저널: neurips2021
DDPM 논문리뷰: https://velog.io/@guts4/Basic-Generative-Model-DDPM
GAN 논문리뷰: https://velog.io/@guts4/GANGenerative-Adversal-Network-%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0
DDIM 논문리뷰: https://velog.io/@guts4/Denoising-Diffusion-Implicit-ModelsDDIM-논문-리뷰
GAN vs Diffusion?
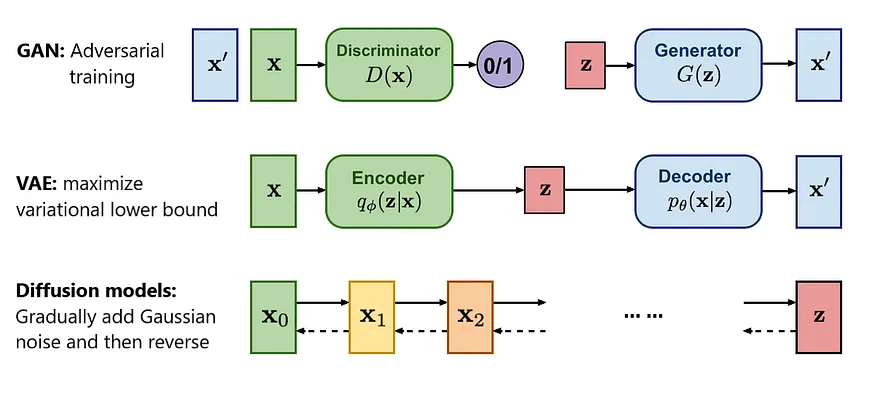
Generative Adverserial Network(GAN)Model: 높은 품질과 빠른 속도라는 장점이 있지만, 다양성이 부족
Diffusion Model: 높은 품질과 다양성은 가졌지만, 속도가 느리다는 단점이 있습니다.
Diffusion 모델의 높은 성능에도 불구하고 해당 논문이 쓰여지는 시점(2021)에서는 간단한 이미지(CIFAR-10)에서는 GAN의 성능을 뛰어넘었지만, 복잡한 이미지(LSUN, ImageNet)에서의 성능은 아직 GAN이 더 높다고 평가됐습니다.
저자는 GAN모델의 성능이 더 높은 이유를 2가지 제시했습니다.
- GAN이 많이 탐구되고 정제되었다.
- GAN 모델이 나온시점이 훨씬 앞서기때문에 이와 관련된 GAN-liked 모델들이 많이 나오고 이중에서 BigGAN-deep처럼 훨씬 더 좋은 모델이 나왔기때문에 아직 Diffusion모델보다 성능이 좋아 보인다.
- GAN은 다양성보다는 이미지의 품질에 집중하고 있다.
저자는 이 2가지 방법을 기반으로 Diffusion모델을 바꿨다고 합니다. 우선 새로운 방법을 추가해서 성능을 개선하고, 다양성과 이미지 품질의 trade off를 개선했다고 합니다.
결론적으로 해당 논문에서 처음으로 Diffusion 모델이 GAN의 성능보다 높게 나왔습니다.
Improvements
Predict variance(분산 예측)
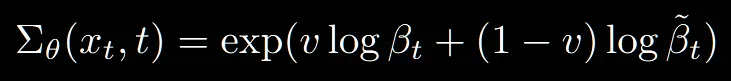
DDPM논문에서는 분산을 constant(상수)로 고정했습니다. DDPM 이전 논문의 결과를 보면 분산을 학습하는 것보다는, 고정하는 것이 성능이 더 좋다고 했지만 이후 논문에서 학습을 통해서 더 최적의 값을 찾을 수 있다고 언급했고 이방식을 이용해서 분산을 학습하도록 변경했습니다.
