MeshUp: Multi-Target Mesh Deformation via Blended Score Distillation[3D Vision 2025]
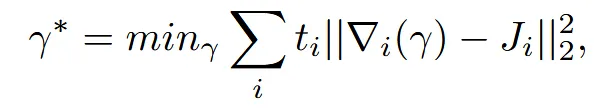

Source mesh에 대해서 입력 prompt에 맞게 deformation을 진행하는 과정입니다. 3D 초기 논문들에서 text-to-3d나 image-to-3d 대부분의 논문들이 SDS 방식을 사용하는데 해당 논문에서는 이와 비슷한 BSD 방식을 사용한다고 했습니다. 어떻게 mesh가 우리가 원하는 형태로 바꿀 수 있게 되는지 확인해보도록 하겠습니다.
Method
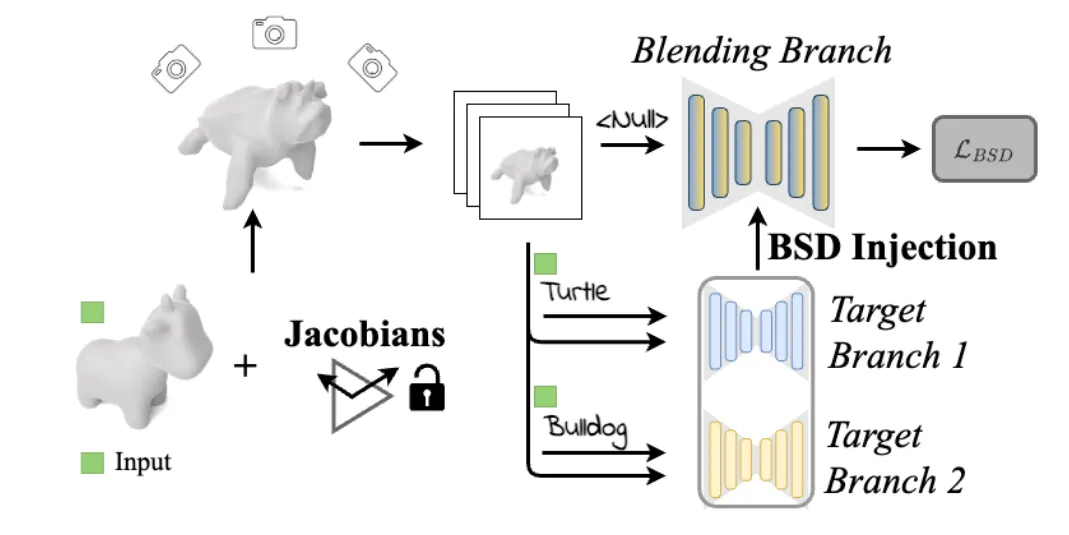
큰틀은 이전에 설명했던 것처럼 입력 mesh에 대해서 concept(어떻게 mesh를 바꿀지에 대한 여러가지 정보 + 그 정보에 대한 가중치)에 맞게 수정하는 것입니다.
핵심 개념은 2개입니다. 첫번째로 objective function입니다. Score Distillation Sampling(SDS)를 사용해서 diffusion을 이용해서 각 concept의 정보를 반영하는 것 입니다. 이렇게 될 경우 sharp artifact가 발생할 수 있는데, 이를 방지하기 위해서 두번째 개념인 Jacobian-based deformation 방식을 사용해서 smooth, continuous and global deformation이 가능하게 했습니다.
Jacobian-Based Mesh Deformation
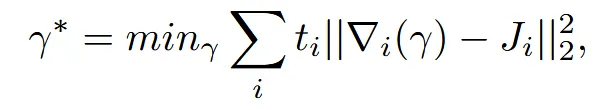
텍스트 또는 이미지로 정의된 N개의 콘셉트와 각 콘셉트의 가중치 w를 입력으로 받아, 먼저 메쉬의 각 삼각형(face)마다 학습 가능한 3×3 Jacobian 행렬 를 단위행렬 또는 작은 노이즈로 초기화합니다. 이후 이 들을 Poisson solver를 통해 전역 변형 지도γ로 풀어내고, γ를 적용한 메쉬를 임의의 시점에서 렌더링하여 2D 이미지 z를 생성합니다. 생성된 z에 확산 모델의 timestep t에 맞춰 가우시안 노이즈ϵ을 더해 를 만들고, 이를 조건 임베딩 y와 함께 U-Net에 입력하여 모델이 예측한 노이즈 와 실제 노이즈 ϵ 간의 L2 오차로 Score Distillation Sampling(SDS) 손실을 계산합니다 . 이 SDS 손실의 그래디언트를 Poisson solver와 differentiable renderer를 거쳐 까지 전파한 뒤, Adam 등의 옵티마이저로 를 업데이트하며 이 과정을 수천 회 반복합니다. 마지막으로 최적화된 를 다시 Poisson solver에 적분하여 얻은 최종 변형 지도 를 원본 메쉬에 적용하면, 주어진 콘셉트들의 가중치 혼합이 반영된 매끄럽고 전역적인(deformation map) 3D 변형 결과를 얻을 수 있습니다.
