SYNCDREAMER: GENERATING MULTIVIEWCONSISTENT IMAGES FROM A SINGLE-VIEW IMAGE [2024 ICLR]

NVS(Novel View Synthesis)와 관련된 논문입니다. 해당 논문에서는 어떤점을 개선해서 새로운 시점에서의 이미지를 잘 생성할 수 있었는지 확인해보도록 하겠습니다.
Method
MULTIVIEW DIFFUSION
Zero123처럼 Vanilla DDPM을 사용할 경우 생성된 view끼리의 consistency가 부족하다는 단점이 생깁니다.
따라서 Multiview diffusion model을 생성해서 생성하는 view끼리의 consistency를 일치시키게 합니다.
N개의 미리 정의한 이미지를 생성한다고 했을 때 time step 0에서의 값은 로 표현할 수 있습니다. 우리는 N개의 이미지에 대한 joint distribution을 구하고 싶습니다.
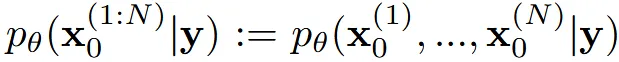
아래에서 수식을 설명할 때 앞으로 모든 생성하는 이미지 x는 y를 condition으로 받기 때문에 y를 생략하도록 하겠습니다.
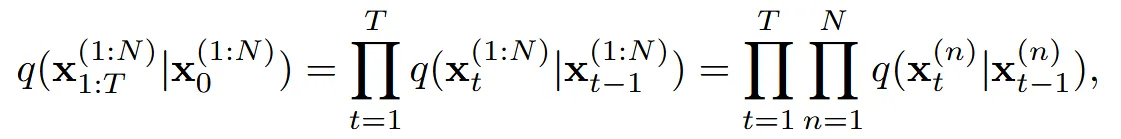
Forward Process: 수식을 오른쪽부터 확인하면 1부터 N까지의 이미지에 대해서 T시점까지 noise를 더하는 과정인 것을 확인할 수 있습니다. 가운데 수식은 1부터 N까지의 이미지를 윗첨자로 (1:N)으로 나타낸 것이고, 맨 왼쪽 수식은 time step도 아래첨자로 1:T로 단순화 해서 나타낸 것입니다.
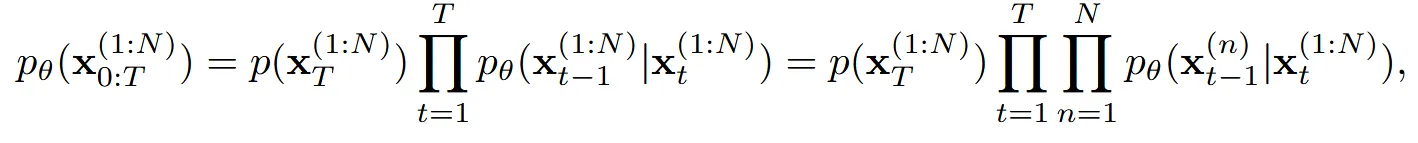
Reverse Process: 마찬가지 과정으로 진행하면 되지만 n번째 view를 생성할 때도 다른 모든 view들 의 정보를 사용합니다.
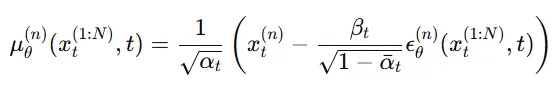
의 평균은 위와 같이 정의됩니다. 이후에 다시 한번 정의되겠지만 입력 이미지는 N개의 이미지 중에서 랜덤한 n번째 이미지, condition으로는 나머지 시점의 이미지 와 입력 이미지(y)와 n번째 이미지와 입력이미지와 camera 차이 3가지 정보가 들어가게 됩니다.
Training procedure : 1개의 object로부터 N개의 시점을 렌더링합니다. 이후 노이즈를 추가해서 을 얻습니다. 이후에 노이즈를 예측하고 샘플링된 노이즈와 L2 distance를 비교하면서 loss로 학습됩니다.
