PHIDIAS: A GENERATIVE MODEL FOR CREATING 3D CONTENT FROM TEXT, IMAGE, AND 3D CONDITIONS WITH REFERENCE-AUGMENTED DIFFUSION [2025 ICLR]
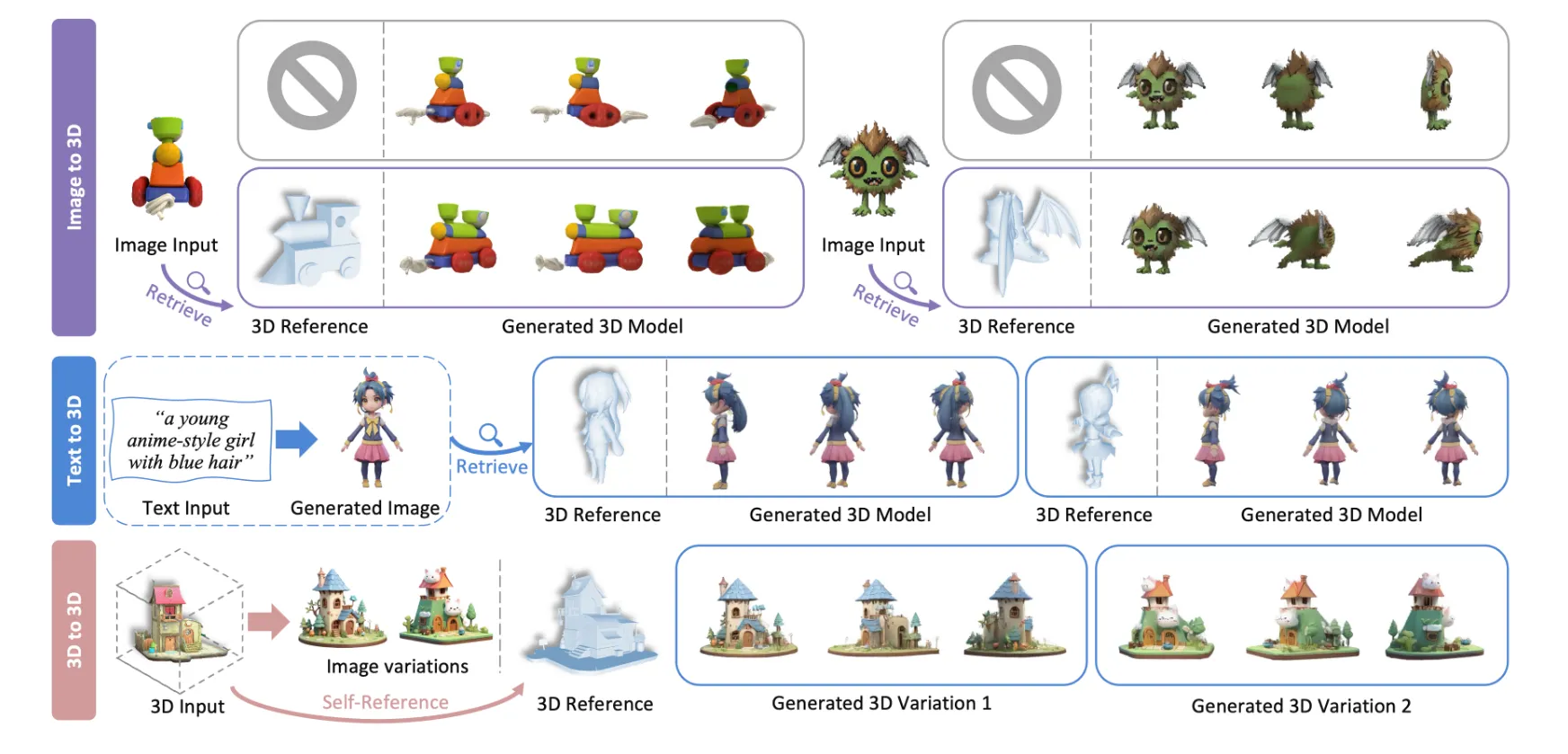
우리가 원하는 형태의 3D를 얻고싶을 때 Reference Shape을 기반으로 생성해서 더 좋은 퀄리티를 얻는 방식입니다. 위의 그림처럼 크게 Image, Text, 3D To 3D가 가능한거 같습니다.