SDS Guidance for a Single-Target Mesh Deformation
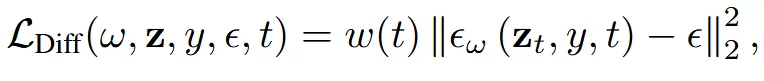
위의 문단에서 말한 것처럼 Jacobian 행렬을 학습하기 위해서 SDS를 사용합니다. 설명은 위와 완전히 동일하므로 생략하겠습니다.
위의 수식에 대해서 기호만 자세히 설명해드리면 는 weighting term, 는 렌더링된 이미지, t는 timestep, y는 condition입니다.
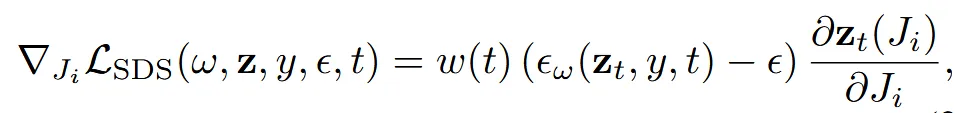
실제로 U-Net 내부까지 모두 역전파하면 계산 비용이 크기 때문에, 실제로는 노이즈 예측 단계의 gradient만 취해 효과적인 파라미터 업데이트 방향을 얻습니다. Mesh 각 face의 Jacobian에 대한 SDS loss gradient는 위의 수식과 같이 구할 수 있습니다. 위의 수식을 통해 얻은 gradient를 optimizer로 Jacobian에 적용
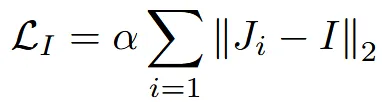
추가로 위의 수식처럼 jacobian regularization term을 추가했습니다. 는 하이퍼파라미터 값으로 강도를 조절합니다. Identity matrix와의 차이를 최소화하도록 하는 loss로서 너무 많은 변형이 가하지 않도록 제한합니다.
Multi-target Guidance via BSD.
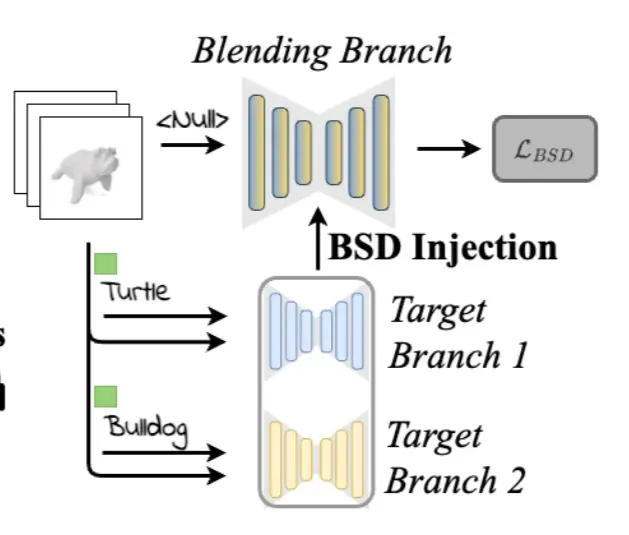
condition의 종류에 따라 diffusion을 parallel하게 진행하고, 추가적으로 null-text prompt에 대한 diffusion도 추가합니다. Null-tex prompt diffusion의 경우는 condition의 weight 총합이 1이 안될 경우, 총합이 1이 되도록 나머지 비율을 채워주는 역할을 합니다.
각각의 diffusion을 Target Branch라고 표현하고, 주어진 조건 하에서 렌더링 이미지에 대한 self-attention 레이어를 통과하며 말미에 activation matrix 를 생성합니다. 즉 렌더링된 이미지와 condition을 Unet의 입력에 넣고, Unet의 중간 feature map입니다.
