SEELE: A Unified Acceleration Framework for Real-Time Gaussian Splatting [2025 arXiv]
project page: https://seele-project.netlify.app/
github page: https://github.com/SJTU-MVCLab/SeeLe
paper page: https://arxiv.org/abs/2503.05168
3D GS는 많은 장점에도 불구하고 hardware 리소스를 많이 사용하기 때문에 실시간으로 모바일에서 사용이 힘들었습니다. 논문에서 제시한 SEELE는 Hybrid preprocessing과 contribution-aware rasterization 방식을 활용해서 하드웨어 리소스를 크게 줄이게 됐습니다.
Method
3D Gaussian에서 3D를 2D 픽셀로 변환하는 Rasterization이 전체 시간의 67% 이상을 차지합니다. 이는 픽셀 하나당 수천 개의 Gaussian을 처리해야 하기 때문입니다.
이를 완화하기 위해, 기존 3DGS 파이프라인은 두 가지 단계의 필터링 기법을 적용합니다.
1. Pruning (오프라인)
- 투명도 기반 제거: 각 Gaussian의 투명도(α)가 사전에 정한 임계치이하이면 기여도가 미미하다고 판단해 렌더링 리스트에서 제외합니다.
- Top-K 선택: 전체 Gaussian 개수에 상한선을 두고, 미리 계산해둔 기여도 순위에 따라 상위 K개만 남겨 모델 크기와 연산량을 제한합니다.
2. 온라인 필터링 (타일/뷰 프러스텀 단위)
https://m.blog.naver.com/rhkdals1206/221654162321
렌더링 직전에, 실제 화면 또는 타일 단위로 Gaussian을 더 정밀하게 거릅니다.
- AABB (Axis-Aligned Bounding Box)
- Gaussian의 2D 투영 타원을 축에 평행한 사각형으로 감싸고, 이 AABB가 현재 타일 영역과 겹치지 않으면 해당 Gaussian을 스킵합니다.
- 장점: 계산이 단순하고 빠름.
- 단점: 회전된 타원을 완전히 감싸지 못해 불필요한 Gaussian이 남을 수 있음.
- OBB (Oriented Bounding Box)
- Gaussian의 2D 공분산 행렬 고유벡터를 이용해, 타원 모양에 맞춰 회전된 사각형을 구성합니다.
- 이 OBB와 타일 간 충돌(intersection) 검사를 통해 훨씬 타이트하게 필터링합니다.
- 장점: 더 정확히 불필요 Gaussian을 걸러냄.
- 단점: 회전 변환 연산이 추가돼 조금 더 무거움.
위의 2가지 방식을 사용했음에도 여전히 많은 하드웨어 리소스를 소모하기 때문에 해당 논문에서는 2가지 방식을 추가로 제안하며 리소스를 optimization 했습니다.
Hybrid Preprocessing

가까운 시점끼리 비슷한 Gaussian을 공유하는 성질을 이용해, Gaussian을 Share와 Exclusive로 클러스터링합니다.
View-Dependent Scene Representation

기본적인 아이디어는 간단합니다. 모든 시점에서 보이는 부분과, 특정 시점에서만 보이는 부분이 다르게 존재하다는 것입니다. 모든 시점에서 보이는 부분을 공유하고, 해당 부분의 계산을 줄이자가 핵심 아이디어입니다.
Shared Gaussian은 모든 시점에서 보이는 부분으로 위의 그림에서 왼쪽에서는 자전거 부분, 오른쪽에서는 노란색 영역이 될 것입니다. Exclusive Gaussian은 특정 시점에서만 보이는 부분으로 나머지 영역과 색깔에 해당된다고 보시면 됩니다. 오른쪽 그림에서 시점에 따라서 다른 색깔로 구분해둔 것을 알 수 있습니다.
Clustering Strategy
이 단락에서는 어떻게 Shared와 Exclusive Gaussian을 구분하는지 설명하겠습니다.