Method

모델은 크게 2개의 Stage로 진행됩니다. 첫번째로 reference augmented multi-view generation이고 두번째로 sparse-view 3D reconstruction입니다. 그러면 각 단계에서 어떤 방식이 사용되는지 자세히 확인해보도록 하겠습니다.
Zero123++?
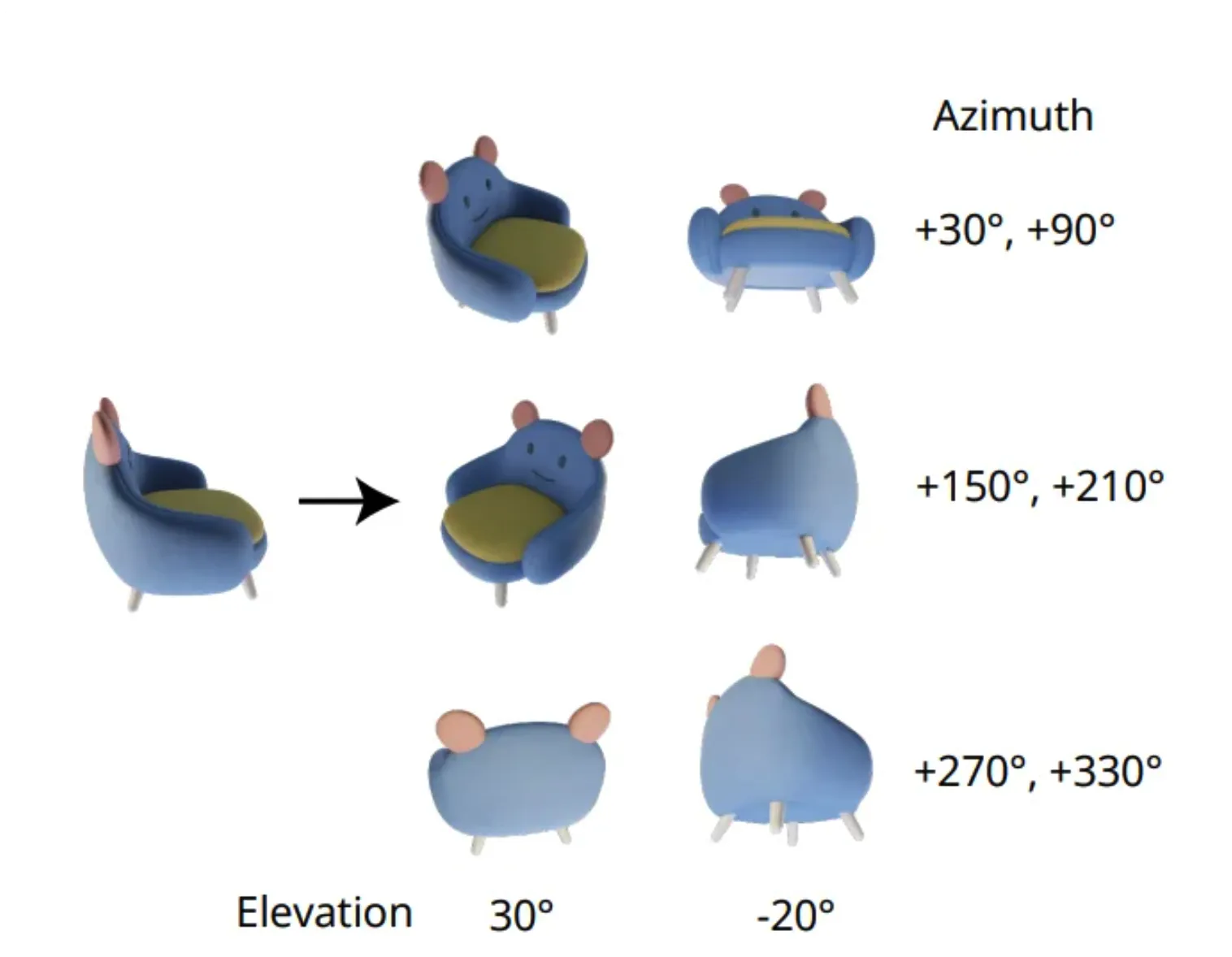
앞으로 계속 나올 baseline model이기 때문에 가볍게 설명하고 넘어가도록 하겠습니다. 위의 사진처럼 하나의 이미지를 넣고, 해당 시점에서 6개의 변환된 시점에 대한 카메라 정보를 넣으면 6개 시점의 이미지가 생성됩니다. 즉 입력 이미지는 1개, 출력 이미지는 정해진 6개의 시점에서의 이미지입니다.
