Bayesian Diffusion Models for 3D Shape Reconstruction[2024 CVPR]
BDM(Bayesian Diffusion Model)은 Bayesian Inference 개념을 Diffusion model에 접목시켜, top-down(prior)과 bottom-up(posterior) 정보의 결합을 통해 3D shape reconstruction 성능을 개선하는 방법입니다.
Method
Bayesian Inference with Stochastic Gradient Langevin Dynamics
입력 이미지(x)로부터 point cloud들의 집합(y)를 찾는 것이 우리의 목표입니다.
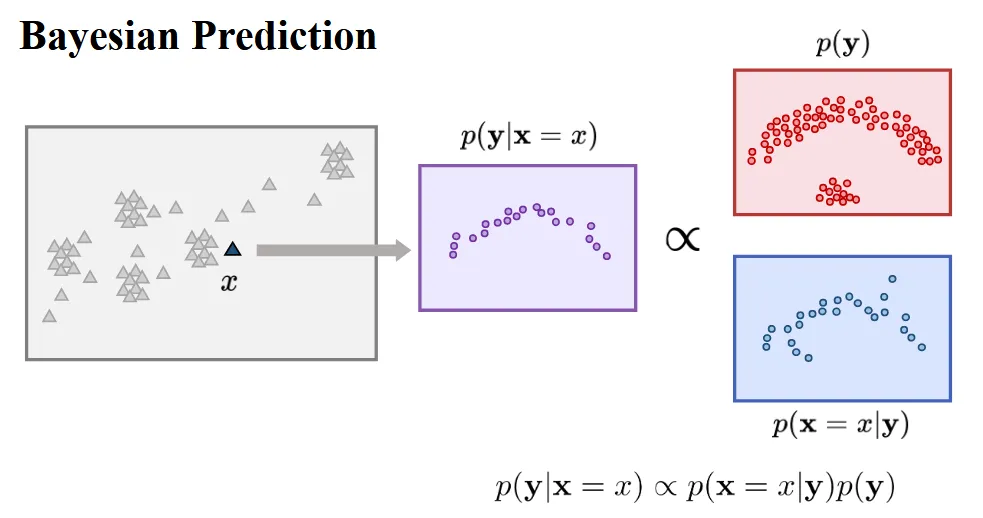
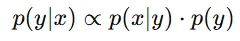
Bayesian 정리에 따르면 Posterior = LIkelihood X Prior라는 것을 알 수 있습니다. 하지만 실제로 Likelihood는 구하기가 어렵습니다.
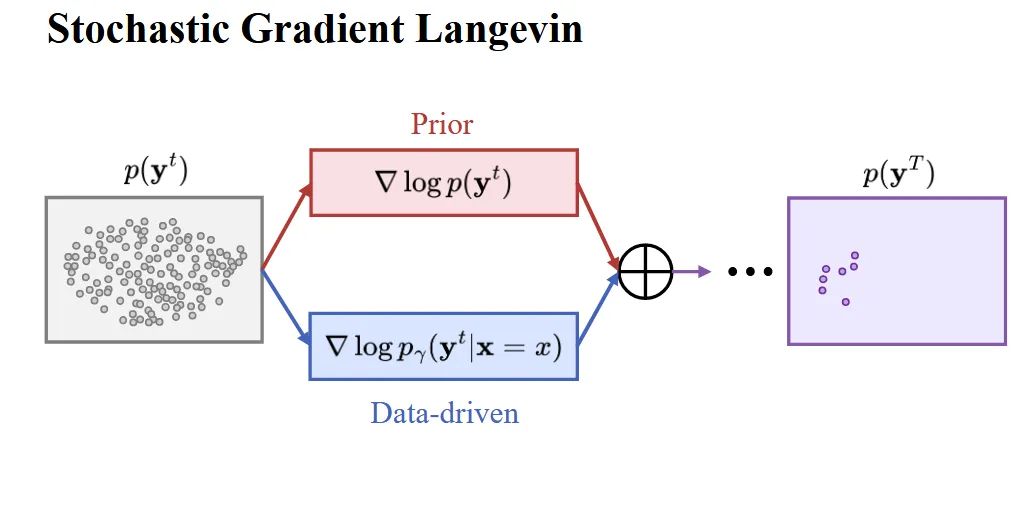
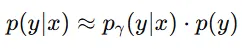
따라서 Likelihood 부분에 데이터 기반 근사 모델을 사용해서 학습합니다.