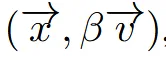
우선 비슷한 시점끼리 Clustering을 하는 과정을 설명해 드리겠습니다. Camer position(x)와 view direction(v)에 대해서 위와 같이 1D vector를 구합니다. 이때 2가지 값 모두 정규화 하는데, 2가지 정보의 차이를 구분하기 위해서 view direction에 hyperparameter(B)를 추가합니다. 이렇게 생성한 1D vector들에 대해서 거리 기반으로 N개의 clustering을 생성합니다.
각 cluster에 대해서 의 accumulative transmittance의 중요도를 이용해서 Top-K개를 선택합니다. 해당 값은 누적 투과율(앞서 더해진 gaussian들이 남긴 빛의 양) X 투명도(i번째 gaussian이 얼마나 불투명하게 보여줄지)를 곱해서 나온 것입니다. 논문에서 k 값은 32로 정했을 때 퀄리티 손실 없이 최적화 할 수 있다고 밝혔습니다.
위에서 구한 k개의 gaussian이 shared gaussian이고, 나머지 gaussian들이 exclusive gaussian이 됩니다.
Algorithm

위에서 구한 1D vector로 현재 시점에서 가장 가까운 cluster인 nearest cluster를 구합니다. 이후 neighboring cluster M개를 구합니다. 논문에서 M은 3으로 설정했습니다. 이렇게 되면 최종적으로 1 + M개의 cluster가 선택됩니다.
그림을 보면 위에서 초록색 점들이 nearest cluster, 노란색 부분이 neighboring cluster, 회색 부분이 shared cluster입니다. 3개의 점들만 사용되고 나머지 점들은 모두 제거되는게 2번째 그림입니다. Shared cluster는 항상 gpu에 올라가 있기 때문에, 1 + M 개의 클러스터에 해당하는 부분만 추가로 gpu 메모리에 올립니다.
이렇게 올라간 gaussian들에 대해서 AABB(Online filtering)방식을 적용해 필요 없는 gaussian들을 제거해 최종적으로 빨간색 X표친 것들을 제외한 guassian들만 사용하게 됩니다.
Scene Prefetching
렌더링 중간에 cluster를 로드하면 프레임이 중간에 멈출 수 있는데, 이를 대비해서 사전에 다음에 필요한 cluster를 미리 결정해서 로드해두면 프레임이 멈추는 현상을 막을 수 있습니다.
다음에 오는 scene을 예측할 때는 linearly extrapolating 방식을 사용했습니다. 이에 따라 최종적으로 GPU에 올라 있는 gaussian 총량이 최대 32.7% 줄어듭니다.
Contribution-Aware Rasterization

Algorithm
Motiviation
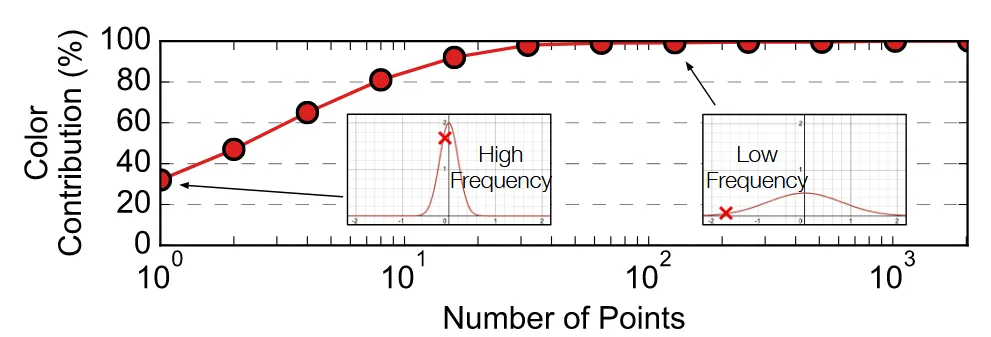
위의 그림은 하나의 픽셀에 대해서 gaussian의 누적 기여도(Γα)의 값을 내림차순으로 시각화 한 것입니다. 1.5%의 상위 gaussian 만으로도 99% 픽셀을 완성할 수 있음을 확인할 수 있습니다. 나머지 98.5%의 gaussian들은 픽셀에 미미한 영향을 미치는 것을 알 수 있습니다.
