출처[LECTURE13]
강의 영상 및 자료:
https://mhsung.github.io/kaist-cs492d-fall-2024/
해당 강의를 기반으로 추가적인 설명을 정리했습니다.
Inverse problems

지난 강의에서 배운 Inverse problem의 사용 예시로서 style guidance가 있습니다.
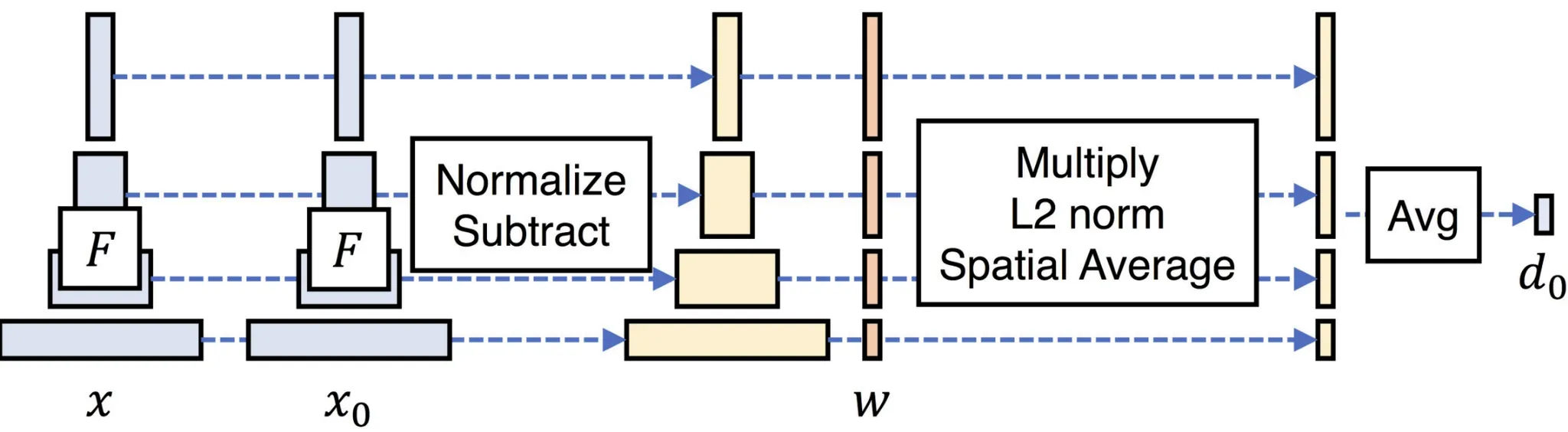
Style guidance를 사용하는 첫번째 방법은 Learned Perceptual Image Patch Similarity(LPIPS)입니다. 이전에 저희가 L2 difference를 이용해서 Condition 정보를 기반으로 Inverse problem을 학습할 수 있는 것을 확인할 수 있었고, 해당 방법을 사용하기 위해서 condition으로 들어가는 style을 어떤 CNN network(VGG, DINO)를 이용해서 feature를 추출하고, 이를 기반으로 L2 difference를 계산하면서 학습을 진행하게 됩니다.
또 다른 적용 분야는 protein engineering이라고 하셨는데… 해당 부분에 대해서는 정보가 많이 없어서 어떠한 방법으로 적용된지는 모르겠지만 어쨌든 condition과 L2 difference를 기반으로 학습된 것입니다.
Coherent Panoramas

사실 Panoram 이미지 생성 관련해서는 Lecutre 11에서 자세히 설명해주셨지만, 해당 내용을 제가 리뷰 하지않아서 이 부분도 최대한 간단하게 설명하고 넘어가도록 하겠습니다.
MultiDiffusion의 결과가 위의 사진과 같은데 장점은 전체이미지가 매끄럽게 이어지는 듯한 느낌을 받지만, 왼쪽은 밤 오른쪽은 낮처럼 이미지와 이미지의 차이는 일치하지 않습니다.

