TextDeformer: Geometry Manipulation using Text Guidance[SIGGRAPH 2023]

입력 Mesh를 Text prompt 기반으로 deformation하는 논문입니다. 아마 이전에 리뷰했던 MeshUp과 비슷한 과정인데 해당 논문이 2023년으로 baseline이 되었던거 같습니다. 어떤 방법을 사용했는지 Deformation 특히 Jacobian 부분을 중심적으로 설명하도록 하겠습니다.
Method
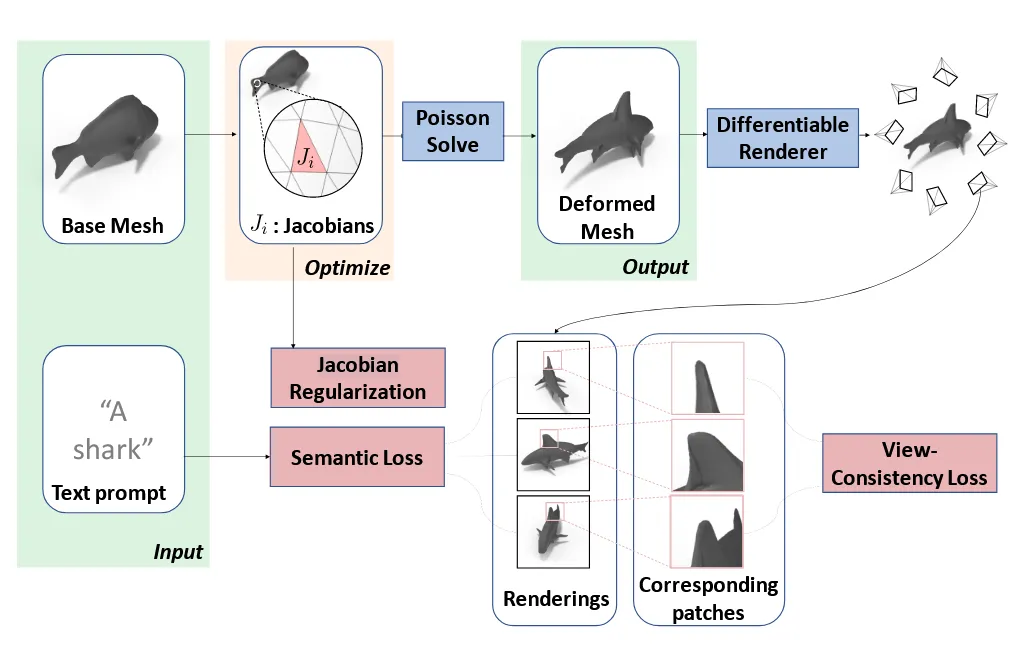
입력으로는 위에서 말했던 것처럼 Base Mesh + Text prompt가 들어가고, 출력으로는 점들의 집합(V)와 faces(F)를 기반으로 mesh(M)을 생성합니다. 이를 위해서 displacement map(Φ : R3 → R3)을 학습하는 것을 목표로 합니다. 이제 이 과정이 어떻게 진행되는지 하나하나 살펴보겠습니다.
Deformations through Jacobians
Deformation을 하는 가장 naive한 방식은 각 vertex의 위치를 직접 이동시키는 것입니다. 하지만 vertex의 위치를 직접 이동시킬 경우 high-frequency noise가 발생할 수 있습니다. 즉 디테일한 부분에 울퉁불퉁한 부적절한 결과가 나올 수 있습니다. 또한 전체적인 형태가 무너지고 artifact가 발생할 수 있습니다.
윗줄: Vertex deformation
아랫줄: Jacobian deformation
이러한 이유때문에 각 vertex가 아닌 face 단위의 변형 행렬을 최적화 합니다. 즉 삼각형이 어떤 방향으로 얼마나 늘어나고 뒤틀렸는지를 행렬로 표현하는 것 입니다.
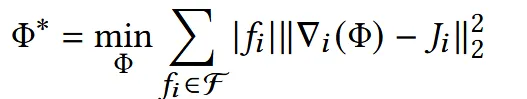
수식적으로 displacement map을 구하기 위해서 face를 기반으로 Jacobian을 우리가 원하는 형태로 변형합니다. 는 i번째 face로서 면적이 클수록 결과에 더 많은 영향을 주도록 설계 되어 있습니다.
Deformation을 진행할 때 face의 변화를 나타내는 Jacobian을 구해도 우리는 vertex의 위치가 필요한데, 이 과정에서 Poisson Equation을 사용합니다. 이 과정은 Neural Jacobian Fields (Aigerman et al. 2022) 논문에 나와있는데 시간이 된다면 나중에 리뷰를 진행하도록 하겠습니다.
Language Guidance
이 부분에서는 어떻게 text가 guidance로서 mesh를 deformation하는지 설명하도록 하겠습니다. 사용하는 모델은 pre-trained vision-language CLIP 모델입니다.
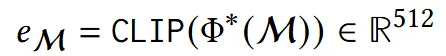
위에서 구한 최종 mesh를 렌더링한 이미지를 CLIP 이미지 인코더를 통해서 이미지 임베딩을 생성합니다.
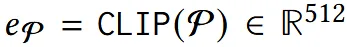
같은 방식으로 Text(Pormpt, P)도 CLIP 텍스트 인코더를 통해서 텍스트 임베딩을 생성합니다.
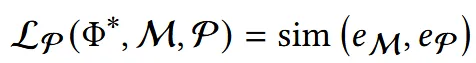
이후 CLIP에서 사용한 Cosine 유사도를 사용해서 학습을 진행합니다.
