출처[LECTURE07]
강의 영상 및 자료: https://mhsung.github.io/kaist-cs492d-fall-2024/
해당 강의를 기반으로 추가적인 설명을 정리했습니다.
Classifier Guidance 논문리뷰: https://velog.io/@guts4/Diffusion-Models-Beat-GANs-on-Image-Synthesis-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
Classifier-Free Guidance 논문리뷰: https://velog.io/@guts4/Classifier-Free-Diffusion-Guidance-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
Classifier-Free Guidance
Guidance의 역할을 한마디로 정의하자면, 생성 모델을 발전시키는 방법 중 하나로서, class label과 같은 추가적인 정보를 사용하는 방법입니다.
Classifier Guidance
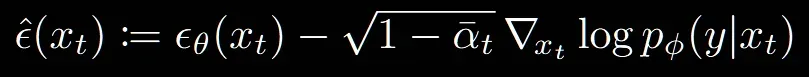
시작은 Classifier Guidance입니다. y라는 class label의 정보를 추가하기 위해서 위와 같은 식으로 변경했습니다. 식 자체는 간단합니다, 기존 노이즈 예측하는 부분에 단순히 추가적으로 오른쪽에 보이는부분을 학습하면됩니다. 그러면 오른쪽에 class label 정보는 어떻게 학습할까요?
더 간단합니다. Classifier를 이용해서 해당 부분을 학습할 수 있습니다. Classifier의 학습은 의 학습과 동일하고 Gradient값을 이용해서 이전 수식의 오른쪽 부분을 구할 수 있습니다.
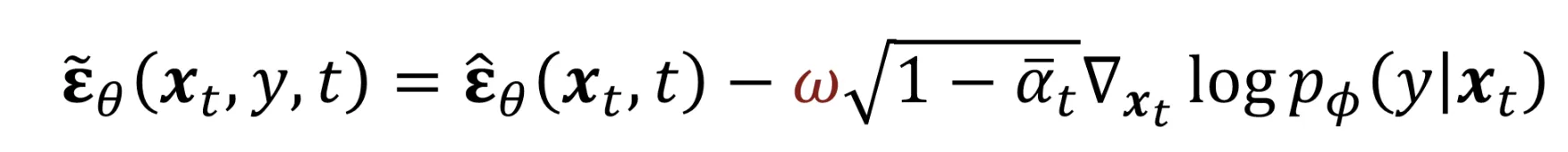
최종적으로는 위와 같은 형태로 Scale 값인 w를 곱해서 Classifier Guidance의 정도를 조절할 수 있습니다. w값이 커질수록 해당 class에 대한 더 정확한 결과, 더 좋은 결과가 나오지만 diversity가 떨어질 수 있다는 trade off가 존재합니다.
Classifier-Free Guidance
더 자세한 설명은 위의 제가 정리한 블로그 링크에 나와있겠지만, 여기서는 수업시간에 다룬 간단한 내용만 정리하면 기존에 diffusion 모델에 Classifier를 붙인 형태를 conditional 모델과 unconditional 모델을 합친 형태로 변형한 것입니다.
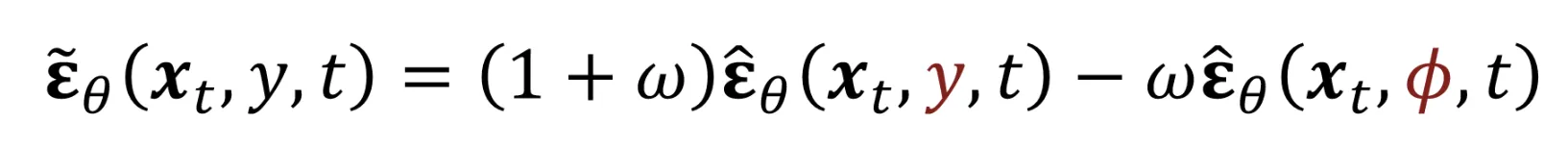
condition(y)값이 NULL값은 갖는다면 일반적인 diffusion모델이 될 것입니다. 그러면 위와 같은 수식이 이전에 설명한 Classifier Guidance와 동일한지 수식을 확인해봐야겠죠?