어떻게하면 이미지와 이미지의 차이도 줄인 결과가 나오게 될까요?
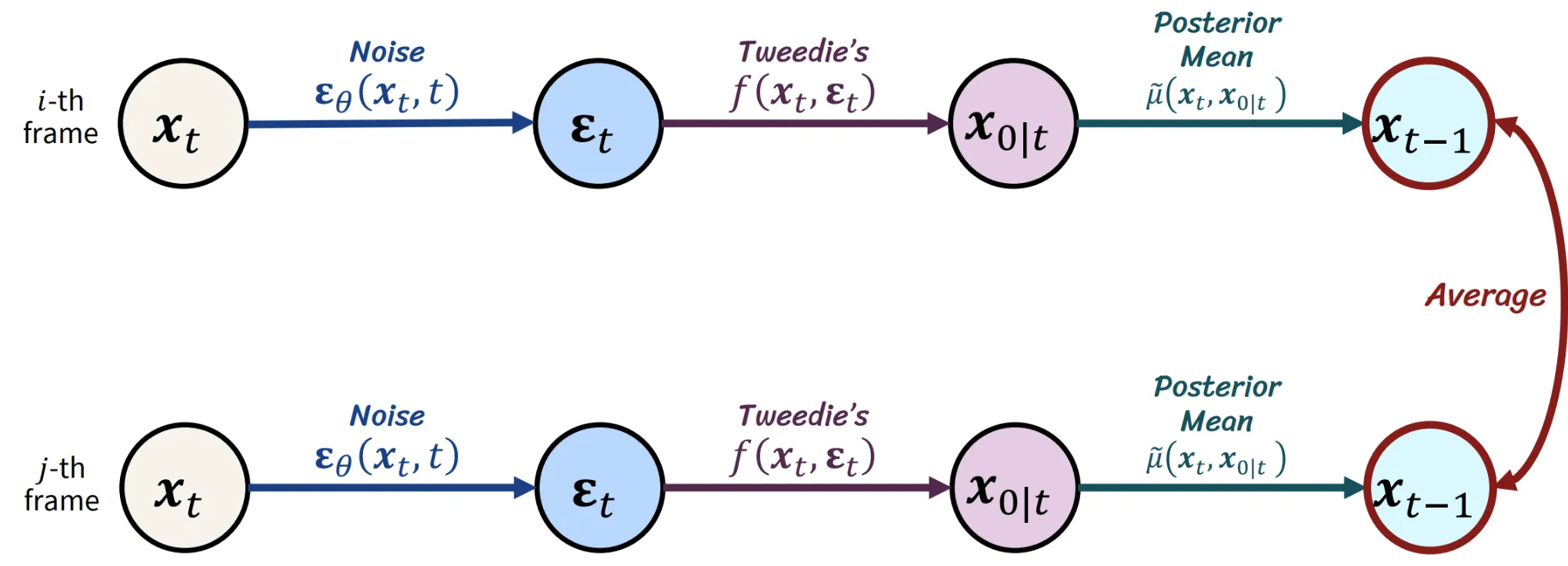
아이디어는 간단합니다. 원래 MultiDiffusion의 작동방식은 여러장의 이미지가 각각 reverse process를 거친다음에 평균을 취하는 형식으로(위와 같은 방식으로) 작동합니다.