왜냐하면 alpha(투명도)가 낮을 경우 low frequency를, 높을 경우 high frequency를 결정하기 때문입니다.
Idea
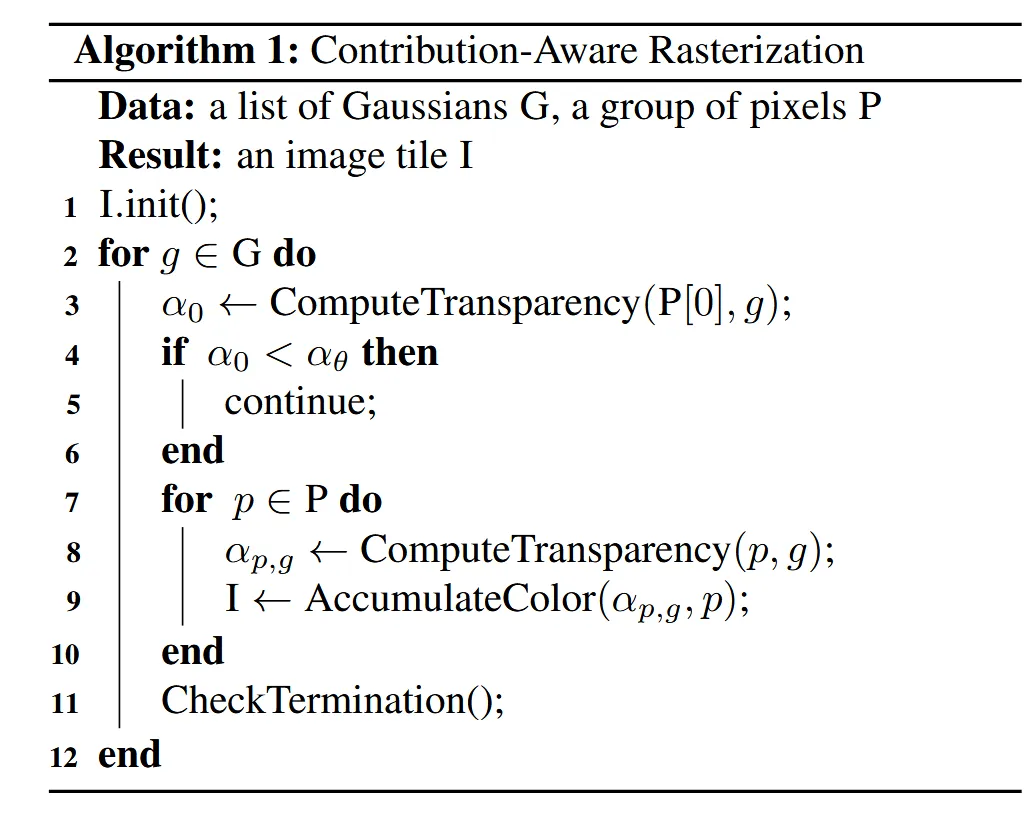
위의 알고리즘으로 어떻게 Contribution-Aware Rasterization가 작동하는지 설명해드리겠습니다.
입력값은 Gaussian이고, 한 그룹에 몇개의 픽셀을 묶을지 결정하는 P(wxw) 값 2개입니다. 출력은 최종적으로 해당 타일 위에 그려질 이미지 데이터입니다.