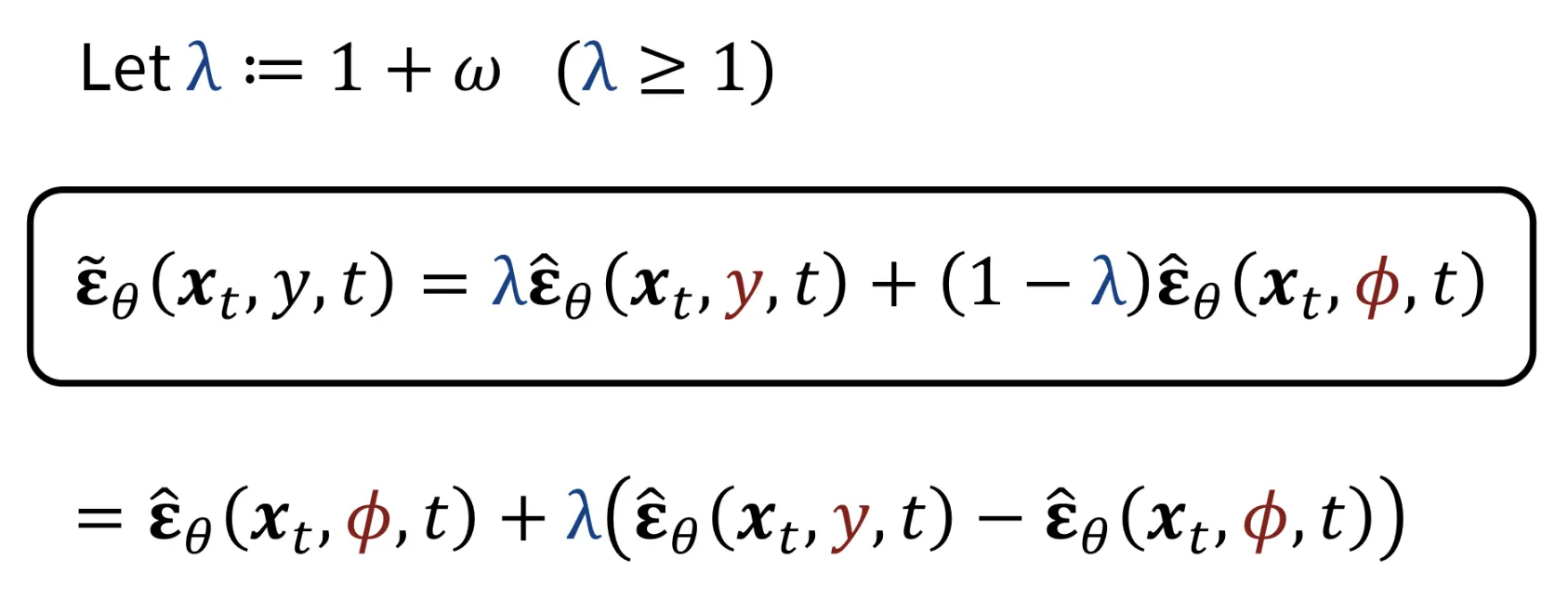
1+w의 값을 로 나타내어 extrapolation을 interpolation처럼 나타낼 수 있습니다. 이후 로 묶으면 맨 아래의 식이 나옵니다.