Architecture Improvements
U-Net
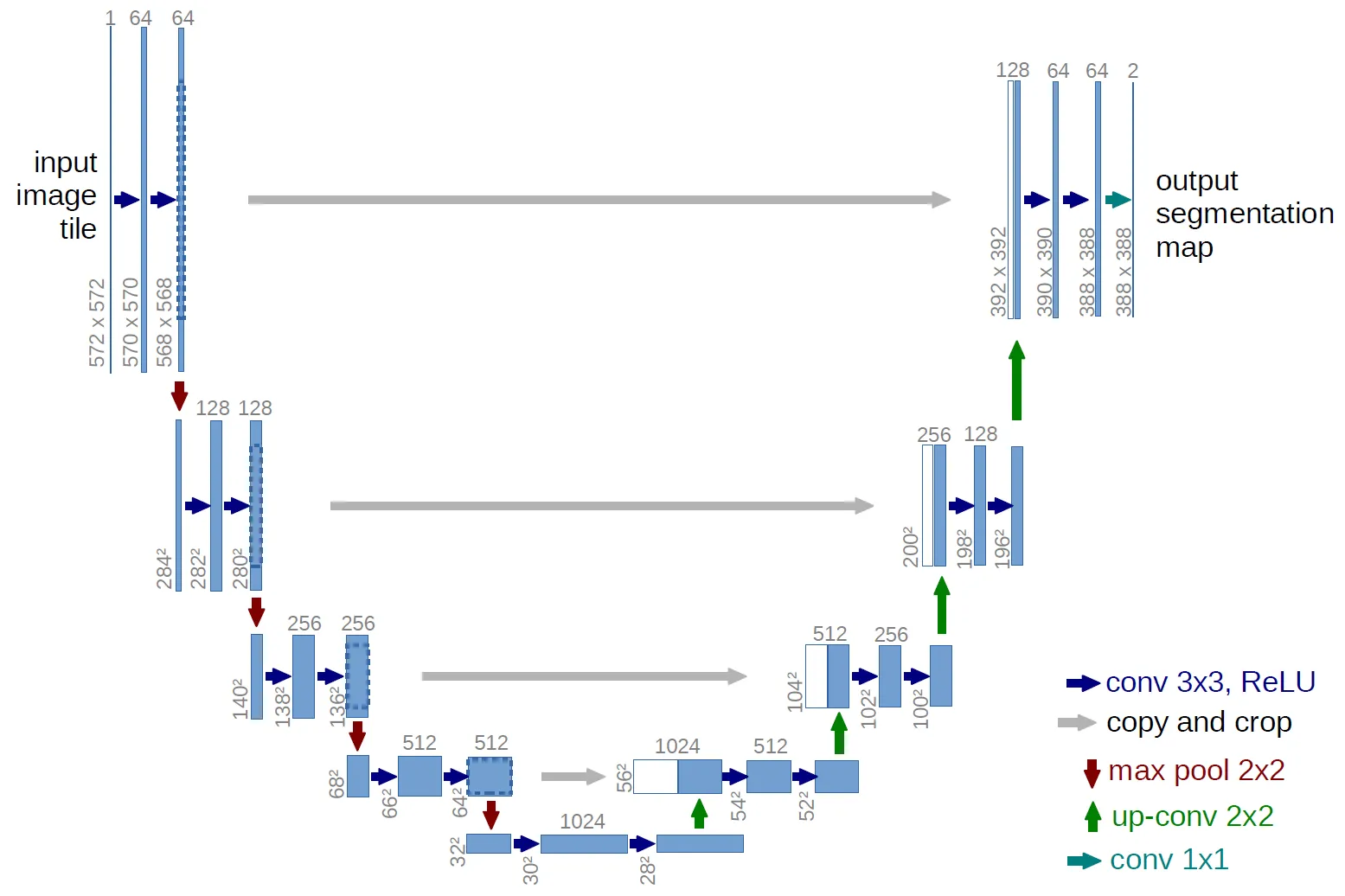
DDPM에서는 위의 U-Net모델을 통해서 노이즈를 예측하는 과정을 진행했습니다. 위의 U-Net모델에 5가지 변경사항을 적용해서 성능을 개선했다고 했습니다.
- 모델의 사이즈는 고정한 채 width는 줄이고, depth는 늘렸습니다.
- attention head의 개수를 늘렸습니다.
- 기존에 16x16에 attention을 적용했는데 이때 사용하는 single head대신에 head수를 늘려섰다고 설명했습니다.
- 그림에서는 32x32가 마지막 feature map사이즈크기인데, 현재 depth를 늘렸기때문에 그림과는 약간 다른 구조이기때문에 그림은 참고용으로만 보시면 됩니다.
- Attention을 32x32, 16x16, 8x8에 모두 적용했습니다.
- BigGAN에서 사용한 residual block을 사용했습니다.
- AdaIN의 residual block을 사용해서 style transfer를 사용할 수 있습니다.(논문 참고)
- Residual connection(회색 화살표)에 를 곱해서 사용했습니다.

U-Net모델의 변경에 따른 성능의 차이입니다. 위에서 설명한 5가지중 마지막 Rescale resblock을 제외하고는 모두 성능이 개선된 것을 확인할 수 있습니다.
그래서 Rescale resblock은 사용된건지 여부가 궁금해서 인터넷을 찾아봤지만, 해당 내용이 나오지 않아서 코드를 확인해봤습니다. 하지만 unet모델에 해당하는 부분에 sqrt(2)에 해당하는 값이 없어서 저는 사용하지 않는다고 판단했습니다.(개인 생각)
+논문의 6페이지에 마지막으로 어떤 모델을 사용했는지 설명할 때 rescale reseblock은 존재하지 않았습니다.
cf. variable width with 2 residual blocks per resolution, multiple heads with 64 channels per head, attention at 32, 16 and 8 resolutions, BigGAN residual blocks for up and downsampling, and adaptive group normalization for injecting timestep and class embeddings into residual blocks.