각각의 타일에 속하는 의 픽셀들 중에서 대표 픽셀을 정합니다. 대표 픽셀은 3x3 혹은 4x4일 경우 가운데의 픽셀을, 2x2일경우 대각선(?)을 선택한다고 합니다. 이 대표픽셀에 대해서 임계치 (1/255)값과 비교해서 작은 경우 해당 그룹의 픽셀들은 전부 계산을 생략하고, 임계치를 넘는 경우 그룹에 속하는 모든 픽셀에 대해서 투명도를 계산합니다. 이후 이전 gaussian 방식처럼 기여도를 기반으로 픽셀의 값을 계산합니다.
마지막으로 CheckTermination()에서 현재까지 블록 내 픽셀의 누적 투과율이 임계치 미만이 되면 더 이상 뒤쪽 gaussian을 처리하지 말라는 뜻입니다.
GPU Parallelism
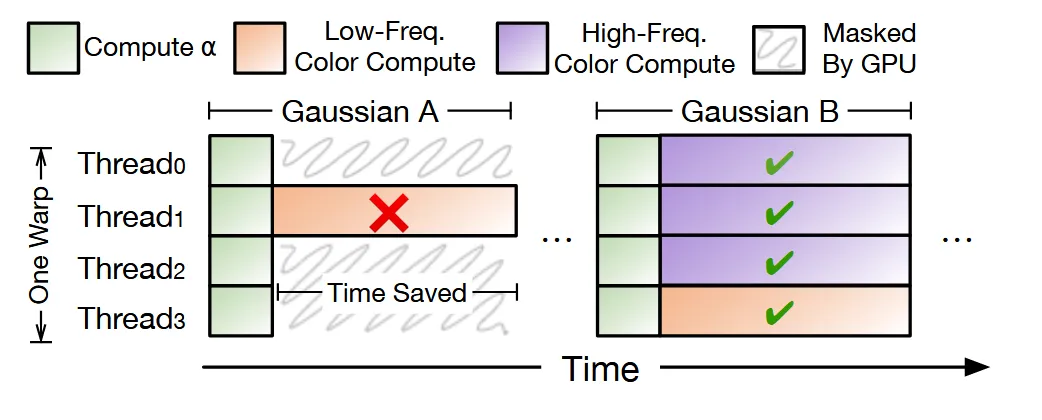
GPU는 일반적으로 32개의 Wrap(Thread)로 구성되어 있고, 하나의 gpu에 있는 32개의 Wrap는 동일한 작업만을 진행할 수 있습니다. 기존의 방식은 하나의 픽셀에 하나의 Wrap를 매칭시켜서, 32개중에 1개라도 임계치를 넘는게 있다면 나머지 임계치를 넘지 않는 Wrap들도 기다리게 됩니다.
이러한 기다림을 방지하기 위해서 1개의 gaussian 안의 Wrap들을 모두 동일한 그룹으로 속하게 시킨 후 , Thread0번을 리더 픽셀로 선택해서 임계치를 넘으면 모든 Wrap들이 이후 연산을 진행, 임계치를 넘지 않으면 모든 Wrap들이 연산을 진행하지 않는 방식으로 작동합니다.
왼쪽 그림은 하나의 Thread만 임계치를 넘어서 나머지 Thread들이 이를 기다리는 것이고, 오른쪽 그림은 모두 동일한 작업을 효율적으로 하는 것을 알 수 있습니다.