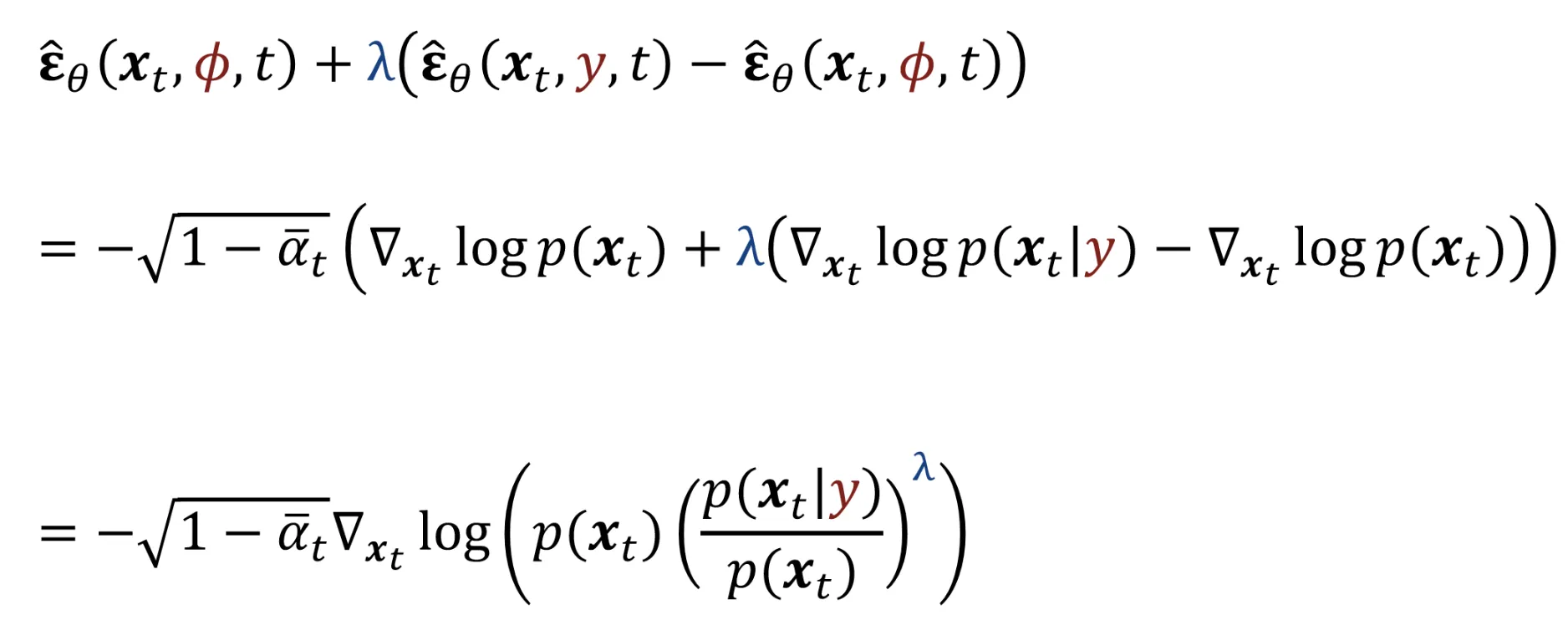
맨 아래의 식을 Gradient에 관해 나타내고, Gradient에 관해 묶으면 다시 맨 아래의 식을 얻을 수 잇는데 해당 식을 보면 베이즈 정리로 강하게 무언가를 하고 싶다는 생각이 들 것입니다.

베이즈 정리로 정리하면 Classifier의 식과 동일하게 나온다는 것을 확인할 수 있습니다. 결론적으로 Classifier 없이 conditional 정보를 학습할 수 있게 된것입니다.
Classifier-Free Guidance는 Classifier가 없어 추가학습이 없고, GAN의 단점인 Mode collapse도 발생하지 않습니다. 심지어 위의 식처럼 간단하게 추가만 하면되기 때문에 실행하기도, 어떠한 정보를 추가해도 상관이 없습니다. 단지 Condition부분과 Uncondition부분을 2번 평가해야돼서 시간이 걸린다는점이 유일한 단점으로 남았습니다.
Zero123 논문리뷰: https://velog.io/@guts4/Zero-1-to-3-Zero-shot-One-Image-to-3D-Object-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
Condition으로 카메라 파라미터를 추가하면서 Classifier-Free Guidance를 학습시킨 논문이 Zero123이고, 해당 모델은 3D를 생성하는데 사용이됩니다. 이외에도 여러가지 방법으로 Classsifier-Free Guidance는 개발 되었습니다.