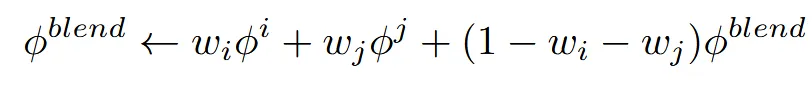
최종적으로 activation matrix가 여러개 생성될 것인데, 이거에 대해서 각 가중치에 대한 비율로 blend한 최종 값을 생성합니다.
Localized Control
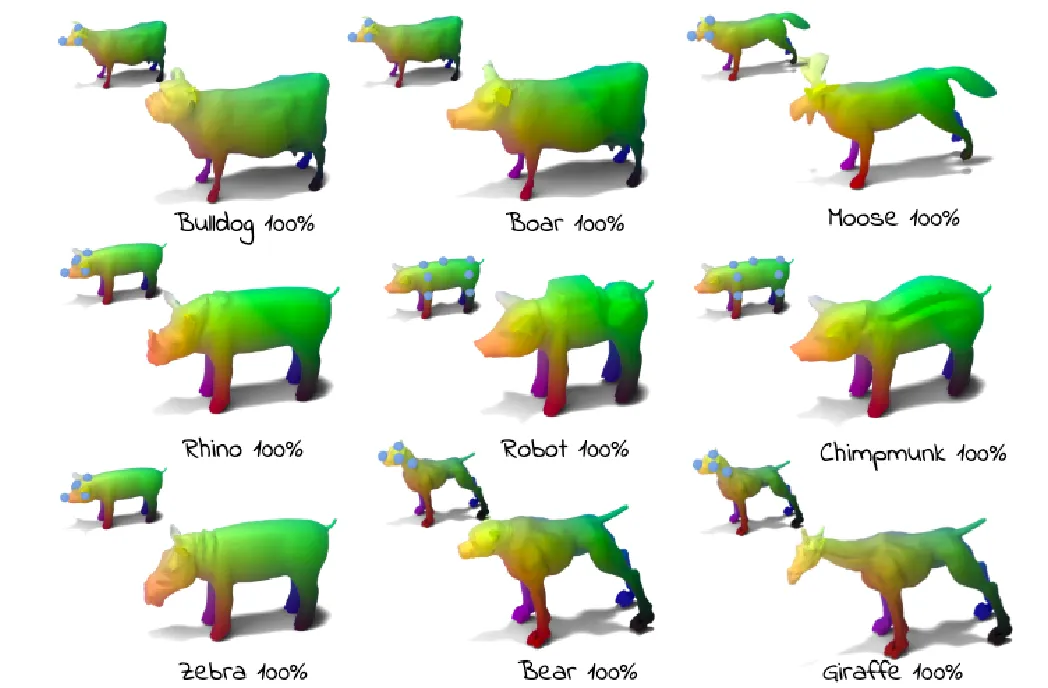
사용자가 수정하고 싶은 부분의 VERTEX를 MESH 위에서 고른 후, 그 점을 기반으로 3D deformation을 진행하는 과정입니다. 위의 그림처럼 사용자가 바꾸고 싶은 부분에 대해서 점을 지정하고, 이에 대해서 해당 부분이 집중적으로 변형되는 것을 알 수 있습니다. 이렇게 사용자가 지정한 점들을 control vertices라고 합니다.
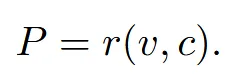
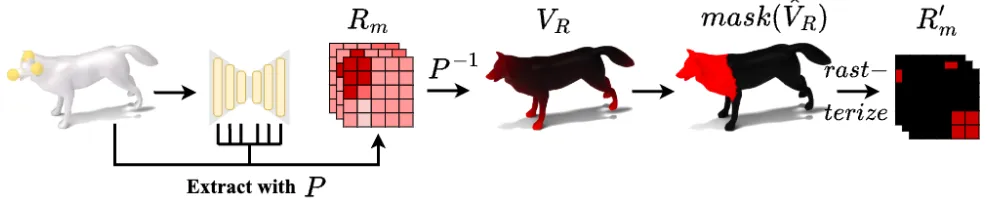
첫번재로 3D 점이 2D 상에서 어디에 대응되는지를 찾습니다. v는 vertex, c는 camera position, r는 mapping function이고, vertex-to-pixel mapping P 값을 찾습니다.