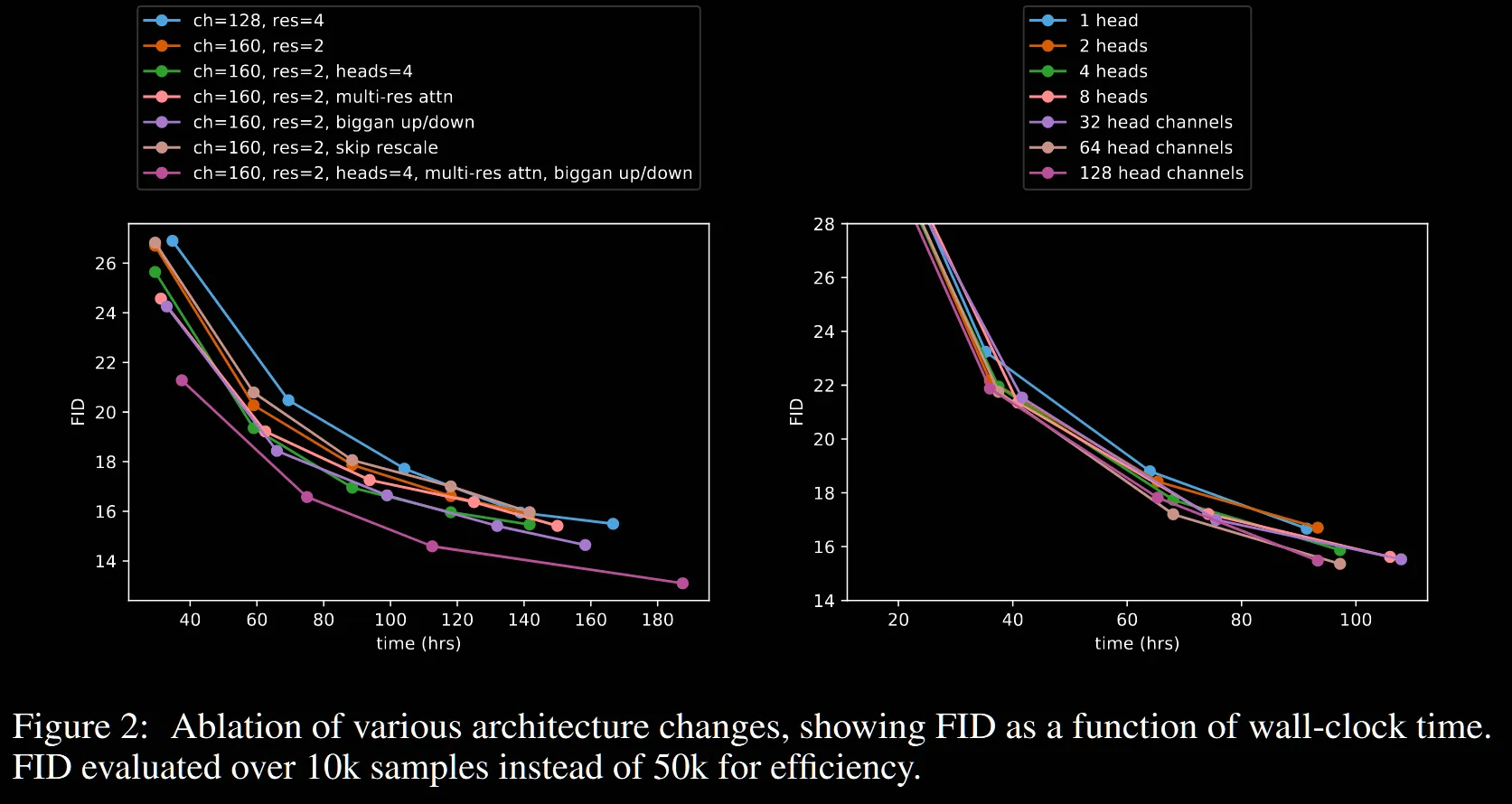
해당 그림을 통해서 성능별 모델의 학습시간을 확인할 수 있습니다. 논문에서 depth를 늘렸을 때 성능이 더 좋아지긴 했지만, 학습시간이 오래 걸리기때문에 추후 실험에서는 사용하지 않았다고 합니다.
Adaptive Group Normalization

U-Net모델의 residual block들에 group normalization이후 timestep과 class embedding 정보를 포함하도록 설정했습니다.
로 이루어져있고 각각 timestep과 class embedding을 의미합니다.
Classifier Guidance
t시점의 이미지 와 time step t를 입력으로 해서 class label에 속한 확률 을 학습합니다. 이후 해당 값의 gradient인 이미지가 특정 확률에 속할 확률인 를 이용해서 해당 class에 속할 확률을 최대화하면서 학습을 진행합니다.