3D-AWARE FEATURE ATTENTION FOR DENOISING
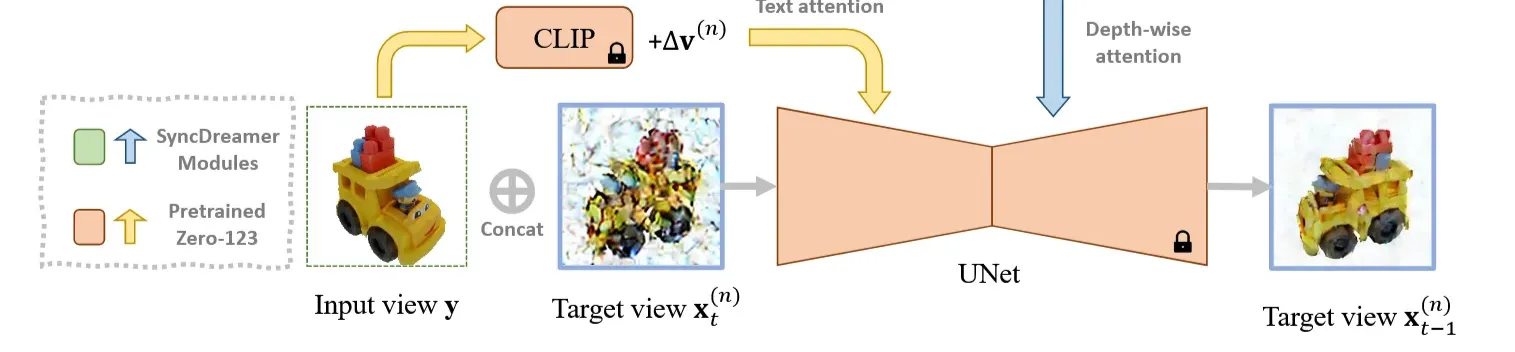
Backbone UNet
Noise를 제거하는 UNet 모델은 Zero123의 가중치를 기반으로 사용했습니다. 아래 부분을 보시면 Zero123랑 동일하게 작동합니다. 입력이미지와 noisy target view 이미지를 concat해서 UNet의 입력으로 사용합니다. Viewpoint difference()을 encode시켜서 입력 이미지(y)를 CLIP 임베딩을 통과한 결과와 concat해서 diffusion의 text attention layer에 넣습니다.
3D-aware feature attention.
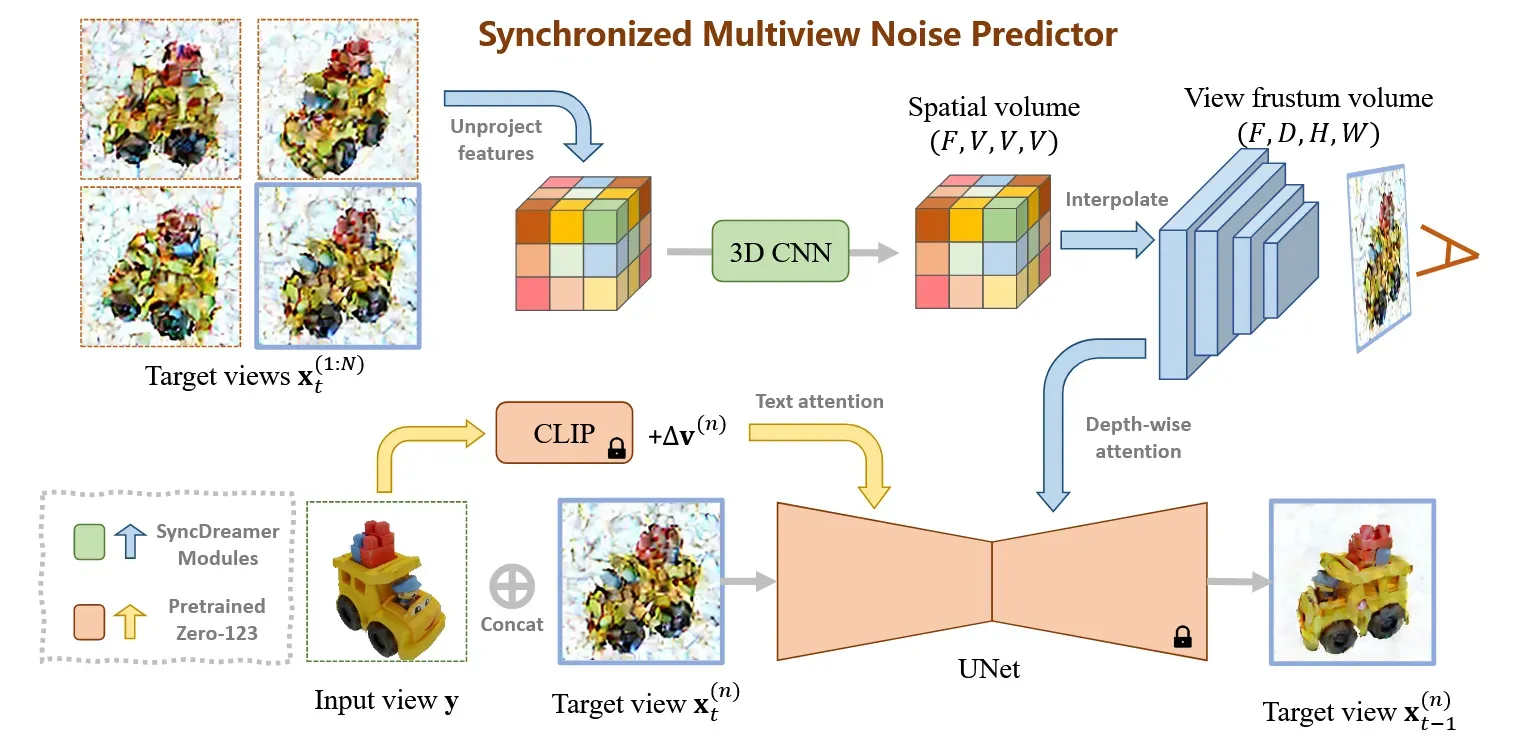
해당 과정 설명이 어려워서 최대한 쉽고 간단하게 설명해보도록 하겠습니다.
일단 의 voxel grid를 생성합니다. 이때 voxel grid는 아무값도 들어있지 않은 그냥 3차원 정육면체라고 생각하시면됩니다. 이 voxel의 하나의 점을 N개의 시점에서 봤을 때 어떤 좌표값을 갖는지 얻을 수 있습니다. 예를들어서 3차원에서 (78,13,244)라는 좌표가 시점1에서는 (120, 130) 시점2에서는 (123,322) 이런식으로 다른 좌표 값을 얻을 수 있습니다.