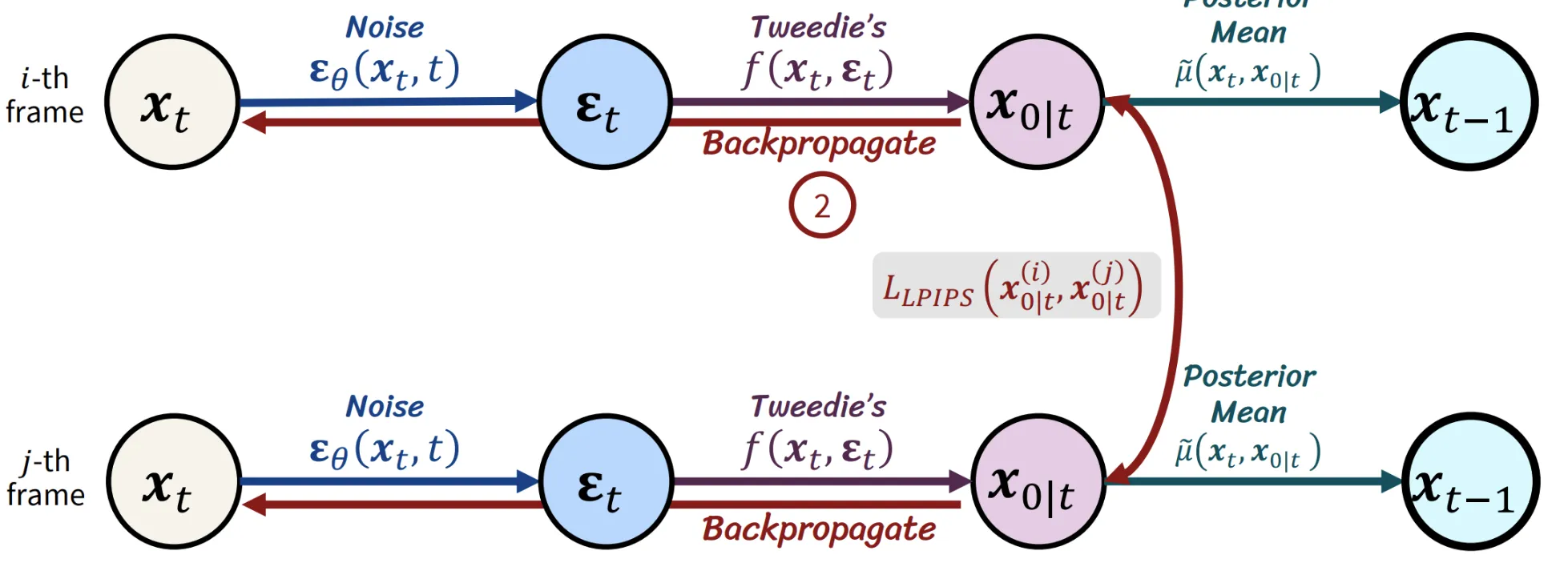
이때 평균을 취하기전에 이전단계에서 L2 difference를 이용해서 각 이미지들끼리의 차이를 줄이고(Backpropagate 까지 진행하고) 다시 원래대로 평균을 취하는 형식으로 동작하게 하는 것입니다.

결론적으로 위와같이 이전에는 단절된 이미지들이 존재했다면, 오른쪽과같이 모든 이미지들이 연결되는 느낌을 더 받을 수 있도록 파노라마 이미지가 생성되었습니다.
Guided Generation - Summary
지금까지 배웠던 condition을 주는 방법에 대해서 비교해보려고 합니다.
ControlNet
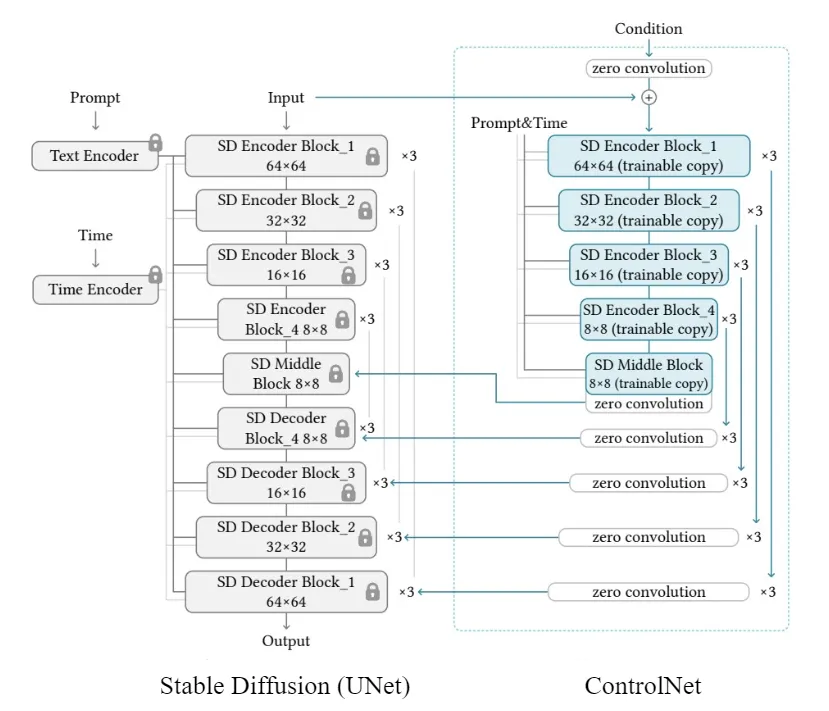
- 만약에 condition-output 페어 데이터를 갖고 있고 이를 이용해서 finetuning 할 수 있다면 적절한 모델입니다. 해당 데이터가 없다면 controlNet을 사용할 수 없을 것입니다.
