An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion [ICLR 2023]

해당 논문은 Text-to-image 생성 모델에 새로운 개념을 personalize해서 반영하는 방법을 제안했습니다. 이를 통해 원하는 개념을 마치 하나의 단어처럼 사용할 수 있게 했습니다.
기존의 방법은 새로운 개념을 반영하려면 모델을 다시 학습해야 했지만, textual inversion은 기존 모델을 전혀 바꾸지 않고, 새로운 embedding을 학습합니다.
Method
기존의 연구들은 contrastive방식이나 langauge learning을 통해서 이미지의 시각적 디테일은 무시하고, 이미지가 어떤 단어와 어울리는지를 배우는데 치중 했습니다. 논문에서는 이미지의 디테일까지 정확히 살리도록하는 임베딩을 학습하도록 모델을 설계 했습니다. 이는 GAN-inversion에서 사용한 방식과 비슷하지만, 그대로 적용할 경우 성능이 오히려 나빠지는 결과를 야기했기 때문에 이를 수정해서 사용했습니다.
Latent Diffusion Models(LDMs)
Textual inversion은 LDMs 모델을 사용해서 수행됩니다. LDMs는 autoencoder를 통해 이미지를 latent space으로 압축한 뒤, 더 작은 차원에서 denoising 과정을 진행해 속도와 메모리 효율을 높인 모델입니다.
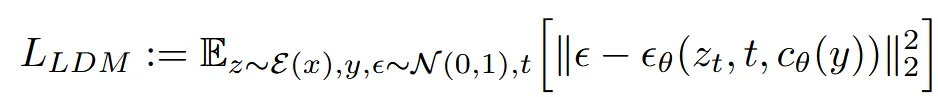
수식적으로는, 조건 y로부터 얻은 벡터 를 이용해, 특정 시점(time step t)의 노이즈 상태 를 정확히 예측하도록 학습합니다.
Text embeddings
Text는 보통 text encoder를 통해 임베딩으로 변환됩니다. 이 과정에서 문장은 먼저 단어 단위로 분리되고, 각 단어는 미리 정의된 dictionary에서 index로 변환됩니다. 각 index에 해당하는 임베딩 값은 사전에 학습돼 저장되어 있어서, 최종적으로 단어들은 연속적인 벡터(embedding)로 표현됩니다. 그리고 이렇게 얻어진 각 단어의 임베딩을 이어붙여서 최종적으로 문장의 임베딩을 만듭니다.
해당 논문에서는 이 과정을 응용하여, 사용자가 원하는 새로운 개념을 나타낼 수 있도록 S*라는 단어를 학습합니다. 즉, S*라는 단어가 입력되면 이에 대응하는 새로운 임베딩 벡터 v*를 출력하도록 최적화해, 마치 기존 단어처럼 자연스럽게 사용되도록 하는 것입니다.
Textual Inversion
에 대응되는 임베딩 벡터 를 학습하기 위해서는, 다양한 배경과 포즈를 포함하는 3~5개의 이미지가 일반적으로 필요합니다. 이렇게 여러 이미지를 사용하는 이유는 개념의 본질만 잘 학습하도록 하기 위해서입니다.
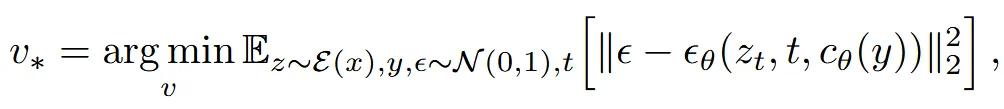
학습의 목표는, 이전에 설명한 LDM loss를 최소화하는 를 찾는 것입니다. 수식적으로는, condition(y)을 “A photo of ”로 주고, 이에 대응하는 임베딩 벡터 를 최적화하는 방식입니다. 기존 LDM에서 학습하는 네트워크 파라미터(𝜃와 )는 고정시키고, 오직 와 만 학습하도록 설계한 것이 특징입니다.
Experiments