Negative Prompt
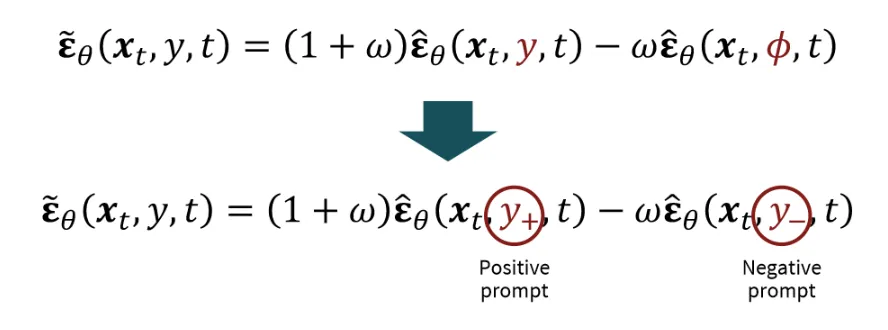
우리가 만들고 싶지 않은 형태의 text prompt를 Negative prompt에 입력하면, 해당 text prompt와 반대되는 결과가 나옵니다. 원리는 간단합니다. 이전에 Classifier Free Guidance의 Null 값을 단순히 y-로 바꿔주면 됩니다.

대표적인 예시로 위와같이 성별을 지정 해주고싶을 때 Female을 원할 경우, Male을 Negative Prompt로 지정해주면서 Female의 결과를 얻을 수 있습니다.
Latent Diffusion Model
- 어떻게 LAION-5B같은 대용량 데이터를 학습할 수 있을까?
- 어떻게 high-resolution 이미지를 만들 수 있을까?
2가지 질문에 대한 답을 해결해주기 위해서 나온 모델이 latent diffusion 모델입니다.
2가지 질문들은 어떤 문제점이 있을까요? 바로 많은 학습 시간이 필요하다는 점입니다. 그러면 어떻게 학습 시간을 줄일 수 있을까요? 해결책은 Image Compression입니다.
Image Compression
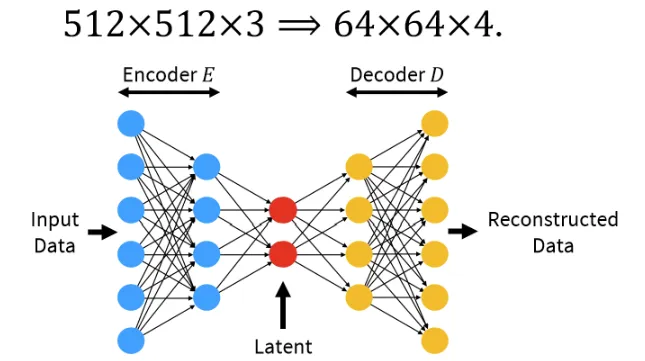
사전 학습된 Autoencoder를 사용해서 512X512X3 ⇒ 64X64X4로 변경할 수 있습니다. 채널이 3에서 4로 변경된 이유는 ..
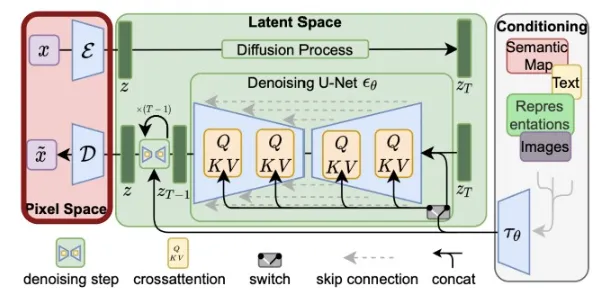
- 맨 왼쪽의 Image Compression을 진행하는 Encoder와 이를 다시 복구해주는 Decoder는 사전 학습된 모델을 사용합니다.
- 가운데 부분에서 noise predictor는 64X64X4의 latent space상에서 학습이 진행됩니다.
- 오른쪽에 Condition으로 들어가는 값은 Condition에 알맞은 Network를 통해서 임베딩 형태로 변환하고, 임베딩값을 U-NEt모델에 Cross-attention을 이용해서 학습합니다.