- 또한 Condition과 Output이 동일한 데이터 모달리티를 공유할 때 사용된다고 합니다.
- Condition과 Output은 spatially aligned 되어야 합니다. 즉 새 스케치 사진을 넣었을 때 꽃이 생성되는 것을 기대하기 힘든 것처럼 어느정도 픽셀값들이 align 되어있어야 한다는 의미입니다.
- 예를 들어서 Zero 123같이 Novel view synthesis(새로운 뷰의 이미지 생성)은 ControlNet에서 좋은 결과를 기대하기 힘들 것입니다. 어느정도 픽셀의 위치가 비슷해야하는데 새로운 시점에서는 전혀다른 위치에 픽셀값이 존재할 확률이 있기 때문입니다.
Classify-Free Guidance

- ControlNet과 동일하게 condition-output 페어 데이터가 존재해야합니다.
- 하지만 condition과 output이 controlnet과 다르게 spatially aligned될 필요는 없습니다.
ControlNet은 Condition을 기반으로 이미지를 수정하고, Classify-Free Guidance는 이미지의 전체적인 특징을 바꿉니다.
ControlNet 같은 경우 pose를 condition으로주면 동일한 pose의 어떤 물체를 만들거나, mask를 condition으로 주면 해당 mask만 inpainting 하는 경우가 다수입니다. 이와 달리 Classifiy-Free Guidance는 이미지의 전체적인 특징을 condition에 맞게 수정하기 때문에 ControlNet에서는 Condition과 Output이 align되어야 하는 반면, Classify-Free Guidance는 align이 없어도 되는 것입니다.
Diffusion Posterior Sampling(DPS)

- condition-output pair가 없을 경우 objective function을 사용하여 모델을 훈련
- 이때 objective function은 미분 가능해야 합니다.
한문장으로 정리하면 condition-output 페어가 없을 때 미분 가능한 objective function(ex. loss functioni)을 통해서 condition 정보를 추가하는 것입니다.
SDEdit
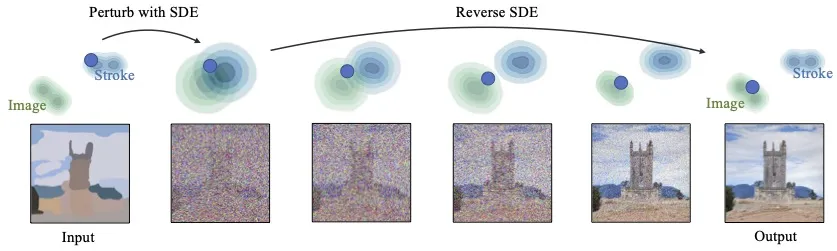
- Condition과 Output간의 관계가 데이터 기반이나 objective function으로 명확히 정의되지 않았을 때
- 목표가 비현실적인 데이터 포인트(스케치)에서 현실적인 데이터 포인트(그림)으로 변환하는 경우