StyleCLIP에서 사용한 Cosine 유사도 방식을 사용해서 위의 수식을 조금 수정합니다.
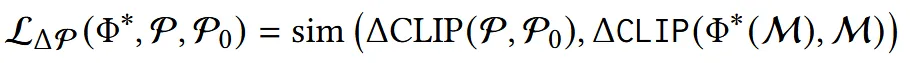
Mesh의 렌더링 임베딩 과 Input Mesh의 렌더링 임베딩 의 차이가, Input mesh를 설명하는 base caption 과 text prompt 와의 차이와 유사하도록 학습하는 방식입니다.
Jacobian Regularization
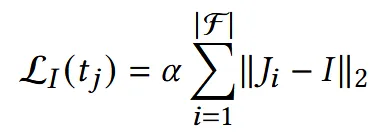
위의 수식은 우리가 Mesh를 변형할 때 원본이 너무 많이 바뀌는 것을 방지하는 regularization 부분입니다. 값을 하이퍼파라미터로 설정할 수 있고, 이 값이 0이면 regularization이 없게 되는 것입니다.
View Consistency
만약 소의 mesh를 코끼리로 변형한다고 했을 때 현재까지 설계된 방식으로 진행하면 정면 view에서는 코를 늘려서 코끼리 코로 만들려고 하고, 옆면 view에서는 코 부분을 상아로 생각해서 옆으로 튀어나오게 하려 할 것입니다. 즉 한 vertex가 서로 모순된 방향으로 당겨져 일관성이 깨집니다. 이렇게 된 원인은 단순히 여러시점에서 나온 Jacobian의 gradient를 평균내려고 하기 때문입니다.
위의 문제를 해결하기 위해서 새로운 regularization을 추가합니다. CLIP 이미지 인코더는 ViT를 사용하는데, ViT는 서로 겹치지 않는 여러개의 패치들로 나눠서 transformer encdoer를 통과하게 됩니다. 각각의 vertex(v)를 렌더링 했을 때, 렌더링 된 이미지에서 어느 픽셀에 속하는지 p(u,r)을 구합니다. 이후 이 픽셀값이 ViT의 어느 패치에 속하는지 P(u,r)로 구합니다.
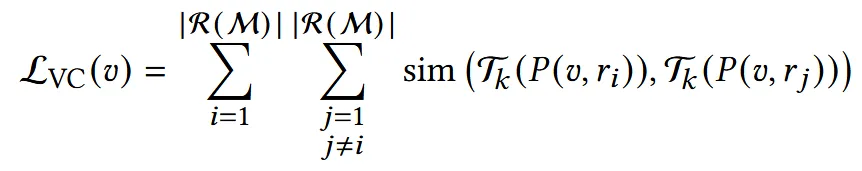
위의 방법으로 여러시점에서 구한 서로다른 ViT 패치들은 서로 의미론적으로 유사해야 하기 때문에 cosine 유사도를 기반으로 추가적인 학습을 진행하게 됩니다. 여기서 패치로부터 추출된 임베딩을 속하기 위해서 어떤 output을 사용할지를 의 layer로 결정하는데 논문에서는 final transformer block를 선택했습니다.
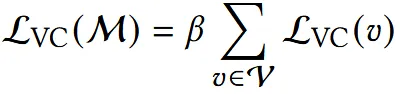
최종적인 Regularization term은 위와 같이 기존처럼 하이퍼파라미터 B를 통해서 강도를 조절할 수 있는 형태가 될 것 입니다.

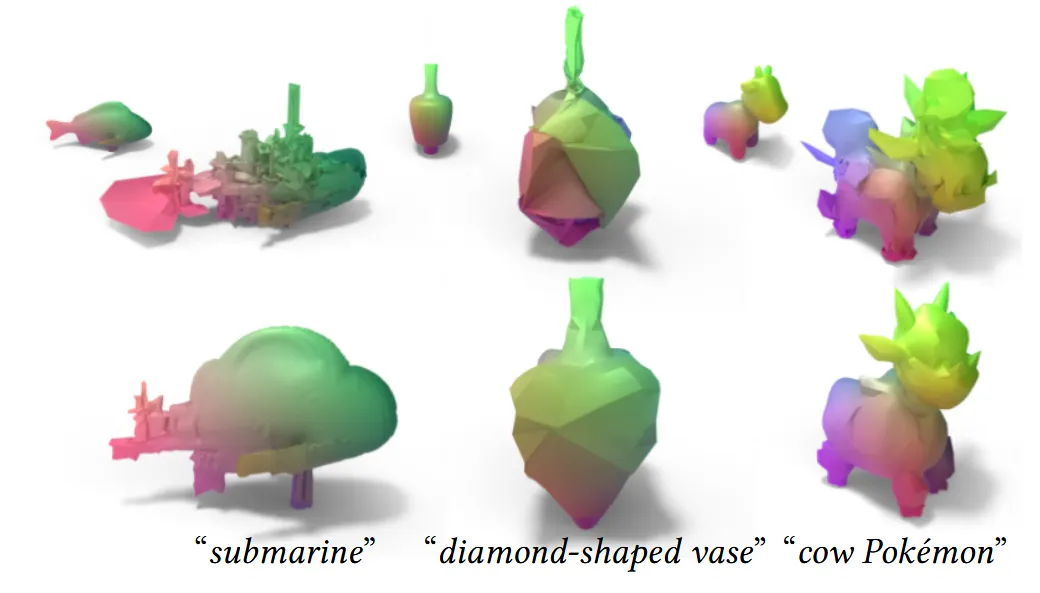
Regularization을 추가함으로서 확실히 view consistency가 일치해지는 것을 확인할 수 있습니다.
Experiments

