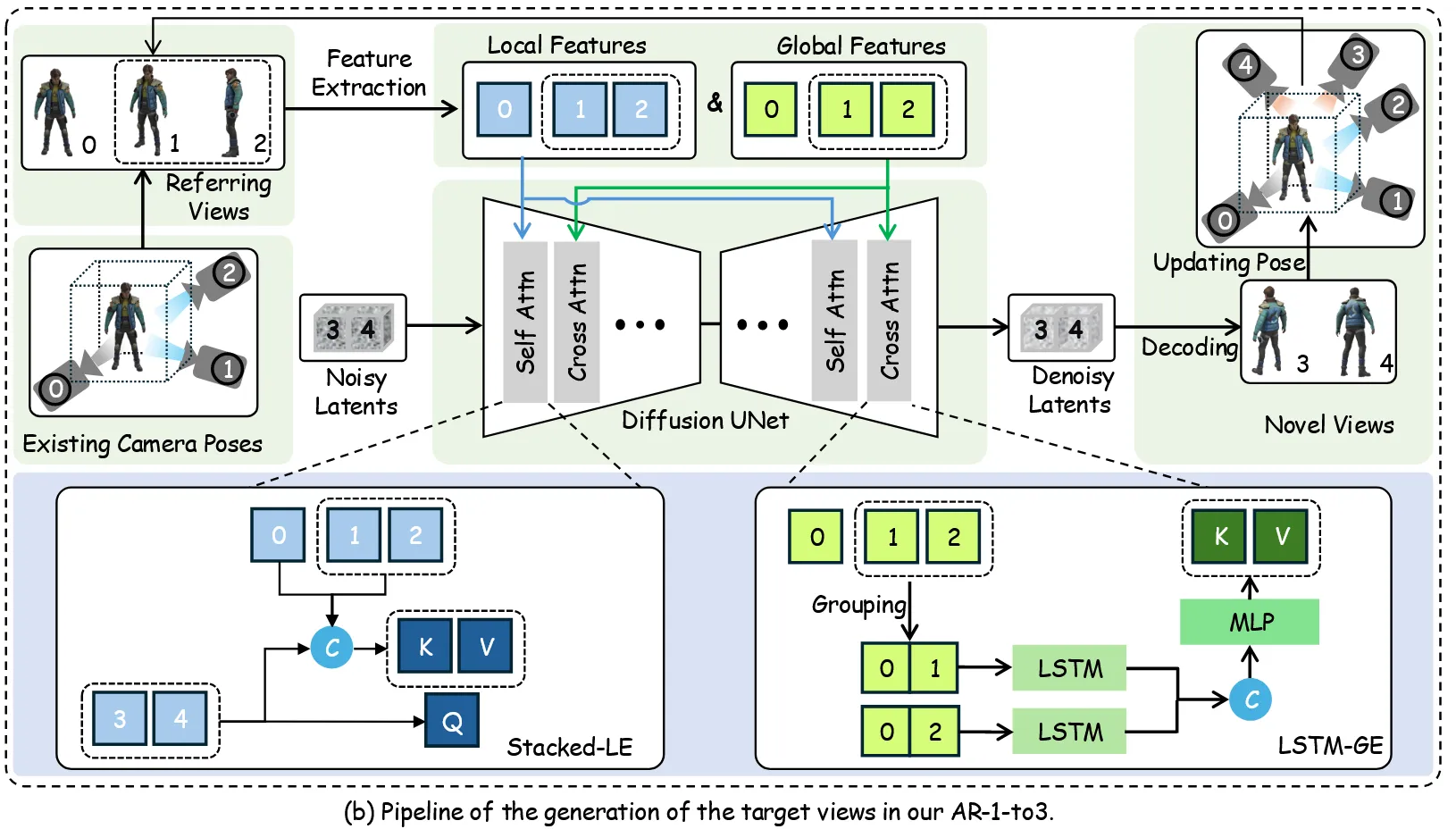
6개의 이미지에서 고도가 20,-10 2그룹이 존재했기 때문에 LSTM을 사용할 때도 2개의 그룹을 사용합니다. 각 이미지가 CLIP 이미지 인코더를 통과하면 1D vector를 얻을 수 있고, 이를 이용해서 LSTM을 사용합니다.