결론적으로 많은 데이터를, 고해상도의 이미지의 결과를 학습 시간을 적게 사용해서 얻을 수 있게 됐습니다.
Frechet Inception Distance(FID)
𝑝-Wasserstein Distance
Fréchetdistance / Earth movers’ distance라고도 불리는 𝑝-Wasserstein Distance 개념에 대해서 설명해드리겠습니다.
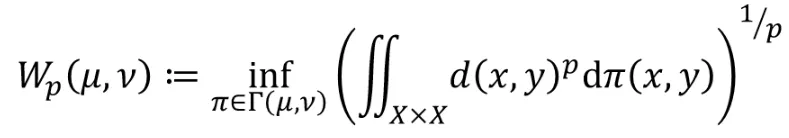
와 라는 두 데이터 분포가 있을 때 가 와 닮아질려면 얼마나 많은 비용이 들어가는지를 나타내는 개념이라고 생각하시면 도비니다. 수식은 위와 같습니다.
d(x,y)는 두 분포의 거리를 나타내며, p는 차원을 결정합니다. 이때 차원 p는 저희가 l1-norm, l2-norm할 때 사용하는 개념으로 p차승한 후 p제곱근을 취해주는 것입니다. 는 두 분포의 모든 가능한 조합입니다. 결론적으로 모든 가능한 조합 중에서 inf 즉 가장 적은 비용을 찾는 과정입니다.
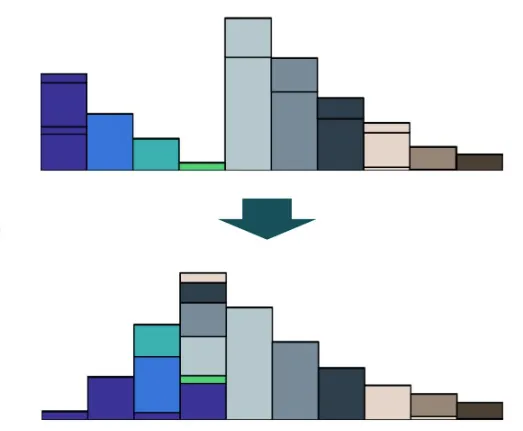
위의 초록색을 기준으로 4개의 막대가 6개의 막대로 이동한다고 했을 때, 막대들이 움직인 양과 거리에 비례해서 해당 값이 증가하게 됩니다. 즉 수식을 라고도 볼 수 있습니다.
Fréchet Inception Distance(FID)
𝑝-Wasserstein Distance개념을 이용해서 FID를 구하는 방법에 대해서 설명해드리겠습니다. 실제 데이터와 생성한 이미지를 Inception v3 network에 넣어서 latent space를 얻습니다.
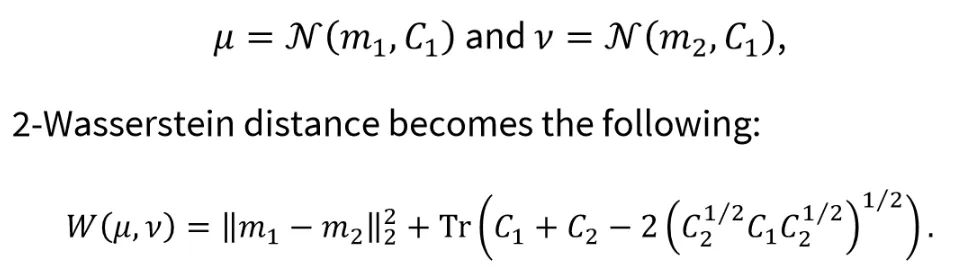
이후 위 과정처럼 정규분포로 만들면 2-Wassertein(p=2)인 경우의 수식을 쉽게 얻을 수 있으므로, 2개의 latent space를 정규분포로 가정하여 위의 수식으로 2-Wassertein 값을 얻습니다. 해당 값이 FID라고 보시면됩니다.