N개의 시점 각각에 대해서 CNN을 통해 feature를 얻고, 이 feature map에서 방금 얻은 2차원 좌표(120,130등)값에 해당하는 feature map N개를 concat해서 3차원 좌표(78,13,244)에 매핑시킵니다. 이렇게 얻은 차원의 값을 3D CNN에 넣어서 공간적인 정보를 담고 있는 Spatial volume을 생성합니다.
이렇게 생성된 spatial volume을 n번째 시점에서 view frustum을 통해서 View frustum volume을 생성합니다. 이 값은 Zero123의 UNet에 depth-wise attention으로 활용됩니다. Depth-wise attention은 epipolar attention layer와 비슷하게 우리가 원하는 공간적인 attention만을 가능하게 합니다.
Experiments

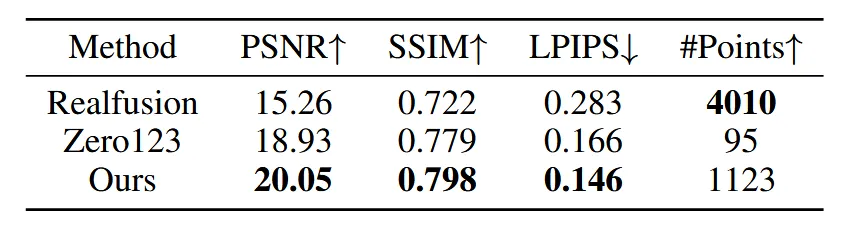
Ablation study

Ablation study에서 신기한 점은 UNet 모델을 학습할 경우 위의 그림처럼 thin plate가 나온다는 점입니다. 저자는 이러한 현상이 overfitting으로 인해 발생한다고 합니다.
Limitations
- 고정된 view의 이미지를 생성

홀수번째 줄이 SyncDreamer로 생성한 이미지, 짝수번째 줄이 이를 기반으로 NeuS로 생성한 이미지입니다. 제한된 view라는 점을 NeuS로 생성하려고 했지만 결과를 보시면 blur 해지는 것을 알 수 있습니다.