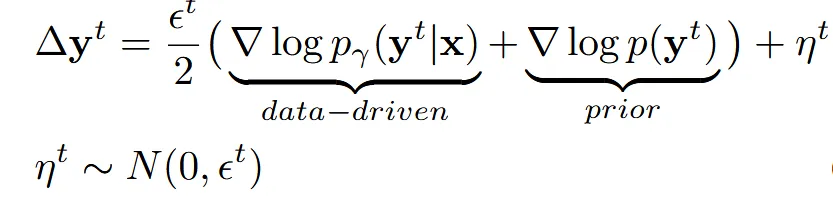
- ϵt: 작은 step 크기
- : 랜덤 가우시안 노이즈
- : 현재 예측한 y가 이미지 x에 맞는지에 대한 데이터 기반 gradient
- : 현재 y가 일반적인 모양(prior)에 얼마나 맞는지에 대한 사전 gradient
위와 같은 방식으로 진행할 경우 2가지 한계점이 존재합니다.
- log 확률의 식을 정확하게 계산하기 어렵다
- 2개의 gradient를 단순히 더하기만 하기 때문에 복잡한 상호작용이 없다.
나머지 절에서는 2가지 한계점을 어떻게 극복하는지 설명하도록 하겠습니다.
Denoising Diffusion Probabilistic Models
이 부분에서는 Diffusion 모델을 이용해서 어떻게 Point Cloud를 예측할 수 있는지 설명합니다.
Forward process가 이미지에 노이즈를 추가하는 과정이기 때문에, Point Cloud에서도 마찬가지로 각각의 point에 노이즈를 추가하는 과정입니다. 이때 각 점은 3차원 좌표이기 때문에 N개의 Point Cloud에 대해서 다루는 diffusion 모델은 3N차원입니다.
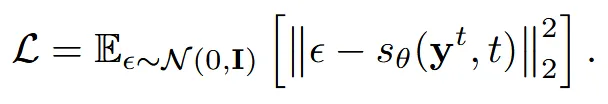
Backward process는 일반적인 diffusion 모델처럼 디노이징을 하는 과정입니다. 위의 식도 동일하게 t시점에서의 노이즈를 예측하면서 진행됩니다.
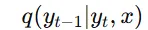
추가적으로 우리는 data given(image x) 상태이기 때문에 condition으로 single-view image x만 추가하게 됩니다.
Bayesian Diffusion Model
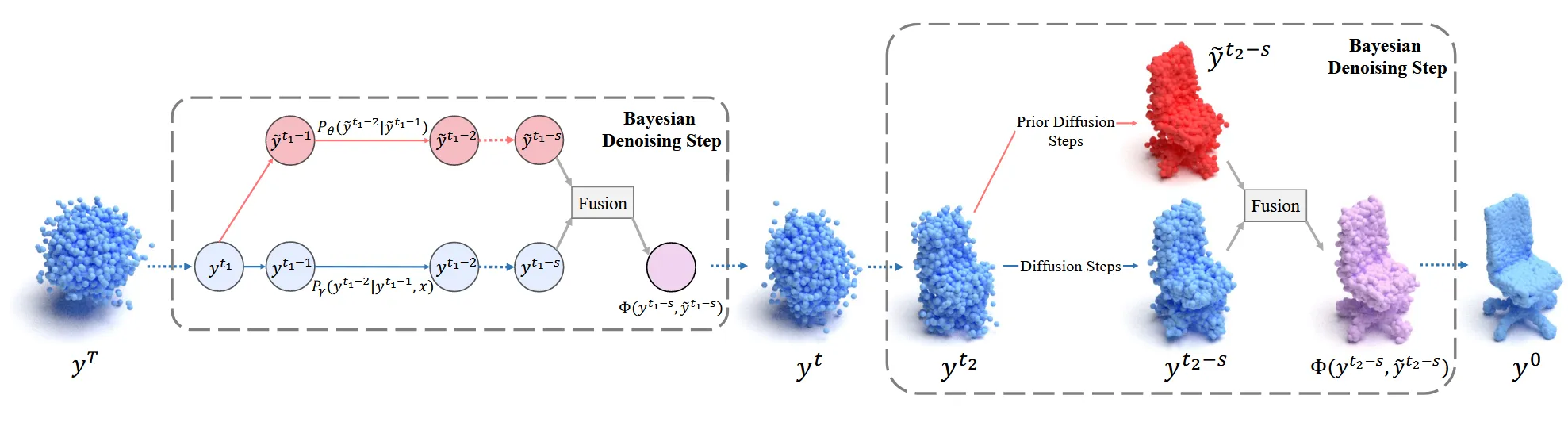
해당 부분에서는 prior gradient와 데이터 기반 gradient 2가지를 단순히 더하지 않고 어떻게 fusion 할 수 있는지에 대해서 설명합니다.