Memory Optimization
Double Buffering
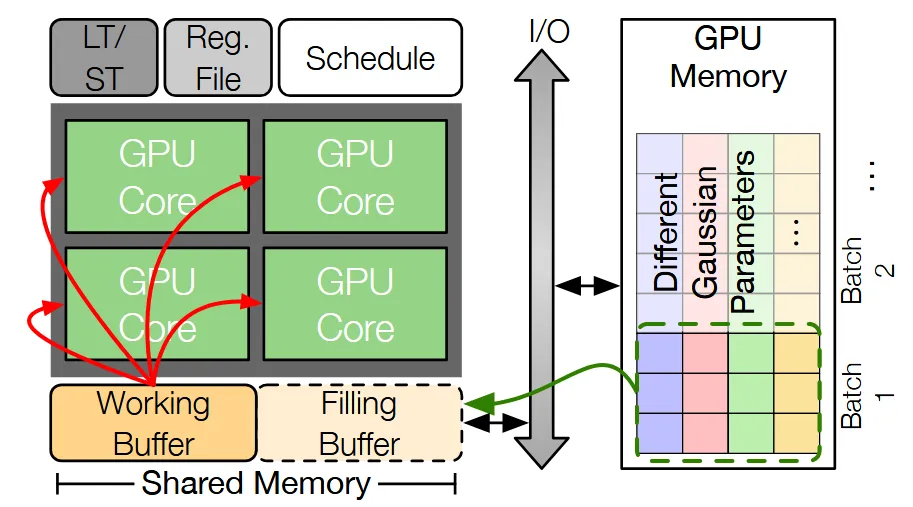
GPU Memory(오른쪽 부분)에는 많은 데이터를 저장할 수 있지만, 데이터를 읽고 쓰는데 시간이 오래걸립니다. 반대로 Shared Memory(왼쪽 부분)에는 적은 데이터를 저장할 수 있지만, 데이터를 읽고 쓰는데 시간이 적게 걸립니다.
Shared Memory를 효율적으로 사용하면 시간을 단축할 수 있기 때문에 논문에서는 효율적인 Shared Memory 사용을 위해서 Double Buffering 방식을 사용했습니다. Working Buffer 부분에서는 현재 배치에서 사용하는 데이터를 저장, Filling Buffer에서는 다음 배치에서 사용할 버퍼를 저장합니다. 이렇게 될 경우 데이터를 불러올 때 드는 시간을 단축시킬 수 있습니다.
Fine-Grained Pepelining
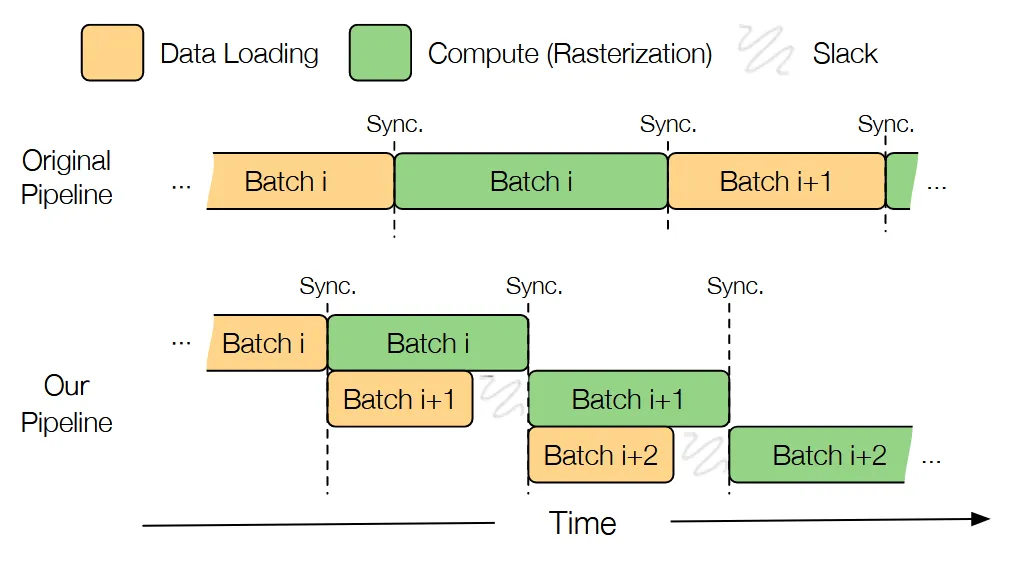
이전 Double buffering과 같은 맥락입니다. 데이터를 불러오는 시간을 단축하는 과정임을 위의 그림을 통해서 확인할 수 있습니다.