- Seed의 영향을 많이 받는다.
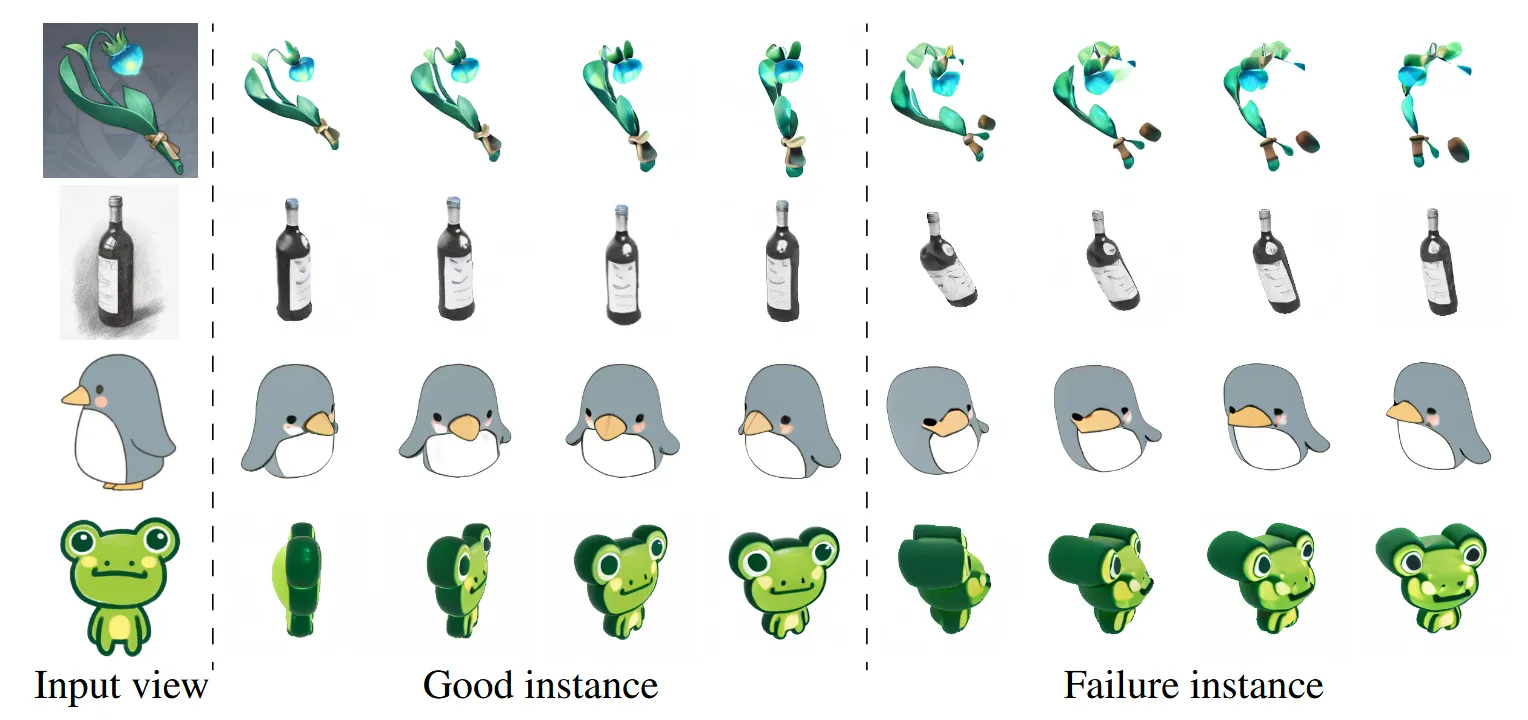
- 입력 이미지에서 object 크기가 클수록 생성 품질이 떨어진다.
학습할 때 사용한 거리보다 더 크다면, 다른 geometry로 해석해서 품질이 저하됩니다.
- Orthographic 이미지 결과가 좋지 않다.
Perspective image만을 입력으로 가정하기 때문에 성능 저하.
- Texture 디테일이 zero123보다 떨어질 수 있다.
geometry와 appearance consistency를 동시에 맞추다보니 trade-off 발생