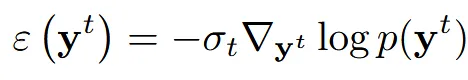
Prior difusion model은 위와 같이 현재 시점 에서 prior 분포로부터 더 그럴듯한 y 방향으로 이동하는 gradient입니다. 즉 사람은 팔이 2개 다리가 2개야 라는 prior 지식을 반영하는 gradient 입니다. 위의 model을 논문에서는 generative(prior) model이라고 부릅니다.
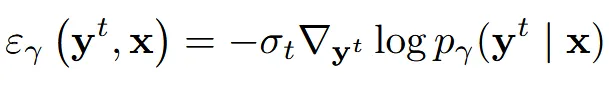
같은 방식으로 이미지를 보고 point cloud를 reconstruction 하는 모델은 위와 같이 작동합니다. 위의 모델을 논문에서는 Reconstruction model이라고 부릅니다.
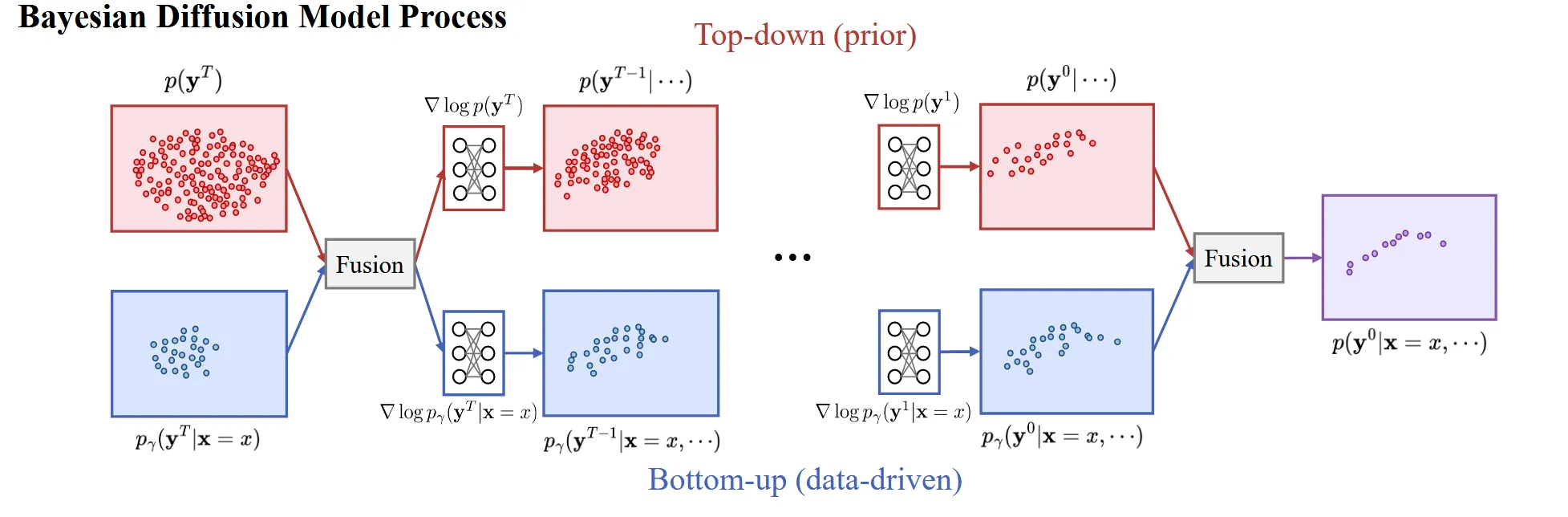
2개의 gradient를 단순히 더하면 상호작용이 없습니다. 따라서 2개의 gradient를 상호작용할 수 있는 함수 Φ를 도입합니다.