Integrated Fine-Tuning
원본 3D Gaussian의 파라미터들을 고정하고, 추가적으로 위에서 언급한 내용에 대해서만 fine-tuning을 진행합니다.
첫번째로 shared gaussian은 고정하고, exclusive gaussian만 1000 step 학습, 이후에 exclusive gaussian은 고정하고, shared gaussian만 학습합니다.
결과적으로 화질은 원본보다 오히려 조금 더 나아지거나(노이즈, 경계 부자연스러움 개선), 최소한 동일 수준으로 복원되고, 렌더링 속도는 이전에 설명한 2가지 방식의 적용으로 크게 빨라진 상태를 얻을 수 있습니다.
Experiments
Dataset Evaluation : Mip-NeRF360, Tank&Temple and DeepBlending
Quality Evaluation
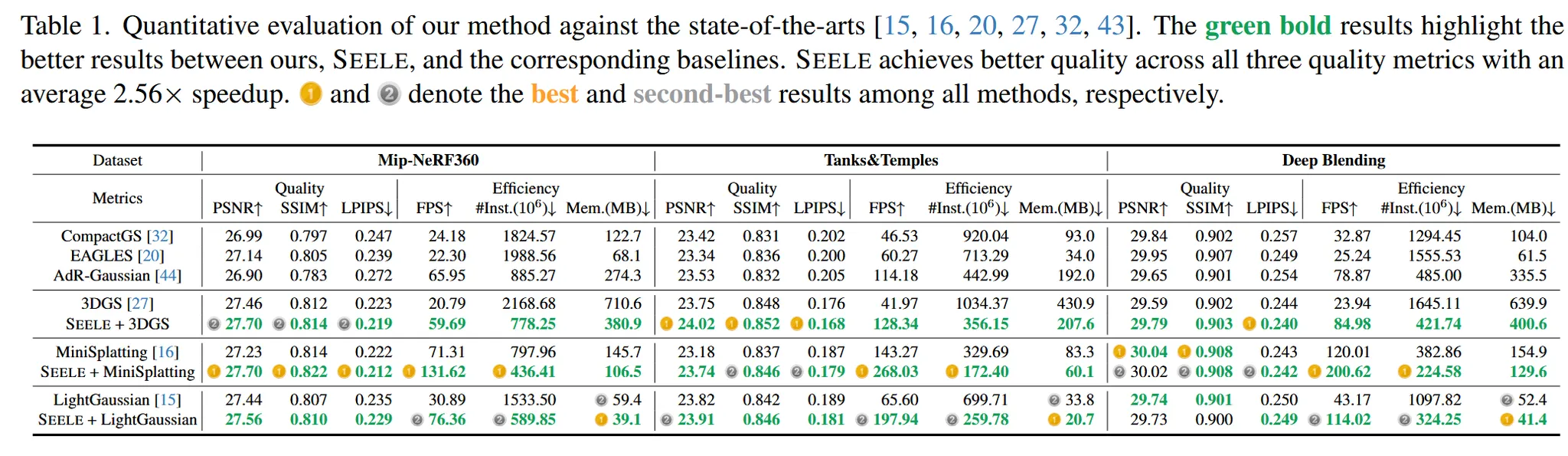
여러 3D GS를 사용하는 모델들과 위에서 말한 3가지 데이터셋의 성능을 비교한 결과입니다. 전반적으로 SEELE 모델이 PSNR과 SSIM 그리고 LPIPS 결과가 개선된 것을 확인할 수 있습니다.