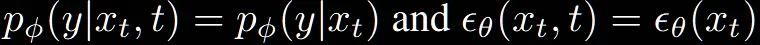
아래에 어떻게 classifier를 학습하고, 이를 통해서 어떻게 sample quality를 개선할지 설명할 것인데 위의 수식처럼 time step이 condition으로 들어가는데 편의상 생략하고 적을것입니다.
Conditional Reverse Noising Process

Reverse process과정에서 class label y를 condition으로 넣기 위해서 위와 같은 형태로 수식을 변경해야합니다.
- : unconditional 모델에서의 reverse process
- : 가 특정 label y에 속할 확률(classifier)
- Z: normalizing constant
normalizing constant는 확률 분포가 유효한 확률 분포가 되도록 전체 확률이 1이 되게끔 맞춰주는 역할인데, 해당 값을 구하기가 매우 복잡하고 어렵습니다.
따라서 이를 perturbed Gaussian distribution, 즉 간단한 분포로 바꾸는 과정을 설명해드리겠습니다.
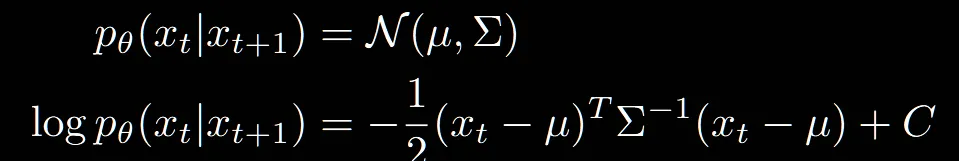
위의 과정은 DDPM에서 reverse process입니다. 평균과 분산을 예측하고 해당 network의 미분값이 아래의 식입니다.
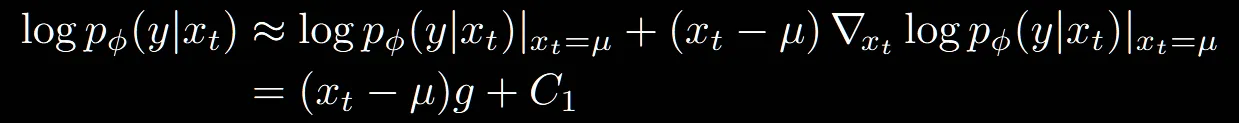
를 구하기 위해선 한가지 가정을 해야합니다. 해당 함수의 변화가 완만하고, 급격한 변화가 없다는 low curvate를 갖는다는 가정입니다. 즉 값이 작아서 변화가 작다는 가정입니다. 이러면 1차 Taylor expansion(테일러 전개)로 모델을 간단하게 나타낼 수 있습니다.
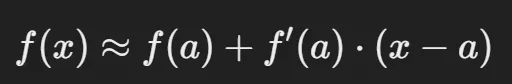
여기서 말하는 1차 테일러 전개는 함수 f(x)가 점 a에서 다형식 형태로 근사하는 방법으로, 쉽게 말하면 복잡한 함수를 단순화하는 방법입니다. 2차, 3차도 있지만 위에서 함수가 low cruvate이기때문에 1차 테일러 전개만으로도 표현할 수 있다고 한 것입니다.
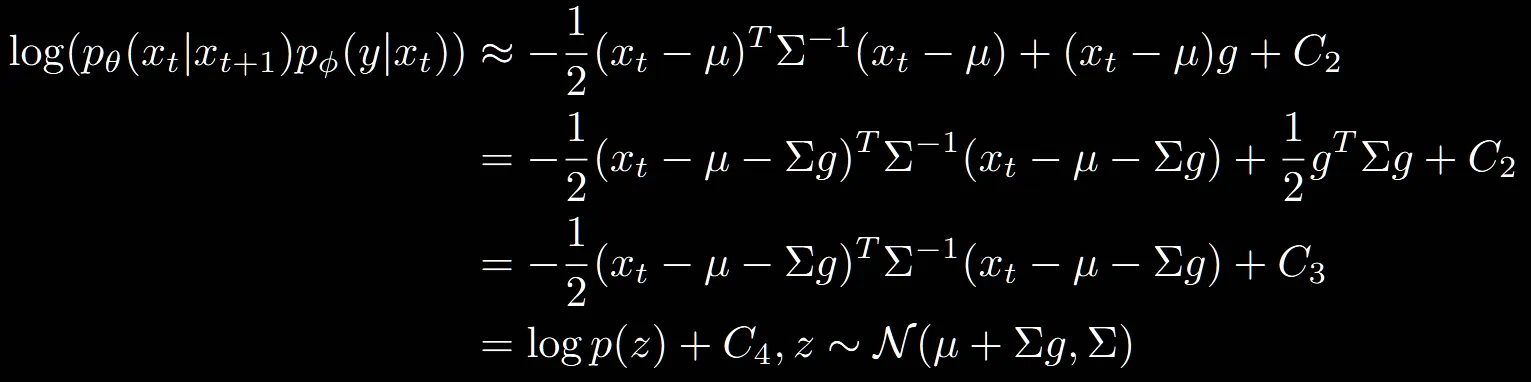
결론적으로 위의 2개의 함수를 곱하면 식(10)이 나오고, 해당 식은 기존 unconditional diffusion모델에서 평균에 를 더한 값입니다.