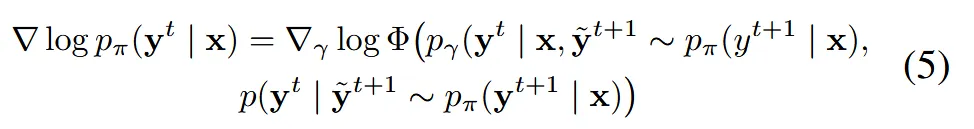
2개의 gradient를 log 함수안에서 Φ를 이용해서 합친 후, 이를 이용해서 2개의 gradient를 융합하는 것입니다. 수식을 자세히 보시면 t+1시점의 y에 ~이 붙어서 동일한 공통 조건으로 작용하고, 동일한 공통 조건으로부터 t시점을 예측할 때 단순히 더하는 것이 아닌 Φ 함수를 학습합니다. Φ 함수 학습 방식은 다음 절에서 설명하도록 하겠습니다.
Point Cloud Prior Integration
이번 절에서는 Φ 함수가 실제 구현에서 어떻게 동작하는지를 설명하도록 하겠습니다. BDM-M(Merging)과 BDM-B(Blending) 2가지 방식으로 나누어서 동작합니다.
BDM-M(Merging)
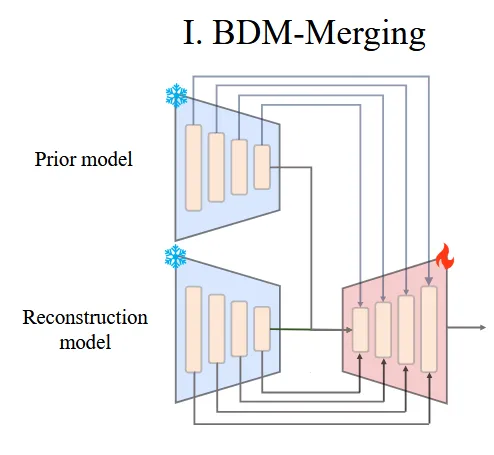
BDM-M은 PVD와 PC2 2개의 diffusion 모델을 사용해서 진행합니다. 2개의 모델 모두 backbone이 PVCNN이기 때문에 feature-level로 정보를 주고받기가 쉽습니다.
Prior model로 PVD를 사용하고 PVD의 Encoder는 고정합니다. Reconstruction model로 PC2를 사용하고 PC2의 decoder만 학습하도록 합니다. 이후에 PC2의 decoder에 PVD encoder의 multiscale feature를 zero-initialized convolution을 이용해서 부드럽게 학습합니다.
따라서 여기서의 Φ함수는 PVD의 Encoder 정보를 PC2의 Decoder에 삽입하도록 도와주는 함수라고 볼 수 있습니다.
BDM-B(Blending)
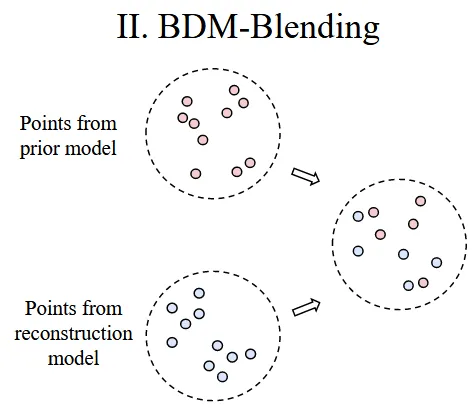
BDM-M이 PC2의 decoder를 학습했다면, BDM-B는 training free 모델입니다. 해당 모델은 2개의 모델이 각각 denoising을 한 뒤 반반 섞어서 예측값을 사용하도록 하는 방식을 채택했습니다.
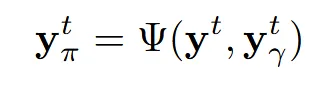
같은 gaussian noise에서 시작해서 N개의 point cloud에 대해서 1 step denoising을 진행하면 N개의 결과가 나오는데 여기서 각 N개에 대해서 50% 확률로 prior model의 output을 사용하고, 나머지 50% 확률로 reconstruction model의 결과를 사용하는 것입니다.