그러면 왜 Inception Network를 사용할까요? 어떻게 latent space를 정규분포로 가정할 수 있을까요? 이런 당연한 의문들이 들기때문에 해당 평가지표는 완벽하지 않다고 설명해주셨습니다.

위의 사진은 동일한 이미지를 단순히 JPEG를 이용해서 압축한 후 FID 결과를 확인한 것입니다. 육안으로 모든 이미지가 동일해보이지만, FID값은 20이나 차이나는 것을 알 수 있습니다. 이처럼 FID값은 모델의 평가지표로 적절하지 않다고 볼 수 있습니다.
ControlNet: Few-Shot Adaptation

지금까지 대부분의 Condition은 Text propmpt 였습니다. 하지만 Condition 값으로는 human pose나 스케치 값들도 들어갈 수 있습니다. 이러한 Condition들은 입력값과 출력값이 모두 존재하는 경우가 많이 존재할까요? 아닙니다. 그러면 어떻게 이러한 Condition 데이터들을 학습할 수 있을까요?
이 의문점을 해결한 논문이 ControlNet입니다. 많은 데이터들이 존재하지 않을 때 Fine-Tuning을 통해서 해결하는 것입니다.
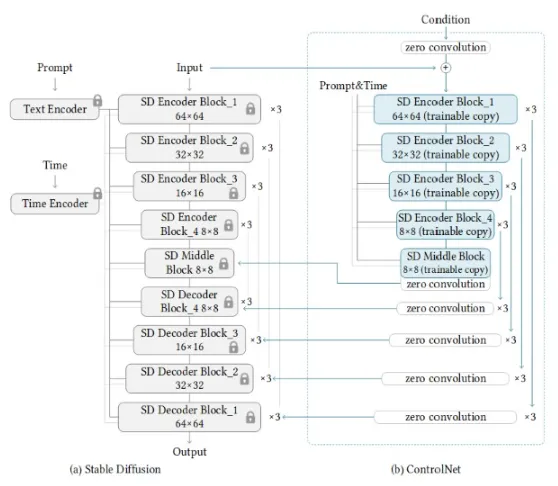
핵심 아이디어는 최대한 사전 학습된 Stable Diffusion 모델을 이용하는 점입니다.
- Stable Diffusion 모델을 Freeze(학습 X)
- Stable Diffusion의 Encoder 부분을 복사해서 Conditional image를 학습하는 부분의 Encoder로 가져옵니다. 가져온 부분은 Freeze 시키지 않고 학습 가능한 형태입니다.
- Conditional 이미지를 Encoding 한 값에 Zero Convolution을 한번 거친 후 Stable Diffusion의 Condition으로 들어갑니다.
Zero Convolution
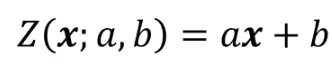
Zero Convolution은 계수가 a이고 bias가 b인 정말 단순한 layer입니다. 초기 a와 b의 값은 0으로 initilaize됩니다.
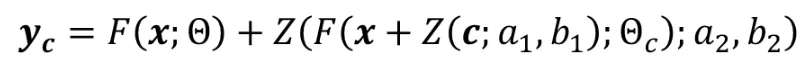
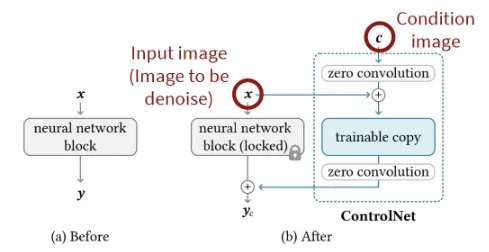
Zero Convolution이 그러면 어떤 역할을 해주는지 알아보기 위해서 모델이 작동하는 과정을 설명해드리도록 하겠습니다.