이렇게 찾은 픽셀 값에 대응되는 임베딩 값을 찾기 위해서 BSD를 진행할 때 Unet안에서 self-attention이 진행되는 부분의 Attention matrix에서 픽셀값이 존재하는 부분의 패치를 가져옵니다. 여러개의 Attention matrix가 존재하기 때문에 여러개의 패치가 나올 것이고, 이 패치들을 평균 낸 을 생성합니다.

생성한 mask에 대응되는 vertex를 찾기 위해서 mapping function의 역함수를 이용합니다. 최종적으로 나온 은 3D상에서 ROI입니다. 여러가지 시점에서 렌더링을 진행하기 때문에 의 값은 계속 optimization 될 것입니다. VR을 정규화 한다음에 0.8 임계치를 넘는 경우에 대해서 이전처럼 똑같이 binary mask를 생성합니다.
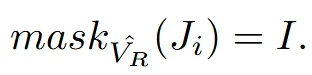
초기에는 jacobian 기반으로 deformation을 진행하고, 이후에 방금 생성한 마스크를 이용해서 마스크 영역 밖은 idenety matrix로 변형합니다.
Localized Control for Multiple Concept Blending
다 배운 내용들을 어떻게 적용할 수 있는지 구체화하는 부분입니다.
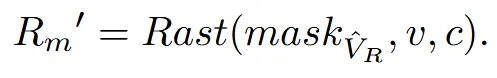
방금 구한 3D mask 을 특정 시점(c)에 렌더링 해서 2D mask 를 얻습니다. 이후에 BSD를 할 때 해당 마스크 부분의 cross-attention map을 0으로 설정합니다.
필요한 경우 LoRA(Low-Rank Adaptation) 기법으로 U-Net을 멀티뷰 렌더링 대상에 맞춰 빠르게 파인튜닝하여 더 정확한 attention을 얻도록 했습니다.
Image Targets with Textual Inversion
Textual inversion에서 사용한 방식으로 이미지를 프롬프트 임베딩으로 바꾼 뒤, BSD의 target branch 입력으로 사용하면 text가 아닌 이미지로도 3D Deformation이 가능합니다.
Experiments
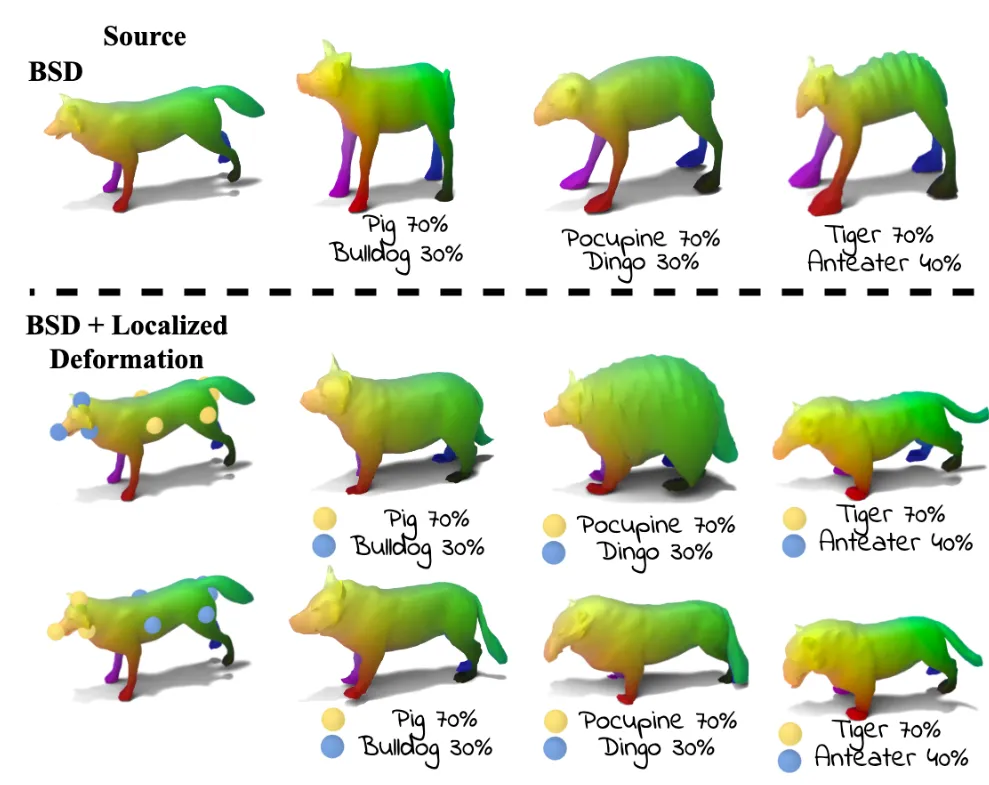
Localized Deformation 유무에 따른 결과 비교 사진입니다. 확실히 영역을 지정하지 않았을 경우 다리의 변형이 많이 나타난 것을 알 수 있습니다. 결과를 보면 놓쳤던 부분이 text prompt가 여러개 들어갈 경우 각 경우에 맞는 point가 색깔별로 다르게 지정된 것을 알 수 있습니다.