알고리즘으로 나타내면 위와 같은데, 평균에 gradient scale을 통해서 condition 정보를 넣은 것을 알 수 있습니다.
Conditional Sampling for DDIM
이전 과정은 DDPM의 reverse process에서 어떻게 condition 정보를 넣는지에 대해서 설명했습니다. DDPM에서 Sampling 과정을 변경해서 시간을 크게 단축한 DDIM 논문도 unconditional 모델이기때문에 해당 모델에 적용하는 방법을 설명해드리겠습니다.
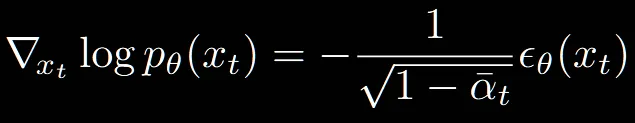
해당 모델에 적용하기 위해서 score matching 방식을 적용했습니다. 원래 DDIM은 위의 식처럼 에서 노이즈를 제거하는 방향으로 데이터를 이동시킵니다. 해당식에 condition 정보를 적용하기 위해서 를 적용하면 아래와 같습니다.

최종적으로 노이즈를 얘측하는 네트워크는 아래와 같이 생겼고, 해당 식은 condtion 정보를 반영할 수 있는 모델로 수정됐습니다.
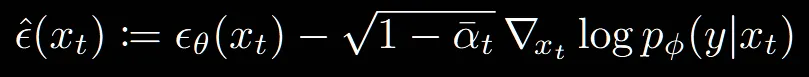

이를 간단히 나타낸 과정이 Algorithm 2입니다. 노이즈를 예측하는 과정에서 condition을 추가할 수 있는 식이 추가된 것을 확인할 수 있습니다.
개인적으로 DDPM에서는 평균을 구하는 수식에 Classifier gradient를 더하고, DDIM에서는 노이즈를 예측하는 과정에서 Classifier gradient를 더한점이 궁금했습니다. 둘다 그냥 노이즈 예측하는 과정에서 Classifier gradient를 더했으면 안될까? 라는 의문으로 찾아본 결과는 아래와 같습니다.(확실하지 않습니다.)
→ DDPM은 다음 step의 평균을 구하가면서 reverse process가 진행됩니다. 노이즈를 예측하는 과정도 결국 구한 노이즈로부터 다시 평균을 구합니다. 하지만 DDIM은 결정론적으로 정해진 경로를 구하기 위해 노이즈를 예측합니다. 즉 수식이 서로 다르기 때문에 여기서 Classifier gradient도 서로 다른 형태로 더해지는 것입니다.
Scaling Classifier Gradients
Classifier는 U-Net모델의 downsampling 맨아래에 있는 8x8 layer의 출력값을 이용해서 학습됩니다. 학습에 사용되는 데이터셋은 ImageNet입니다. 오버피팅을 피하기 위해서 Random crops을 추가로 적용했습니다.

Scaling값을 몇으로 적용하느냐에 따라서 모델의 결과가 크게 차이가 납니다. 왼쪽은 scale이 1.0일 때의 결과로서 완벽하게 corgi를 표현하지 못하고 있지만, 오른쪽 scale이 10.0일 때는 corgi를 거의 완벽하게 표현하는 것을 확인할 수 있습니다.