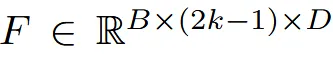
이전처럼 이전 시점의 정보는 2k-1개가 존재하므로 CLIP model을 거친 feature의 차원은 위와 같습니다. 그리고 이전에 말한 것처럼 2개의 차원으로 나누는데 입력 이미지(0)은 special case로 2경우 모두 들어가도록 설정합니다.
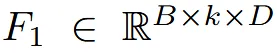
따라서 위의 차원을 갖는 2개의 feature가 생성됩니다.
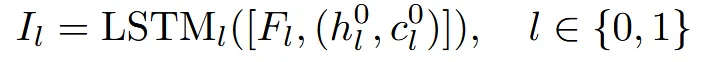
과 은 hidden state와 cell state로서 zero vector로 시작됩니다.
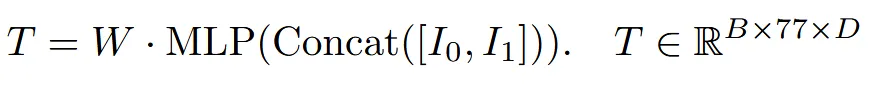
위의 LSTM으로 생성된 2개의 결과는 concat해서 MLP에 들어가게 됩니다. W는 trainable weight로 Cross Attention의 토큰 수 77개를 사용합니다.
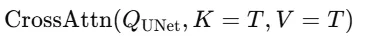
위의 T는 U-Net의 Key&Value로 UNet 내부에서 pixel-wise feature를 의미적으로 조정하는 데 사용됩니다.
cf. clip embedding의 empty text는 text가 없으므로 제거 했습니다.
Experiments
Dataset
| 데이터셋 | 용도 | 수량 및 설명 | 특이사항 |
|---|---|---|---|