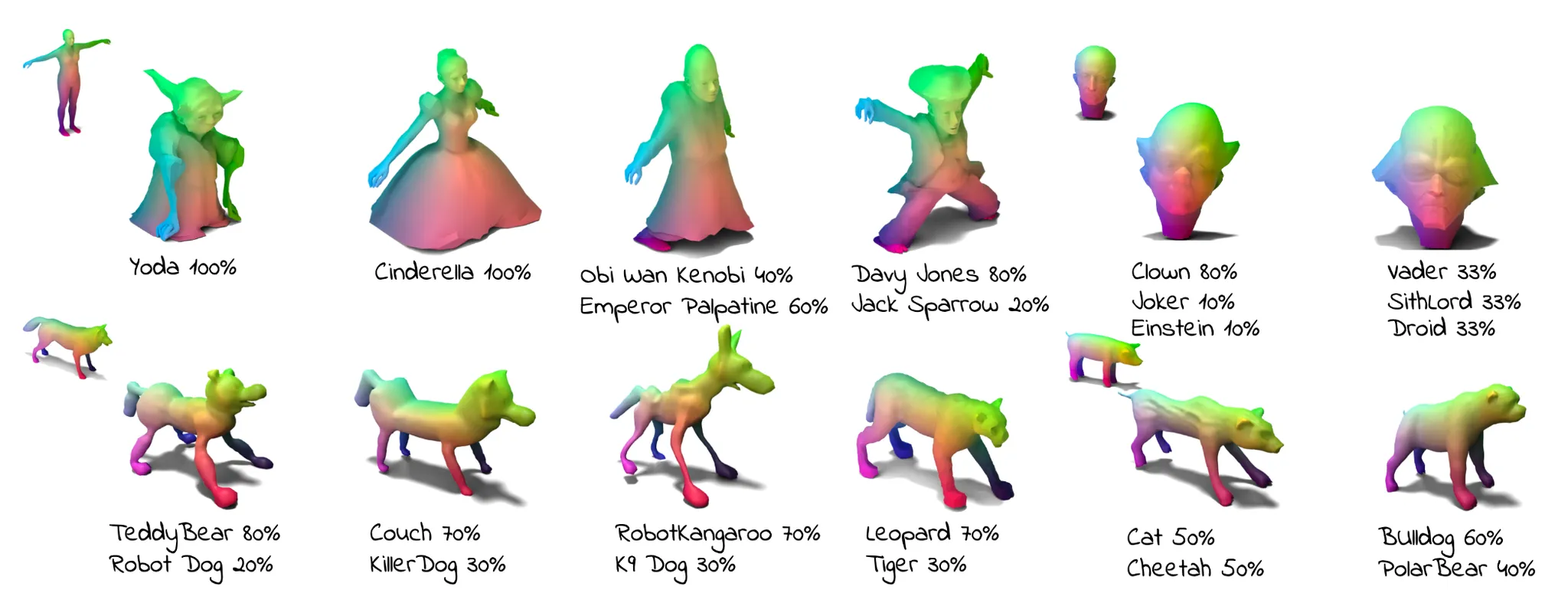

4개의 이미지에 대해서 여러가지 가중치를 넣어서 blending 할 수 있다는 것을 보여주고 있습니다.

입력으로 mesh를 넣은 경우 Dreambooth를 finetuning 시켜서 점진적 defroming을 가능하게 했습니다. 메모리 overload를 피하기 위해서 LoRA도 finetuning 시켰습니다.

이외에도 texture transfer도 가능하게 했습니다.
Limitations
초기 mesh의 topology(vertex, face, 연결구조)를 그대로 유지 → topoloy 변화(구멍 뚫기, 분리된 파트 합치기) 같은 작업을 지원하지 않습니다.