REFERENCE-AUGMENTED MULTI-VIEW DIFFUSION

Zero123++ 모델에서는 condition으로 camera 정보만 들어갔지만, 해당 논문에서는 3D reference 정보를 추가했습니다. 3D reference를 diffusion의 condition으로 사용하기 위해서 CCM(canonical coordinate maps)형태로 수정했습니다.
CCM(canonical coordinate maps)란?
3D 물체를 여러 시점에서 2D로 투영 하되, 3D 공간의 좌표값 자체를 색깔처럼 이미지에 저장한 것입니다. 그래서 위의 사진을 보면 시점에 따라서 물체의 형태가 RGB 값으로 표현된 것을 확인할 수 있습니다.
왜 CCM으로 변환을 한거야?
CCM으로 형태를 변환한 이유는 첫번째로 특정 시점에서 단순 mesh나 voxels 정보가 반영되는 것보다는 더 효율적이기 때문입니다. 두번째로 3D reference에서 geometry 정보만 가져와야지 texture가 달라서 생기는 충돌을 방지할 수 있습니다.

CCM으로만 guidance를 추가한 경우 3D reference가 input image와 정확하게 align 되지 않거나, local적으로 형태가 다를 수 있습니다. 이를 위해서 아래에 3가지 개념(Meta-ControlNet, Dynamic Reference Routing, Self-Reference Augmentation)를 제시했습니다.
Meta-ControlNet
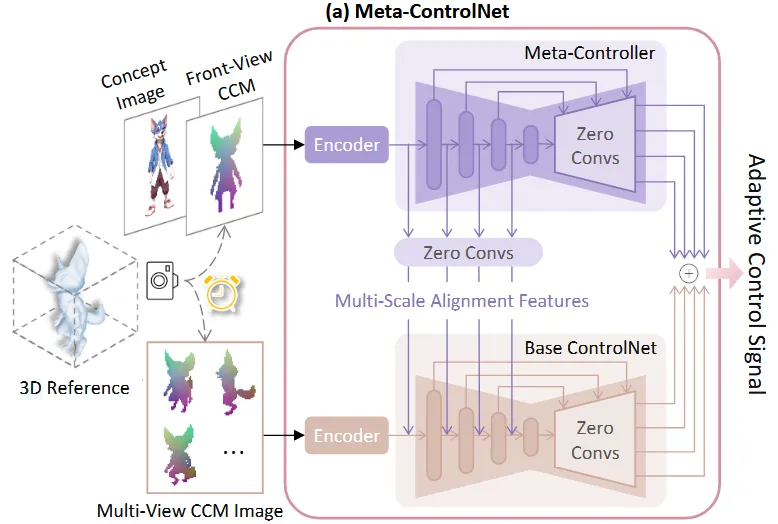
ControlNet의 경우 condition으로 들어가는 이미지(depht, edge)가 정확하게 target 이미지와 align되기 때문에 조건을 강하게 따른다는 가정이 들어갑니다. 하지만 Phidas는 3D reference가 target과 완전히 align되는게 아니라 참고용으로 하기 때문에 reference를 따르려다가 artifact가 발생합니다.