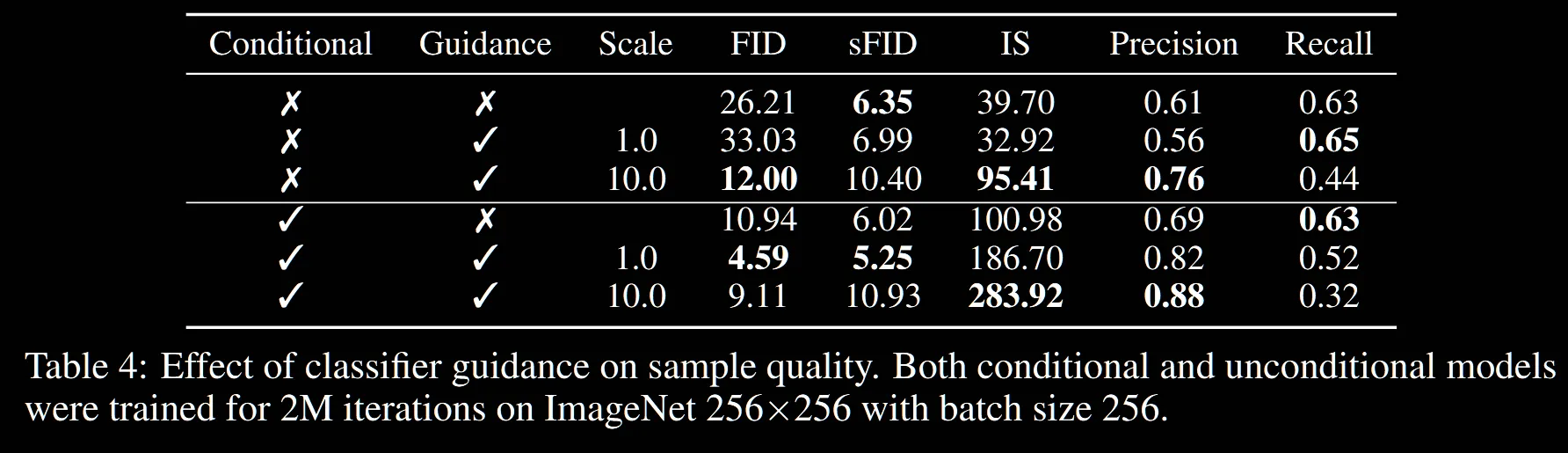
해당 표는 Guidance의 적용 유무에 대한 결과입니다. Guidance를 적용할 경우, IS값은 증가하고, Recall값은 작아지는 것을 확인할 수 있습니다. IS의 증가를 통해서 품질은 개선되었지만 Recall값이 실제 데이터 분포의 얼마나 많은 부분을 커버하는지 인데, 해당값의 감소를 통해서 데이터의 diversity는 감소한 것을 확인할 수 있습니다. 논문에서는 이 부분을 trade-off라고 설명했습니다.
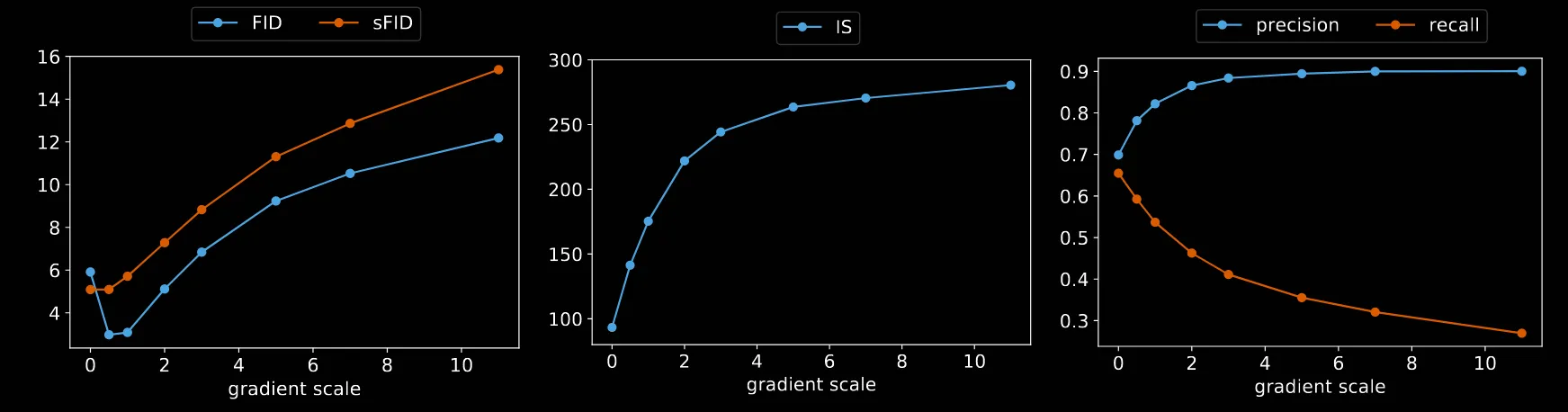
그림을 통해서 조금더 자세히 알아보면, scale값이 커질수록 IS는 증가, recall은 감소하는 것을 알 수 있습니다. FID는 다양성과 품질을 모두 고려해야하는 지표이기때문에 최적점은 1.0이라는 것을 확인할 수 있습니다.