다른 모델들과 시각적인 결과 비교인데, 이 역시 개선된 것을 알 수 있습니다.
speed up result
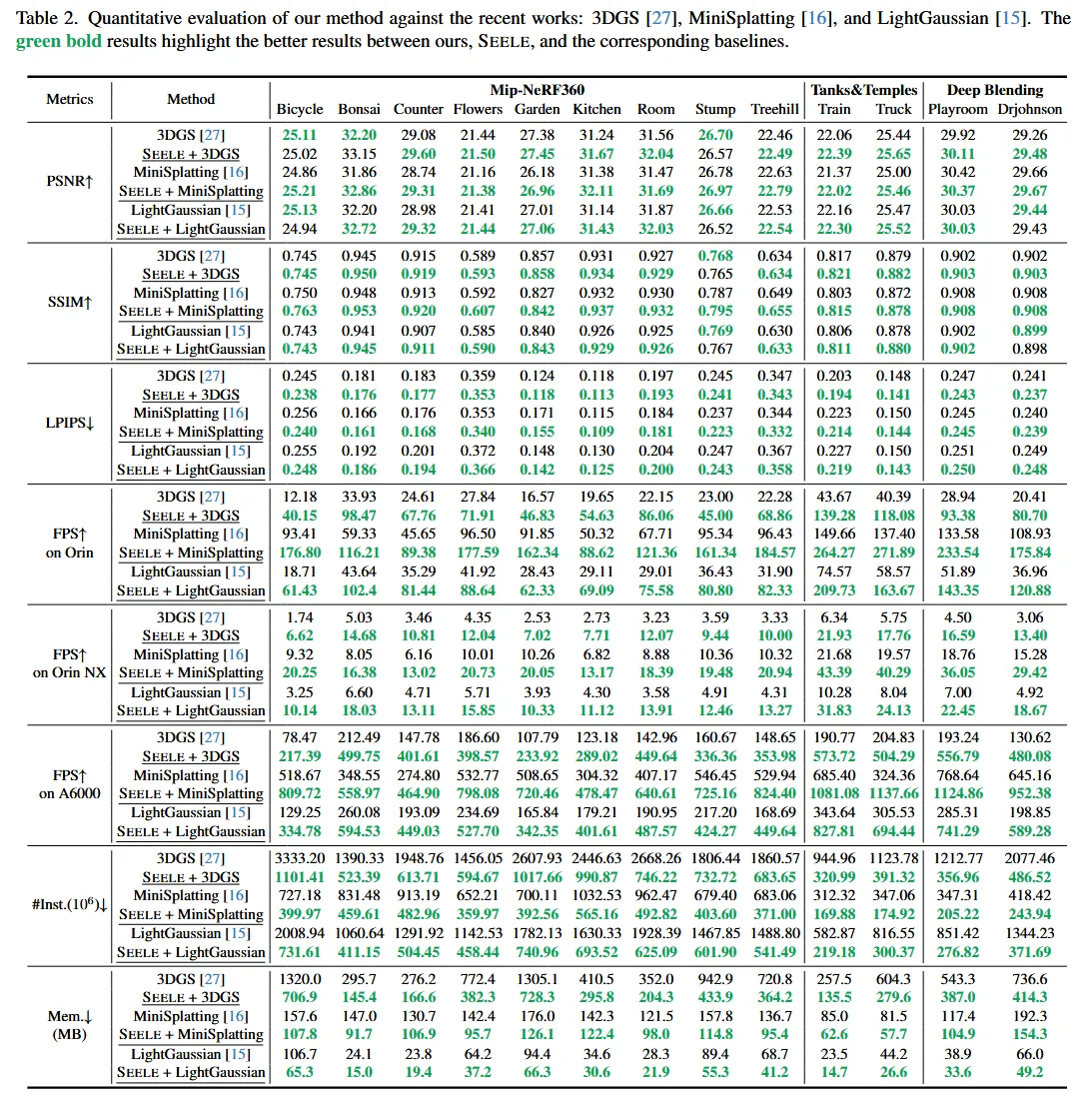
이번에는 Optimization의 효과를 확인하기 위해서 시간적으로 얼마나 개선됐는지를 확인했습니다. A6000 GPU 기준으로 전반적으로 시간이 반정도 감소한 것을 알 수 있습니다.