Meta-ControlNet은 위의 사진처럼 Base ControlNet과 Meta-Controller로 구성됩니다.
Base ControlNet
6개의 시점에 대한 CCM을 Encoder를 통해서 feature를 추출하고, multi-view diffusion(zero123++)의 down-sampling blocks와 middle blocks를 복사한 를 통과하고 마지막으로 연속적인 1 X 1 zero convolution layer인 를 통과합니다.
Meta-Controller
(Concep image, Front-View CCM)쌍을 Encoder로 통과시켜 feature()를 생성합니다. 이렇게 생성된 feature는 multi-scale()로 Base-ControlNet에 들어갑니다. 수식을 조금 더 자세히 설명하면 생성된 feature가 multis-scale로 들어가기 위해서 down-sampling block을 거치므로 F함수에 들어가고, 이후에 Zero convolution Z를 통과해서 Base-ControlNet에 들어갑니다.
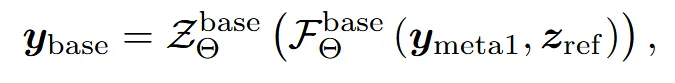
위에 설명한 multi-scale()과 가 multi-view diffusion의 입력이 되어서 Zero Convolution까지 통과하면 가 생성됩니다.

두번째로 로 거쳐서 나온 맨 오른쪽 보라색 화살표 결과는 와 더해져서 최종적인 결과 를 생성합니다.
DYNAMIC REFERENCE ROUTING
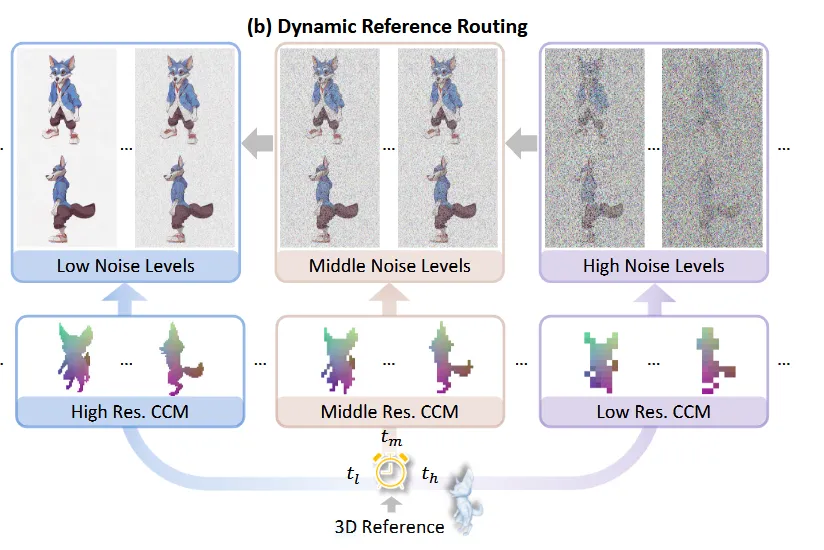
이전에도 말했지만, 3D reference는 우리가 원하는 결과와 대략적인 형태는 비슷하지만 texture와 같은 디테일한 부분은 다릅니다. 따라서 denoise timestep에서 reference의 resolution을 조절해주는 dynamic reference routing을 통해서 디테일한 부분을 참고해서 발생한 artifact를 제거하려고 합니다.
Diffusion은 초기에는 coarse한 결과가 나중에는 detail한 결과가 생성됩니다. 따라서 전체적인 구조가 결정되는 초기에는 낮은 해상도를 사용하고, 시간이 지날수록 해상도를 올려 세부 디테일을 보완했습니다. 이렇게 되면 초기에는 낮은 해상도로 디테일은 무시하고 전체적인 구조만 생성하고, 이후에 전체적인 구조는 확정된 상태에서 높은 해상도로 디테일한 부분을 학습하도록 설계한 것 입니다.