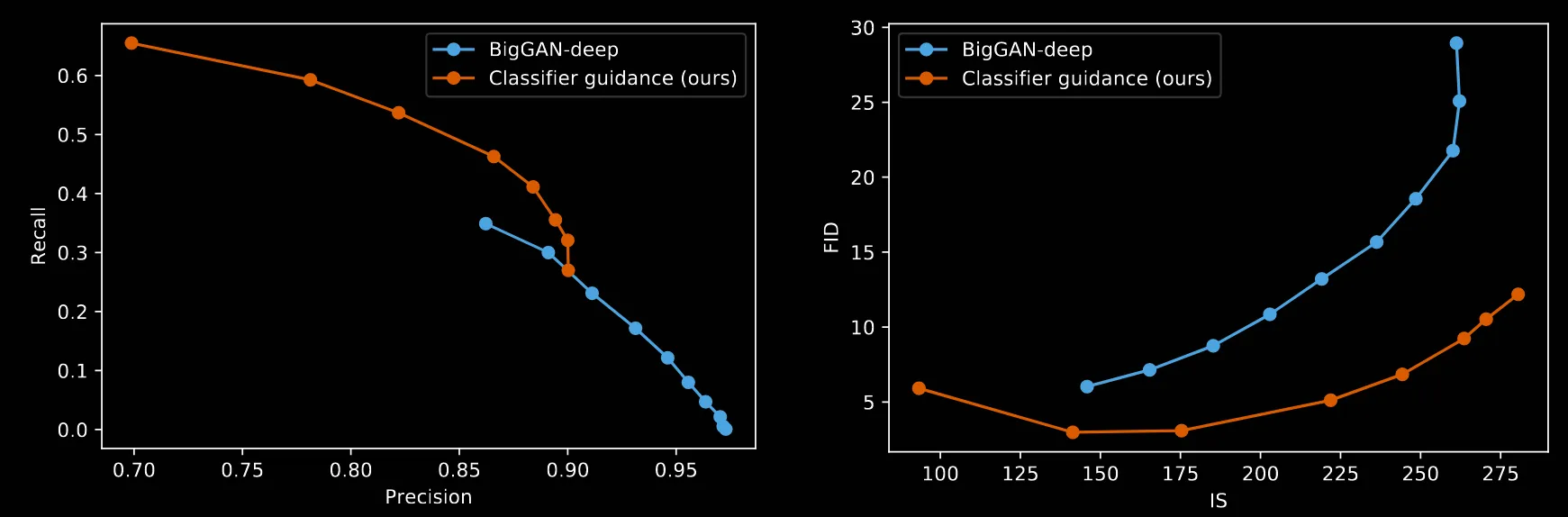
GAN의 SOTA모델인 BigGAN과의 비교를 하는 그림입니다. truncation level을 0.1~1.0까지 0.1 간격으로 나타낸 결과입니다. truncation level은 정규분포로에서 평균으로부터 어느정도 떨어진 구간을 샘플링 할지 나타낸 것입니다.
왼쪽의 그림을 통해서 모델의 다양성 측면에서 classifier guidance가 더 좋고, precision 즉 실제 데이터 분포에 얼마나 가까운지를 나타내는 지표에서는 GAN 모델이 더 좋은 것을 확인할 수 있습니다.
오른쪽 그림의 마지막 점인 truncation 1.0을 기준으로 보면 FID도 더 낮고, IS도 더 높으므로 최종적으로 classifier guidance의 성능이 더 좋다! 라고 결론낼 수 있습니다.
Results
Unconditional 모델 비교를 위해서 LSUN데이터의 bedroom, horse, cat 3가지 class를 학습시켰습니다. 또한 classifier guidance의 성능을 평가하기 위해서 ImageNet 데이터셋을 사용했습니다.
ADM: Ablated Diffusion Model // ADM-G: ADM + classifier guidance
- ADM은 Classifier Guidance를 제외하고, 분산 예측이나 Unet모델 구조 변경같은 부분들은 반영된 모델이라고 보시면 됩니다.
Unconditional: 1000 steps // Conditional: 250 steps(DDIM 25 steps)
Unconditional Model
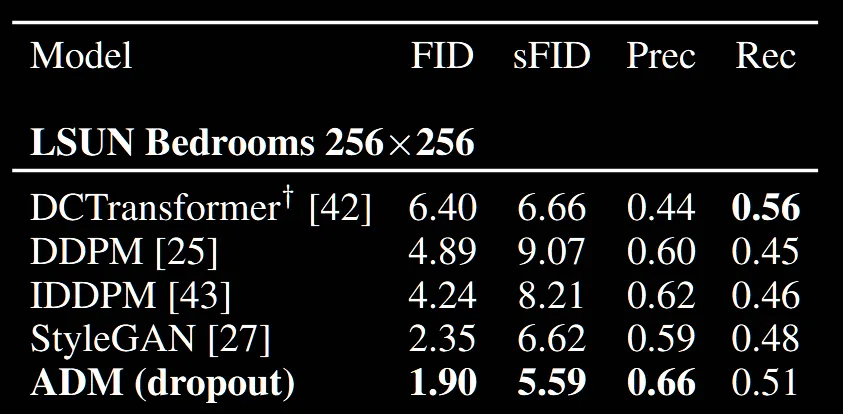
Bedroom 클래스에서 ADM의 성능이 가장 우수한 것을 확인할 수 있습니다.