Ablation Study
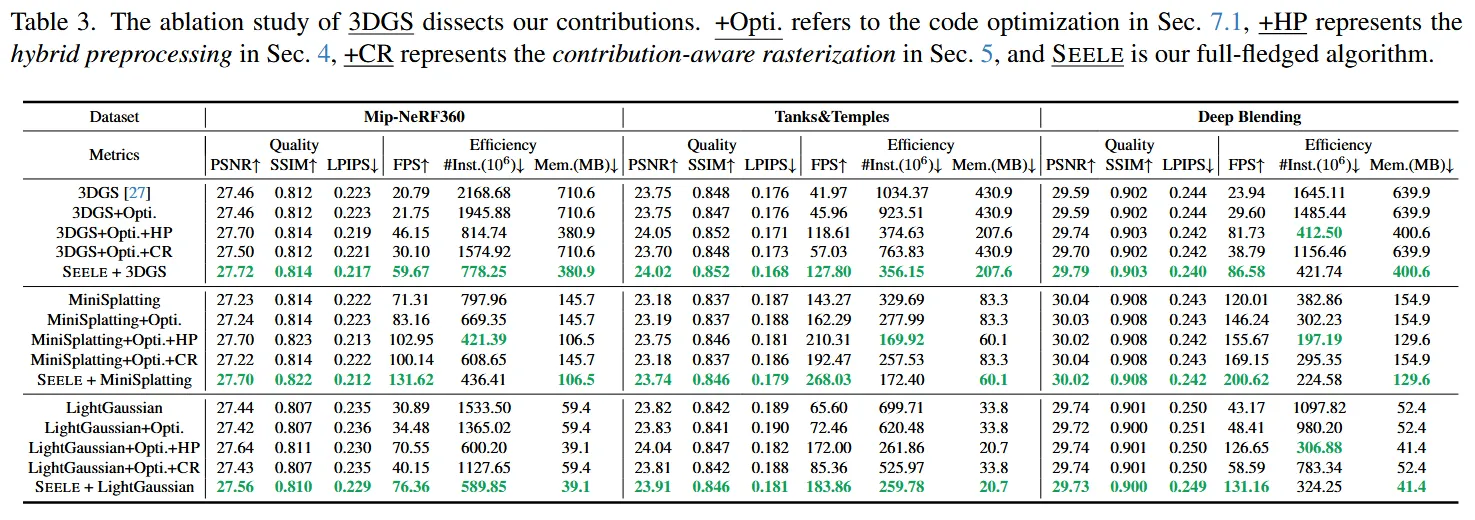
- +Opti: 순수 코드 최적화만 적용한 버전
3가지 모델에 적용한 결과 성능 개선은 없었지만, 1.1X 정도의 성능 향상을 보였습니다.
- +Opti + Hp: 코드 최적화 + Hybrid Preprocessing
평균 2.8x 정도의 전체 속도 향상을 이뤘습니다. 모델 크기와 메모리도 불필요한 gaussian을 제거했기 때문에 32.3% 감소 했습니다.
- +Opti + CR: 코드 최적화 + Contribution-Aware Rasterization
추가적인 1.3x 정도의 속도 향상을 이뤘습니다.
- SEELE: 코드 최적화 + Hybrid Preprocessing + Contribution-Aware Rasterization
최종적으로
평균 3.3x 정도의 전체 속도 향상 달성
Limitation
Scene-Specific Configuration in Hybrid Preprocessing
- 서로 다른 장면에서 동일한 cluster 개수를 사용해서 장면에 따른 품질 저하와 비효율성 존재
Aliasing in Contribution-Aware Rasterization
- wxw 크기의 윈도우를 크게하면 aliasing이 발생하고, 작게하면 효율성이 크게 개선되지 않는 trade-off