SELF-REFERENCE AUGMENTATION
3D reference와 Source image가 너무 다를 경우 model이 3D reference를 무시하게 되어 효과가 사라질 수 있습니다. 따라서 훈련 초기에는 모델이 reference를 무시하지 않도록 유도하기 위해 self-reference 방식이 도입됩니다. 이는 source image를 reference로 사용하되, aligment가 어긋난 것처럼 보이도록 augmentation을 적용하여 훈련을 안정화하는 전략입니다.
Curriculum training strategy를 통해서 초기에는 약한 strength의 augmentation을 진행하고, 이후에 점점 strength를 키워가고 후반부에는 retrieval된 reference로 훈련시킵니다.
Appendix: Detail Augmentaion
Resize + Horizontal Flip: Reference와 크기나 좌우 반전된 경우를 고려
Grid Distortion + Shift: Reference의 비대칭성을 고려
Retrieved Reference: 특정 확률로 retrieved reference를 사용
SPARSE-VIEW 3D RECONSTRUCTION
Multi-view 이미지를 이용해서 3D를 생성하는 단계입니다. LGM의 입력값이 4개인 것은 fintuning으로 6개의 입력값을 갖을 수 있도록 해서 사용했습니다.
Experiments
3D Retrieval Database: ‘Uni3d: Exploring unified 3d representation at scale’ 참고
Train Data: Subset of Objaverse(40K modelS)
Image-to-3D


Quantitive comparision을 위해서 google scanned objects(GSO)를 사용했습니다. 중복된 물체를 제거하고 랜덤하게 200개를 선택했습니다.