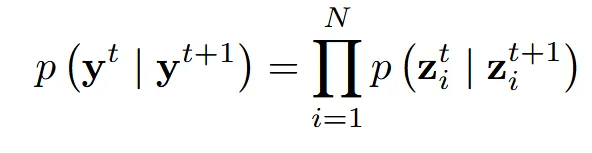
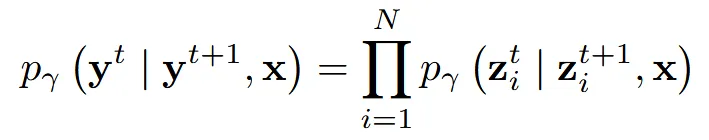
z는 Ψ함수에 의해 prior 또는 reconstruction 중에서 선택된 하나의 점입니다. 이를 diffusion 모델에 적용한게 첫번째 수식이고, 여기에 condition(x)까지 적용한게 아래의 수식입니다.
Experiments
Data
- ShapeNet: Synthetic(합성) 데이터셋(chari, airplane, car 카테고리만 사용)
- Pix3D: 실제 이미지 기반 데이터셋(chair, table, sofa 카테고리만 사용)

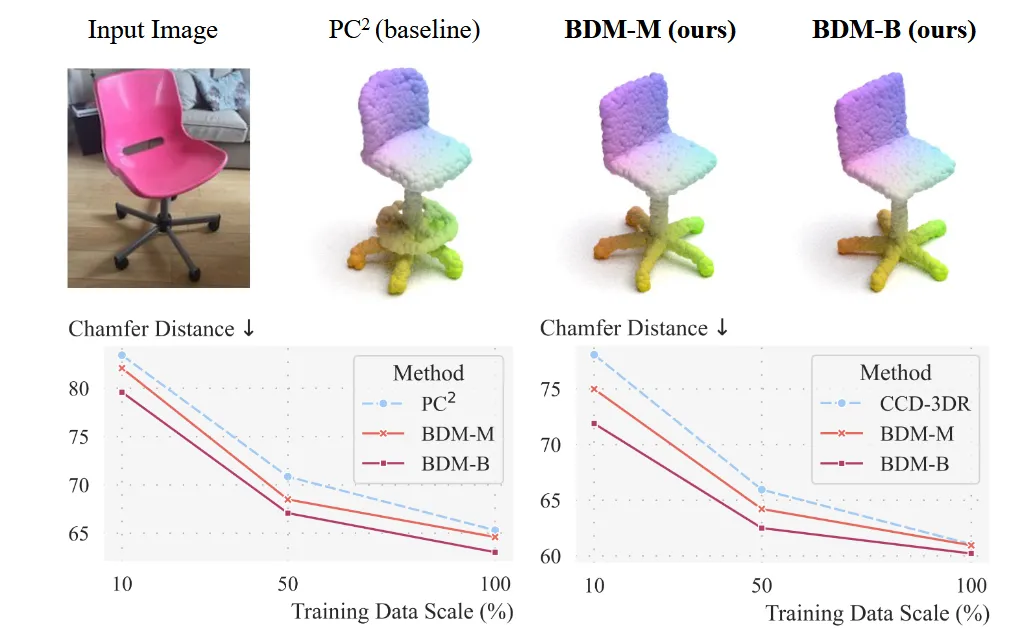
학습 데이터 양이 적을수록 baseline이 심각하게 무너지지만, BDM은 prior 정보 덕분에 안정적이고 정밀한 3D reconstruction이 가능하고, 데이터를 50% 늘려도 여전히 BDM 성능이 우월한 것을 확인할 수 있습니다.

BDM vs CFG
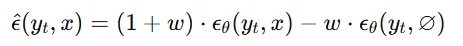
CFG도 conditional과 unconditional 2가지 모델의 결과를 조합하기 때문에 2가지 해당 논문에서 사용하는 방식에 적용할 수 있습니다.

하지만 결과를 보면 확실히 CFG보다 BDM을 사용한 경우가 2가지 gradient를 fusion했기 때문에 좋은 것을 알 수 있습니다.