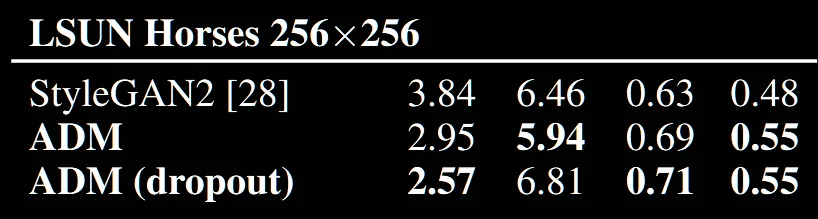
Horses 역시 ADM이 가장 우수합니다. 개인적으로 이전 Bedrooms에서는 dropout을 적용하지 않은 결과는 나타내지 않았는데, 아마 dropout적용한 sFID가 너무 높아서 dropout을 적용하지 않은 결과를 보여준것같다는 생각이 듭니다.

Cat 역시 ADM이 가장 우수합니다. 개인적인 생각이 틀렸다는걸 보여주듯이 여기서는 dropout을 적용하지 않은 결과를 보여주지 않았습니다.
Conditional Model
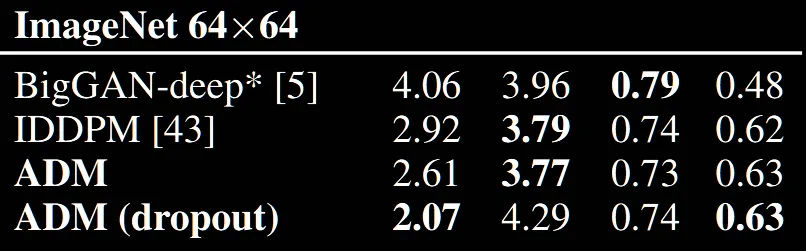
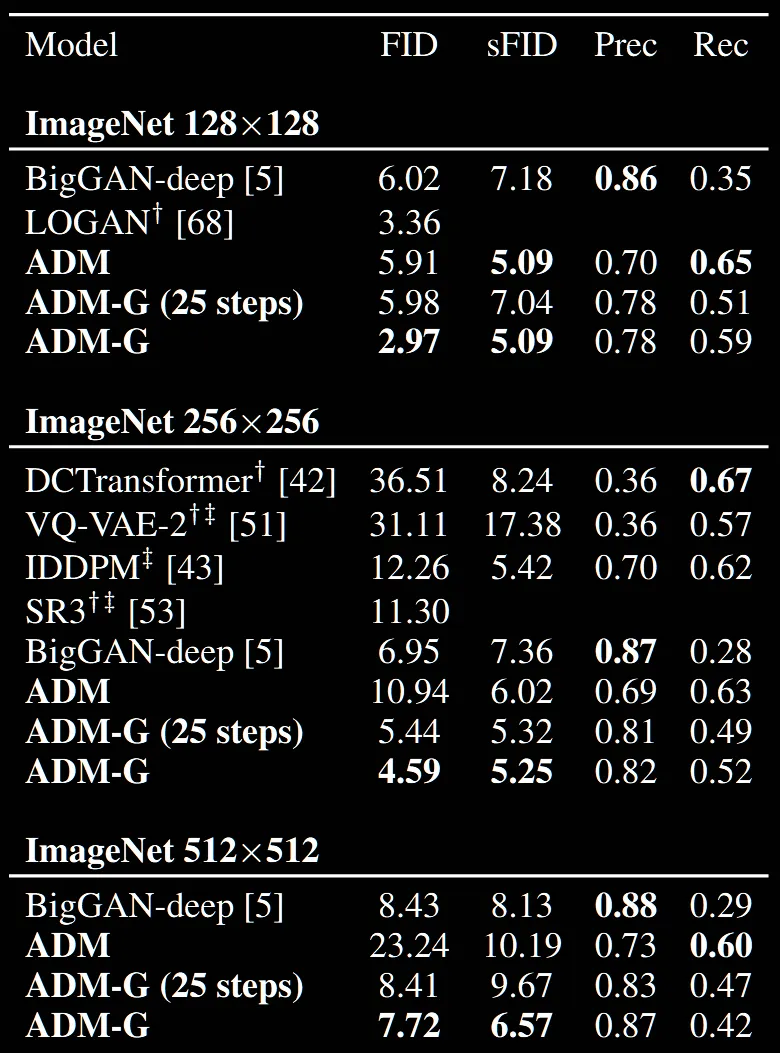
Conditional 부분에서 다른부분은 생략하고 가장 신기했던 부분은 DDIM과 DDPM에 Classifier guidance를 적용했을 때 DDPM의 성능이 더 좋다는 점입니다. 물론 step수 자체가 250과 25로 다르긴 하지만, Classifier guidance를 제외하고는 성능이 더 좋았는데 적용후 성능이 차이난다는 점이 신기했습니다.