20개의 Novel view synthesis를 이용해서 PSNR, SSIM, LPIPS와 CLIP(GT와 비교: CLIP-P, input image와 비교: CLIP-I)지표를 통해서 비교했습니다.
Geometry 비교를 위해서 50K points를 mesh surface에서 추출한 후 Chamfer Distance(CD)와 F-Score(threshold:0.05)를 통해서 비교했습니다.
Ours의 경우 Reference를 GT를 사용해서 할 경우(GT Ref)와 그냥 일반적인 모델(Retrieved Ref) 2가지로 나눠서 진행했습니다.
Ablation Study
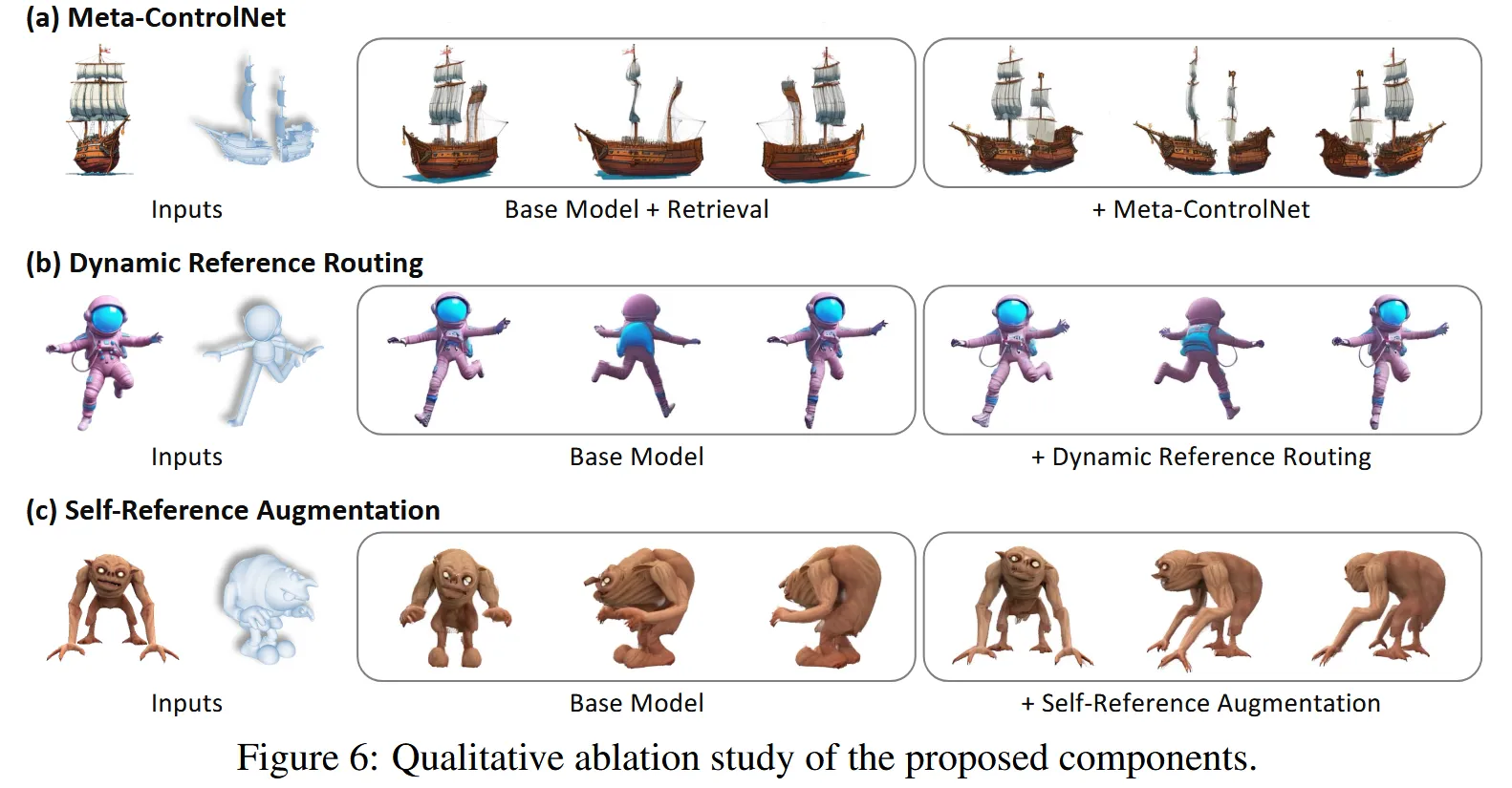
(a)그림을 통해서 단순히 retrieval을 사용 할 경우 끊겨진 배를 reference로 넣어도 이를 표현하지 못합니다. 즉 reference를 무시하는 경향이 나타납니다. Meta-ControlNet이 추가된 경우 reference의 유사도를 판단해서 condition 강도를 조절해 표현이 가능하게 됨을 확인할 수 있습니다.
(b)그림을 보고 Dynamic Reference Routing을 통해서 local 디테일이 보존되면서 reference geometry가 유지되는것을 확인할 수 있습니다.
(c)그림을 통해서 reference를 사용 안하는 문제를 self-reference로 해결할 수 있음을 확인할 수 있습니다.
Analysis

PHIDIAS는 reference 유사도에 매우 민감하며, 유사한 reference일수록 더 좋은 성능을 내고, 오히려 무관한 reference는 없는 것보다 나쁜 결과를 유도할 수 있습니다.
Appendix
A: Implementation Details
DATASET
Training set
Objaverse의 필터링된 데이터셋 사용
- low-quality 제거(Lgm과 동일한 방식 사용)
- 너무 얇은 데이터 제거
- 스캔 기반 데이터 제거
- 너무 많은 수의 vertices or faces는 제거
→ 64000개의 3D objects 데이터셋 구축
각각의 object에서 어떤 과정을 진행?