Zero Convolution의 초기 a와 b는 0이기 때문에 위의 수식에서 과 의 값은 0입니다. 그러면 수식 에서 Z안의 값은 0이되게 됩니다. Z값은 ax + b인데 a와 b가 모두 0이면 당연히 Z값이 0이겠죠. 그러면 초기 trainable copy(파란색 박스)는 x만을 이용해서 학습하게 됩니다. 이렇게 학습된 값은 다시 새로운 zero convolution을 통해서 0이라는 값이 되어 condition으로 들어가게 됩니다. 그러면 다음 iteration에서 과 이 조금씩 변하면서 conditional 이미지 정보가 trainable copy에 들어가게 되고, 인코딩된 값이 새로운 zero convolution의 와 에 의해서 Stable Diffusion 모델의 condition으로 들어가게 될것입니다.
결론적으로 zero convolution은 조금씩 conditional image의 정보를 학습해주도록 하는 역할을 합니다.
이러한 아이디어를 통해서 LAION-5B의 데이터셋보다 50000배 작은 데이터로 fine-tuning 한 결과로도(100k 데이터 만으로도) 좋은 결과를 얻을 수 있다고 합니다.

위의 사진은 Zero Convolution을 사용하지 않았을 경우, 모델의 성능이 좋지 않음을 보여주면서 Zero Convolution의 능력을 보여주고 있습니다.
GLIGEN

Controlnet처럼 모델을 복사해서 일부만 Fie-Tuning 시키는 모델중에 GLIGEN이라는 논문도 간단히 소개해주셨습니다. 맨위의 왼쪽 예시처럼 Text-prompt에 대한 결과를 나타낼 때 B-Box로 생성되는 이미지의 영역을 지정할 수 있도록 추가로 설정할 수 있는 모델입니다. 이렇게 추가로 설정하는 부분을 Fine-Tuning 한 것입니다.
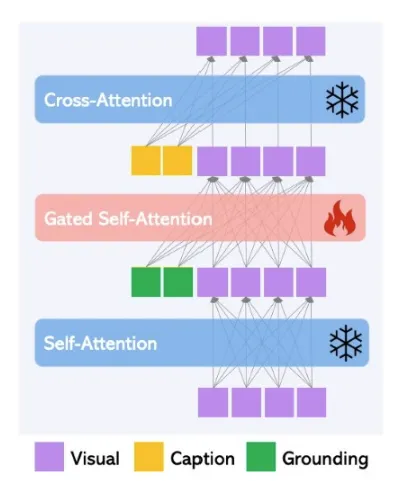
위의 그림이 GLIGEN 구조인데 다른 부분은 그대로 두고 오직 Gated Self-Attention 부분만을 학습함으로써 원하는 모델 구조를 설계할 수 있었습니다.
Personalization

나라는 이미지를 잘 생성하고 싶을 때 어떻게 해야할까요? 내가 원하는 이미지를 생성하려면 어떻게 해야할까요? 이에 대한 답을 주는 모델은 LoRA와 Dream Booth입니다.

LoRA의 핵심 아이디어는 ControlNet과 비슷합니다. 왼쪽에 사전 학습된 모델을 가져오고 입력 차원이 d이고 출력 차원도 d인 간단한 MLP를 주황색처럼 추가합니다.

하지만 d라는 차원이 이미지 정보를 담고 있어서 매우 크기 때문에 이를 줄이는 과정이 필요합니다. 1개의 dxd라는 layer를 d→r→d 이러한 변환을 담는 2개의 layer로 변환함으로써 차원을 줄일 수 있습니다. 해당 방법은 layer를 추가하지만 파라미터 수를 줄이는 LoRA의 핵심 아이디어입니다.
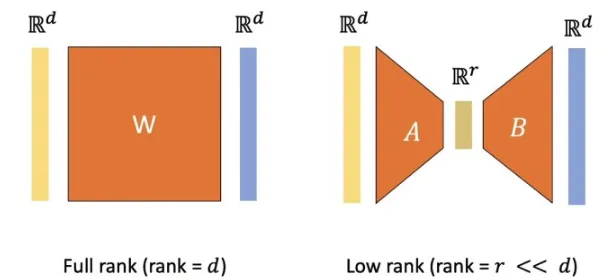
결론적으로 LoRA 모델은 위의 사진처럼 2개의 layer로 구성된 형태가 될 것입니다.