| Objaverse [7] | 학습 + 평가 | 전체 약 210,000개의 3D object 사용→ 이 중 300개는 validation/test용 | 대규모 3D 메쉬 데이터셋Diffusion 모델 학습용 주요 소스 |
| Google Scanned Objects (GSO) [8] | out-of-domain 평가 | 무작위로 300개 샘플 사용 | 실제 household object의 고정밀 스캔 |
| OmniObject3D (Omni3D) [53] | out-of-domain 평가 | 무작위로 300개 샘플 사용 | 다양한 클래스의 복잡한 3D 객체 포함 |
Result

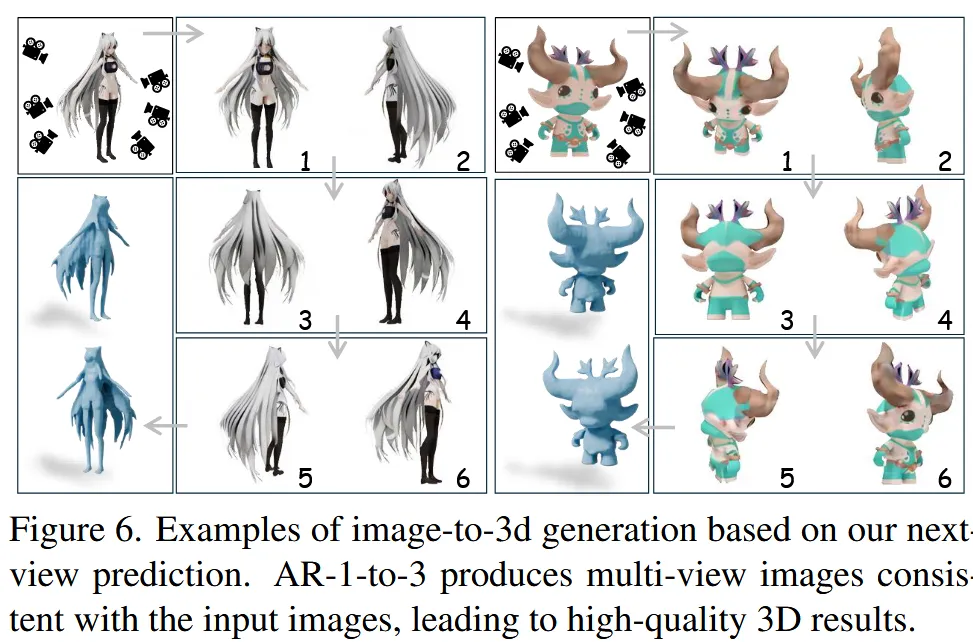
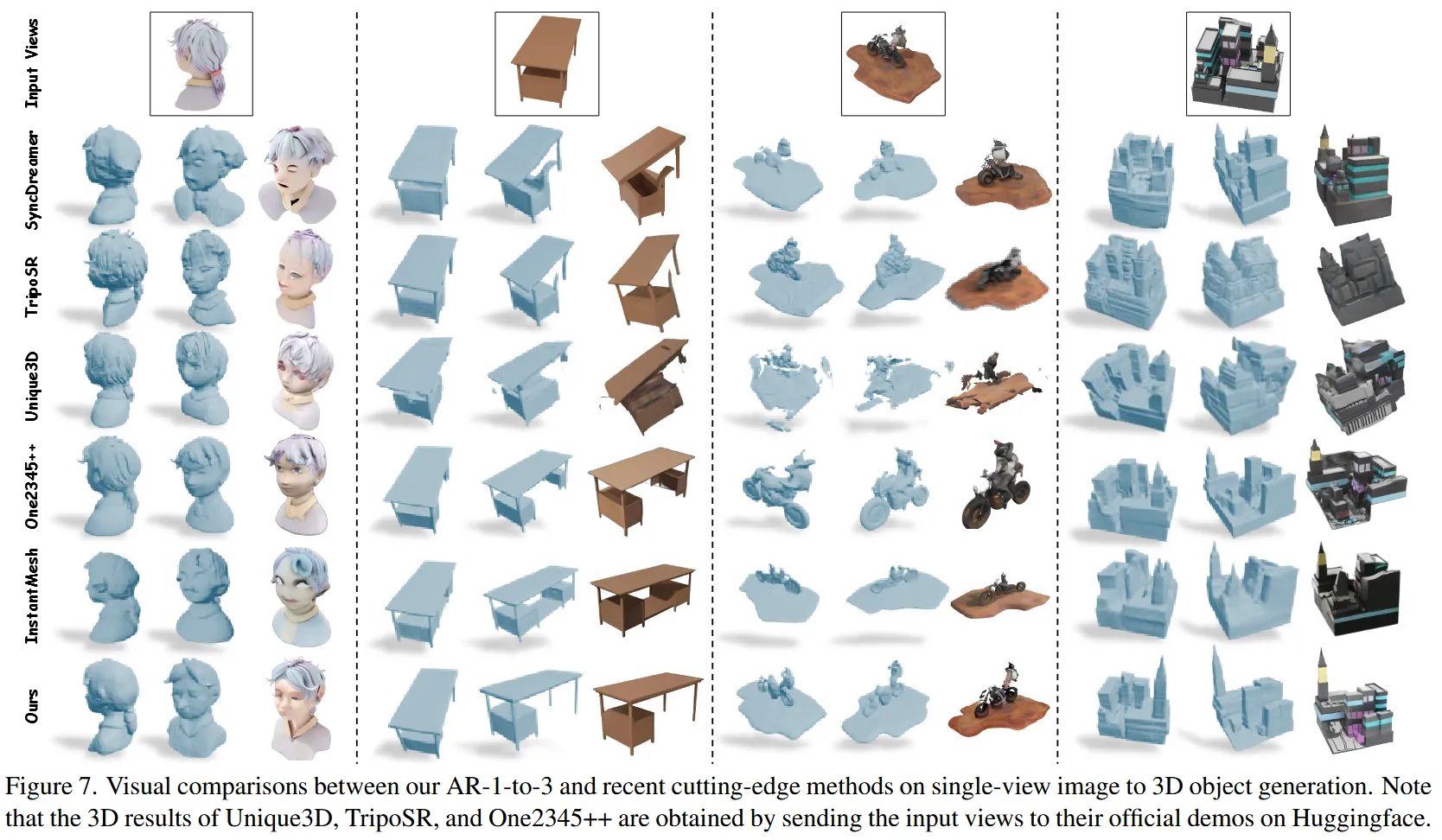
Review 정리
Weakness
- Noise strategy
- reference와 target frame에 동일한 noise timestep을 사용했다는데 이에 대한 근거를 제시하지 않음
- Efficient Parallel Training Across Target and References frames.
- Block-wise causal attention 구조를 사용하면 reference view에 대해서도 loss를 계산할 수 있는데 안함.
- 설득력 부족
- Zero123++에 비해서 성능이 좋다는 객관적인 비교 실험이 존재하지 않는다. 또한 공정한 실험도 존재하지 않는다.
- Arbitray pose
- 무작위 시점에 대한 생성 불가가 단점