- normalize it within a unit sphere
- rendering
- 1 concep image(random)
- 6 CCM(canonical coordinate maps)
- 6 target RGBA images
| Elevation(θ) | Azimuth(φ) |
|---|---|
| 20° | φ + 30° |
| −10° | φ + 90° |
| 20° | φ + 150° |
| −10° | φ + 210° |
| 20° | φ + 270° |
| −10° | φ + 330° |
- 512x512 resolution, 30 FOV, 1.866 camera distance
Retrieval data and method
Uni3D: point cloud와 이미지를 비교해서 retrival 사용하게 한 모델(10k points)
40K의 데이터셋에 대해서 OpenClip을 거친 이미지 임베딩 값과 Uni3D 방식을 이용해서 얻은 임베딩을 비교해서 retrival을 진행
- OpenCLIP의 EVA02-E-14-plus 모델을 사용해서 입력 이미지 normalization transform
A: Training
- 회색 배경 → 하얀색 배경
- Zero123 ++에서 회색 배경을 사용했지만, Sparse-view 3D reconstrucion을 진행할 때 회색이 object로 인식 돼서 floaters가 발생
- 최종 해상도 960 X 640
- 320X320의 3x2 grid 이미지
- dynamic reference routing
| Noise level 구간 | CCM 해상도 | 업샘플링 후 크기 |
|---|---|---|
| [0.0, 0.05) | 16×16 | 320×320 |
| [0.05, 0.4) | 32×32 | 320×320 |
| [0.4, 1.0] | 64×64 | 320×320 |
- Augmentation probabilities
| Augmentation 종류 | 확률 |
|---|---|
| Random resize | 0.4 |
| Flip horizontal | 0.5 |
| Grid distortion | 0.1 |
| Shift | 0.5 |
| Retrieved reference 사용 | 0.2 |
- 기타 사항
- optimiazation: AdamW()
- batch size: 48
- NVDIA A1000(80G) 10 hours
- Sparse-view 3D reconstruction model
- LGM: 6 view → 3D Reconstruction
- 256x256 → 320x320 으로 변경하기 위한 finetuning 진행
A: META-CONTROLNET

B: LIMITAION AND FAILURE CASE
LIMITATION
- Retrival하는 databse가 40K로 작다보니 완벽한 매칭이 되지 않는다.
- Semantic similarity를 기반으로 Top-k를 선택하다보니 완벽한 매칭이 되지 않는다.

- 왼쪽에서는 입력이미지와 3D reference의 시점이 맞지 않아 주전자의 주둥이가 2개 생성됩니다.
- 고양이라는 의미는 비슷 하지만, 입력이미지는 앉아있고 reference는 서 있어서 결과가 안 좋습니다.
Future Works
- Retrieval Accuracy 향상
- 320x320을 고해상도 이미지로 생성
ADDITIONAL RESULTS

입력 시점이 어떠냐에 따라서 기존 모델들의 성능 차이가 심했는데 Phidas의 경우는 시점에 상관없이 항상 좋은 성능을 보여줬습니다.
추가 결과
3D-to-3D
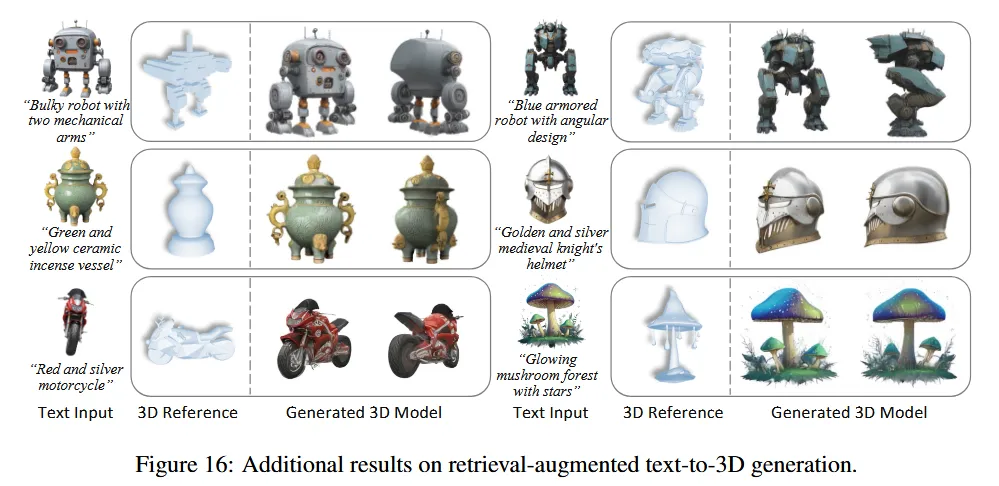
Text-to-3D

Image-to-3D
